Learning Orthonormal Bases for Function Spaces
Pith reviewed 2026-05-20 07:45 UTC · model grok-4.3
The pith
Any target orthonormal basis in function space can be approximated arbitrarily closely by integrating rank-2 skew-adjoint operators generated by a neural network from a reference basis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Even with a rank-2 generator, the integrated solutions of the ODE are dense in the orthogonal group under the appropriate operator topology, so any target orthonormal basis can be approximated arbitrarily closely from a reference basis.
What carries the argument
Finite-rank skew-adjoint generators of ODEs on the Lie manifold of the orthogonal group that produce continuous paths from a reference orthonormal basis to a target basis.
If this is right
- A Fourier basis can be continuously deformed into the principal components of a given functional dataset while remaining orthonormal throughout.
- Eigenfunctions of a linear operator on the function space can be obtained by optimizing the endpoint of such a neural-driven path.
- Dynamic modes of energy-preserving physical simulations can be recovered as the learned basis without explicit mode decomposition.
- The same parameterization supports end-to-end training of basis coefficients together with the generator network for downstream tasks.
Where Pith is reading between the lines
- The density result may allow similar finite-rank control on other infinite-dimensional Lie groups that arise in constrained optimization over function spaces.
- Numerical experiments could test whether low-rank generators require more training steps than higher-rank ones to reach comparable approximation quality.
- The framework could be combined with existing functional data analysis pipelines to replace hand-chosen bases in kernel methods or spectral methods.
Load-bearing premise
Finite-rank skew-adjoint generators produced by neural networks can produce paths whose limits cover the full space of orthonormal bases in the relevant operator topology without requiring infinite-dimensional controls.
What would settle it
An explicit orthonormal basis together with a concrete operator-topology distance such that no sequence of rank-2 neural-generated paths approaches it within that distance.
Figures



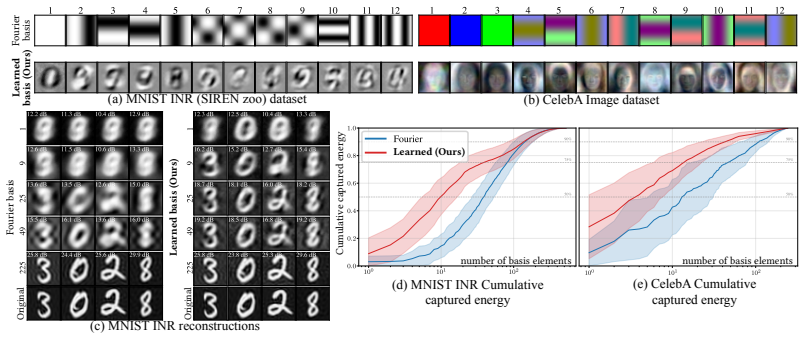
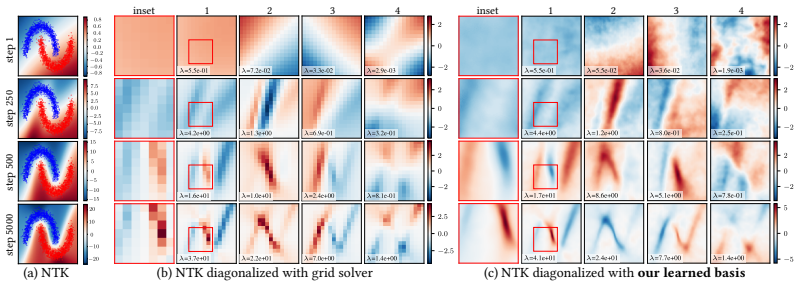
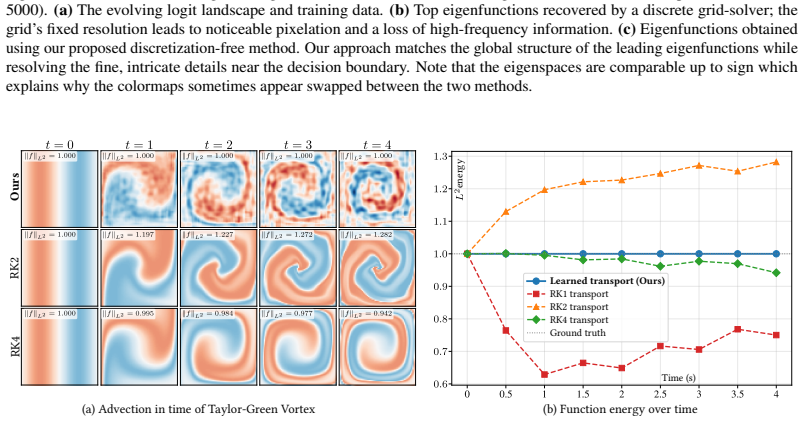





read the original abstract
Infinite-dimensional orthonormal basis expansions play a central role in representing and computing with function spaces due to their favorable linear algebraic properties. However, common bases such as Fourier or wavelets are fixed and do not adapt to the structure of a given problem or dataset. In this paper, we aim to represent these bases with neural networks and optimize them. Our key idea is that any target infinite-dimensional orthonormal basis can be viewed either as a point on the Lie manifold of the orthogonal group, or equivalently, as the endpoint of a continuous path on that manifold that connects a reference basis, e.g. Fourier, to that target. Paths on the Lie manifold satisfy ordinary differential equations (ODEs) governed by skew-adjoint integral operators. Using neural networks to define finite-rank generators of such ODEs allows us to parameterize and optimize orthonormal bases in function space. While relying on finite-rank generators to model infinite operators might seem restrictive, we prove a universality result: even with a rank-2 generator, the integrated solutions of the ODE are dense in the orthogonal group under the appropriate operator topology. In other words, for any target orthonormal basis, there exists a path originating from a reference basis and driven by finite-rank generators that gets arbitrarily close to that target basis. We demonstrate the flexibility of our framework by transforming the Fourier basis into the principal components of a functional dataset, eigenfunctions of linear operators, or dynamic modes of energy-preserving physical simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes parameterizing adaptive orthonormal bases in infinite-dimensional function spaces as endpoints of paths on the orthogonal group, where the paths are solutions to ODEs driven by skew-adjoint generators that are themselves parameterized by neural networks. A central theoretical claim is a universality result: even when the generators are restricted to rank-2 finite-rank operators, the reachable set of integrated flows is dense in the orthogonal group under the strong operator topology. The framework is illustrated by transforming a reference Fourier basis into principal components of functional data, eigenfunctions of linear operators, and dynamic modes of energy-preserving simulations.
Significance. If the density result holds, the approach supplies a principled, optimizable alternative to fixed bases such as Fourier or wavelets, with direct relevance to functional data analysis, operator learning, and structure-preserving scientific machine learning. The grounding in Lie-group controllability theory and the explicit statement that finite-rank controls suffice are strengths that distinguish the work from purely empirical basis adaptation methods.
major comments (1)
- [§4] §4 (Universality result): the proof sketch invokes controllability of the infinite-dimensional orthogonal group by plane rotations in the strong operator topology, but the manuscript does not explicitly address how the neural-network approximation error on the generator accumulates along the flow and whether the density statement remains uniform with respect to that approximation; a quantitative bound linking generator approximation to basis approximation error would strengthen the claim.
minor comments (2)
- [§2] The notation for the skew-adjoint integral operator and its finite-rank truncation should be introduced with a single consistent symbol rather than switching between K(t) and A_N(t) across sections.
- [Figure 2] Figure 2 (basis transformation examples): the caption should state the precise operator topology in which the reported approximation error is measured.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive feedback. We respond to the major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Universality result): the proof sketch invokes controllability of the infinite-dimensional orthogonal group by plane rotations in the strong operator topology, but the manuscript does not explicitly address how the neural-network approximation error on the generator accumulates along the flow and whether the density statement remains uniform with respect to that approximation; a quantitative bound linking generator approximation to basis approximation error would strengthen the claim.
Authors: We appreciate the referee's suggestion to strengthen the universality claim. The proof in §4 establishes that the reachable set using exact rank-2 generators is dense in the orthogonal group under the strong operator topology, based on controllability results for the infinite-dimensional case. Regarding neural network approximation, we note that the generators are finite-rank and can be approximated arbitrarily well by neural networks due to their universal approximation properties for continuous functions on compact sets (as the finite-rank operators can be represented via finite-dimensional parameters). To address accumulation along the flow, we will revise the manuscript to include a brief argument that the solution map of the ODE is continuous with respect to the generator in the topology that induces the strong operator topology on the group. This continuity ensures that the density result carries over to approximately realized generators. A fully quantitative error bound would require additional estimates on the Lipschitz constants of the flow, which we believe is possible but may be technical; we will provide a qualitative statement and leave a quantitative version for future work if space permits. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper introduces a neural parameterization of paths on the infinite-dimensional orthogonal group via finite-rank skew-adjoint generators of ODEs, with the central universality claim—that rank-2 generators produce dense flows in the strong operator topology—presented as a proved controllability result from Lie-group theory rather than a fitted or self-referential construction. No equation or step reduces the density statement to data-driven inputs by construction, no self-citation chain bears the load of the existence result, and the framework does not rename empirical patterns or smuggle ansatzes. The derivation remains self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Solutions to the skew-adjoint operator ODE exist and remain on the orthogonal group for finite-rank generators.
- domain assumption The operator topology used for density is the appropriate one for function-space bases.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
even with a rank-2 generator, the integrated solutions of the ODE are dense in the orthogonal group under the appropriate operator topology
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Paths on the Lie manifold satisfy ordinary differential equations (ODEs) governed by skew-adjoint integral operators
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hervé Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
work page 2010
-
[2]
Pooya Ashtari, Pourya Behmandpoor, Nikos Deligiannis, and Aleksandra Pizurica. Futon: Fourier tensor network for implicit neural representations.arXiv preprint arXiv: 2602.13414, 2026
-
[3]
Continuous-time signal de- composition: An implicit neural generalization of pca and ica
Shayan K Azmoodeh, Krishna Subramani, and Paris Smaragdis. Continuous-time signal de- composition: An implicit neural generalization of pca and ica. In2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6. IEEE, 2025
work page 2025
-
[4]
Ido Ben-Shaul, Leah Bar, Dalia Fishelov, and Nir Sochen. Deep learning solution of the eigenvalue problem for differential operators.Neural Computation, 35(6):1100–1134, 2023
work page 2023
-
[5]
Yoshua Bengio, Jean-françcois Paiement, Pascal Vincent, Olivier Delalleau, Nicolas Roux, and Marie Ouimet. Out-of-sample extensions for lle, isomap, mds, eigenmaps, and spectral clustering.Advances in neural information processing systems, 16, 2003
work page 2003
-
[6]
Pierre Brémaud.Mathematical principles of signal processing: Fourier and wavelet analysis. Springer, 2002
work page 2002
-
[7]
Elena Celledoni, Håkon Marthinsen, and Brynjulf Owren. An introduction to lie group integrators–basics, new developments and applications.Journal of Computational Physics, 257: 1040–1061, 2014
work page 2014
-
[8]
and Chen, Peter Yichen and Grinspun, Eitan , title =
Yue Chang, Otman Benchekroun, Maurizio M. Chiaramonte, Peter Yichen Chen, and Eitan Grinspun. Shape space spectra.ACM Trans. Graph., 44(4), July 2025. ISSN 0730-0301. doi: 10.1145/3731148. URLhttps://doi.org/10.1145/3731148
-
[9]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
work page 2018
-
[10]
Methods of mathematical physics, vol
Richard Courant and David Hilbert. Methods of mathematical physics, vol. i.Phys. Today, 7 (5):17–17, 1954
work page 1954
-
[11]
Luca De Luigi, Adriano Cardace, Riccardo Spezialetti, Pierluigi Zama Ramirez, Samuele Salti, and Luigi Di Stefano. Deep learning on implicit neural representations of shapes.The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[12]
Neuralef: Deconstructing kernels by deep neural networks
Zhijie Deng, Jiaxin Shi, and Jun Zhu. Neuralef: Deconstructing kernels by deep neural networks. InInternational Conference on Machine Learning, pages 4976–4992. PMLR, 2022
work page 2022
-
[13]
Fasma Diele, Luciano Lopez, and R Peluso. The cayley transform in the numerical solution of unitary differential systems.Advances in computational mathematics, 8(4):317–334, 1998. 10
work page 1998
-
[14]
Ziya Erkoc ¸, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai
Emilien Dupont, Hyunjik Kim, SM Eslami, Danilo Rezende, and Dan Rosenbaum. From data to functa: Your data point is a function and you can treat it like one.arXiv preprint arXiv:2201.12204, 2022
-
[15]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
work page 2018
-
[16]
How to train your neural ode: the world of jacobian and kinetic regularization
Chris Finlay, Jörn-Henrik Jacobsen, Levon Nurbekyan, and Adam Oberman. How to train your neural ode: the world of jacobian and kinetic regularization. InInternational conference on machine learning, pages 3154–3164. PMLR, 2020
work page 2020
-
[17]
Jean Gallier. Remarks on the cayley representation of orthogonal matrices and on perturbing the diagonal of a matrix to make it invertible.arXiv preprint math/0606320, 2006
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[18]
Eigengame: Pca as a nash equilibrium.International Conference on Learning Representations, 2021
Ian Gemp, Brian McWilliams, Claire Vernade, and Thore Graepel. Eigengame: Pca as a nash equilibrium.International Conference on Learning Representations, 2021
work page 2021
-
[19]
On the relationships between svd, klt and pca.Pattern recognition, 14(1-6): 375–381, 1981
Jan J Gerbrands. On the relationships between svd, klt and pca.Pattern recognition, 14(1-6): 375–381, 1981
work page 1981
-
[20]
Roger G Ghanem and Pol D Spanos.Stochastic finite elements: a spectral approach. Courier Corporation, 2003
work page 2003
-
[21]
Anode: Unconditionally accurate memory- efficient gradients for neural odes
Amir Gholaminejad, Kurt Keutzer, and George Biros. Anode: Unconditionally accurate memory- efficient gradients for neural odes. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, pages 730–736. International Joint Conferences on Artificial Intelligence Organization, 7 2019. doi: 10.24963/ijcai.2019/103....
-
[22]
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
work page 2013
-
[23]
David Gottlieb and Steven A Orszag.Numerical analysis of spectral methods: theory and applications. SIAM, 1977
work page 1977
-
[24]
Lie groups, lie algebras, and representations
Brian C Hall. Lie groups, lie algebras, and representations. InQuantum Theory for Mathemati- cians, pages 333–366. Springer, 2013
work page 2013
-
[25]
Nicholas J Higham.Accuracy and stability of numerical algorithms. SIAM, 2002
work page 2002
-
[26]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
work page 1989
-
[27]
On cayley-transform methods for the discretization of lie-group equations
Arieh Iserles. On cayley-transform methods for the discretization of lie-group equations. Foundations of Computational Mathematics, 1(2):129–160, 2001
work page 2001
-
[28]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
CelebA Dataset cropped with Haar-Cascade face detector, 2021
Andreas M Kist. CelebA Dataset cropped with Haar-Cascade face detector, 2021. URL https://doi.org/10.5281/zenodo.5561092
-
[30]
Bernard O Koopman. Hamiltonian systems and transformation in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931
work page 1931
-
[31]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
work page 2023
-
[32]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical Report, 2009
work page 2009
-
[33]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. 11
work page 1998
-
[34]
Bruno Lévy. Laplace-beltrami eigenfunctions towards an algorithm that" understands" geometry. InIEEE International Conference on Shape Modeling and Applications 2006 (SMI’06), pages 13–13. IEEE, 2006
work page 2006
-
[35]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[36]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.International Conference on Learning Representations, 2021
work page 2021
-
[37]
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/JMS Journal of Data Science, 1(3):1–27, 2024
work page 2024
-
[38]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofeng Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
work page 2021
- [39]
-
[40]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[41]
Vismay Modi, Nicholas Sharp, Or Perel, Shinjiro Sueda, and David IW Levin. Simplicits: Mesh-free, geometry-agnostic elastic simulation.ACM Transactions on Graphics (TOG), 43(4): 1–11, 2024
work page 2024
-
[42]
Equivariant architectures for learning in deep weight spaces
Aviv Navon, Aviv Shamsian, Idan Achituve, Ethan Fetaya, Gal Chechik, and Haggai Maron. Equivariant architectures for learning in deep weight spaces. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 ofPro- ceed...
work page 2023
-
[43]
David Pfau, Stig Petersen, Ashish Agarwal, David GT Barrett, and Kimberly L Stachenfeld. Spectral inference networks: Unifying deep and spectral learning.International Conference on Learning Representations, 2019
work page 2019
-
[44]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[45]
Yousef Saad.Numerical methods for large eigenvalue problems: revised edition. SIAM, 2011
work page 2011
-
[46]
Peter J Schmid. Dynamic mode decomposition of numerical and experimental data.Journal of fluid mechanics, 656:5–28, 2010
work page 2010
-
[47]
Data-free learning of reduced-order kinematics
Nicholas Sharp, Cristian Romero, Alec Jacobson, Etienne V ouga, Paul Kry, David IW Levin, and Justin Solomon. Data-free learning of reduced-order kinematics. InACM SIGGRAPH 2023 Conference Proceedings, pages 1–9, 2023
work page 2023
-
[48]
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Im- plicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
work page 2020
-
[49]
Henry Stark and John W Woods.Probability, random processes, and estimation theory for engineers. Prentice-Hall, Inc., 1986
work page 1986
-
[50]
Pearson Prentice Hall Upper Saddle River, NJ, 2005
Petre Stoica, Randolph L Moses, et al.Spectral analysis of signals, volume 452. Pearson Prentice Hall Upper Saddle River, NJ, 2005. 12
work page 2005
-
[51]
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547, 2020
work page 2020
-
[52]
Geoffrey Ingram Taylor and Albert Edward Green. Mechanism of the production of small eddies from large ones.Proceedings of the Royal Society of London. Series A-Mathematical and Physical Sciences, 158(895):499–521, 1937
work page 1937
- [53]
-
[54]
Functional data analysis.Annual Review of Statistics and its application, 3:257–295, 2016
Jane-Ling Wang, Jeng-Min Chiou, and Hans-Georg Müller. Functional data analysis.Annual Review of Statistics and its application, 3:257–295, 2016
work page 2016
-
[55]
Neural fields in visual computing and beyond
Yiheng Xie, Towaki Takikawa, Shunsuke Saito, Or Litany, Shiqin Yan, Numair Khan, Federico Tombari, James Tompkin, Vincent Sitzmann, and Srinath Sridhar. Neural fields in visual computing and beyond. InComputer graphics forum, volume 41, pages 641–676. Wiley Online Library, 2022
work page 2022
-
[56]
Dejia Xu, Peihao Wang, Yifan Jiang, Zhiwen Fan, and Zhangyang Wang. Signal processing for implicit neural representations.Advances in Neural Information Processing Systems, 35: 13404–13418, 2022
work page 2022
-
[57]
A structured dictionary perspective on implicit neural representations
Gizem Yüce, Guillermo Ortiz-Jiménez, Beril Besbinar, and Pascal Frossard. A structured dictionary perspective on implicit neural representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19228–19238, 2022
work page 2022
-
[58]
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019. 13 A Proof of Theorem 1 We first restate the theorem for completeness: Theorem 1(Approximating the Orthogonal Group via Rank-2 Generators).Let QT denote the set of all operators Q(T) obtained by solving the initial value problem ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.