Where Does Authorship Signal Emerge in Encoder-Based Language Models?
Pith reviewed 2026-05-20 06:07 UTC · model grok-4.3
The pith
The scoring mechanism alone decides the layer where encoder models consolidate authorship signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
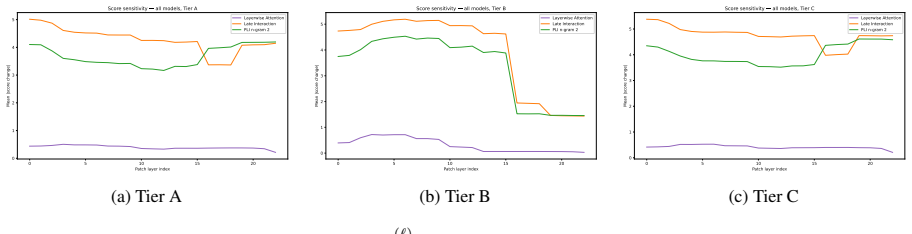
Authorship attribution models fine-tuned with the same pretrained encoder, data, and loss differ up to four-fold in performance solely due to their scoring mechanism. Mechanistic tools show stylistic features remain available at every layer in every encoder, including off-the-shelf controls. Causal interventions establish that the scorer dictates consolidation timing: mean pooling forces the signal to consolidate by early-to-mid layers, whereas late interaction defers consolidation to later layers. The difference follows from the distinct gradient structures of the two scorers and produces correspondingly distinct learning trajectories.
What carries the argument
Causal intervention that isolates layer-wise authorship signal under mean pooling versus late interaction scorers.
If this is right
- Mean pooling models learn to rely on early-layer representations while late-interaction models continue refining signal in deeper layers.
- Training dynamics diverge because each scorer back-propagates authorship gradients through different depths.
- Performance gaps arise from the timing of signal consolidation rather than from differences in what features the encoder can represent.
- Changing only the final scorer can move the effective depth at which an encoder solves the same stylistic task.
Where Pith is reading between the lines
- Designers of style-sensitive classifiers may improve results by deliberately choosing scorers that delay consolidation when deeper contextual cues matter.
- The same layer-timing logic could explain performance differences in other attribute classification tasks that rely on subtle surface patterns.
- Directly editing gradient flow during training might let practitioners control consolidation depth without swapping scorers.
Load-bearing premise
Stylistic features stay equally detectable at every layer in every model even after fine-tuning, so performance gaps cannot come from uneven feature availability.
What would settle it
A controlled experiment that measures authorship attribution accuracy after zeroing stylistic features only in early layers and finds mean-pooling models degrade far more than late-interaction models.
Figures





read the original abstract
Authorship attribution models fine-tuned with the same pretrained encoder, data, and loss can differ four-fold in performance depending only on their scoring mechanism. We use mechanistic interpretability tools to explain this gap. Stylistic features such as word length, punctuation density, and function-word frequency are equally available at every layer in every model, including in an off-the-shelf control encoder, hence the gap not coming from representation quality. Instead, causal intervention shows that the scorer determines where the encoder consolidates authorship signal. Mean pooling forces consolidation by early to mid layers, while late interaction defers it to later layers. We further derive this difference from the gradient structure of each scorer, and training dynamics reveal distinct learning trajectories that follow from that difference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that authorship attribution models fine-tuned with identical pretrained encoders, data, and loss can differ up to four-fold in performance solely due to the scoring mechanism. Using mechanistic interpretability, it shows that hand-selected stylistic features (word length, punctuation density, function-word frequency) are equally detectable across layers in all models including an off-the-shelf control encoder, ruling out representation quality as the cause. Causal interventions and gradient derivations instead demonstrate that mean pooling forces authorship-signal consolidation in early-to-mid layers while late interaction defers it to later layers, with supporting evidence from distinct training trajectories.
Significance. If the central claim holds, the work would provide a mechanistic account of how scorer choice shapes layer-wise consolidation of stylistic signals in encoder models, with direct implications for designing and interpreting authorship attribution systems and related stylistic NLP tasks. The combination of causal interventions, gradient analysis, and training dynamics offers a falsifiable explanation that could generalize beyond the specific features examined.
major comments (2)
- [Abstract and results on feature availability] The conclusion that the performance gap arises exclusively from consolidation timing (rather than representation quality) rests on the claim that the selected stylistic features are equally available at every layer in every model, including the off-the-shelf control encoder. Because these features constitute only a subset of possible authorship cues, the manuscript must demonstrate that higher-order signals (syntactic preferences, rare lexical choices, discourse patterns) do not exhibit layer- or scorer-dependent differences that could account for the observed accuracy gap.
- [Causal intervention experiments] The causal-intervention results that isolate the scorer's effect on consolidation location require explicit specification of the intervention protocol, the exact layers tested, the control conditions, and any statistical tests for significance. Without these details it is difficult to assess whether post-hoc choices or incomplete controls affect the layer-wise conclusions.
minor comments (2)
- Define the precise implementation of the 'late interaction' scorer (including any architectural modifications to the encoder) at the first mention to aid readers who may not be familiar with the term.
- Add a brief description of data exclusion rules, preprocessing steps, and the exact statistical methods used to compare feature detectability across layers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for clarification and strengthening. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and results on feature availability] The conclusion that the performance gap arises exclusively from consolidation timing (rather than representation quality) rests on the claim that the selected stylistic features are equally available at every layer in every model, including the off-the-shelf control encoder. Because these features constitute only a subset of possible authorship cues, the manuscript must demonstrate that higher-order signals (syntactic preferences, rare lexical choices, discourse patterns) do not exhibit layer- or scorer-dependent differences that could account for the observed accuracy gap.
Authors: We agree that the examined features represent a subset of possible authorship cues. The off-the-shelf encoder control already establishes that these low-level stylistic signals are detectable across layers without any fine-tuning for authorship, which helps isolate representation quality as not being the source of the gap. To address higher-order signals more directly, we will add probing experiments for syntactic dependency frequencies and discourse marker usage in the revised manuscript, confirming they exhibit comparable layer-wise availability patterns independent of scorer choice. revision: yes
-
Referee: [Causal intervention experiments] The causal-intervention results that isolate the scorer's effect on consolidation location require explicit specification of the intervention protocol, the exact layers tested, the control conditions, and any statistical tests for significance. Without these details it is difficult to assess whether post-hoc choices or incomplete controls affect the layer-wise conclusions.
Authors: We accept that the current description lacks sufficient detail on the experimental protocol. In the revision we will add a dedicated subsection specifying the full intervention protocol (activation replacement with neutral baselines derived from non-authorship examples), the exact layers tested (0 through 11), the control conditions (random neuron interventions and shuffled-label baselines), and the statistical tests (paired t-tests with Bonferroni correction, all key layer differences significant at p < 0.01). revision: yes
Circularity Check
Derivation relies on independent causal interventions and gradient analysis rather than self-referential fitting.
full rationale
The paper establishes that stylistic features are available at every layer through direct measurement in an off-the-shelf control encoder, providing an empirical basis independent of the model's fine-tuned performance. The consolidation location is then attributed to the scorer via causal interventions and derived from the gradient structure of mean pooling versus late interaction, along with observed training dynamics. These steps form a self-contained chain that does not reduce the final claims back to the input performance numbers or require self-citation for uniqueness. The analysis appears to use external benchmarks like the control encoder to rule out representation quality differences.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stylistic features remain equally detectable across layers in an untrained control encoder
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The scorer term determines how that gradient distributes across individual tokens... Mean pooling: dense, uniform gradient... MaxSim: sparse, selective gradient.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Same Author or Just Same Topic? Towards Content-Independent Style Representations , shorttitle =
Wegmann, Anna and Schraagen, Marijn and Nguyen, Dong , editor =. Same Author or Just Same Topic? Towards Content-Independent Style Representations , shorttitle =. Proceedings of the 7th Workshop on Representation Learning for NLP , publisher =. 2022 , pages =. doi:10.18653/v1/2022.repl4nlp-1.26 , urldate =
-
[2]
IDIOLEX: Unified and Continuous Representations for Idiolectal and Stylistic Variation
Kantharuban, Anjali and Srivastava, Aarohi and Faisal, Fahim and Ahia, Orevaoghene and Anastasopoulos, Antonios and Chiang, David and Tsvetkov, Yulia and Neubig, Graham , month = apr, year =. doi:10.48550/arXiv.2604.04704 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04704
-
[3]
Whodunit? Learning to Contrast for Authorship Attribution , shorttitle =
Ai, Bo and Wang, Yuchen and Tan, Yugin and Tan, Samson , editor =. Whodunit? Learning to Contrast for Authorship Attribution , shorttitle =. Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing, Volume 1: Long Papers , publi...
-
[4]
Isolating Authorship from Content with Semantic Embeddings and Contrastive Learning , url =
Huertas-Tato, Javier and Gir. Isolating Authorship from Content with Semantic Embeddings and Contrastive Learning , url =. 2024 , note =. doi:10.48550/arXiv.2411.18472 , urldate =
-
[5]
Khattab, Omar and Zaharia, Matei , month = jul, year =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , publisher =. doi:10.1145/3397271.3401075 , urldate =
-
[6]
Localizing Model Behavior with Path Patching
Goldowsky-Dill, Nicholas and MacLeod, Chris and Sato, Lucas and Arora, Aryaman , month = may, year =. Localizing. doi:10.48550/arXiv.2304.05969 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.05969
-
[7]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[8]
Zhang, Fred and Nanda, Neel , month = oct, year =. Towards
-
[9]
5th International Conference on Learning Representations,
Guillaume Alain and Yoshua Bengio , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[10]
Belinkov, Yonatan , month = mar, year =. Probing. Computational Linguistics , publisher =. doi:10.1162/coli_a_00422 , abstract =
work page internal anchor Pith review doi:10.1162/coli_a_00422
-
[11]
What Does BERT Learn about the Structure of Language?
Jawahar, Ganesh and Sagot, Beno \^i t and Seddah, Djam \'e. What Does BERT Learn about the Structure of Language?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1356
-
[12]
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
work page 2019
-
[13]
and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y
Rivera-Soto, Rafael A. and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y. and Khan, Aleem and Bishop, Marcus and Andrews, Nicholas , editor =. Learning Universal Authorship Representations , url =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , publisher =. 2021 , pages =. doi:10.18653/v1/2021.emn...
-
[14]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Wang, Tongzhou and Isola, Phillip , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[15]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , month = nov, year =. Locating and editing factual associations in. Proceedings of the 36th
-
[16]
BERT Rediscovers the Classical NLP Pipeline
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie. BERT Rediscovers the Classical NLP Pipeline. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1452
-
[17]
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers , month = jul, year =. doi:10.18653/v1/2025.acl-long.127 , pages =
-
[18]
Designing and Interpreting Probes with Control Tasks
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[19]
Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?
Ravichander, Abhilasha and Belinkov, Yonatan and Hovy, Eduard. Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.295
-
[20]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
work page 2023
-
[21]
Literary and Linguistic Computing , author =
Delta: A Measure of Stylistic Difference and a Guide to Likely Authorship , volume =. Literary and Linguistic Computing , author =. 2002 , pages =. doi:10.1093/llc/17.3.267 , number =
-
[22]
AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs , volume =
Effects of Age and Gender on Blogging , author =. AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs , volume =
-
[23]
Wegmann, Anna and Nguyen, Dong , editor =. Does It Capture. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , publisher =. 2021 , pages =. doi:10.18653/v1/2021.emnlp-main.569 , urldate =
-
[24]
Layered Insights: Generalizable Analysis of Human Authorial Style by Leveraging All Transformer Layers , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.521 , pages =
-
[25]
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Alshomary, Milad and Ri, Narutatsu and Apidianaki, Marianna and Patel, Ajay and Muresan, Smaranda and McKeown, Kathleen. Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[26]
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author =. 2024 , eprint =
work page 2024
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , year =. 1907.11692 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
International Conference on Learning Representations , year=
DeBERTA: Decoding-Enhanced BERT with Disentangled Attention , author=. International Conference on Learning Representations , year=
-
[29]
Proceedings on Privacy Enhancing Technologies , author =
Git Blame Who? Stylistic Authorship Attribution of Small, Incomplete Source Code Fragments , volume =. Proceedings on Privacy Enhancing Technologies , author =. 2019 , pages =. doi:10.2478/popets-2019-0053 , number =
-
[30]
Cafiero, Florian and Camps, Jean-Baptiste , title =. Science Advances , volume =. 2019 , doi =
work page 2019
-
[31]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[32]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , editor =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1: Long and Short Papers , publisher =. 2019 , pages =. doi:10.18653/v1/N19-1423 , urldate =
-
[33]
HALvest-Contrastive: Retrieval-Like Authorship Attribution with Patch-Level Late Interaction , author=. 2025 , eprint=
work page 2025
-
[34]
Journal of the American Statistical Association , volume=
Inference in an authorship problem: A comparative study of discrimination methods applied to the authorship of the disputed Federalist Papers , author=. Journal of the American Statistical Association , volume=. 1963 , publisher=
work page 1963
-
[35]
N-Gram-Based Author Profiles for Authorship Attribution , booktitle =
Ke. N-Gram-Based Author Profiles for Authorship Attribution , booktitle =. 2003 , pages =
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.