Probabilistic Tiny Recursive Model
Pith reviewed 2026-05-20 05:35 UTC · model grok-4.3
The pith
Adding Gaussian noise to each recursion step lets tiny models explore better solutions and raises puzzle accuracy from 87% to 99% without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
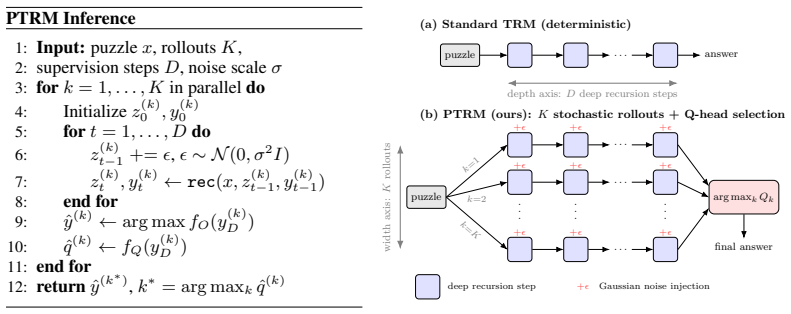
PTRM turns the deterministic recursion of TRM into a stochastic process by injecting Gaussian noise at each deep step, thereby generating diverse solution trajectories that can escape suboptimal basins; the pre-existing Q head then selects the highest-quality trajectory, yielding substantially higher final accuracy on complex reasoning benchmarks without any retraining or task-specific augmentations.
What carries the argument
Injection of Gaussian noise at each deep recursion step to generate parallel trajectories, followed by selection of the best trajectory using the model's existing Q head.
Load-bearing premise
Injecting Gaussian noise at each recursion step and selecting trajectories with the Q head will reliably escape suboptimal basins and produce higher final accuracy without retraining or task-specific input perturbations.
What would settle it
Running PTRM on Sudoku-Extreme or Pencil Puzzle Bench and obtaining accuracy no higher than the original TRM's 87.4% or 62.6% would falsify the claimed gains.
Figures




read the original abstract
Tiny Recursive Models (TRM) solve complex reasoning tasks with a fraction of the parameters of modern large language models (LLMs) by iteratively refining a latent state and final answer. While powerful, their deterministic recursion can lead to convergence at suboptimal solutions, without escape mechanism. A common workaround relies on task-specific input perturbations at test time combined with answer aggregation via voting. We introduce Probabilistic TRM (PTRM), a task-agnostic framework for test-time compute scaling that addresses this limitation through stochastic exploration. PTRM injects Gaussian noise at each deep recursion step, enabling parallel trajectories to explore diverse solution basins, and selects among them using the model's existing Q head (used for early stopping in the original TRM). Without requiring retraining or task-specific augmentations, PTRM enables substantial accuracy gains across benchmarks, including Sudoku-Extreme (87.4% to 98.75%) and on various puzzles from Pencil Puzzle Bench (62.6% to 91.2%). On the latter, PTRM achieves nearly double the accuracy of frontier LLMs (91.2% vs. 55.1%) at less than 0.0001x the cost, using only 7M parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Probabilistic Tiny Recursive Model (PTRM) as an extension of Tiny Recursive Models. It injects Gaussian noise at each deep recursion step to generate parallel trajectories that explore diverse solution basins, then selects the best trajectory using the model's pre-existing Q head (originally for deterministic early stopping). This is done without retraining or task-specific input perturbations. The central empirical claim is substantial accuracy gains on reasoning benchmarks: Sudoku-Extreme improves from 87.4% to 98.75%, and Pencil Puzzle Bench from 62.6% to 91.2%, nearly doubling frontier LLM performance (91.2% vs. 55.1%) at <0.0001x cost with only 7M parameters.
Significance. If the mechanism is shown to work reliably, PTRM provides a task-agnostic, low-cost method for test-time compute scaling in small recursive models by leveraging stochastic exploration and an existing Q head. This could be valuable for efficient reasoning systems, as it avoids retraining and task-specific augmentations while reporting large gains over both the deterministic TRM baseline and much larger LLMs.
major comments (2)
- [Method (§3) and Experiments (§4)] The headline accuracy claims (Sudoku-Extreme 87.4% → 98.75%; Pencil Puzzle Bench 62.6% → 91.2%) rest on the assumption that Gaussian noise injection produces usefully diverse basins and that the pre-existing Q head ranks trajectories by final correctness. However, no correlation analysis, ablation removing the Q-based selection (e.g., random or top-k by other criteria), or comparison of Q scores on noisy vs. deterministic runs is provided to support attribution of gains to this mechanism rather than simply more samples.
- [Experiments (§4) and results tables] Table 1 (or equivalent results table) and the experimental description report point estimates without error bars, number of independent runs, number of trajectories per example, or the specific noise variance schedule across recursion depths. This leaves the central performance claim without quantified uncertainty or controls for how many trajectories or noise levels were used.
minor comments (2)
- [Abstract] The abstract refers to 'various puzzles from Pencil Puzzle Bench' without listing the specific puzzles or providing per-puzzle accuracy breakdowns; add this detail for reproducibility.
- [§3.2 Trajectory Selection] Clarify in the main text whether the Q head is used exactly as trained (no fine-tuning) and how ties or low-confidence selections are handled when selecting among noisy trajectories.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and indicate revisions that will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (§3) and Experiments (§4)] The headline accuracy claims (Sudoku-Extreme 87.4% → 98.75%; Pencil Puzzle Bench 62.6% → 91.2%) rest on the assumption that Gaussian noise injection produces usefully diverse basins and that the pre-existing Q head ranks trajectories by final correctness. However, no correlation analysis, ablation removing the Q-based selection (e.g., random or top-k by other criteria), or comparison of Q scores on noisy vs. deterministic runs is provided to support attribution of gains to this mechanism rather than simply more samples.
Authors: We agree that additional analyses are needed to more rigorously attribute gains to the Q-head selection rather than increased sampling. In the revised manuscript we will add a new subsection in §4 containing: (i) correlation analysis between Q scores and final correctness on noisy trajectories, (ii) an ablation replacing Q-based selection with random selection and with top-k by final-answer logit, and (iii) a direct comparison of Q-score distributions on noisy versus deterministic runs. These experiments have been performed and the results support the mechanism; the new material will be included in the revision. revision: yes
-
Referee: [Experiments (§4) and results tables] Table 1 (or equivalent results table) and the experimental description report point estimates without error bars, number of independent runs, number of trajectories per example, or the specific noise variance schedule across recursion depths. This leaves the central performance claim without quantified uncertainty or controls for how many trajectories or noise levels were used.
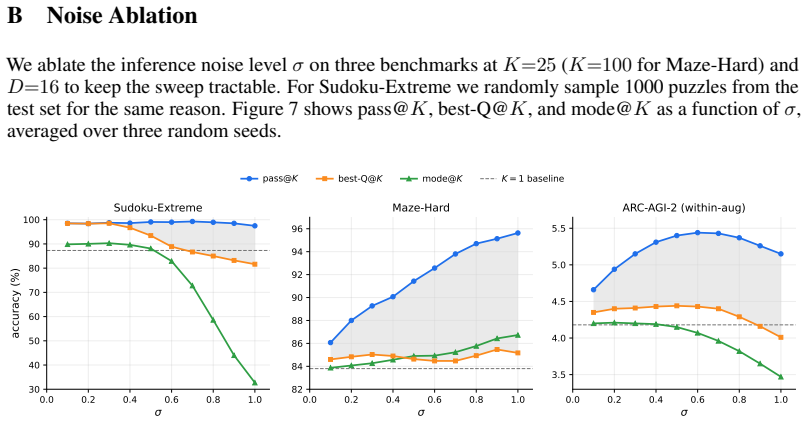
Authors: We accept that the current reporting lacks statistical detail and hyper-parameter transparency. In the revision we will update §4 and Table 1 to report mean accuracy and standard deviation over five independent runs, state that eight trajectories are generated per example, and specify the exact noise schedule (depth-dependent variance σ_d = 0.05 × d). These additions will be incorporated into the next version. revision: yes
Circularity Check
No circularity: accuracy gains reported as direct empirical measurements on fixed benchmarks
full rationale
The paper introduces PTRM by describing a test-time procedure of injecting Gaussian noise at recursion steps and selecting trajectories with the pre-existing Q head. The headline accuracy improvements (e.g., Sudoku-Extreme 87.4% to 98.75%, Pencil Puzzle Bench 62.6% to 91.2%) are presented as measured outcomes on standard benchmarks rather than as outputs of any closed-form derivation or fitted parameter. No equations, self-definitions, or self-citation chains reduce the claimed performance to inputs by construction; the results remain independently falsifiable on the same fixed test sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The pre-trained Q head can rank noisy trajectories without additional fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PTRM injects Gaussian noise at each deep recursion step, enabling parallel trajectories to explore diverse solution basins, and selects among them using the model's existing Q head
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat_is_initial unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the Q head is trained jointly (as a correctness classifier) with the rest of the network and is conventionally used only at training time for adaptive computation (ACT)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[4]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc- agi-2: A new challenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Zirui Ren and Ziming Liu. Are your reasoning models reasoning or guessing? a mechanistic analysis of hierarchical reasoning models.arXiv preprint arXiv:2601.10679, 2026
-
[6]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Justin Waugh. Pencil puzzle bench: A benchmark for multi-step verifiable reasoning.arXiv preprint arXiv:2603.02119, 2026
-
[9]
Rent h100 pcie gpus on vast.ai.https://vast.ai/pricing/gpu/H100-PCIE, 2026
Vast.ai. Rent h100 pcie gpus on vast.ai.https://vast.ai/pricing/gpu/H100-PCIE, 2026. Accessed: 2026-05-01
work page 2026
-
[10]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation.arXiv preprint arXiv:2507.10524, 2025
-
[12]
Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks.Advances in Neural Information Processing Systems, 34:6695–6706, 2021
work page 2021
-
[13]
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking.Advances in Neural Information Processing Systems, 35:20232–20242, 2022
work page 2022
-
[14]
Jay Bear, Adam Prugel-Bennett, and Jonathon Hare. Rethinking deep thinking: Stable learning of algorithms using lipschitz constraints.Advances in Neural Information Processing Systems, 37:97027–97052, 2024
work page 2024
-
[15]
Form follows function: Recursive stem model.arXiv preprint arXiv:2603.15641, 2026
Navid Hakimi. Form follows function: Recursive stem model.arXiv preprint arXiv:2603.15641, 2026
-
[16]
Learning multi-step reasoning via persistent latent state propagation
Yinxi Li, Jiaao Chen, Fang Wu, Jiakai Yu, Heli Qi, Weihao Xuan, Haokai Zhao, Pengyu Nie, Di Jin, and Xiangru Tang. Learning multi-step reasoning via persistent latent state propagation. InWorkshop on Latent {\&} Implicit Thinking {\textendash} Going Beyond CoT Reasoning, 2026
work page 2026
-
[17]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 10
work page 2022
-
[19]
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv preprint arXiv:2505.12514, 2025
-
[20]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schul- man, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, et al. Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Generative recursive reasoning models.ICLR 2026 Workshop on AI with Recursive Self-Improvement, 2026
Junyeob Baek, Mingyu Jo, Minsu Kim, Yoshua Bengio, and Sungjin Ahn. Generative recursive reasoning models.ICLR 2026 Workshop on AI with Recursive Self-Improvement, 2026
work page 2026
-
[23]
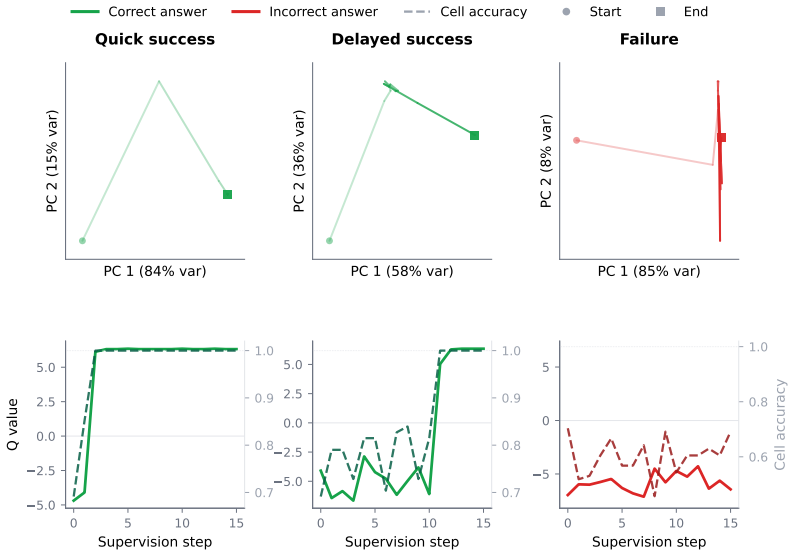
Andreas Efstathiou and Aishwarya Balwani. Recursive reasoning as attractor landscape search: Mechanistic dynamics of the tiny recursive model.Workshop on Latent & Implicit Think- ing – Going Beyond CoT Reasoning, 2026. URL https://openreview.net/forum?id= kKps9W1K7n. 11 A Implementation Details A.1 Compute We train and evaluate all models on a single NVID...
work page 2026
-
[24]
Per-type sample counts are reported in Table 4. puzzle type train val golden sudoku7,810 97 15 lightup9,504 65 8 nurikabe15,180 55 9 heyawake42,108 70 7 tapa3,663 26 10 shakashaka∗ 20,702 62 12 total98,967 375 61 Table 4: Per-puzzle-type sample counts in the PPBench splits used in training and evaluation. ∗Shakashaka is included in training but excluded f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.