What Are LLMs Doing to Scientific Communication? Measuring Changes in Writing Practices and Reading Experience
Pith reviewed 2026-05-20 06:02 UTC · model grok-4.3
The pith
LLM-assisted writing in NLP papers shifts toward complex syntax, longer words, reduced lexical diversity, and higher expert ratings for understandability and excitement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Growing LLM adoption in the writing process produces measurable changes in NLP papers, including more frequent use of particular syntactic constructions, increased word complexity and length, decreased lexical diversity, and improved subjective ratings for understandability and excitement from domain experts.
What carries the argument
Diachronic lexical analysis combined with stylistic feature modeling applied to the ACL Anthology corpus and a paired human-LLM passage dataset.
If this is right
- Word usage contexts evolve with some terms becoming more specialized and others more general over the 2020-2024 period.
- LLM-modified texts display higher rates of certain syntactic constructions alongside lower lexical diversity.
- Domain experts rate LLM-improved passages as more understandable and exciting than their human-written originals.
- Negative expert attitudes toward LLMs coexist with positive assessments of the resulting text qualities.
Where Pith is reading between the lines
- Continued trends could lead to greater homogenization of scientific prose across the field while improving accessibility.
- The subjective boost in reading experience may encourage wider LLM adoption even among those with reservations.
- Similar stylistic and reception shifts could emerge in other scientific domains once comparable corpora become available.
Load-bearing premise
The measured changes in lexical and stylistic features stem primarily from rising LLM adoption instead of shifts in research topics, author demographics, or conference standards.
What would settle it
A controlled comparison of writing features in papers by the same authors before and after documented LLM adoption, or direct correlation of self-reported LLM usage with text metrics.
Figures


read the original abstract
Has the style of scientific communication changed due to the growing use of large language models in the writing process? We address this question in the domain of Natural Language Processing by leveraging two data resources we create: a naturalistic corpus of over 37,000 papers from the ACL Anthology (2020-2024); and a synthetic dataset of 3,000 human-written passages and their LLM-generated improvements. We first implement a series of diachronic lexical analyses, showing that both word frequency and usage contexts have changed significantly over time, indicating semantic specialization in some cases and generalization in others. Broadening our perspective, we then model a range of more complex stylistic features and find that LLM-modified texts more frequently contain certain syntactic constructions, more complex and longer words and a lower lexical diversity. Finally, we connect these changes in writing practices to subjective reading experience through a pilot annotation study with 20 domain experts. They overall rate LLM-improved texts as more understandable and exciting, but also express negative qualitative attitudes towards LLMs, highlighting the strongly subjective effect of AI-assisted writing on reading experience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs are altering scientific writing in NLP, evidenced by diachronic shifts in a corpus of >37k ACL papers (2020-2024) showing changes in word frequency, contexts, syntactic constructions, word complexity, and reduced lexical diversity; these are linked to LLM use via a synthetic dataset of 3k human vs. LLM-improved passages, and a pilot expert annotation (n=20) finds LLM-modified texts rated more understandable and exciting despite negative attitudes toward AI assistance.
Significance. If the causal attribution can be strengthened, this would be a timely contribution documenting LLM effects on scientific communication, with credit due for the large naturalistic ACL corpus, the synthetic human-LLM pairs enabling controlled comparisons, and the expert annotation connecting style to reading experience. These resources support reproducible follow-up work on AI-assisted writing.
major comments (2)
- [Diachronic analyses and stylistic feature modeling] Diachronic lexical and stylistic analyses (as described in the abstract and methods): observed increases in complex syntax, longer words, and lower lexical diversity are presented as LLM-driven, yet no stratification, matching, or regression controls for concurrent topic drift (e.g., rising LLM/scaling papers), author demographics, or conference norms are reported; this directly undermines the causal step from correlation to LLM adoption as the primary driver.
- [Synthetic dataset and results] Synthetic dataset construction and connection to observational trends: while the human-vs-LLM pairs establish that models can generate the reported features, the manuscript does not use them to quantify how much of the 2020-2024 ACL corpus shifts are explained by LLM adoption versus other factors, leaving the central claim only partially grounded.
minor comments (2)
- [Abstract and annotation study] Abstract and pilot study description: inter-annotator agreement statistics for the 20-expert ratings are not reported, and the exact rating scales or qualitative prompts used to elicit 'more understandable and exciting' judgments should be specified for interpretability.
- [Methods] Notation and presentation: clarify how 'lexical diversity' and 'syntactic constructions' are operationalized (e.g., specific metrics or parsers) to aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important considerations for strengthening the interpretation of our observational findings. We address each major comment below and outline targeted revisions to clarify the role of the synthetic dataset and discuss potential confounds.
read point-by-point responses
-
Referee: [Diachronic analyses and stylistic feature modeling] Diachronic lexical and stylistic analyses (as described in the abstract and methods): observed increases in complex syntax, longer words, and lower lexical diversity are presented as LLM-driven, yet no stratification, matching, or regression controls for concurrent topic drift (e.g., rising LLM/scaling papers), author demographics, or conference norms are reported; this directly undermines the causal step from correlation to LLM adoption as the primary driver.
Authors: We agree that the diachronic analyses are observational and that the absence of explicit controls for topic drift, author demographics, or conference norms limits strong causal claims. The manuscript positions the synthetic dataset as complementary evidence showing that LLM modifications can produce the observed features under controlled conditions. In revision, we will add a new subsection in the discussion that explicitly addresses alternative explanations, including topic shifts toward LLM-related content, and perform a post-hoc stratification of stylistic trends within major ACL sub-areas (e.g., machine translation vs. semantics) to partially mitigate topic drift concerns. We will also expand the limitations section to note that author-level metadata for demographics is not available in the ACL Anthology and that conference norms may co-vary with LLM adoption. revision: partial
-
Referee: [Synthetic dataset and results] Synthetic dataset construction and connection to observational trends: while the human-vs-LLM pairs establish that models can generate the reported features, the manuscript does not use them to quantify how much of the 2020-2024 ACL corpus shifts are explained by LLM adoption versus other factors, leaving the central claim only partially grounded.
Authors: The synthetic dataset is designed to provide controlled evidence that the stylistic changes identified diachronically are consistent with LLM-assisted writing rather than to decompose the exact variance explained by LLM use. Quantifying the precise contribution would require reliable per-paper adoption rates or instrumentation data that are not available for the 37k ACL papers. We will revise the methods and discussion sections to more precisely delineate the inferential role of the synthetic pairs and to outline why a full attribution analysis is beyond the current scope, while suggesting directions for future work that could combine adoption surveys with the existing resources. revision: yes
Circularity Check
No significant circularity: analyses rest on newly constructed external corpora and independent expert ratings
full rationale
The paper constructs a new naturalistic corpus of ACL Anthology papers (2020-2024) and a separate synthetic dataset of human-written passages paired with LLM improvements. Diachronic lexical and stylistic analyses, plus the pilot annotation study with 20 experts, operate directly on these resources without any equations, fitted parameters, or predictions that reduce to quantities defined inside the same dataset. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation chain is self-contained against the collected data and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal changes in word frequency, context, and stylistic features in the 2020-2024 ACL corpus are primarily caused by increasing LLM adoption rather than other evolving factors.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first implement a series of diachronic lexical analyses... model a range of more complex stylistic features... pilot annotation study with 20 domain experts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Data We now present our two English-language data re- sources: a naturalistic corpus of NLP papers from the ACL Anthology (henceforthoriginaldataset); and a synthetic dataset of human-written passages and their LLM-generated improvements (hence- forthLLMdataset). 3.1. ACL Anthology Corpus Since the focus of our work is on scientific com- munication in the...
work page 2023
-
[2]
Thefirsttimeperiod( t1)containspaperspub- lished from 2020 to 2022. Its last major conference event is EMNLP 2022, which had a camera-ready deadline in October of that year. The second time period( t2)containspaperspublishedinthesecond half of 2023 and in 2024. It begins with ACL 2023, whose camera-ready deadline was in May of that year, i.e., six months ...
work page 2020
-
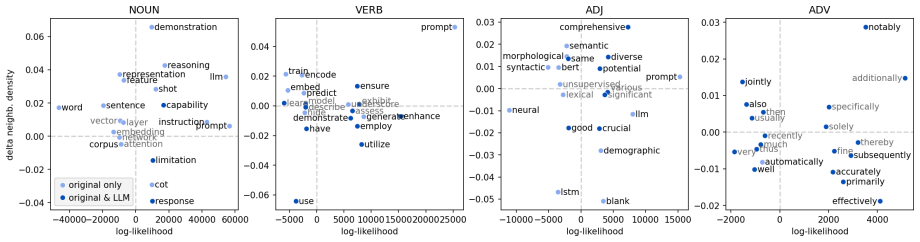
[3]
Characterizing Writing Changes via Lexical Choices We begin by addressingRQ1: Are there core lin- guisticchoiceswhichchangedbetween t1 and t2 in connection with LLM use? Focusing on the lexical level, we identify words with strongest changes in rates of use and then characterize them in terms of finer-grained patterns of semantic change. 4.1. Experimental...
work page 2000
-
[4]
Predicting Time Periods from Complex Linguistic Features Inthefollowingsection, weaddressRQ2: arethere systematic stylistic differences betweent1 and t2 thatcouldbeattributedtotheuseofLLMsaswriting assistants? 5.1. Experimental Setup We apply logistic regression as an analysis tool to find the linguistic markers that significantly con- tribute to explaini...
work page 2026
-
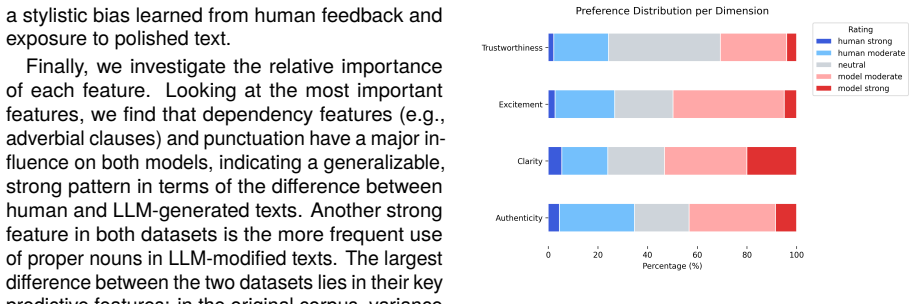
[5]
Measuring Reading Experience While prior research has examined lexical and stylistic differences between human- and LLM- generated texts, little is known about how readers perceive these changes. To address this gap, we conducted a pilot study to assess human percep- tion of human-only and LLM-modified texts (RQ3). To gain insights on that question, we lo...
work page 2019
-
[6]
Conclusion In this work, we investigated the influence of LLMs on writing style in scientific communication, specif- ically in the NLP domain. We relied on two data scenarios: a naturalistic corpus of over 37,000 sci- entific papers published in the two years preceding vs. following the release of ChatGPT, and a syn- thetic dataset of 3,000 human-written ...
-
[7]
First, our analysis is framed as a binary comparison of lan- guage use across two time periods
Limitations We note several limitations of our work. First, our analysis is framed as a binary comparison of lan- guage use across two time periods. This approach hasimportantpracticalbenefitsandisunderpinned by clearly stated assumptions (e.g., uncertainty re- garding the precise degree of LLM use in the sec- ond time period). However, a finer-grained co...
-
[8]
Acknowledgments We are grateful to our 20 volunteer annotators for the time and effort they put into this study. Filip Miletić was supported by DFG Research Grant SCHU 2580/5-2 (Computational Models of Se- mantic Variation in Multi-Word Expressions across Speakers and Languages)
-
[9]
Bibliographical References Mayowa Akinwande, Oluwaseyi Adeliyi, and Toyy- ibat Yussuph. 2024. Decoding ai and human authorship: Nuances revealed through nlp and statistical analysis.International Journal on Cy- bernetics & Informatics, 13(4):85–103. Yutian Chen, Hao Kang, Vivian Zhai, Liangze Li, Rita Singh, and Bhiksha Raj. 2023. Token pre- diction as im...
-
[10]
InJADT 2004 : 7es Journées internationales d’Analyse statistique des Données Textuelles
Extending the cochran rule for the com- parison of word frequencies between corpora. InJADT 2004 : 7es Journées internationales d’Analyse statistique des Données Textuelles. PaulRaysonandRogerGarside.2000. Comparing corpora using frequency profiling. InThe Work- shop on Comparing Corpora, pages 1–6, Hong Kong, China. Association for Computational Lin- gui...
work page 2004
-
[11]
Automaticauthorshipanalysisinhuman-AI collaborative writing. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), pages 1845–1855, Torino, Italia. ELRA and ICCL. Shaurya Rohatgi, Yanxia Qin, Benjamin Aw, Ni- ranjana Unnithan, and Min-Yen Kan. 2023. The ACL OCL corpus...
work page 2024
-
[12]
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 5342–5373, Vienna, Austria. Association for Computational Linguistics. Eyal Sagi, Stefan Kaufmann, and Brady Clark
-
[13]
Semantic density analysis: Comparing word meaning across time and phonetic space. InProceedings of the Workshop on Geometrical Models of Natural Language Semantics, pages 104–111, Athens, Greece. Association for Com- putational Linguistics. DominikSchlechtweg.2023.HumanandComputa- tional Measurement of Lexical Semantic Change. Stuttgart, Germany. Zhixiong...
work page 2023
-
[14]
Survey of computational approaches to lexical semantic change. In Nina Tahmasebi, Lars Borin, Adam Jatowt, Yang Xu, and Simon Hengchen, editors,Computational Approaches to Semantic Change, pages 1–91. Language Science Press, Berlin. Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Chenxi Whitehouse, Osama Mohammed Afza...
work page 2024
-
[15]
Olga Zamaraeva, Dan Flickinger, Francis Bond, and Carlos Gómez-Rodríguez
A comparison of human-written versus AI- generated text in discussions at educational set- tings: Investigating features for ChatGPT, Gem- ini and BingAI.European Journal of Education, 60(1). Olga Zamaraeva, Dan Flickinger, Francis Bond, and Carlos Gómez-Rodríguez. 2025. Compar- ing LLM-generated and human-authored news textusingformalsyntactictheory. InP...
-
[16]
are more frequent int1. Those concerned with LLMs (13, 54) and more recent methods such as reinforcementlearning(62)aremoreprevalentin t2. Butbeyondtheseratherintuitivedifferences,39out of 70 topics (62% of all papers) have a broadly bal- anced temporal distribution (normalized proportion of papers from the dominant time period≤60%). Together with the fac...
work page 2022
- [17]
- [18]
-
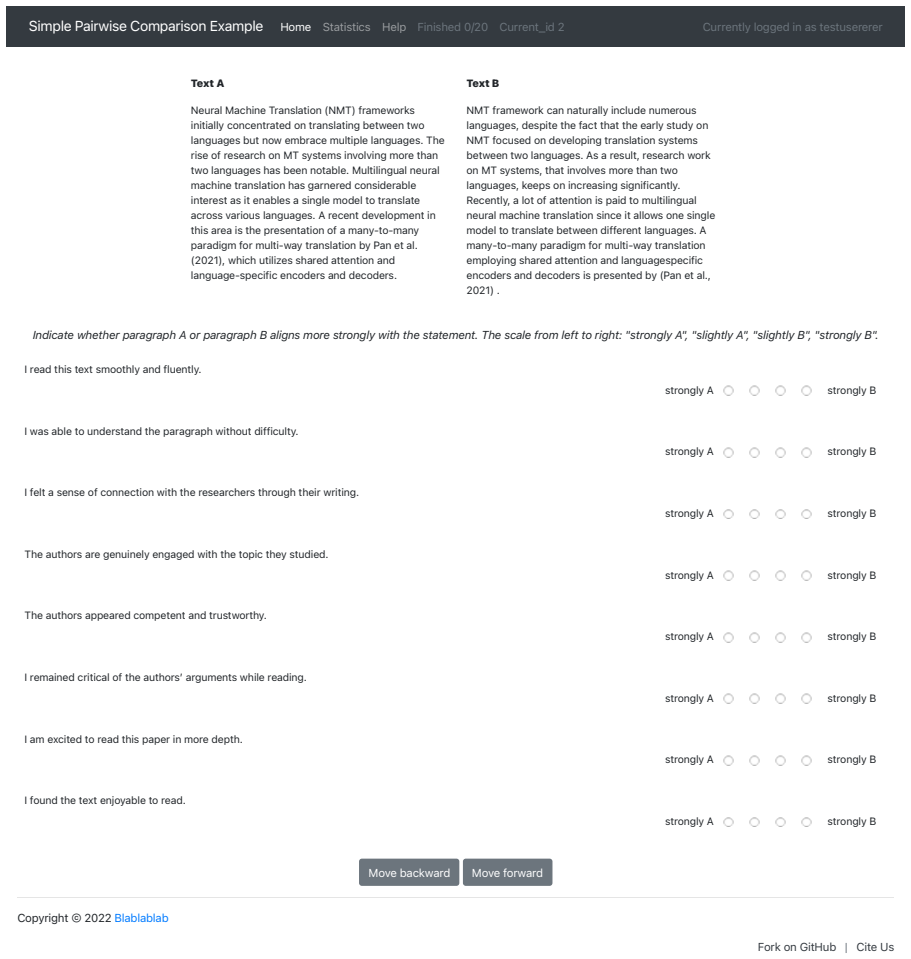
[19]
Provide broad background information on your education, language use, and writing practices (ca. 1 minute) In step 2, you will be shown 20 pairs of short texts taken from scientific papers. In a given pair, both texts intend to convey the same message, but they are written in different ways. You will be shown several statements and decide which of the two...
work page 2022
-
[20]
I was able to understand the paragraph without difficulty
I read this text smoothly and fluently. I was able to understand the paragraph without difficulty. I felt a sense of connection with the researchers through their writing. The authors are genuinely engaged with the topic they studied. The authors appeared competent and trustworthy. I remained critical of the authors’ arguments while reading. I am excited ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.