Neural Collapse by Design: Learning Class Prototypes on the Hypersphere
Pith reviewed 2026-05-22 09:44 UTC · model grok-4.3
The pith
Both cross-entropy and supervised contrastive learning are variants of prototype contrast on the unit hypersphere, and fixing each at its failure point reaches neural collapse by design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Both cross-entropy and supervised contrastive learning are different appearances of the same method that contrasts prototypes on the unit hypersphere, and closing the gap requires fixing each at its point of failure. From the cross-entropy side we propose NTCE and NONL, two normalized losses that import contrastive optimization's missing ingredients: a large effective negative set and decoupled alignment and uniformity terms. From the supervised contrastive side we prove that its objective already optimizes throughout training for a principled classifier whose weights are the class mean embeddings, making linear probing both redundant and harmful.
What carries the argument
Contrasting class prototypes on the unit hypersphere, where features and prototypes are forced to unit length so that alignment to the correct prototype and uniformity across prototypes can be optimized separately.
If this is right
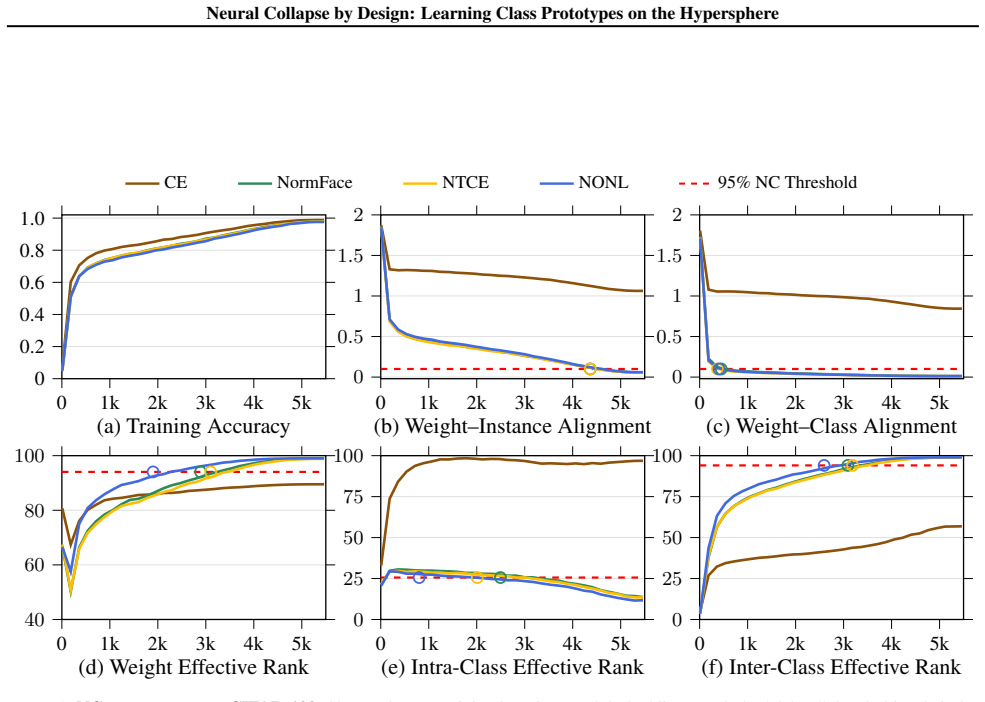
- NTCE and NONL surpass cross-entropy accuracy on four benchmarks including ImageNet-1K while approximating neural collapse at 95 percent or higher.
- They reach converged neural collapse metrics on four of five measures in under 7.5 percent of the iterations needed by cross-entropy.
- Supervised contrastive learning with fixed prototypes matches the accuracy of linear probing without the hours-long post-training classifier phase.
- The learned geometry produces a 5.5 percent mean relative gain in transfer learning and up to 8.7 percent under severe class imbalance.
- Robustness to corruptions improves on ImageNet-C.
Where Pith is reading between the lines
- If the unification is correct, the same hyperspherical prototype contrast principle could be applied directly to other supervised losses without first running contrastive pretraining.
- The proof that class-mean embeddings are the optimal classifier weights suggests initializing or periodically resetting the final linear layer to running class means during training.
- The approach may extend naturally to multi-label or long-tailed settings where maintaining uniform prototype spacing on the sphere is especially valuable.
- Viewing all supervised training as prototype placement on the sphere implies that the final geometry matters more than the particular loss used to reach it.
Load-bearing premise
The main defect in cross-entropy is its unconstrained radial degrees of freedom and that importing a large effective negative set plus decoupled alignment and uniformity terms will produce neural collapse without new side effects or hidden fitting.
What would settle it
Train a standard ResNet on ImageNet-1K with the proposed NTCE loss and check whether neural collapse metrics stay below 95 percent or final accuracy fails to exceed ordinary cross-entropy; if either occurs the central claim is refuted.
Figures

read the original abstract
Supervised classification has a theoretical optimum, Neural Collapse (NC), yet neither of its two dominant paradigms reaches it in practice. Cross entropy (CE) leaves radial degrees of freedom unconstrained and converges to a degenerate geometry, while supervised contrastive learning (SCL) drives features toward NC during pretraining but discards this structure in a post hoc linear probing phase. We show that both paradigms are different appearances of the same method that contrasts prototypes on the unit hypersphere, and that closing the gap requires fixing each at its point of failure. From the CE side, we propose NTCE and NONL, two normalized losses that import contrastive optimization's missing ingredients into classifier learning: a large effective negative set and decoupled alignment and uniformity terms. From the SCL side, we prove that SCL's objective already optimizes throughout training for a principled classifier whose weights are the class mean embeddings, making linear probing both redundant and harmful. Empirically, on four benchmarks including ImageNet-1K, NTCE and NONL surpass CE accuracy, closely approximate NC ($\geq 95\%$), and match CE's converged NC on 4/5 metrics in under $7.5\%$ of its iterations, while SCL with fixed prototypes matches linear probing without the hours-long classifier training phase. The learned geometry yields $+5.5\%$ mean relative improvement in transfer learning, up to $+8.7\%$ under severe class imbalance, and improved robustness to corruptions on ImageNet-C. Our work recasts supervised learning as prototype learning on the hypersphere, with NC reached by design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that neural collapse (NC) is the theoretical optimum for supervised classification but is not reached by standard cross-entropy (CE) or supervised contrastive learning (SCL). It argues both paradigms are equivalent appearances of prototype contrasting on the unit hypersphere. From the CE side it introduces NTCE and NONL, normalized losses that add a large effective negative set plus decoupled alignment/uniformity terms. From the SCL side it proves that the SCL objective already optimizes for a classifier whose weights are the class-mean embeddings, rendering linear probing redundant. Experiments on ImageNet-1K and three other benchmarks report accuracy gains, NC metrics ≥95%, faster convergence, +5.5% mean relative transfer improvement, and better robustness under imbalance and corruptions.
Significance. If the unification and the SCL proof hold, the work would recast supervised learning as hypersphere prototype learning and supply a design principle for reaching NC without post-hoc stages. The explicit proof that SCL optimizes class-mean embeddings is a clear strength, as is the empirical demonstration of high NC metrics and transfer gains on ImageNet-1K. The practical speed-up (NC reached in <7.5% of CE iterations) and robustness improvements would be noteworthy if the theoretical equivalence is made rigorous.
major comments (2)
- [Introduction / unification section] Introduction and the unification section: the central claim that CE and SCL are 'different appearances of the same method' that contrasts prototypes on the unit hypersphere requires an explicit gradient-level equivalence between NTCE's class-prototype negatives and SCL's instance-level batch negatives. The abstract states that NTCE imports 'a large effective negative set,' yet without showing that the resulting gradient w.r.t. normalized features exactly parallels the SCL gradient (including temperature scaling and negative weighting), the 'same method' assertion remains approximate and the transfer of the NC-by-design guarantee is not guaranteed.
- [SCL proof section] SCL proof (the section containing the claim that SCL optimizes for class-mean embeddings): the proof must specify whether the class means are treated as fixed or dynamically updated during training, and how the resulting classifier is shown to be 'principled' throughout optimization rather than only at convergence. If the derivation assumes fixed prototypes, it does not directly establish that linear probing is redundant or harmful at every stage.
minor comments (2)
- [Abstract / Experiments] The abstract reports NC metrics '≥95%' and 'match CE's converged NC on 4/5 metrics' but does not state the precise NC metrics used or whether they are averaged over multiple seeds; this should be clarified in the experimental section.
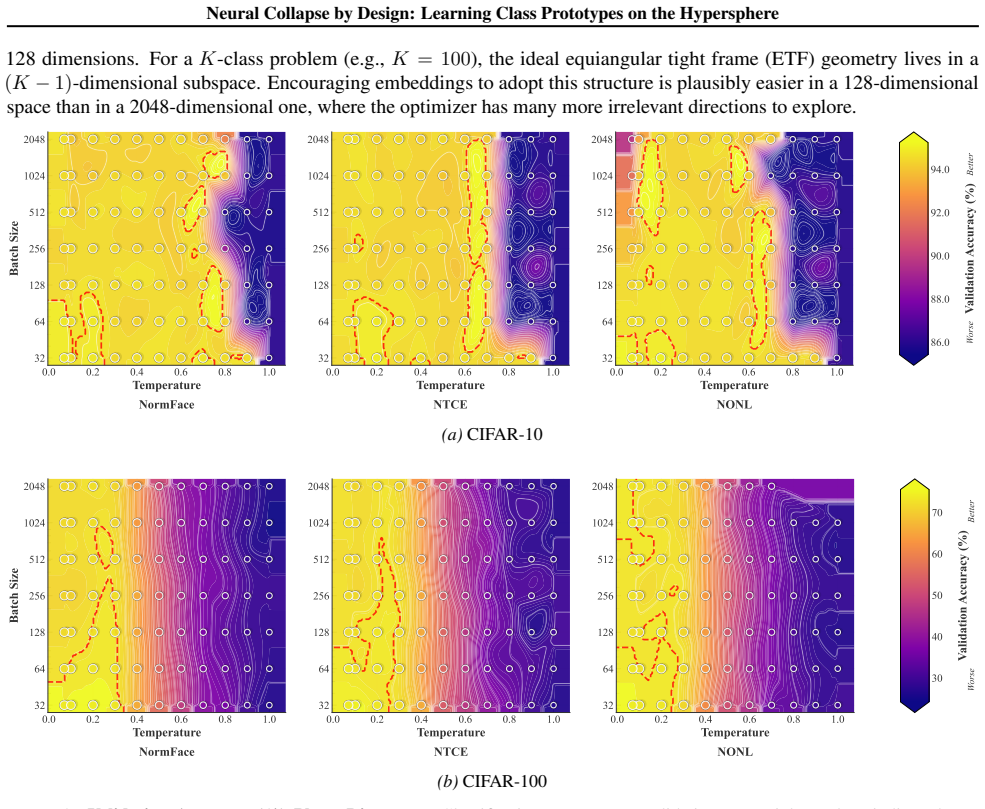
- [Method section] Notation for the new losses (NTCE, NONL) should be introduced with explicit equations showing the alignment and uniformity terms before the empirical comparisons.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments help clarify the scope of our unification claim and the SCL proof. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Introduction / unification section] Introduction and the unification section: the central claim that CE and SCL are 'different appearances of the same method' that contrasts prototypes on the unit hypersphere requires an explicit gradient-level equivalence between NTCE's class-prototype negatives and SCL's instance-level batch negatives. The abstract states that NTCE imports 'a large effective negative set,' yet without showing that the resulting gradient w.r.t. normalized features exactly parallels the SCL gradient (including temperature scaling and negative weighting), the 'same method' assertion remains approximate and the transfer of the NC-by-design guarantee is not guaranteed.
Authors: We agree that the unification would benefit from greater precision on the gradient relationship. The manuscript presents the equivalence at the level of the optimized geometry and the shared objective of prototype alignment plus uniformity on the hypersphere, rather than claiming identical per-step gradients. NTCE replaces instance negatives with class prototypes while preserving the normalized feature space and the decoupled alignment/uniformity structure; this yields the same NC fixed point but with different negative sampling. In the revision we will add a short appendix that derives the NTCE gradient for normalized features and explicitly compares its alignment term and effective negative weighting to the SCL gradient (including temperature). We will also qualify the abstract and introduction to state that the methods are equivalent in their design principle and NC optimum, while noting that the negative sets differ in construction. revision: partial
-
Referee: [SCL proof section] SCL proof (the section containing the claim that SCL optimizes for class-mean embeddings): the proof must specify whether the class means are treated as fixed or dynamically updated during training, and how the resulting classifier is shown to be 'principled' throughout optimization rather than only at convergence. If the derivation assumes fixed prototypes, it does not directly establish that linear probing is redundant or harmful at every stage.
Authors: We thank the referee for this clarification request. The proof treats the class means as the empirical means computed from the current embeddings at each training step; these means are therefore updated dynamically as the feature extractor evolves. The derivation shows that, for any fixed feature distribution at a given iteration, the SCL objective is minimized with respect to the linear classifier precisely when the classifier weights equal those instantaneous class means. Because this optimality condition holds with respect to the features present at every step, the resulting classifier remains principled throughout training rather than only at convergence. In the revision we will rewrite the relevant section to state explicitly that the means are recomputed from the current batch statistics at each iteration and that the optimality argument applies to the instantaneous feature distribution, thereby establishing redundancy of linear probing at all stages. revision: yes
Circularity Check
No significant circularity; derivations are independent reformulations with external benchmarks.
full rationale
The paper's core claims rest on explicit reformulations of CE into normalized variants (NTCE/NONL) that add large negative sets and decoupled alignment/uniformity terms, plus a proof that SCL's loss already targets class-mean embeddings on the hypersphere. These steps are presented as direct mathematical mappings and empirical checks on ImageNet-1K and other datasets rather than reductions to fitted parameters or self-citation chains. No load-bearing premise collapses to a prior result by the same authors or to an ansatz smuggled via citation; the unification is derived from the loss gradients and geometry, not assumed by construction. The work remains self-contained against external validation metrics.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that both paradigms are different appearances of the same method that contrasts prototypes on the unit hypersphere... NTCE and NONL... decoupled alignment and uniformity terms.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1 (Neural Collapse optimality of normalized losses)... simplex ETF class means... classifier–feature alignment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Are All Losses Created Equal: A Neural Collapse Perspective , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[2]
International Conference on Learning Representations , year=
On the Role of Neural Collapse in Transfer Learning , author=. International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , volume =
Inducing Neural Collapse in Imbalanced Learning: Do We Really Need a Learnable Classifier at the End of Deep Neural Network? , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
Advances in Neural Information Processing Systems , volume =
Hyperspherical Prototype Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Equiangular Basis Vectors , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[6]
International Conference on Learning Representations (ICLR) , year =
Visual Recognition with Deep Nearest Centroids , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Neural Collapse Inspired Knowledge Distillation , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[8]
Proceedings of the International Conference on Learning Representations , year=
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations , author=. Proceedings of the International Conference on Learning Representations , year=
-
[9]
International conference on machine learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[10]
Advances in neural information processing systems , volume=
Formal guarantees on the robustness of a classifier against adversarial manipulation , author=. Advances in neural information processing systems , volume=
-
[11]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[12]
L2-constrained Softmax Loss for Discriminative Face Verification
L2-Constrained Softmax Loss for Discriminative Face Verification , author =. arXiv preprint arXiv:1703.09507 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =
No Fuss Distance Metric Learning Using Proxies , author =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages =. 2017 , doi =
work page 2017
-
[14]
International Conference on Learning Representations (ICLR) , year =
Fixed Non-Negative Orthogonal Classifier: Inducing Zero-Mean Neural Collapse with Feature Dimension Separation , author =. International Conference on Learning Representations (ICLR) , year =
-
[15]
Proceedings of the National Academy of Sciences , volume=
Prevalence of neural collapse during the terminal phase of deep learning training , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , doi=
work page 2020
-
[16]
Journal of Machine Learning Research , volume=
The Implicit Bias of Gradient Descent on Separable Data , author=. Journal of Machine Learning Research , volume=. 2018 , url=
work page 2018
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Spectrally-normalized margin bounds for neural networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[18]
Neyshabur, Behnam and Bhojanapalli, Srinadh and Srebro, Nathan , booktitle=. A. 2018 , url=
work page 2018
-
[19]
Kornblith, Simon and Shlens, Jonathon and Le, Quoc V. , booktitle=. Do Better. 2019 , url=
work page 2019
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Supervised Contrastive Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Robustness of classifiers: from adversarial to random noise , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[22]
Gavin Weiguang Ding and Yash Sharma and Kry Yik Chau Lui and Ruitong Huang , booktitle=. 2020 , url=
work page 2020
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Neural Collapse with Normalized Features: A Geometric Analysis over the Riemannian Manifold , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[24]
Applied and Computational Harmonic Analysis , volume=
Neural Collapse under Cross-Entropy Loss , author=. Applied and Computational Harmonic Analysis , volume=. 2022 , doi=
work page 2022
-
[25]
International Conference on Machine Learning , pages=
Unveiling the Dynamics of Information Interplay in Supervised Learning , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[26]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
work page 2007
-
[27]
Proceedings of the 41st International Conference on Machine Learning , pages=
Matrix information theory for self-supervised learning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[28]
Advances in Neural Information Processing Systems , volume=
Imbalance trouble: Revisiting neural-collapse geometry , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Machine Learning , pages=
On the optimization landscape of neural collapse under mse loss: Global optimality with unconstrained features , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[30]
Advances in Neural Information Processing Systems , volume=
A geometric analysis of neural collapse with unconstrained features , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
On the Existence of Maximum Likelihood Estimates in Logistic Regression Models , author=. Biometrika , volume=. 1984 , publisher=
work page 1984
-
[32]
Journal of Machine Learning Research , volume=
Neural Collapse for Unconstrained Feature Model under Cross-Entropy Loss with Imbalanced Data , author=. Journal of Machine Learning Research , volume=
-
[33]
Wang, Feng and Xiang, Xiang and Cheng, Jian and Yuille, Alan L. , booktitle=. 2017 , doi=
work page 2017
-
[34]
Liu, Weiyang and Wen, Yandong and Yu, Zhiding and Li, Ming and Raj, Bhiksha and Song, Le , booktitle=
-
[35]
Wang, Hao and Wang, Yitong and Zhou, Zheng and Ji, Xing and Gong, Dihong and Zhou, Jingchao and Li, Zhifeng and Liu, Wei , booktitle=
-
[36]
Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos , booktitle=
-
[37]
Han and Vardan Papyan and David L
X.Y. Han and Vardan Papyan and David L. Donoho , booktitle=. Neural Collapse Under. 2022 , url=
work page 2022
-
[38]
Proceedings of the National Academy of Sciences , volume=
Exploring Deep Neural Networks via Layer-Peeled Model: Minority Collapse in Imbalanced Training , author=. Proceedings of the National Academy of Sciences , volume=. 2021 , doi=
work page 2021
-
[39]
arXiv preprint arXiv:2110.02796 , year=
An Unconstrained Layer-Peeled Perspective on Neural Collapse , author=. arXiv preprint arXiv:2110.02796 , year=
-
[40]
A Theoretical Framework for Preventing Class Collapse in Supervised Contrastive Learning , author=
-
[41]
Proceedings of the 39th International Conference on Machine Learning , series =
Extended Unconstrained Features Model for Exploring Deep Neural Collapse , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
work page 2022
-
[42]
International Conference on Machine Learning , pages=
Dissecting supervised contrastive learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
- [43]
-
[44]
arXiv preprint arXiv:2011.11619 , year =
Neural Collapse with Unconstrained Features , author =. arXiv preprint arXiv:2011.11619 , year =
-
[45]
International Conference on Learning Representations , year =
An Unconstrained Layer-Peeled Perspective on Neural Collapse , author =. International Conference on Learning Representations , year =
-
[46]
International Conference on Learning Representations , year =
Long-Tail Learning via Logit Adjustment , author =. International Conference on Learning Representations , year =
-
[47]
Advances in Neural Information Processing Systems , volume =
Prototypical Networks for Few-shot Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[48]
Advances in Neural Information Processing Systems , volume=
Guiding neural collapse: Optimising towards the nearest simplex equiangular tight frame , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[50]
International Conference on Machine Learning , pages=
Bridging Mini-Batch and Asymptotic Analysis in Contrastive Learning: From InfoNCE to Kernel-Based Losses , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[51]
European Conference on Computer Vision , pages=
Decoupled contrastive learning , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Unsupervised feature learning by cross-level instance-group discrimination , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
Journal of Machine Learning Research , volume =
Neural Collapse for Unconstrained Feature Model under Class-Imbalance , author =. Journal of Machine Learning Research , volume =. 2024 , url =
work page 2024
-
[54]
arXiv preprint arXiv:2202.08384 , year =
Limitations of Neural Collapse for Understanding Generalization in Deep Learning , author =. arXiv preprint arXiv:2202.08384 , year =
-
[55]
Proceedings of the National Academy of Sciences , volume =
Exploring Deep Neural Networks via Layer-Peeled Model: Minority Collapse in Imbalanced Training , author =. Proceedings of the National Academy of Sciences , volume =. 2021 , doi =
work page 2021
-
[56]
Advances in Computational Mathematics , volume =
Finite Normalized Tight Frames , author =. Advances in Computational Mathematics , volume =. 2003 , doi =
work page 2003
-
[57]
Experimental Mathematics , volume =
Packing Lines, Planes, etc.: Packings in Grassmannian Spaces , author =. Experimental Mathematics , volume =. 1996 , url =
work page 1996
-
[58]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[59]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [60]
-
[61]
Symmetric Neural-Collapse Representations with Supervised Contrastive Loss: The Impact of
Kini, Ganesh Ramachandra and Vakilian, Vala and Behnia, Tina and Gilani Tehrani-Saadi, Jaiden and Thrampoulidis, Christos , booktitle =. Symmetric Neural-Collapse Representations with Supervised Contrastive Loss: The Impact of
-
[62]
Engineering the Neural Collapse Geometry of Supervised-Contrastive Loss , author =. ICASSP 2024 -- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2024 , organization =
work page 2024
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Neural Collapse versus Low-Rank Bias: Is Deep Neural Collapse Really Optimal? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Deep Neural Collapse Is Provably Optimal for the Deep Unconstrained Features Model , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[65]
International Conference on Machine Learning (ICML) , year =
Perfectly Balanced: Improving Transfer and Robustness of Supervised Contrastive Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[66]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Why Do Better Loss Functions Lead to Less Transferable Features? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[67]
International Conference on Machine Learning (ICML) , year =
Controlling Neural Collapse Enhances Out-of-Distribution Detection and Transfer Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[68]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Associative Embedding: End-to-End Learning for Joint Detection and Grouping , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[69]
Semantic Instance Segmentation with a Discriminative Loss Function
Semantic Instance Segmentation with a Discriminative Loss Function , author =. arXiv preprint arXiv:1708.02551 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[71]
Orthogonal Weight Normalization: Solution to Optimization over Multiple Dependent
Huang, Lei and Liu, Xianglong and Lang, Bo and Yu, Adams Wei and Wang, Yongliang and Li, Bo , booktitle =. Orthogonal Weight Normalization: Solution to Optimization over Multiple Dependent
-
[72]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Can We Gain More from Orthogonality Regularizations in Training Deep Networks? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[73]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[74]
International Conference on Learning Representations (ICLR) , year =
Spectral Normalization for Generative Adversarial Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[75]
ICML Workshop on Identifying and Understanding Deep Learning Phenomena , year =
Layer Rotation: a Surprisingly Simple Indicator of Generalization in Deep Networks? , author =. ICML Workshop on Identifying and Understanding Deep Learning Phenomena , year =
-
[76]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, Priya and Doll. Accurate, Large Minibatch. arXiv preprint arXiv:1706.02677 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Deep Residual Learning for Image Recognition , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[78]
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle =
-
[79]
Learning Multiple Layers of Features from Tiny Images , author =
-
[80]
Bossard, Lukas and Guillaumin, Matthieu and Van Gool, Luc , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.