Hunting Vulnerability Variants in AI Infra: Measurement and Reference-Driven Detection
Pith reviewed 2026-05-20 03:46 UTC · model grok-4.3
The pith
AI infrastructure projects share recurrent vulnerable patterns across similar designs, which a reference-driven framework can detect from known disclosures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
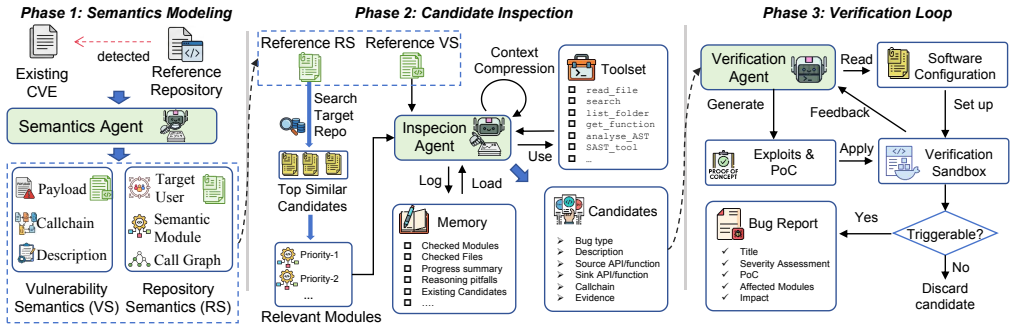
AI infra projects frequently implement related model-centric workflows, so vulnerabilities disclosed in one repository recur as variants in others with similar structure. INFRASCOPE extracts vulnerability semantics from public disclosures and deploys them through a reference-driven multi-agent process to scan fresh repositories for matching patterns and confirm their validity.
What carries the argument
INFRASCOPE, a reference-driven multi-agent framework that extracts transferable vulnerability semantics from known disclosures to locate and validate variants in new repositories.
If this is right
- Shared design patterns in AI infra create concrete opportunities for vulnerability variants to spread across projects.
- Reference cases from public disclosures supply enough semantic information to guide automated searches in unrelated but related repositories.
- The detection process can surface previously unknown issues that later receive official acknowledgments and CVE assignments.
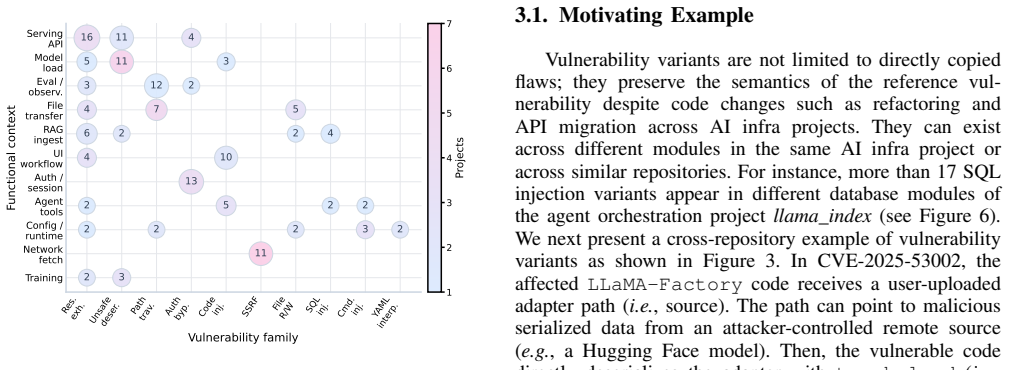
- Measurement across hundreds of repositories confirms that overlapping functionality is common enough to justify systematic variant hunting.
Where Pith is reading between the lines
- Security auditing practices for AI systems could shift toward maintaining libraries of reference vulnerabilities rather than relying solely on per-project scans.
- Similar recurrence patterns may exist in other domains with high code reuse, such as cloud orchestration or data pipeline tools.
- Integrating the semantic extraction step with existing static analysis engines could reduce the manual validation burden for discovered variants.
Load-bearing premise
Vulnerability semantics extracted from known disclosures transfer reliably to new repositories without excessive false positives or loss of important context-specific details.
What would settle it
If manual examination of the 20 evaluated repositories shows that the reported vulnerabilities are not genuine variants of the referenced disclosures or if the method produces mostly invalid findings on additional repositories, the transferability claim would not hold.
Figures




read the original abstract
AI infra has become a shared execution layer for model training, deployment, and agent orchestration. Because many projects reimplement similar model-centric workflows, a vulnerability disclosed in one repository can recur as a variant in another repository with a related design. Yet the prevalence and detectability of these variants remain poorly understood. This paper presents a measurement study of vulnerability variants in AI infra. Analyzing 688 GitHub repositories and 251 publicly disclosed vulnerabilities, we find that AI infra projects frequently share overlapping functionality and recurrent vulnerable patterns, creating a concrete basis for cross-repository variants. Building on this finding, we study how to automatically identify such variants from known disclosures. We propose INFRASCOPE, a reference-driven multi-agent framework that extracts transferable vulnerability semantics from known cases and uses them to locate and validate variants in new repositories. Evaluating INFRASCOPE on 20 real-world AI infra repositories, we uncover over 20 vulnerabilities, including 11 acknowledged cases and 4 cases that have been assigned CVEs so far.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a measurement study analyzing 688 GitHub repositories and 251 publicly disclosed vulnerabilities in AI infrastructure projects, identifying frequent overlapping functionality and recurrent vulnerable patterns that enable cross-repository variants. It proposes INFRASCOPE, a reference-driven multi-agent framework that extracts transferable vulnerability semantics from known disclosures and applies them to locate and validate variants in new repositories. Evaluation on 20 real-world AI infra repositories is reported to uncover over 20 vulnerabilities, including 11 acknowledged cases and 4 assigned CVEs.
Significance. If the evaluation holds, the work provides empirical evidence for the prevalence of vulnerability variants in AI infra and demonstrates a practical reference-driven approach to detection that has already yielded acknowledged issues and CVEs. The measurement on a large set of repositories and use of public disclosures as external references are strengths that ground the claims in observable data rather than self-referential fitting.
major comments (2)
- [Evaluation of INFRASCOPE] Evaluation section (description of INFRASCOPE results on 20 repositories): the claim of uncovering over 20 vulnerabilities (11 acknowledged, 4 CVE-assigned) lacks any reported count of total candidates examined, precision/recall figures, or explicit validation criteria and process (manual review, PoC execution, static analysis, or maintainer confirmation). This information is load-bearing for assessing whether semantic extraction succeeds without excessive false positives or context loss.
- [Abstract and INFRASCOPE description] Abstract and framework description: the assumption that vulnerability semantics extracted from known disclosures transfer reliably to new repositories is presented without quantitative evidence on false-positive rates or context-specific failure modes, which directly affects the central claim that the framework locates and validates variants.
minor comments (2)
- [Measurement study description] The selection criteria for the 688 repositories and 251 vulnerabilities are not detailed in the provided abstract; adding explicit inclusion/exclusion rules would improve reproducibility.
- [Framework overview] Consider clarifying the multi-agent architecture of INFRASCOPE with a high-level diagram or pseudocode to make the reference-driven extraction process easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below and have revised the manuscript to strengthen the presentation of the evaluation and framework details.
read point-by-point responses
-
Referee: [Evaluation of INFRASCOPE] Evaluation section (description of INFRASCOPE results on 20 repositories): the claim of uncovering over 20 vulnerabilities (11 acknowledged, 4 CVE-assigned) lacks any reported count of total candidates examined, precision/recall figures, or explicit validation criteria and process (manual review, PoC execution, static analysis, or maintainer confirmation). This information is load-bearing for assessing whether semantic extraction succeeds without excessive false positives or context loss.
Authors: We agree that the evaluation requires more granular reporting to allow readers to assess false-positive rates and semantic fidelity. In the revised manuscript we have expanded the Evaluation section to report the total number of candidates examined by INFRASCOPE across the 20 repositories, the resulting precision and recall figures computed from the validation outcomes, and the explicit multi-stage validation criteria and process (initial static filtering, manual code review by the authors, PoC execution where feasible, and direct maintainer confirmation or CVE assignment). These additions directly address concerns about excessive false positives and context loss. revision: yes
-
Referee: [Abstract and INFRASCOPE description] Abstract and framework description: the assumption that vulnerability semantics extracted from known disclosures transfer reliably to new repositories is presented without quantitative evidence on false-positive rates or context-specific failure modes, which directly affects the central claim that the framework locates and validates variants.
Authors: The measurement study on 688 repositories and 251 disclosures supplies the empirical basis for recurrent overlapping patterns that enable transfer. To provide the requested quantitative grounding, we have revised the INFRASCOPE description and added a new subsection that reports observed false-positive rates from the 20-repository evaluation together with an analysis of context-specific failure modes (e.g., differences in dependency resolution or API surface) and how the multi-agent extraction mitigates them. This supplies concrete evidence supporting reliable transfer in the evaluated setting. revision: yes
Circularity Check
No circularity: results derive from external repositories and disclosures
full rationale
The paper's measurement analyzes 688 GitHub repositories and 251 publicly disclosed vulnerabilities as independent external inputs, identifying overlapping functionality as an empirical observation. INFRASCOPE is then built to extract semantics from these known cases and apply them to new repositories for variant detection. Evaluation on 20 additional real-world repositories reports over 20 vulnerabilities (11 acknowledged, 4 with CVEs), grounded in external data and validation rather than any fitted parameters, self-definitions, or self-citation chains that reduce the central claims to inputs by construction. No equations, ansatzes, uniqueness theorems, or renamings of known results appear in the derivation; the chain remains self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI infra projects frequently share overlapping functionality and recurrent vulnerable patterns
invented entities (1)
-
INFRASCOPE multi-agent framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose INFRASCOPE, a reference-driven multi-agent framework that extracts transferable vulnerability semantics from known cases and uses them to locate and validate variants in new repositories.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LlamaFactory: Unified efficient fine-tuning of 100+ language models,
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, and Z. Luo, “LlamaFactory: Unified efficient fine-tuning of 100+ language models,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations). Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 400–410. [Online]. Available: h...
work page 2024
-
[2]
vLLM Project, “vLLM documentation,” Official documentation, 2026, accessed: 2026-04-27. [Online]. Available: https://docs.vllm.ai/
work page 2026
-
[3]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[4]
A. Chan, K. Wei, S. Huang, N. Rajkumar, E. Perrier, S. Lazar, G. K. Hadfield, and M. Anderljung, “Infrastructure for AI agents,” Trans. Mach. Learn. Res., vol. 2025, 2025. [Online]. Available: https://openreview.net/forum?id=Ckh17xN2R2
work page 2025
-
[5]
National Vulnerability Database, “Nvd - cve-2025-53002,” National Vulnerability Database, 2025, accessed: 2026-02-20. [Online]. Available: https://nvd.nist.gov/vuln/detail/CVE-2025-53002
work page 2025
-
[6]
Anthropic, “Claude mythos preview,” Anthropic Alignment Science technical blog, Apr. 2026, published: 2026-04-07. Accessed: 2026-04-08. [Online]. Available: https://red.anthropic.com/2026/ mythos-preview/
work page 2026
-
[7]
Vuddy: A scalable approach for vulnerable code clone discovery,
S. Kim, S. Woo, H. Lee, and H. Oh, “Vuddy: A scalable approach for vulnerable code clone discovery,” in2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 595–614
work page 2017
-
[8]
S. Woo, H. Hong, E. Choi, and H. Lee, “MOVERY: A precise approach for modified vulnerable code clone discovery from modified Open-Source software components,” in31st USENIX Security Symposium (USENIX Security 22). Boston, MA: USENIX Association, Aug. 2022, pp. 3037–3053. [Online]. Available: https: //www.usenix.org/conference/usenixsecurity22/presentation/woo
work page 2022
-
[9]
S. Woo, E. Choi, H. Lee, and H. Oh, “V1SCAN: Discovering 1-day vulnerabilities in reused C/C++ open-source software components using code classification techniques,” in32nd USENIX Security Symposium (USENIX Security 23). Anaheim, CA: USENIX Association, Aug. 2023, pp. 6541–6556. [Online]. Available: https: //www.usenix.org/conference/usenixsecurity23/pres...
work page 2023
-
[10]
A large-scale empirical study of security patches,
F. Li and V . Paxson, “A large-scale empirical study of security patches,” inProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 2201–2215. [Online]. Available: https://doi.org/10.1145/3133956. 3134072
-
[11]
K. Huang, C. Lu, Y . Cao, B. Chen, and X. Peng, “Vmud: Detecting recurring vulnerabilities with multiple fixing functions via function selection and semantic equivalent statement matching,” in Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 202...
-
[12]
S. Feng, Y . Wu, W. Xue, S. Pan, D. Zou, Y . Liu, and H. Jin, “FIRE: Combining Multi-Stage filtering with taint analysis for scalable recurring vulnerability detection,” in33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA: USENIX Association, Aug. 2024, pp. 1867–1884. [Online]. Available: https:// www.usenix.org/conference/usenixsecuri...
work page 2024
-
[13]
Accurate and efficient recurring vulnerability detection for iot firmware,
H. Xiao, Y . Zhang, M. Shen, C. Lin, C. Zhang, S. Liu, and M. Yang, “Accurate and efficient recurring vulnerability detection for iot firmware,” ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 3317–3331. [Online]. Available: https://doi.org/10.1145/3658644.3670275
-
[14]
H. Yang, J. Guo, S. Yang, G. Zhao, Q. Liu, C. Zhang, Z. Tan, L. Shan, Q. Zhou, M. Zhou, J. Tai, and X. Jia, “Iotbec: An accurate and efficient recurring vulnerability detection framework for black box iot devices,” inProceedings of the Network and Distributed System Security Symposium (NDSS). San Diego, CA, USA: The Internet Society, 2026
work page 2026
-
[15]
RepoAudit: An autonomous LLM-agent for repository-level code auditing,
J. Guo, C. Wang, X. Xu, Z. Su, and X. Zhang, “RepoAudit: An autonomous LLM-agent for repository-level code auditing,” in Proceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, Eds., vol. 267. PMLR...
work page 2025
-
[16]
IRIS: LLM-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “IRIS: LLM-assisted static analysis for detecting security vulnerabilities,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=9LdJDU7E91
work page 2025
-
[17]
Llm-based vulnerabil- ity detection at project scale: An empirical study,
F. Li, J. Jiang, D. Chen, and Y . Xiong, “Llm-based vulnerabil- ity detection at project scale: An empirical study,”arXiv preprint arXiv:2601.19239, 2026
-
[18]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the association for computational linguis- tics, vol. 12, pp. 157–173, 2024
work page 2024
-
[19]
Hybridflow: A flexible and efficient rlhf framework
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexible and efficient rlhf framework,” p. 1279–1297, 2025. [Online]. Available: https://doi.org/10.1145/3689031.3696075
-
[20]
C-pack: Packaged resources to advance general chinese embedding,
S. Xiao, Z. Liu, P. Zhang, and N. Muennighoff, “C-pack: Packaged resources to advance general chinese embedding,” 2023
work page 2023
-
[21]
National vulnerability database,
National Institute of Standards and Technology, “National vulnerability database,” Official vulnerability database, 2026, accessed: 2026-04-27. [Online]. Available: https://nvd.nist.gov/
work page 2026
-
[22]
Open Source Vulnerabilities, “Open source vulnerabilities,” Official vulnerability database, 2026, accessed: 2026-04-27. [Online]. Available: https://osv.dev/
work page 2026
-
[23]
GitHub, “Github advisory database,” Official vulnerability advisory database, 2026, accessed: 2026-04-27. [Online]. Available: https: //github.com/advisories
work page 2026
- [24]
-
[25]
A. Lekssays, H. Mouhcine, K. Tran, T. Yu, and I. Khalil, “{LLMxCPG}:{Context-Aware}vulnerability detection through code property{Graph-Guided}large language models,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 489– 507
work page 2025
-
[26]
Vulsolver: Vulnerability detection via llm-driven constraint solving,
X. Li, Y . Su, J. Liu, Z. Lin, Y . Hou, P. Gao, and Y . Zhang, “Vulsolver: Vulnerability detection via llm-driven constraint solving,” arXiv preprint arXiv:2509.00882, 2025
-
[27]
Vulnllm-r: Specialized reasoning llm with agent scaffold for vulnerability detection,
Y . Nie, H. Li, C. Guo, R. Jiang, Z. Wang, B. Li, D. Song, and W. Guo, “Vulnllm-r: Specialized reasoning llm with agent scaffold for vulnerability detection,”arXiv preprint arXiv:2512.07533, 2025
-
[28]
Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,
A. Yildiz, S. G. Teo, Y . Lou, Y . Feng, C. Wang, and D. M. Divakaran, “Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code repositories,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, Jul. 2025...
work page 2025
-
[29]
Recurring vulnerability detection: How far are we?
Y . Cao, S. Wu, R. Wang, B. Chen, Y . Huang, C. Lu, Z. Zhou, and X. Peng, “Recurring vulnerability detection: How far are we?”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun. 2025. [Online]. Available: https://doi.org/10.1145/3728901
-
[30]
Memgpt: Towards llms as operating systems,
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “Memgpt: Towards llms as operating systems,” 2023
work page 2023
-
[31]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. R. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” inThirty-seventh Conference on Neural Information Processing Systems, vol. 36. New Orleans, LA, USA: Curran Associates, Inc., 2023, pp. 8634–8652. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2023/file/...
work page 2023
-
[32]
LLMLingua: Compressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “LLMLingua: Compressing prompts for accelerated inference of large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 13 358–13 376. [Online]. Available: https://aclanthology.org/2...
work page 2023
-
[33]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Comput. Surv., vol. 55, no. 12, Mar
-
[34]
Survey of hallucination in natural language generation
[Online]. Available: https://doi.org/10.1145/3571730
-
[35]
GitHub, “Codeql documentation,” Official documentation, 2026, accessed: 2026-04-27. [Online]. Available: https://codeql.github.com/ docs/
work page 2026
-
[36]
Agent Skills, “Agent skills,” Official documentation, 2026, accessed: 2026-04-22. [Online]. Available: https://agentskills.io/home
work page 2026
-
[37]
Deepseek-v3.2: Pushing the frontier of open large language models,
DeepSeek-AI, “Deepseek-v3.2: Pushing the frontier of open large language models,” 2025
work page 2025
-
[38]
Anthropic, “Claude code documentation,” Official documentation, 2026, accessed: 2026-04-27. [Online]. Available: https://code.claude. com/docs/
work page 2026
- [39]
-
[40]
Available: https://github.com/cyberark/Vulnhalla
[Online]. Available: https://github.com/cyberark/Vulnhalla
-
[41]
Vulnhalla: Picking the true vulnerabilities from a codeql haystack,
S. Kosman, “Vulnhalla: Picking the true vulnerabilities from a codeql haystack,” CyberArk Threat Research Blog, Dec. 2025. [Online]. Available: https://www.cyberark.com/resources/threat-research-blog/ vulnhalla-picking-the-true-vulnerabilities-from-the-codeql-haystack
work page 2025
-
[42]
Osv: Ghsa-3hcm- ggvf-rch5 (openclaw),
Open Source Vulnerabilities (OSV), “Osv: Ghsa-3hcm- ggvf-rch5 (openclaw),” OSV , 2026. [Online]. Available: https://osv.dev/vulnerability/GHSA-3hcm-ggvf-rch5
work page 2026
-
[43]
Understanding the reproducibility of crowd-reported security vulnerabilities,
D. Mu, A. Cuevas, L. Yang, H. Hu, X. Xing, B. Mao, and G. Wang, “Understanding the reproducibility of crowd-reported security vulnerabilities,” in27th USENIX Security Symposium (USENIX Security 18). Baltimore, MD: USENIX Association, Aug. 2018, pp. 919–936. [Online]. Available: https://www.usenix. org/conference/usenixsecurity18/presentation/mu
work page 2018
-
[44]
N. Alexopoulos, M. Brack, J. P. Wagner, T. Grube, and M. Mühlhäuser, “How long do vulnerabilities live in the code? a Large-Scale empirical measurement study on FOSS vulnerability lifetimes,” in31st USENIX Security Symposium (USENIX Security 22). Boston, MA: USENIX Association, Aug. 2022, pp. 359–376. [Online]. Available: https://www.usenix.org/ conferenc...
work page 2022
-
[45]
H. Zhang, Y . Pei, J. Chen, and S. H. Tan, “Statfier: Automated testing of static analyzers via semantic-preserving program transformations,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the F oundations of Software Engineering, ser. ESEC/FSE 2023. New York, NY , USA: Association for Computing Machinery, 20...
-
[46]
Towards understanding refactoring engine bugs,
H. Wang, Z. Xu, H. Zhang, N. Tsantalis, and S. H. Tan, “Towards understanding refactoring engine bugs,”ACM Trans. Softw. Eng. Methodol., vol. 35, no. 5, Apr. 2026. [Online]. Available: https://doi.org/10.1145/3747289
-
[47]
Rfcaudit: An llm agent for functional bug detection in network protocols,
M. Zheng, C. Wang, X. Liu, J. Guo, S. Feng, and X. Zhang, “Rfcaudit: An llm agent for functional bug detection in network protocols,”arXiv preprint arXiv:2506.00714, 2025
-
[48]
Understanding and detecting annotation-induced faults of static analyzers,
H. Zhang, Y . Pei, S. Liang, and S. H. Tan, “Understanding and detecting annotation-induced faults of static analyzers,”Proc. ACM Softw. Eng., vol. 1, no. FSE, Jul. 2024. [Online]. Available: https://doi.org/10.1145/3643759
-
[49]
Characterizing and detecting program representation faults of static analysis frameworks,
H. Zhang, Y . Pei, S. Liang, Z. Xing, and S. H. Tan, “Characterizing and detecting program representation faults of static analysis frameworks,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2024. New York, NY , USA: Association for Computing Machinery, 2024, p. 1772–1784. [Online]. Available: h...
-
[50]
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “Llms cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,” in2024 IEEE Symposium on Security and Privacy (SP), 2024, pp. 862–880
work page 2024
-
[51]
Demystifying rce vulnerabilities in llm-integrated apps,
T. Liu, Z. Deng, G. Meng, Y . Li, and K. Chen, “Demystifying rce vulnerabilities in llm-integrated apps,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1716–1730. [Online]. Available: https://doi.org/10.1145/3658644.3690338
-
[52]
Make agent defeat agent: Automatic detection of Taint-Style vulnerabilities in LLM-based agents,
F. Liu, Y . Zhang, J. Luo, J. Dai, T. Chen, L. Yuan, Z. Yu, Y . Shi, K. Li, C. Zhou, H. Chen, and M. Yang, “Make agent defeat agent: Automatic detection of Taint-Style vulnerabilities in LLM-based agents,” in34th USENIX Security Symposium (USENIX Security 25). Seattle, W A: USENIX Association, Aug. 2025, pp. 3767–3786. [Online]. Available: https://www.use...
work page 2025
-
[53]
Mirrorfuzz: Leveraging llm and shared bugs for deep learning framework apis fuzzing,
S. Ou, Y . Li, L. Yu, C. Wei, T. Wen, Q. Chen, Y . Chen, H. Tang, and Z. Pan, “Mirrorfuzz: Leveraging llm and shared bugs for deep learning framework apis fuzzing,”IEEE Transactions on Software Engineering, 2025
work page 2025
-
[54]
Y . Nong, H. Yang, L. Cheng, H. Hu, and H. Cai, “APPATCH: Automated adaptive prompting large language models for Real-World software vulnerability patching,” in34th USENIX Security Symposium (USENIX Security 25). Seattle, W A: USENIX Association, Aug. 2025, pp. 4481–4500. [Online]. Available: https://www.usenix.org/ conference/usenixsecurity25/presentation/nong
work page 2025
-
[55]
Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,
X. Du, G. Zheng, K. Wang, Y . Zou, Y . Wang, W. Deng, J. Feng, M. Liu, B. Chen, X. Penget al., “Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,”ACM Transactions on Software Engineering and Methodology, 2024
work page 2024
-
[56]
National Vulnerability Database, “Nvd - cve-2025-1793,” National Vulnerability Database, 2025, accessed: 2026-02-20. [Online]. Available: https://nvd.nist.gov/vuln/detail/CVE-2025-1793
work page 2025
-
[57]
——, “Nvd - cve-2025-1750,” National Vulnerability Database, 2025, accessed: 2026-02-20. [Online]. Available: https://nvd.nist.gov/ vuln/detail/CVE-2025-1750 Appendix A. Ethical Considerations This study relies only on the public repositories and pub- licly disclosed vulnerabilities. All validation is performed on local checkouts and isolated sandbox envir...
work page 2025
-
[58]
counts how many of the seven repositories contain the feature, and Cohort share reports the same count normalized by the seven repository cohort. Within this measurement range, counts of shared features are bounded by the same 12 binary features, while motif prevalence ranges from 0 to 7 repositories. In the current cohort, five of the eight measured feat...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.