Stage-adaptive Token Selection for Efficient Omni-modal LLMs
Pith reviewed 2026-05-20 06:00 UTC · model grok-4.3
The pith
Stage-adaptive token selection prunes 90% of visual and audio tokens in omni-modal LLMs while keeping 96.3% performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
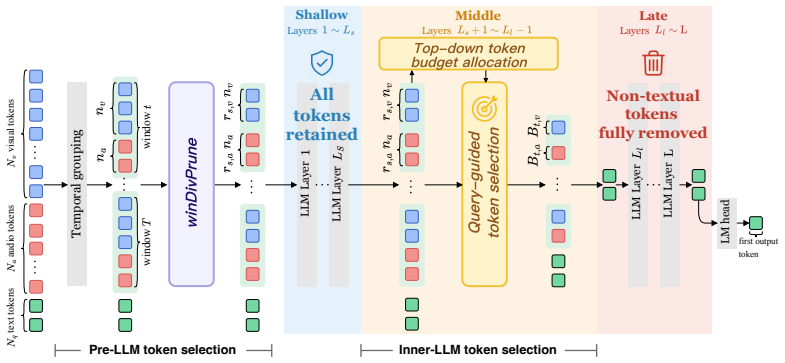
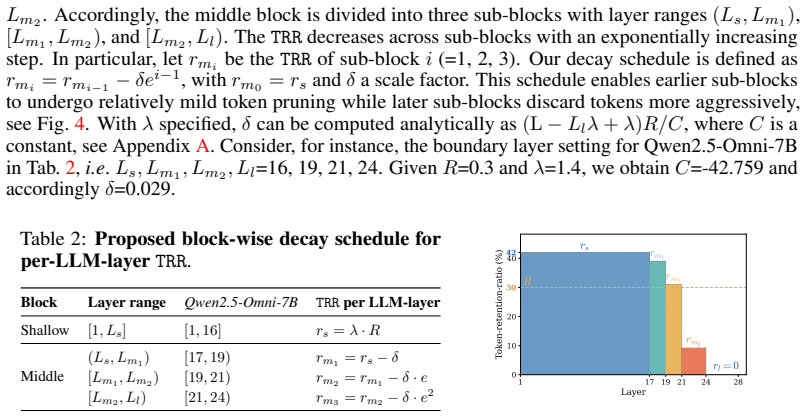
The discovery is that cross-modal token importance evolves predictably across layers in omni-modal LLMs, with dependencies weakening after initial fusion blocks. This observation enables a training-free selection strategy that removes spatiotemporal redundancy upfront, allocates retention dynamically inside the model using query relevance, and discards all remaining non-text tokens once fusion completes. The method thus achieves substantial speed and cost savings while maintaining high task performance.
What carries the argument
The stage-adaptive pruning mechanism that uses attention-weighted diversity before the LLM and query relevance scores inside blocks to progressively reduce non-text tokens.
If this is right
- Retaining only 10% of visual and audio tokens produces a 9.3 times reduction in FLOPs.
- A 4.8 times speedup is observed in the prefill phase of inference.
- 96.3% of the original model performance is preserved across tested tasks.
- The approach requires no additional training and applies directly to current omni-modal LLMs.
Where Pith is reading between the lines
- This dependency pattern could be tested in other multimodal setups to see if late-layer pruning generalizes.
- Future model designs might incorporate explicit stage information to guide token allocation from the start.
- Similar adaptive selection could reduce costs in models that process additional data types such as point clouds or sensor streams.
Load-bearing premise
The layer-wise analysis showing block-wise weakening of visual and audio dependencies holds true for the models under test and allows safe late-layer removal of non-text tokens.
What would settle it
Applying the 10% retention strategy to a new omni-modal LLM and measuring whether performance stays above 90% of the full model would confirm or refute the generalizability of the dependency pattern.
Figures


read the original abstract
Omni-modal large language models (om-LLMs) achieve unified audio-visual understanding by encoding video and audio into temporally aligned token sequences interleaved at the window level. However, processing these dense non-textual tokens throughout the LLM incurs substantial computational overhead. Although training-free token selection can reduce this cost, existing methods either focus on visual-only inputs or prune om-LLM tokens only before the LLM with fixed per-modality ratios, failing to capture how cross-modal token importance evolves across layers. To address this limitation, we first analyze the layer-wise token dependency of om-LLMs. We find that visual and audio dependencies follow a block-wise pattern and gradually weaken with depth, indicating that many late-layer non-textual tokens become redundant after cross-modal fusion. Motivated by this observation, we propose SEATS, a training-free, stage-adaptive token selection method for efficient om-LLM inference. Before the LLM, SEATS removes spatiotemporal redundancy via attention-weighted diversity selection. Inside the LLM, it progressively prunes tokens across blocks and dynamically allocates the retention budget from temporal windows to modalities using query relevance scores. In late layers, it removes all remaining non-textual tokens once cross-modal fusion is complete. Experiments on Qwen2.5-Omni and Qwen3-Omni demonstrate that SEATS effectively improves inference efficiency. Retaining only 10% of visual and audio tokens, it achieves a 9.3x FLOPs reduction and a 4.8x prefill speedup while preserving 96.3% of the original performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEATS, a training-free token selection method for omni-modal LLMs that processes interleaved video and audio tokens. It first analyzes layer-wise token dependencies, observing a block-wise pattern where visual and audio dependencies weaken with depth, suggesting redundancy after cross-modal fusion. SEATS applies attention-weighted diversity selection before the LLM, progressive pruning with dynamic budget allocation inside the LLM using query relevance, and complete removal of remaining non-textual tokens in late layers. On Qwen2.5-Omni and Qwen3-Omni, retaining 10% of visual/audio tokens yields 9.3x FLOPs reduction, 4.8x prefill speedup, and 96.3% of original performance.
Significance. If the reported speedups and performance retention are robust, the work would be significant for practical deployment of omni-modal models by reducing the cost of dense non-textual tokens in a layer-adaptive, training-free manner. The empirical results on two models and the explicit analysis of cross-layer dependency patterns provide a concrete starting point for efficiency techniques in this setting.
major comments (3)
- [Method description and dependency analysis section] The central efficiency claim rests on late-layer removal of all non-textual tokens, justified by the observation that dependencies weaken with depth. However, weakening attention scores does not automatically confirm that modality-specific information has been fully transferred to text tokens via residual connections and feed-forward layers; this assumption is load-bearing for the 96.3% retention result and requires explicit validation (e.g., via controlled ablations that isolate the final removal step).
- [Experiments section] Experiments report 96.3% performance retention and concrete speedups but provide no error bars, standard deviations across runs, or statistical tests. This makes it difficult to determine whether the average masks task-specific degradations, especially given the skeptic concern about unquantified risk in the final pruning step.
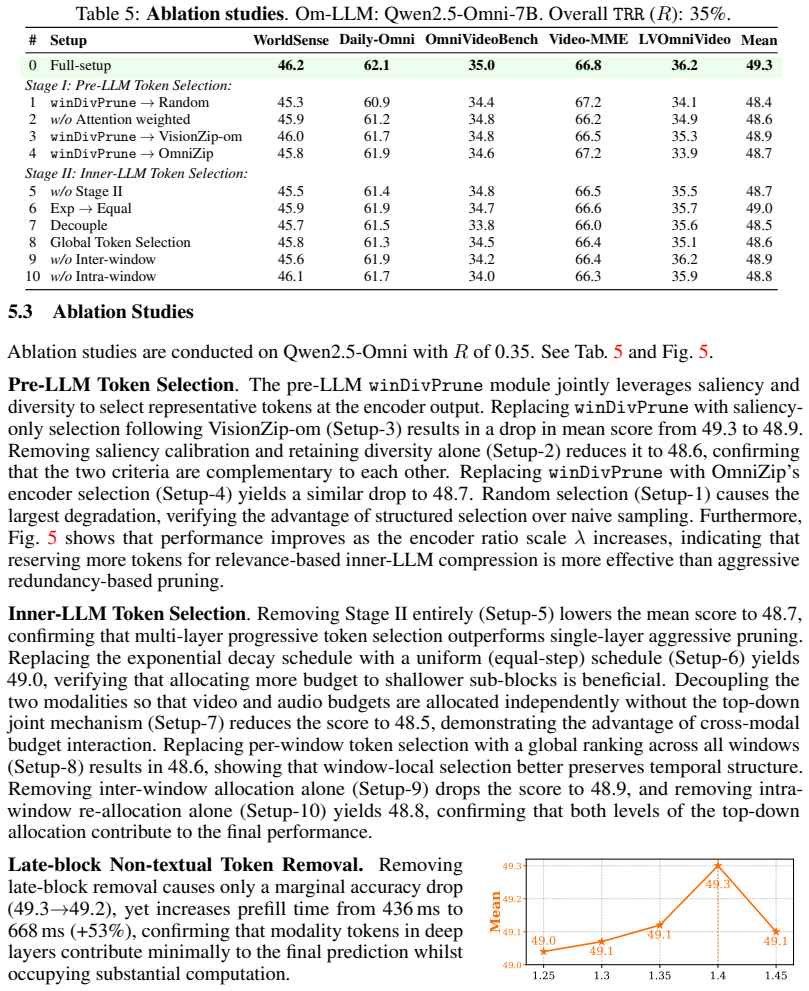
- [Method and ablation studies] The progressive pruning and dynamic budget allocation inside the LLM rely on attention scores and query relevance heuristics; the manuscript would benefit from ablations comparing these choices against fixed per-modality ratios or random selection to establish that the stage-adaptive components are necessary for the reported gains.
minor comments (2)
- [Method] Clarify the exact definition and computation of 'query relevance scores' used for dynamic budget allocation, including any hyperparameters and how they are normalized across modalities.
- [Introduction] The abstract and introduction would be strengthened by a brief comparison table contrasting SEATS with prior visual-only or pre-LLM-only pruning methods on the same omni-modal benchmarks.
Simulated Author's Rebuttal
Thank you for the constructive and detailed review of our manuscript. We have carefully addressed each major comment below with point-by-point responses. Where revisions are needed to strengthen the work, we commit to incorporating them in the next version.
read point-by-point responses
-
Referee: [Method description and dependency analysis section] The central efficiency claim rests on late-layer removal of all non-textual tokens, justified by the observation that dependencies weaken with depth. However, weakening attention scores does not automatically confirm that modality-specific information has been fully transferred to text tokens via residual connections and feed-forward layers; this assumption is load-bearing for the 96.3% retention result and requires explicit validation (e.g., via controlled ablations that isolate the final removal step).
Authors: We thank the referee for this important clarification. Our layer-wise analysis shows that cross-modal attention dependencies between non-text tokens and text tokens weaken progressively with depth, which we interpret as evidence of redundancy after fusion. However, we agree that attention scores alone do not fully prove complete information transfer through residuals and FFN layers. To provide explicit validation, we will add a controlled ablation in the revised manuscript that isolates the final removal step: we will compare full SEATS performance against a variant that retains all non-text tokens in late layers (while applying identical early and progressive pruning). This will quantify the performance impact of the late-layer removal and directly address the load-bearing assumption for the reported 96.3% retention. revision: yes
-
Referee: [Experiments section] Experiments report 96.3% performance retention and concrete speedups but provide no error bars, standard deviations across runs, or statistical tests. This makes it difficult to determine whether the average masks task-specific degradations, especially given the skeptic concern about unquantified risk in the final pruning step.
Authors: We acknowledge the validity of this concern. The current results present average performance across benchmarks without variance measures, which limits assessment of consistency and potential task-specific effects. In the revision, we will rerun the primary experiments across multiple random seeds (where any stochasticity exists in token selection or evaluation) and report means with standard deviations. We will also add statistical tests (e.g., paired t-tests) between SEATS and the baseline to evaluate the significance of the 96.3% retention and to surface any task-specific variations, thereby quantifying the risk associated with the final pruning step. revision: yes
-
Referee: [Method and ablation studies] The progressive pruning and dynamic budget allocation inside the LLM rely on attention scores and query relevance heuristics; the manuscript would benefit from ablations comparing these choices against fixed per-modality ratios or random selection to establish that the stage-adaptive components are necessary for the reported gains.
Authors: We agree that additional ablations are valuable to isolate the contribution of the stage-adaptive mechanisms. We will expand the ablation studies to include direct comparisons against two baselines at the same overall retention rate: (1) fixed per-modality retention ratios applied uniformly across layers, and (2) random token selection. These variants will be evaluated on the same models (Qwen2.5-Omni and Qwen3-Omni) and tasks, allowing us to measure the incremental benefits of progressive pruning with dynamic budget allocation and query relevance. The results will be presented to demonstrate that the adaptive components are necessary for the observed efficiency-performance trade-off. revision: yes
Circularity Check
No significant circularity detected; derivation is empirical and self-contained.
full rationale
The paper conducts an empirical layer-wise dependency analysis on om-LLMs to observe block-wise weakening of visual/audio attention patterns with depth, then designs SEATS pruning rules (attention-weighted diversity before LLM, progressive block pruning inside, query-relevance budget allocation, and late-layer non-text removal) directly from those observations. Retention budgets and removal decisions are defined via attention scores and relevance metrics rather than fitted to final accuracy; the reported 9.3x FLOPs reduction and 96.3% performance retention are measured experimental outcomes on Qwen2.5-Omni/Qwen3-Omni, not tautological consequences of the inputs. No self-definitional equations, fitted-input predictions, load-bearing self-citations, or ansatz smuggling appear in the chain. The method remains falsifiable by direct measurement and does not reduce to its own premises by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DivPrune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. DivPrune: Diversity-based visual token pruning for large multimodal models. InCVPR, pages 9392–9401, 2025
work page 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, 2024
work page 2024
-
[4]
Scope: Saliency-coverage oriented token pruning for efficient multimodel LLMs
Jinhong Deng, Wen Li, Joey Tianyi Zhou, and Yang He. Scope: Saliency-coverage oriented token pruning for efficient multimodel LLMs. InNeurIPS, 2025
work page 2025
-
[5]
OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, et al. OmniSIFT: Modality-asymmetric token compression for efficient omni-modal large language models.arXiv preprint arXiv:2602.04804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
MMTok: Multimodal coverage maximization for efficient inference of VLMs
Sixun Dong, Juhua Hu, Mian Zhang, Ming Yin, Yanjie Fu, and Qi Qian. MMTok: Multimodal coverage maximization for efficient inference of VLMs. InICLR, 2026
work page 2026
-
[7]
Unified spatiotemporal token compression for video-llms at ultra-low retention
Junhao Du, Jialong Xue, Anqi Li, Jincheng Dai, and Guo Lu. Unified spatiotemporal token compression for video-llms at ultra-low retention. InCVPR, 2026
work page 2026
-
[8]
Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, and Zhuotao Tian. FlashVID: Efficient video large language models via training-free tree-based spatiotemporal token merging. InICLR, 2026
work page 2026
-
[9]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis. InCVPR, 2025
work page 2025
-
[10]
Yuying Ge, Yixiao Ge, Chen Li, Teng Wang, Junfu Pu, Yizhuo Li, Lu Qiu, Jin Ma, Lisheng Duan, Xinyu Zuo, et al. Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts.arXiv preprint arXiv:2507.20939, 2025
-
[11]
Chao Gong, Depeng Wang, Zhipeng Wei, Ya Guo, Huijia Zhu, and Jingjing Chen. Echoing- pixels: Cross-modal adaptive token reduction for efficient audio-visual LLMs.arXiv preprint arXiv:2512.10324, 2025
-
[12]
WorldSense: Evaluating real-world omnimodal understanding for multimodal LLMs
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. WorldSense: Evaluating real-world omnimodal understanding for multimodal LLMs. InICLR, 2026
work page 2026
-
[13]
PruneVid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. PruneVid: Visual token pruning for efficient video large language models. InACL, 2025
work page 2025
-
[14]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Omnivideobench: Towards audio-visual understanding evaluation for omni MLLMs
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Jiafu Tang, Zhenghao Song, Dingling Zhang, et al. Omnivideobench: Towards audio-visual understanding evaluation for omni MLLMs. InICLR, 2026
work page 2026
-
[16]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. LLaV A-NeXT-Interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2501.15368 (2025)
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025. 10
-
[18]
Video compression commander: Plug-and-play inference acceleration for video large language models
Xuyang Liu, Yiyu Wang, Junpeng Ma, and Linfeng Zhang. Video compression commander: Plug-and-play inference acceleration for video large language models. InEMNLP, pages 1910–1924, 2025
work page 1910
-
[19]
HoliTom: Holistic token merging for fast video large language models
Kele Shao, TAO Keda, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. HoliTom: Holistic token merging for fast video large language models. InNeurIPS, 2025
work page 2025
-
[20]
LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shao, Boyuan Zhu, Junhao Qi, Fuzhen Wu, and Yan Yan. LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models. InNeurIPS, 2024
work page 2024
-
[21]
FastVID: Dynamic density pruning for fast video large language models
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Sicheng Zhao, Guiguang Ding, et al. FastVID: Dynamic density pruning for fast video large language models. InNeurIPS, 2025
work page 2025
-
[22]
video-SALMONN: Speech-enhanced audio-visual large language models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, Yuxuan Wang, and Chao Zhang. video-SALMONN: Speech-enhanced audio-visual large language models. InICML, 2024
work page 2024
-
[23]
video-SALMONN-o1: Reasoning-enhanced audio-visual large language model
Guangzhi Sun, Yudong Yang, Jimin Zhuang, Changli Tang, Yixuan Li, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN-o1: Reasoning-enhanced audio-visual large language model. InICML, 2025
work page 2025
-
[24]
video-SALMONN 2: Caption-enhanced audio-visual large language models
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-SALMONN 2: Caption-enhanced audio-visual large language models. arXiv preprint arXiv:2506.15220, 2025
-
[25]
DyCoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. DyCoke: Dynamic compression of tokens for fast video large language models. InCVPR, 2025
work page 2025
-
[26]
OmniZip: Audio-guided dynamic token compression for fast omnimodal large language models
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Huan Wang, et al. OmniZip: Audio-guided dynamic token compression for fast omnimodal large language models. InCVPR, 2026
work page 2026
-
[27]
Keda Tao, Yuhua Zheng, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, et al. LVOmniBench: Pioneering long audio-video understanding evaluation for omnimodal LLMs.arXiv preprint arXiv:2603.19217, 2026
-
[28]
Qwen Team. Qwen3.5-Omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Hao Wu, Yingqi Fan, Jinyang Dai, Junlong Tong, Yunpu Ma, and Xiaoyu Shen. HiDrop: Hierarchical vision token reduction in MLLMs via late injection, concave pyramid pruning, and early exit. InICLR, 2026
work page 2026
-
[31]
Zhifei Xie and Changqiao Wu. Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities.arXiv preprint arXiv:2410.11190, 2024
-
[32]
PyramidDrop: Accelerating your large vision-language models via pyramid visual redundancy reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. PyramidDrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. InCVPR, 2025
work page 2025
-
[33]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-Omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
VisionZip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. VisionZip: Longer is better but not necessary in vision language models. InCVPR, 2025. 11
work page 2025
-
[36]
OmniVinci: Enhancing architecture and data for Omni-Modal understanding LLM
Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, et al. OmniVinci: Enhancing architecture and data for Omni-Modal understanding LLM. InICLR, 2026
work page 2026
-
[37]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. MiniCPM-V 4.5: Cooking efficient MLLMs via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
LMMs-Eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. LMMs-Eval: Reality check on the evaluation of large multimodal models. InFindings of NAACL, pages 881–916, 2025
work page 2025
-
[39]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in VLMs
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in VLMs. InCVPR, 2025
work page 2025
-
[40]
Beyond Attention or Similarity: Maximizing conditional diversity for token pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond Attention or Similarity: Maximizing conditional diversity for token pruning in MLLMs. InNeurIPS, 2025
work page 2025
-
[41]
SparseVLM: Visual token sparsification for efficient vision-language model inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. SparseVLM: Visual token sparsification for efficient vision-language model inference. InICML, 2025
work page 2025
-
[42]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.Transactions on Machine Learning Research, 2025
work page 2025
-
[43]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities,
Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities.arXiv preprint arXiv:2505.17862, 2025. 12 We provide additional details, extended experimental results, and further discussion in this supple- mentary material, including: • More experimental results and analysis. • Detailed experiment...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.