RoHIL: Robust Human-in-the-Loop Robotic Reinforcement Learning Against Illumination Variations
Pith reviewed 2026-05-20 05:04 UTC · model grok-4.3
The pith
RoHIL adapts human-in-the-loop robot reinforcement learning to illumination changes without new real data or forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
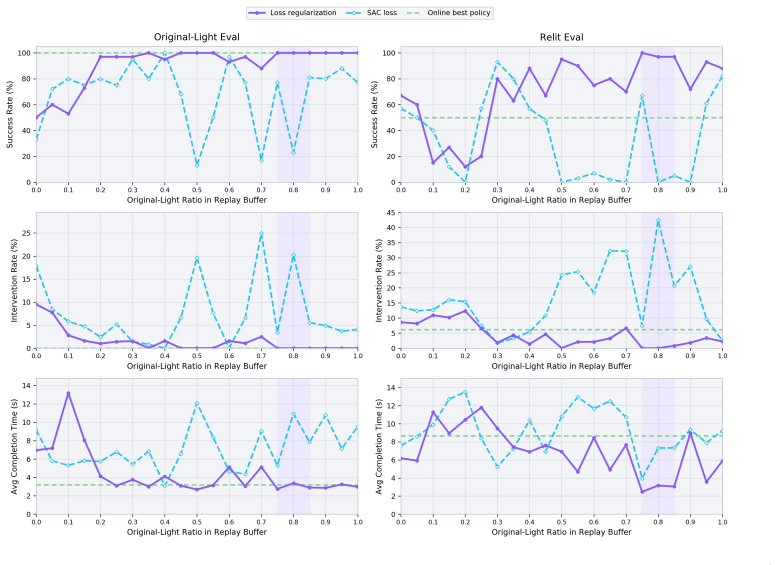
RoHIL combines a world-model-based image relighter that re-synthesizes source trajectories under virtual HDRI environments while keeping actions and rewards unchanged, Illumination-Retention Replay to interleave relit and original transitions for preserving Bellman coverage, and an anchored Bellman-actor regulariser to constrain drift, resulting in improved performance on shifted lighting tasks while maintaining source performance.
What carries the argument
The combination of image relighting via world model, illumination-retention replay, and anchored regularization that allows offline adaptation to lighting shifts.
If this is right
- Performance on new workstations with different illumination improves substantially compared to standard methods that collapse.
- Original workstation performance is preserved after adaptation.
- No extra real-robot interactions are required for the fine-tuning process.
- Robots can be moved between workstations without re-collecting data and retraining each time.
Where Pith is reading between the lines
- Similar techniques might apply to other visual domain shifts such as changes in background or object appearance.
- Extending the relighting to dynamic lighting changes during operation could further enhance robustness.
- Integration with other sim-to-real methods could broaden applicability in varied environments.
Load-bearing premise
The world-model-based image relighter can accurately re-synthesize the visual stream of source trajectories under new illumination conditions without changing the actions or rewards.
What would settle it
Running the adapted policy on a new workstation with altered lighting and observing no improvement over the baseline or a drop in original performance would disprove the claim.
Figures







read the original abstract
Human-in-the-loop reinforcement learning systems achieve near-perfect success on the workstation where they are trained, but collapse when the same robot is moved to a workstation a few meters away due to shifts in the visual input distribution caused by new lamp positions and window light. Re-collecting demonstrations and re-running HIL on every workstation is incompatible with deployment, and naively fine-tuning on shifted-light data triggers catastrophic forgetting of the source workstation. To close this cross-domain gap, we present RoHIL, an offline fine-tuning framework that uses no extra real-robot interaction. RoHIL combines (i) a world-model-based image relighter that re-synthesises the visual stream of source-workstation trajectories under multiple virtual HDRI environments, leaving actions and rewards real; (ii) Illumination-Retention Replay (IRR), a data-level anti-forgetting mechanism that interleaves relit adaptation transitions with original-light retention transitions to preserve source-workstation Bellman coverage; and (iii) an anchored Bellman-actor regulariser that constrains representation and policy drift from the original source-workstation policy. Across four real-robot manipulation tasks under significant cross-workstation illumination variations, RoHIL substantially improves shifted-light performance where standard HIL-RL collapses, while preserving source-workstation performance, eliminating the need to re-collect data and retrain for every new workstation and environment. Project page: https://anonymous4365.github.io/RoHIL/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RoHIL, an offline fine-tuning framework for human-in-the-loop (HIL) robotic reinforcement learning to handle cross-workstation illumination variations. It integrates (i) a world-model-based image relighter that re-synthesizes source trajectories under virtual HDRI environments while keeping actions and rewards unchanged, (ii) Illumination-Retention Replay (IRR) that interleaves relit and original-light transitions to preserve Bellman coverage, and (iii) an anchored Bellman-actor regulariser to limit policy drift. The central claim is that RoHIL substantially improves shifted-light performance on four real-robot manipulation tasks where standard HIL-RL fails, while retaining source-workstation performance without additional real-robot data collection or retraining.
Significance. If the results and relighter fidelity hold, the work would address a practical barrier to real-world robotic RL deployment by enabling policies to generalize across lighting conditions without repeated human demonstrations. The combination of data-level retention and representation anchoring is a concrete contribution to mitigating catastrophic forgetting in offline adaptation settings.
major comments (2)
- [Abstract (component (i) description)] Abstract, paragraph on component (i): the claim that the world-model relighter produces images sufficiently close to real target-workstation illumination distributions (while leaving actions/rewards real) is load-bearing for the generalization result, yet no quantitative validation (FID, LPIPS, or lighting-error metrics) comparing relit source trajectories to actual images captured at the target workstation is referenced. Without this, it remains possible that gains derive primarily from IRR and the regulariser rather than accurate relighting of geometry-dependent effects such as shadows and specularities.
- [Abstract] Abstract: the statement of 'substantial improvements' across four tasks supplies no numerical results, baselines, error bars, or ablation details. This makes it impossible to assess effect size, statistical significance, or whether the cross-workstation claim is supported by the data.
minor comments (1)
- The abstract and project page link are useful, but the manuscript would benefit from an explicit statement of the world-model architecture and training procedure for the relighter in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and outline revisions that will strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Abstract (component (i) description)] Abstract, paragraph on component (i): the claim that the world-model relighter produces images sufficiently close to real target-workstation illumination distributions (while leaving actions/rewards real) is load-bearing for the generalization result, yet no quantitative validation (FID, LPIPS, or lighting-error metrics) comparing relit source trajectories to actual images captured at the target workstation is referenced. Without this, it remains possible that gains derive primarily from IRR and the regulariser rather than accurate relighting of geometry-dependent effects such as shadows and specularities.
Authors: We agree that quantitative validation of the relighter would more directly support the claim and help isolate its contribution from IRR and the regulariser. The current manuscript presents qualitative image comparisons and relies on end-to-end task performance plus ablations to demonstrate utility. In the revision we will add FID and LPIPS metrics computed between relit source images and real images captured at the target workstation, along with a brief discussion of limitations in modeling complex geometry-dependent effects such as shadows and specularities. These additions will clarify the relighter's role while preserving the paper's focus on the combined framework. revision: yes
-
Referee: [Abstract] Abstract: the statement of 'substantial improvements' across four tasks supplies no numerical results, baselines, error bars, or ablation details. This makes it impossible to assess effect size, statistical significance, or whether the cross-workstation claim is supported by the data.
Authors: We concur that the abstract would be more informative with concrete numbers. In the revised abstract we will include representative success rates (with standard deviations across runs) for RoHIL versus standard HIL-RL and other baselines on the four tasks under shifted illumination, while retaining the high-level summary of the method and contributions. revision: yes
Circularity Check
No significant circularity; framework components are additive and externally grounded
full rationale
The paper presents RoHIL as an offline fine-tuning framework that combines three distinct components: a world-model-based image relighter that re-synthesises source trajectories under virtual HDRI environments while leaving actions and rewards unchanged, Illumination-Retention Replay (IRR) that interleaves relit and original transitions, and an anchored Bellman-actor regulariser that constrains policy drift. These are described as modular additions with grounding in existing world models and standard RL replay mechanisms rather than any self-referential definitions or fitted parameters renamed as predictions. No equations or derivations in the abstract reduce the claimed cross-workstation gains to inputs by construction, and the central claims rest on empirical comparisons to standard HIL-RL rather than self-citation chains or ansatzes smuggled from prior author work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A world model trained on source data can generate accurate relit images under new HDRI lighting while leaving actions and rewards unchanged.
- domain assumption Interleaving relit adaptation transitions with original-light retention transitions preserves source-workstation Bellman coverage.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RoHIL combines (i) a world-model-based image relighter that re-synthesises the visual stream of source-workstation trajectories under multiple virtual HDRI environments, leaving actions and rewards real; (ii) Illumination-Retention Replay (IRR)...; and (iii) an anchored Bellman–actor regulariser...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hassan Abu Alhaija and NVIDIA. Cosmos-Transfer1: Conditional world generation with adaptive multimodal control.arXiv preprint arXiv:2503.14492,
-
[2]
Ankile, L., Simeonov, A., Shenfeld, I., and Agrawal, P
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement: Residual RL for precise visual assembly. InarXiv preprint arXiv:2407.16677,
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023a. Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chel...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2023.xix.025 2023
-
[6]
doi: 10.15607/RSS.2025.XXI.019. Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11),
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion
doi: 10.1177/02783649241273668. Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1861–1870,
-
[8]
12 Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang. UniRelight: Learning joint decom- position and synthesis for video relighting.arXiv preprint arXiv:2506.15673,
-
[9]
Sheng Jin, Lu Wang, Benedikt Temming, and Florian T
doi: 10.15607/RSS.2024.XX.056. Sheng Jin, Lu Wang, Benedikt Temming, and Florian T. Pokorny. Physically-based lighting generation for robotic manipulation.arXiv preprint arXiv:2508.01442,
-
[10]
doi: 10.1109/ICRA.2019.8793698. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model.ar...
-
[11]
doi: 10.1109/TPAMI.2017.2773081. Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, and Zian Wang. DiffusionRenderer: Neural inverse and forward rendering with video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[12]
Lumos: Learning visual generative priors without text.arXiv preprint arXiv:2503.12246, 2025a
Xiao Liu, Bo Yang, Hangjie Liu, Yuyang Zhang, Yuwei Wang, Wencheng Pang, Cuilin Lan, Tao Zhang, and Yu-Gang Jiang. Lumos: Learning visual generative priors without text.arXiv preprint arXiv:2503.12246, 2025a. Yang Liu, Chen Lin, Hanrong Zhao, Wei Yu, Yiqun Du, and Zhitong Tang. TC-Light: Temporally coherent generative relighting.arXiv preprint arXiv:2506....
-
[13]
doi: 10.1126/scirobotics.ads5033. Mitsuhiko Nakamoto, Yuexiang Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. InAdvances in Neural Information Processing Systems 36,
-
[14]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration. Open X-Embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. iCaRL: Incremental classifier and representation learning. InIEEE Conference on Computer Vision and Pattern Recognition, pages 2001–2010,
work page 2001
-
[17]
doi: 10.1109/CVPR.2017.587. Allen Z. Ren, Justin Lidard, Lars Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization. In International Conference on Learning Representations,
-
[18]
Domain random- ization for transferring deep neural networks from simu- lation to the real world
doi: 10.1109/IROS.2017.8202133. Charles Xu, Qiyang Li, Jianlan Luo, and Sergey Levine. RLDG: Robotic generalist policy distillation via reinforcement learning. InRobotics: Science and Systems XXI,
-
[19]
Jianqi Yang, Linsen Wang, Yikai Du, Hao Du, Mingkai Zhao, Sheng Liu, Wei Wang, and Cihang Yang. Lumen: Consistent video relighting and harmonious background replacement.arXiv preprint arXiv:2508.12945,
-
[20]
Lvmin Zhang and Maneesh Agrawala. IC-Light: Imposing consistent light.Software project page, 2024.https://github.com/lllyasviel/IC-Light. Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems XIX,
work page 2024
-
[21]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
doi: 10.15607/RSS.2023.XIX.016. Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforce- ment learning fine-tuning need not retain offline data. InInternational Conference on Learning Representations,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.