GoTTA be Diverse: Rethinking Memory Policies for Test-Time Adaptation
Pith reviewed 2026-05-20 05:21 UTC · model grok-4.3
The pith
Memory policies that keep intra-class diverse samples outperform recent or class-balanced buffers for test-time adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
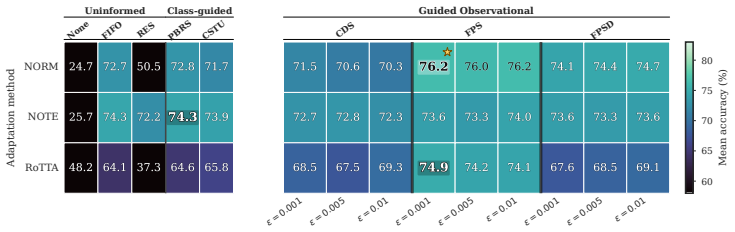
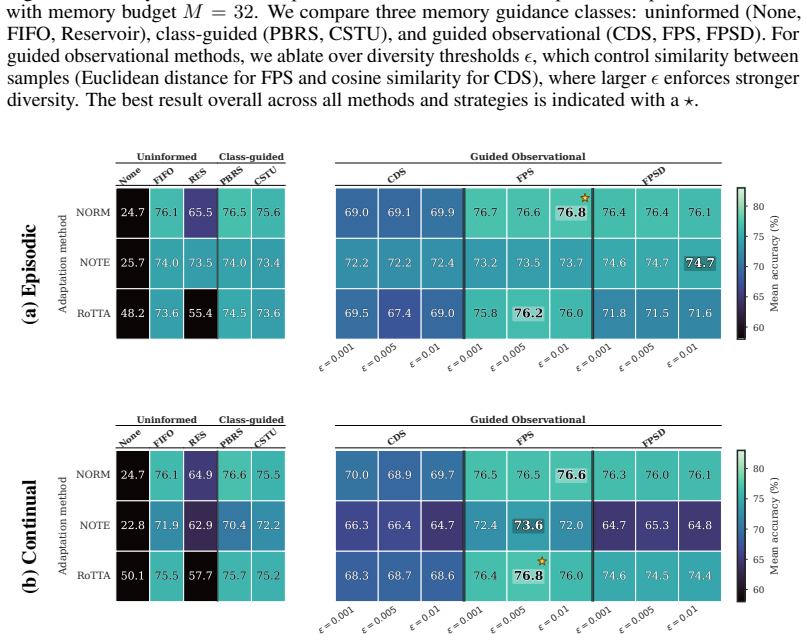
Effective test-time adaptation requires memory buffers that are both class-balanced and diverse within each class; the Guided Observational Test-Time Adaptation (GOTTA) family implements this principle by allocating slots proportionally to observed classes and then selecting samples that maximize feature-space spread, yielding higher adaptation accuracy than recency-only or balance-only policies across corruption and video benchmarks.
What carries the argument
GOTTA diversity-aware memory policies that combine class-balanced slot allocation with explicit feature-space diversity selection inside each class.
If this is right
- Memory design becomes a first-class lever in TTA, independent of the particular adaptation objective.
- Intra-class diversity reduces redundancy and preserves representative signals under label skew and temporal correlation.
- The same memory policies can be swapped into existing TTA methods without changing their loss functions.
- Gains are largest when memory capacity is tightly constrained and streams deviate strongly from i.i.d.
Where Pith is reading between the lines
- The same diversity principle could be tested in continual learning settings where the model must retain knowledge across many tasks rather than adapt once.
- Pairing diversity selection with uncertainty or entropy filters might further improve sample quality when both criteria are available.
- Real-world deployment would benefit from measuring the computational overhead of the diversity computation relative to the adaptation gains.
Load-bearing premise
The chosen corruption and video-stream benchmarks are representative enough that the observed differences between memory policies will hold for other practical test-time conditions.
What would settle it
Running the same memory policies on a new non-i.i.d. stream where intra-class feature variance is naturally very low and finding that GOTTA no longer improves over a simple FIFO buffer.
Figures



read the original abstract
Test-time adaptation (TTA) enables a pre-trained model to adapt online to an unlabeled test stream under distribution shift. While most TTA research focuses on the adaptation objective, practical streams also depend critically on the memory used to select which test samples drive adaptation. Existing memory mechanisms are usually evaluated as components of specific TTA algorithms, making it difficult to isolate which memory design choices matter and when they matter. In this work, we provide a systematic benchmark that decouples memory from the adaptation algorithm and evaluates memory policies under unified conditions across i.i.d., non-i.i.d., continual, and practical test streams. Our study shows that effective memory management requires more than retaining recent or class-balanced samples. In particular, intra-class diversity is a key factor for avoiding redundant buffers and maintaining representative adaptation signals under temporally correlated and label-skewed streams. Motivated by this finding, we introduce Guided Observational Test-Time Adaptation (GOTTA), a family of diversity-aware memory policies that combine class-balanced allocation with feature-space diversity. GOTTA memories act as drop-in replacements for existing buffers and can be paired with different TTA objectives. Across corruption benchmarks and video-stream settings, diversity-aware memory improves adaptation most clearly under constrained memory budgets and challenging non-i.i.d. streams, while remaining competitive as memory capacity increases. These results highlight memory management as a first-class component of robust test-time adaptation and identify diversity as a central principle for practical TTA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that memory policies in test-time adaptation (TTA) have been understudied because they are typically evaluated only as components of specific TTA algorithms. Through a systematic benchmark that decouples memory selection from the adaptation objective, the authors evaluate policies across i.i.d., non-i.i.d., continual, and practical streams on corruption benchmarks (CIFAR-C, ImageNet-C) and video streams. They conclude that intra-class diversity is essential to avoid redundant buffers under temporally correlated and label-skewed conditions, and introduce GOTTA, a family of diversity-aware policies that combine class-balanced allocation with feature-space diversity. These policies are shown to improve adaptation most under constrained memory budgets and challenging non-i.i.d. streams while remaining competitive at larger capacities.
Significance. If the benchmark results and the reported gains hold under the stated conditions, the work usefully elevates memory management to a first-class design choice in TTA and supplies a reusable evaluation framework that isolates policy effects. The emphasis on diversity as a guiding principle offers a concrete, actionable insight for practitioners facing limited buffers and distribution shift.
major comments (1)
- [Section 3] Section 3: The central claim that the benchmark isolates memory-policy effects from adaptation objectives rests on the assumption that buffer contents interact with the TTA loss (entropy minimization, pseudo-labeling, etc.) only through the selected samples. Because the adaptation objective recomputes statistics or gradients from the buffer, diversity-aware selection could alter those statistics differently than the class-balanced or recency baselines; without an explicit ablation that replaces the adaptation objective by a parameter-free alternative, the observed gains cannot be attributed solely to diversity.
minor comments (2)
- [Abstract] The abstract states that diversity-aware memory 'improves adaptation most clearly under constrained memory budgets' but supplies no quantitative deltas, error bars, or statistical tests; the full experimental section should report these numbers for each budget and stream type.
- Clarify the precise definition and computation of 'feature-space diversity' used inside GOTTA (e.g., which distance metric, how many neighbors, whether it is enforced via explicit regularization or only via selection).
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The major comment raises a valid point about the limits of isolation in our benchmark, which we address directly below with a proposed revision.
read point-by-point responses
-
Referee: [Section 3] Section 3: The central claim that the benchmark isolates memory-policy effects from adaptation objectives rests on the assumption that buffer contents interact with the TTA loss (entropy minimization, pseudo-labeling, etc.) only through the selected samples. Because the adaptation objective recomputes statistics or gradients from the buffer, diversity-aware selection could alter those statistics differently than the class-balanced or recency baselines; without an explicit ablation that replaces the adaptation objective by a parameter-free alternative, the observed gains cannot be attributed solely to diversity.
Authors: We thank the referee for this precise observation. Our benchmark in Section 3 does fix the adaptation objective (e.g., entropy minimization or pseudo-labeling) while varying only the memory policy, allowing direct comparison of selection strategies under identical loss computations. We agree, however, that sample selection can still influence batch statistics or gradients, so the gains are not purely from sample quality independent of the objective. To strengthen the isolation claim, we will add (i) an explicit discussion of this interaction in the revised Section 3 and (ii) a new ablation that evaluates buffer quality via a parameter-free method (nearest-neighbor classification on frozen features without any model update or loss-driven adaptation). Preliminary results from this ablation show that diversity-aware buffers still yield higher representation quality than recency or class-balanced baselines, supporting that selection itself contributes meaningfully. We will include the full ablation and updated discussion in the revision. revision: partial
Circularity Check
Empirical benchmark with no circular derivation chain
full rationale
The paper is a systematic empirical benchmark study that decouples memory policies from specific TTA adaptation objectives and evaluates them across i.i.d., non-i.i.d., continual, and practical streams using corruption and video datasets. Claims about diversity-aware memory (GOTTA) improving adaptation under constrained budgets are presented as experimental outcomes rather than mathematical predictions or first-principles derivations. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text; the work remains self-contained against external benchmarks without reducing any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
GOTTA memory policies
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dataset shift in machine learning
Joaquin Quinonero-Candela, Masashi Sugiyama, Anton Schwaighofer, and Neil D Lawrence. Dataset shift in machine learning. 2008
work page 2008
-
[2]
Deep visual domain adaptation: A survey.Neurocomputing, 312:135–153, 2018
Mei Wang and Weihong Deng. Deep visual domain adaptation: A survey.Neurocomputing, 312:135–153, 2018
work page 2018
-
[3]
Domain generalization: A survey.IEEE Trans
Kaiyang Zhou, Ziwei Liu, Yu Qiao, Tao Xiang, and Chen Change Loy. Domain generalization: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 2022
work page 2022
-
[4]
Improving robustness against common corruptions by covariate shift adaptation
Steffen Schneider, Evgenia Rusak, Luisa Eck, Oliver Bringmann, Wieland Brendel, and Matthias Bethge. Improving robustness against common corruptions by covariate shift adaptation. In NeurIPS 2020, 2020
work page 2020
-
[5]
Evaluating prediction-time batch normalization for robustness under covariate shift,
Zachary Nado, Shreyas Padhy, D. Sculley, Alexander D’Amour, Balaji Lakshminarayanan, and Jasper Snoek. Evaluating prediction-time batch normalization for robustness under covariate shift.CoRR, abs/2006.10963, 2020
-
[6]
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno A. Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. InICLR, 2021
work page 2021
-
[7]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. InWorkshop on challenges in representation learning, ICML, volume 3, page 896, 2013
work page 2013
-
[8]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. InICML, pages 9229–9248, 2020
work page 2020
-
[9]
Robust continual test-time adaptation: Instance-aware BN and prediction-balanced memory
Taesik Gong, Jongheon Jeong, Taewon Kim, Yewon Kim, Jinwoo Shin, and Sung-Ju Lee. Robust continual test-time adaptation: Instance-aware BN and prediction-balanced memory. In NeurIPS, 2022
work page 2022
-
[10]
Robust test-time adaptation in dynamic scenarios,
Longhui Yuan, Binhui Xie, and Shuang Li. Robust test-time adaptation in dynamic scenarios,
- [11]
-
[12]
Generalized domain conditioned adaptation network.IEEE Trans
Shuang Li, Binhui Xie, Qiuxia Lin, Chi Harold Liu, Gao Huang, and Guoren Wang. Generalized domain conditioned adaptation network.IEEE Trans. Pattern Anal. Mach. Intell., 44(8):4093– 4109, 2022
work page 2022
-
[13]
Mingsheng Long, Yue Cao, Zhangjie Cao, Jianmin Wang, and Michael I. Jordan. Transferable representation learning with deep adaptation networks.IEEE Trans. Pattern Anal. Mach. Intell., 41(12):3071–3085, 2019
work page 2019
- [14]
-
[15]
Maximum classifier discrepancy for unsupervised domain adaptation
Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. InCVPR, pages 3723–3732, 2018
work page 2018
-
[16]
Sepico: Semantic-guided pixel contrast for domain adaptive semantic segmentation.IEEE Trans
Binhui Xie, Shuang Li, Mingjia Li, Chi Harold Liu, Gao Huang, and Guoren Wang. Sepico: Semantic-guided pixel contrast for domain adaptive semantic segmentation.IEEE Trans. Pattern Anal. Mach. Intell., pages 1–17, 2023
work page 2023
-
[17]
Unsupervised domain adaptation for semantic segmentation via class-balanced self-training
Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. InECCV, pages 289–305, 2018. 10
work page 2018
-
[18]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ales Leonardis, Gregory G. Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Trans. Pattern Anal. Mach. Intell., 44(7):3366–3385, 2022. doi: 10.1109/TPAMI.2021.3057446. URLhttps://doi.org/10.1109/TPAMI.2021.3057446
-
[19]
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Des- jardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska- Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Over- coming catastrophic forgetting in neural networks.CoRR, abs/1612.00796, 2016. URL http://arxiv.org/abs/1...
-
[20]
Gradient based sample selection for online continual learning
Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learning. InNeurIPS, pages 11816–11825, 2019
work page 2019
-
[21]
End-to-end incremental learning
Francisco M Castro, Manuel J Marín-Jiménez, Nicolás Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InECCV, pages 233–248, 2018
work page 2018
-
[22]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. icarl: Incremental classifier and representation learning. InCVPR, pages 5533–5542, 2017
work page 2017
-
[23]
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
work page 2025
-
[24]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InICML, pages 448–456, 2015
work page 2015
-
[25]
Jian Liang, Dapeng Hu, and Jiashi Feng. Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. InICML, pages 6028–6039, 2020
work page 2020
-
[26]
Test-time adaptation via self-training with nearest neighbor information.CoRR, abs/2207.10792, 2022
Minguk Jang and Sae-Young Chung. Test-time adaptation via self-training with nearest neighbor information.CoRR, abs/2207.10792, 2022
-
[27]
Test-time classifier adjustment module for model-agnostic domain generalization
Yusuke Iwasawa and Yutaka Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization. InNeurIPS, pages 2427–2440, 2021
work page 2021
-
[28]
Continual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Continual test-time domain adaptation. InCVPR, pages 7191–7201, 2022
work page 2022
-
[29]
Perez, Merey Ramazanova, and Bernard Ghanem
Shyma Alhuwaider, Motasem Alfarra, Juan C. Perez, Merey Ramazanova, and Bernard Ghanem. Advmem: Adversarial memory initialization for realistic test-time adaptation via tracklet-based benchmarking, 2025. URLhttps://arxiv.org/abs/2509.02182
-
[30]
Stamp: Outlier-aware test-time adaptation with stable memory replay, 2024
Yongcan Yu, Lijun Sheng, Ran He, and Jian Liang. Stamp: Outlier-aware test-time adaptation with stable memory replay, 2024. URLhttps://arxiv.org/abs/2407.15773
-
[31]
Jeffrey S. Vitter. Random sampling with a reservoir.ACM Trans. Math. Softw., 11(1):37–57, March 1985. ISSN 0098-3500. doi: 10.1145/3147.3165. URL https://doi.org/10.1145/ 3147.3165
-
[32]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Towards active learning for action spotting in association football videos
Silvio Giancola, Anthony Cioppa, Julia Georgieva, Johsan Billingham, Andreas Serner, Kerry Peek, Bernard Ghanem, and Marc Van Droogenbroeck. Towards active learning for action spotting in association football videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5098–5108, June 2023
work page 2023
-
[34]
Yuval Eldar, Michael Lindenbaum, Moshe Porat, and Yehoshua Y Zeevi. The farthest point strategy for progressive image sampling.IEEE transactions on image processing, 6(9):1305– 1315, 1997
work page 1997
-
[35]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 11
work page 2017
-
[36]
Determinantal point processes for machine learning.stat, 1050:10, 2013
Alex Kulesza Ben Taskar. Determinantal point processes for machine learning.stat, 1050:10, 2013
work page 2013
-
[37]
Laming Chen, Guoxin Zhang, and Eric Zhou. Fast greedy map inference for determinantal point process to improve recommendation diversity.Advances in neural information processing systems, 31, 2018
work page 2018
-
[38]
Dan Hendrycks and Thomas G. Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. InICLR, 2019
work page 2019
-
[39]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. InICML, volume 162, pages 16888–16905, 2022
work page 2022
-
[40]
Towards stable test-time adaptation in dynamic wild world, 2023
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world, 2023. URL https: //arxiv.org/abs/2302.12400
-
[41]
Tea: Test-time energy adaptation, 2024
Yige Yuan, Bingbing Xu, Liang Hou, Fei Sun, Huawei Shen, and Xueqi Cheng. Tea: Test-time energy adaptation, 2024. URLhttps://arxiv.org/abs/2311.14402
-
[42]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. InBMVC, 2016
work page 2016
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, pages 770–778, 2016
work page 2016
-
[44]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
work page 2021
-
[45]
Parameter-free online test-time adaptation
Malik Boudiaf, Romain Mueller, Ismail Ben Ayed, and Luca Bertinetto. Parameter-free online test-time adaptation. InCVPR, pages 8344–8353, 2022. 12 6 Appendix 6.1 Test-Time Adaptation settings Following Yuan et al.[10], we distinguish four TTA settings of increasing difficulty, all sharing the same protocol: a source-trained model fθs is adapted online usi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.