Streamlined Constraint Reasoning via CNN Pattern Recognition on Enumerated Solutions
Pith reviewed 2026-05-20 05:51 UTC · model grok-4.3
The pith
Training a CNN on enumerated solutions lets an LLM synthesize streamliner constraints that cut portfolio solving times by 89 to 99 percent on hardened benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
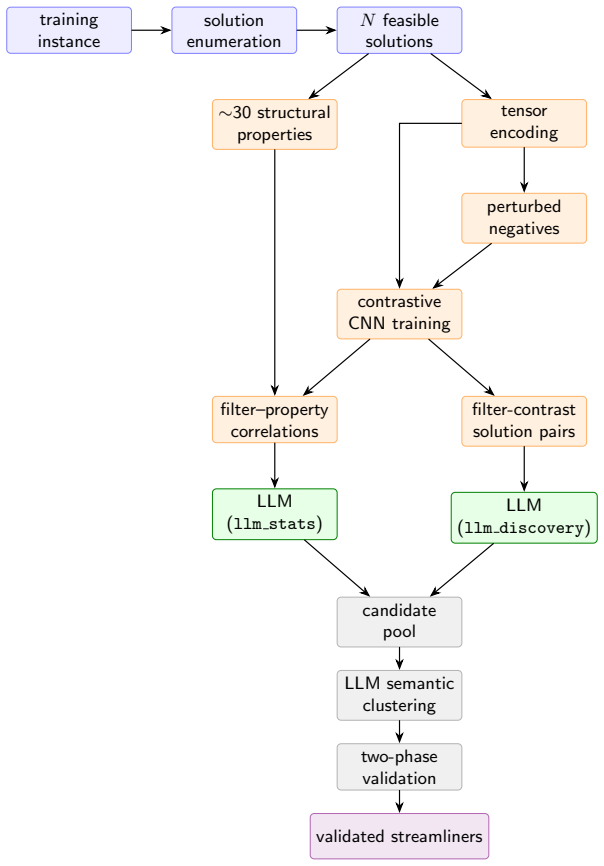
The central claim is that contrastively training a CNN on enumerated feasible solutions versus perturbed non-solutions yields a reliable structural signal that an LLM can translate into candidate streamliner constraints, which in turn produce the reported time reductions and speedups on the three hardened benchmark models while preserving the satisfiability of the original problem within the chosen sub-family of solutions.
What carries the argument
The CNN contrastively trained on solution enumerations to detect discriminative structural patterns, which are then passed to the LLM for synthesis into streamliner constraints.
If this is right
- Class-based packing constraints become discoverable for Vessel Loading problems after standard hardening.
- Beyond-hardening canonicalisation constraints improve solving performance on Social Golfers instances.
- Layout-coordinate bound constraints streamline search on Black Hole problems.
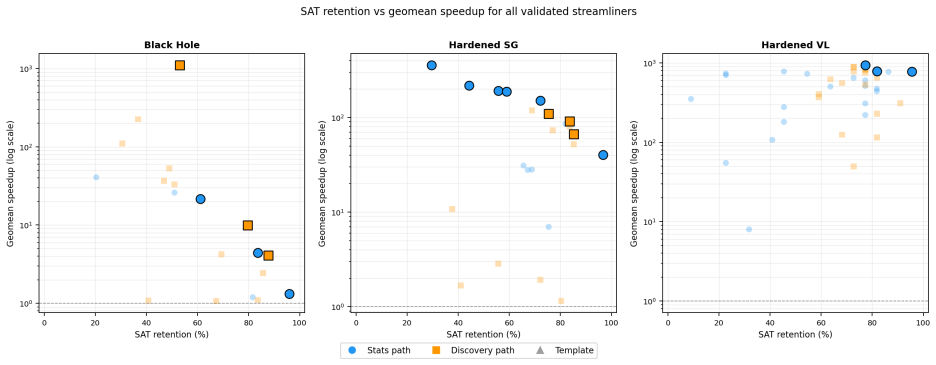
- The overall portfolio solving time across the three domains drops by 89 to 99 percent when the synthesized streamliners are included.
Where Pith is reading between the lines
- The same enumerate-CNN-LLM loop could be tested on other combinatorial domains where small numbers of solutions can be generated quickly.
- If the CNN patterns remain stable across different enumerations, the method might reduce the amount of manual tuning needed when moving from one instance family to another.
- The approach suggests a practical division of labor in which neural methods locate structure and symbolic constraint languages enforce it.
Load-bearing premise
Patterns detected by the CNN on a limited sample of enumerated solutions can be turned by the LLM into streamliners that generalize to the full problem without excluding too many solutions or introducing excessive bias.
What would settle it
A new benchmark instance where the generated streamliners either produce no measurable speedup or cause the solver to report unsatisfiability on a problem that remains satisfiable without them would refute the claim that the CNN-LLM pipeline reliably produces useful streamliners.
Figures




read the original abstract
Constraint programming practitioners accelerate hard problems through a layered set of techniques applied in order of risk. Standard hardening (symmetry-breaking and implied constraints) is applied first and preserves satisfiability. Streamliner constraints, which restrict search to a structural sub-family of solutions, do not preserve satisfiability and are reserved as a final lever. Existing automated streamliner-synthesis approaches either search a constraint grammar or prompt a Large Language Model directly on the problem model. We propose a different approach: enumerate feasible solutions, train a Convolutional Neural Network contrastively against perturbed non-solutions to detect structural patterns, and translate the CNN's discriminative signal into candidate MiniZinc streamliners through LLM-driven synthesis. The CNN grounds the LLM's constraint generation in observed solution structure rather than model text alone. We evaluate on hardened benchmark models where streamliner discovery is the residual performance lever. Our pipeline achieves 98.8% portfolio time reduction on hardened Vessel Loading, 98.6% on hardened Social Golfers, and 89.4% on Black Hole, with best-single streamliners reaching geometric-mean speedups of 932x, 356x, and 1103x respectively. Discovered streamliners include class-based packing constraints on Vessel Loading, beyond-hardening canonicalisations on Social Golfers, and layout-coordinate bounds on Black Hole.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a pipeline for automated streamliner discovery in constraint programming: enumerate feasible solutions to a hardened CP model, train a CNN contrastively on solutions vs. perturbed non-solutions to learn structural patterns, and employ an LLM to synthesize MiniZinc streamliner constraints from the CNN's discriminative features. Evaluation on three hardened benchmarks reports portfolio time reductions of 98.8% (Vessel Loading), 98.6% (Social Golfers), and 89.4% (Black Hole), with best single streamliners yielding geometric-mean speedups of 932x, 356x, and 1103x.
Significance. If the reported performance gains hold under scrutiny regarding enumeration costs and generalization, the work would represent a meaningful advance in hybrid ML-CP methods for streamliner synthesis. By grounding LLM-generated constraints in empirical solution data rather than model text or grammar search alone, it addresses a key limitation of prior approaches and could enable more effective acceleration of hard CP instances where standard hardening is insufficient.
major comments (3)
- Abstract: The central performance claims (98.8% portfolio time reduction on hardened Vessel Loading, 98.6% on Social Golfers, 89.4% on Black Hole) are presented without any indication of the enumeration scale, the computational cost of generating the training set on the full hardened instances, or whether enumeration was performed on proxies. This directly bears on applicability, as the skeptic concern that enumeration may be intractable on the target benchmarks is not addressed.
- Abstract / Evaluation: The pipeline's reliance on translating CNN patterns via LLM into generalizing streamliners is load-bearing for the speedup claims (932x, 356x, 1103x geometric means), yet no validation, ablation, or test for missed solution classes or introduced bias is described, leaving the weakest assumption unexamined.
- Method description: The contrastive CNN training on enumerated solutions vs. perturbed non-solutions is presented as the grounding mechanism, but the manuscript provides no details on perturbation procedure, training hyperparameters, or statistical controls, making it impossible to assess reproducibility or whether the detected patterns are robust.
minor comments (1)
- Abstract: The phrase 'hardened benchmark models' is used without a brief definition or citation to the specific hardening techniques applied prior to streamliner discovery.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify key areas where additional information will strengthen the manuscript's clarity, reproducibility, and defensibility of the performance claims. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: Abstract: The central performance claims (98.8% portfolio time reduction on hardened Vessel Loading, 98.6% on Social Golfers, and 89.4% on Black Hole) are presented without any indication of the enumeration scale, the computational cost of generating the training set on the full hardened instances, or whether enumeration was performed on proxies. This directly bears on applicability, as the skeptic concern that enumeration may be intractable on the target benchmarks is not addressed.
Authors: We agree that the abstract and evaluation sections should explicitly address enumeration feasibility to support applicability claims. In the revised manuscript we will add a concise statement in the abstract and a dedicated paragraph in the Evaluation section reporting the enumeration scale (number of solutions and non-solutions generated per benchmark), the computational resources required (wall-clock time and hardware), and confirming that enumeration was performed directly on the hardened models rather than proxies. These additions will demonstrate that the reported costs remain practical for the evaluated instances. revision: yes
-
Referee: Abstract / Evaluation: The pipeline's reliance on translating CNN patterns via LLM into generalizing streamliners is load-bearing for the speedup claims (932x, 356x, 1103x geometric means), yet no validation, ablation, or test for missed solution classes or introduced bias is described, leaving the weakest assumption unexamined.
Authors: We recognize that empirical speedups alone do not fully validate generalization of the LLM-translated streamliners. The revised manuscript will include a new subsection under Evaluation that reports (i) an ablation comparing CNN-guided synthesis against direct LLM prompting on the model text, (ii) performance on a held-out set of instances to check for missed solution classes, and (iii) a qualitative analysis of potential bias introduced by the CNN feature extraction step. These experiments will be added without altering the original benchmark results. revision: yes
-
Referee: Method description: The contrastive CNN training on enumerated solutions vs. perturbed non-solutions is presented as the grounding mechanism, but the manuscript provides no details on perturbation procedure, training hyperparameters, or statistical controls, making it impossible to assess reproducibility or whether the detected patterns are robust.
Authors: We accept that the current method description lacks sufficient detail for reproducibility. The revised version will expand the Method section with: (a) the exact perturbation procedure (including how non-solutions are generated while preserving local structure), (b) all CNN training hyperparameters (architecture, contrastive loss, optimizer, learning rate, batch size, epochs, and early-stopping criteria), and (c) statistical controls such as multiple random seeds and cross-validation folds used to confirm pattern robustness. These additions will allow independent replication and evaluation of the learned features. revision: yes
Circularity Check
No circularity: empirical pipeline remains self-contained against external benchmarks
full rationale
The paper presents an empirical workflow—enumerate feasible solutions, train a contrastive CNN on structural patterns, then use LLM synthesis to produce MiniZinc streamliners—whose performance claims (time reductions and geometric-mean speedups) are measured on separate hardened benchmark runs. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation; the CNN training data and final solver timings are generated and evaluated independently of any target result. The approach is therefore not equivalent to its inputs by construction and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
enumerate feasible solutions to a training instance, train a Convolutional Neural Network contrastively against perturbed non-solutions to detect structural patterns the feasibility predicate exploits, and translate the CNN’s discriminative signal... into candidate MiniZinc streamliners through LLM-driven constraint synthesis
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The CNN serves as a pattern recognizer over enumerated solutions, surfacing structural regularities that ground the LLM’s constraint-generation reasoning.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
¨Ozg¨ ur Akg¨ un, Alan M. Frisch, Ian P. Gent, Christopher Jefferson, Ian Miguel, and Peter Nightingale. Conjure: Automatic generation of constraint models from problem specifications. Artificial Intelligence, 310:103751, 2022
work page 2022
-
[2]
Network dissection: Quantifying interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. InConference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[3]
A model seeker: Extracting global constraint models from positive examples
Nicolas Beldiceanu and Helmut Simonis. A model seeker: Extracting global constraint models from positive examples. InPrinciples and Practice of Constraint Programming (CP), 2012
work page 2012
-
[4]
Constraint acquisition.Artificial Intelligence, 244:315–342, 2017
Christian Bessiere, R´ emi Coletta, Emmanuel Hebrard, George Katsirelos, Nadjib Lazaar, Nina Narodytska, Claude-Guy Quimper, and Toby Walsh. Constraint acquisition.Artificial Intelligence, 244:315–342, 2017
work page 2017
-
[5]
Automatic generation of implied constraints
John Charnley, Simon Colton, and Ian Miguel. Automatic generation of implied constraints. InEuropean Conference on Artificial Intelligence (ECAI), 2006
work page 2006
-
[6]
Chuffed: A lazy clause generation solver
Geoffrey Chu. Chuffed: A lazy clause generation solver. 2018. https://github.com/chuffed/ chuffed
work page 2018
-
[7]
Symmetry-breaking predicates for search problems
James Crawford, Matthew Ginsberg, Eugene Luks, and Amitabha Roy. Symmetry-breaking predicates for search problems. InKnowledge Representation and Reasoning (KR), 1996
work page 1996
-
[8]
A framework for generating informative benchmark instances
Nguyen Dang, ¨Ozg¨ ur Akg¨ un, Joan Espasa, Ian Miguel, and Peter Nightingale. A framework for generating informative benchmark instances. InPrinciples and Practice of Constraint Programming (CP), volume 235, pages 18:1–18:18, 2022
work page 2022
-
[9]
Frisch, Brahim Hnich, Zeynep Kiziltan, Ian Miguel, Justin Pearson, and Toby Walsh
Pierre Flener, Alan M. Frisch, Brahim Hnich, Zeynep Kiziltan, Ian Miguel, Justin Pearson, and Toby Walsh. Breaking row and column symmetries in matrix models. InPrinciples and Practice of Constraint Programming (CP), pages 462–477, 2002
work page 2002
-
[10]
Frisch, Warwick Harvey, Christopher Jefferson, Bernadette Mart´ ınez Hern´ andez, and Ian Miguel
Alan M. Frisch, Warwick Harvey, Christopher Jefferson, Bernadette Mart´ ınez Hern´ andez, and Ian Miguel. Essence: A constraint language for specifying combinatorial problems.Constraints, 13(3):268–306, 2008
work page 2008
-
[11]
Gent, Christopher Jefferson, Tom Kelsey, Inˆ es Lynce, Ian Miguel, Peter Nightingale, Barbara M
Ian P. Gent, Christopher Jefferson, Tom Kelsey, Inˆ es Lynce, Ian Miguel, Peter Nightingale, Barbara M. Smith, and S. Armagan Tarim. Search in the patience game ‘Black Hole’. InAI Communications, volume 20, pages 211–226, 2007
work page 2007
-
[12]
Ian P. Gent and Toby Walsh. CSPLib: A benchmark library for constraints. https://www. csplib.org/, 1999. Online benchmark library; problem 010 (Social Golfers), 008 (Vessel Loading), 023 (Black Hole patience)
work page 1999
-
[13]
Carla P. Gomes and Meinolf Sellmann. Streamlined constraint reasoning. InPrinciples and Practice of Constraint Programming (CP), 2004
work page 2004
-
[14]
Ronan Le Bras, Carla P. Gomes, and Bart Selman. From streamlined combinatorial search to efficient constructive procedures. InAAAI Conference on Artificial Intelligence, 2012. 27
work page 2012
-
[15]
Stuckey, Ralph Becket, Sebastian Brand, Gregory J
Nicholas Nethercote, Peter J. Stuckey, Ralph Becket, Sebastian Brand, Gregory J. Duck, and Guido Tack. MiniZinc: Towards a standard CP modelling language. InPrinciples and Practice of Constraint Programming (CP), 2007
work page 2007
-
[16]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. Can large language models reason about program invariants? InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[17]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625:468–475, 2024
work page 2024
-
[18]
Foundations of Artificial Intelligence
Francesca Rossi, Peter van Beek, and Toby Walsh, editors.Handbook of Constraint Programming. Foundations of Artificial Intelligence. Elsevier, 2006
work page 2006
-
[19]
Olivier Roussel. Controlling a solver execution: the runsolver tool.Journal on Satisfiability, Boolean Modeling and Computation, 7(4):139–144, 2011
work page 2011
-
[20]
Daniel Selsam, Matthew Lamm, Benedikt B¨ unz, Percy Liang, Leonardo de Moura, and David L. Dill. Learning a SAT solver from single-bit supervision.International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[21]
Gomes, and C` esar Fern´ andez
Casey Smith, Carla P. Gomes, and C` esar Fern´ andez. Streamlining local search for spatially balanced Latin squares. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2005
work page 2005
-
[22]
Monte carlo tree search on a model lattice: Automatic streamliner generation
Patrick Spracklen, ¨Ozg¨ ur Akg¨ un, and Ian Miguel. Monte carlo tree search on a model lattice: Automatic streamliner generation. InPrinciples and Practice of Constraint Programming (CP), 2018
work page 2018
-
[23]
Automatic streamlining for constrained optimisation
Patrick Spracklen, Nguyen Dang, ¨Ozg¨ ur Akg¨ un, and Ian Miguel. Automatic streamlining for constrained optimisation. InPrinciples and Practice of Constraint Programming (CP), 2019
work page 2019
-
[24]
Patrick Spracklen, Nguyen Dang, ¨Ozg¨ ur Akg¨ un, and Ian Miguel. Automated streamliner port- folios for constraint satisfaction problems.Artificial Intelligence, 319:103915, 2023. Benchmark instances and code:https://github.com/stacs-cp/automated-streamliner-portfolios
work page 2023
-
[25]
Florentina Voboril, Vaidyanathan Peruvemba Ramaswamy, and Stefan Szeider. Generating streamlining constraints with large language models.Journal of Artificial Intelligence Research, 84:16:1–16:19, 2025. Code and instances:https://zenodo.org/records/14757597
-
[26]
Po-Wei Wang, Priya Donti, Bryan Wilder, and J. Zico Kolter. SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[27]
Automatically generating streamlined constraint models with Essence and Conjure
James Wetter, ¨Ozg¨ ur Akg¨ un, and Ian Miguel. Automatically generating streamlined constraint models with Essence and Conjure. InPrinciples and Practice of Constraint Programming (CP), 2015
work page 2015
-
[28]
Lemur: Integrating large language models in automated program verification
Haoze Wu, Clark Barrett, and Nina Narodytska. Lemur: Integrating large language models in automated program verification. InInternational Conference on Learning Representations (ICLR), 2024. 28
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.