Corrected Integrated Laplace Approximation for Bayesian Inference in Latent Gaussian Models
Pith reviewed 2026-05-21 07:18 UTC · model grok-4.3
The pith
Importance sampling corrects the integrated Laplace approximation so the posterior converges to the true one in latent Gaussian models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
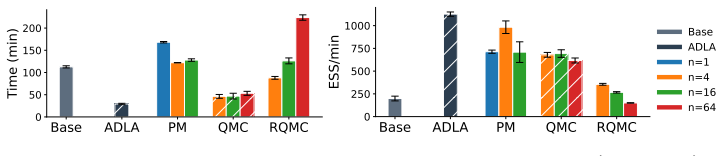
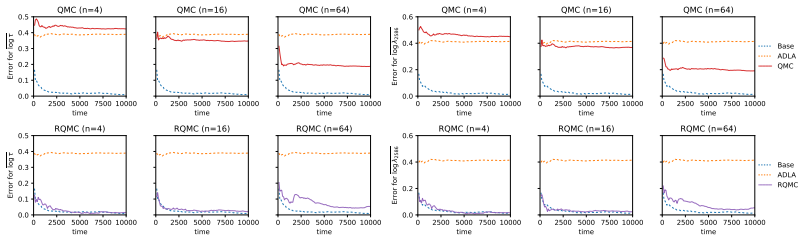
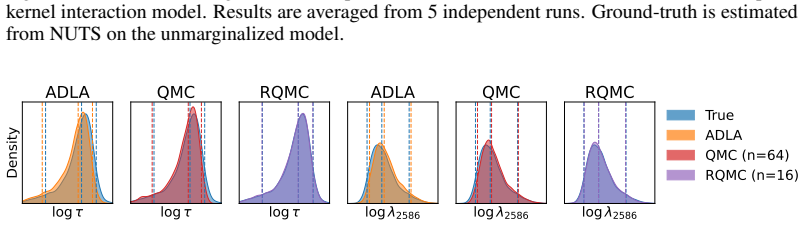
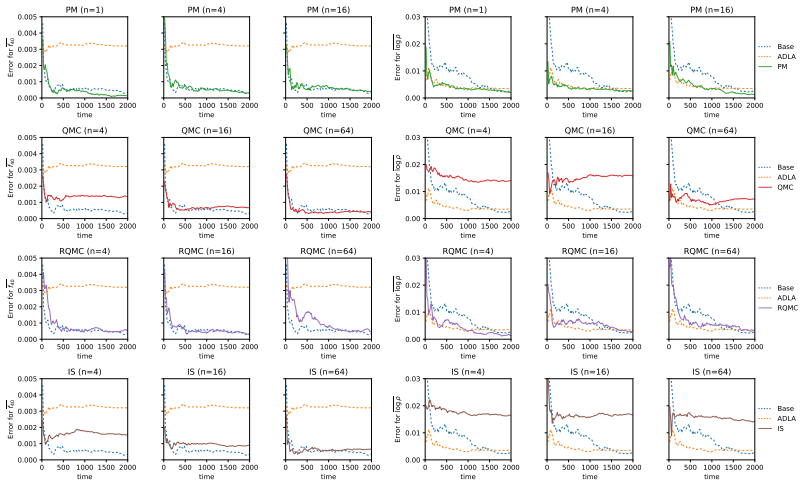
The authors propose an importance sampling scheme to correct the error introduced by the integrated Laplace approximation. By increasing the number of samples in importance sampling, the posterior with ILA converges to the correct posterior. This idea is realized with various techniques, including pseudo-marginalization, quasi-Monte Carlo and randomized quasi-Monte Carlo. The methods are implemented in an automatic differentiation framework to support gradient-based algorithms when doing inference on the hyperparameters, specifically considering Hamiltonian Monte Carlo.
What carries the argument
The importance sampling correction to the integrated Laplace approximation (ILA), which adjusts the marginal likelihood estimate so that the resulting posterior converges to the exact posterior as sample size grows.
If this is right
- The corrected posterior can be used directly in downstream tasks with substantially lower error than plain ILA.
- Hyperparameter inference proceeds with standard gradient-based algorithms such as Hamiltonian Monte Carlo.
- The same correction framework applies to Gaussian processes, spatial models, and mixed-effect models.
- Convergence to the true posterior is obtained simply by increasing the importance sample size without altering the base Laplace approximation.
Where Pith is reading between the lines
- The sampling correction could be paired with other marginalization schemes to handle hierarchical models outside the current latent-Gaussian class.
- Adaptive or learned proposal distributions might reduce the sample count needed to reach a target accuracy level.
- The automatic-differentiation implementation suggests straightforward extension to larger-scale problems where gradient information is already available.
Load-bearing premise
A suitable proposal distribution exists for the importance sampler such that the correction is both effective and computationally tractable across the range of latent Gaussian models considered.
What would settle it
Compute the exact posterior for a simple latent Gaussian model with non-Gaussian likelihood and verify whether the discrepancy with the importance-sampling-corrected ILA posterior shrinks toward zero as the number of importance samples is increased.
Figures





read the original abstract
Latent Gaussian models (LGMs) are a popular class of Bayesian hierarchical models that include Gaussian processes, as well as certain spatial models and mixed-effect models. Efficient Bayesian inference of LGMs often requires marginalizing out the latent variables. For LGMs with a non-Gaussian likelihood, exact marginalization is not possible and a popular approach is to do approximate marginalization with an integrated Laplace approximation (ILA). Using ILA produces an approximate posterior which, in some settings, can differ significantly from the correct posterior, which impacts downstream applications. We propose an importance sampling scheme to correct the error introduced by ILA. By increasing the number of samples in importance sampling, the posterior with ILA converges to the correct posterior. This idea is realized with various techniques, including pseudo-marginalization, quasi-Monte Carlo and randomized quasi-Monte Carlo. We implement our methods in an automatic differentiation framework to support gradient-based algorithms when doing inference on the hyperparameters. For the latter, we specifically consider the use of Hamiltonian Monte Carlo. We demonstrate the benefits of reduced error in various applied models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an importance sampling scheme to correct errors from the integrated Laplace approximation (ILA) when marginalizing latent variables in latent Gaussian models (LGMs) with non-Gaussian likelihoods. The central claim is that the corrected posterior converges to the exact posterior as the number of importance samples increases. Realizations include pseudo-marginal, quasi-Monte Carlo (QMC), and randomized QMC methods, with implementation in an automatic differentiation framework to enable gradient-based hyperparameter inference via Hamiltonian Monte Carlo (HMC). Benefits are demonstrated on applied models including Gaussian processes and spatial models.
Significance. If a low-variance proposal can be constructed that remains tractable, the correction would meaningfully reduce ILA-induced bias in LGMs where approximation error affects downstream tasks. The AD/HMC integration and QMC variants are practical strengths that could improve efficiency over naive sampling corrections.
major comments (2)
- [Abstract] Abstract: The convergence claim ('by increasing the number of samples in importance sampling, the posterior with ILA converges to the correct posterior') is load-bearing but rests on the unstated assumption that a proposal distribution q exists whose support contains the target and whose importance weights have controlled variance. In high-dimensional LGMs the posterior is typically far from Gaussian; any proposal derived from the Laplace approximation will have poor overlap exactly where ILA error is largest, undermining both unbiasedness (for pseudo-marginal HMC) and computational feasibility.
- [Methods] Methods (proposal construction): The manuscript lists pseudo-marginal, QMC and RQMC realizations but does not specify how the importance proposal is built or adapted to the hyperparameters. Without this detail it is impossible to verify that the scheme remains both unbiased and tractable across the range of latent dimensions and likelihoods considered.
minor comments (2)
- [Methods] Notation for the corrected posterior and the importance weights should be introduced with a single consistent equation early in the methods to avoid later ambiguity.
- [Experiments] The empirical demonstrations would benefit from explicit reporting of effective sample size or variance of the importance weights to substantiate the practical convergence rate.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major point below, clarifying the assumptions underlying our convergence claim and providing additional details on proposal construction. We have revised the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The convergence claim ('by increasing the number of samples in importance sampling, the posterior with ILA converges to the correct posterior') is load-bearing but rests on the unstated assumption that a proposal distribution q exists whose support contains the target and whose importance weights have controlled variance. In high-dimensional LGMs the posterior is typically far from Gaussian; any proposal derived from the Laplace approximation will have poor overlap exactly where ILA error is largest, undermining both unbiasedness (for pseudo-marginal HMC) and computational feasibility.
Authors: We agree that the stated convergence relies on standard importance sampling assumptions: the proposal q must have support containing that of the target posterior and the importance weights must have finite variance for practical convergence. These conditions were implicit but will now be stated explicitly in the revised abstract and methods. Regarding high-dimensional LGMs, we acknowledge that a Laplace-derived proposal can have limited overlap where the ILA error is largest, which may lead to high variance and affect computational feasibility for pseudo-marginal HMC. However, the estimator remains unbiased (and thus the corrected posterior converges) as the number of samples tends to infinity whenever the support condition holds, independent of dimension. We will add a new paragraph discussing proposal quality, variance control strategies (including the QMC variants already in the paper), and practical limitations in high dimensions. revision: yes
-
Referee: [Methods] Methods (proposal construction): The manuscript lists pseudo-marginal, QMC and RQMC realizations but does not specify how the importance proposal is built or adapted to the hyperparameters. Without this detail it is impossible to verify that the scheme remains both unbiased and tractable across the range of latent dimensions and likelihoods considered.
Authors: We thank the referee for highlighting this omission. The original manuscript emphasized the general framework and its realizations but did not provide a self-contained description of proposal construction. In the revised manuscript we will insert a dedicated subsection that (i) specifies the default proposal as the Gaussian approximation obtained from the Laplace step, (ii) describes how the proposal is re-centered and re-scaled when hyperparameters change during outer-loop inference, and (iii) outlines simple adaptation heuristics (e.g., moment matching or low-rank updates) that preserve unbiasedness while remaining tractable. These additions will allow readers to verify the conditions for unbiasedness and computational feasibility across the latent dimensions and likelihoods considered in the experiments. revision: yes
Circularity Check
No circularity: importance sampling correction is a standard, independently motivated technique
full rationale
The paper proposes using importance sampling (including pseudo-marginal, QMC, and RQMC variants) to correct the known approximation error of ILA in LGMs, with the claim that the corrected posterior converges to the exact one as the number of samples grows. This follows directly from the standard properties of importance sampling and does not reduce to any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. The derivation chain is self-contained and relies on external statistical results rather than circular internal constructions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Integrated Laplace approximation introduces a correctable error for non-Gaussian likelihoods in latent Gaussian models.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an importance sampling scheme to correct the error introduced by ILA. By increasing the number of samples in importance sampling, the posterior with ILA converges to the correct posterior.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1. ... ˆπz(θ, y) is an unbiased estimator of π(θ, y).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The kernel interaction trick: Fast Bayesian discovery of pairwise interactions in high dimensions
Raj Agrawal, Brian Trippe, Jonathan Huggins, and Tamara Broderick. The kernel interaction trick: Fast Bayesian discovery of pairwise interactions in high dimensions. InInternational Conference on Machine Learning, pages 141–150. PMLR, 2019
work page 2019
-
[2]
Pseudo-marginal Hamiltonian Monte Carlo.Journal of Machine Learning Research, 22(141):1–45, 2021
Johan Alenlöv, Arnoud Doucet, and Fredrik Lindsten. Pseudo-marginal Hamiltonian Monte Carlo.Journal of Machine Learning Research, 22(141):1–45, 2021
work page 2021
-
[3]
Christophe Andrieu and Gareth O. Roberts. The pseudo-marginal approach for efficient Monte Carlo computations.The Annals of Statistics, 37(2), April 2009. ISSN 0090-5364
work page 2009
-
[4]
Survival Regression with Accelerated Failure Time Model in XGBoost
Martin Outzen Berild, Sara Martino, Virgilio Gómez-Rubio, and Håvard Rue. Importance sampling with the integrated nested Laplace approximation.Journal of Computational and Graphical Statistics, 31(4):1225–1237, 2022. doi: 10.1080/10618600.2022.2067551
-
[5]
Hamiltonian Monte Carlo for hierarchical models
Michael Betancourt and Mark Girolami. Hamiltonian Monte Carlo for hierarchical models. In Current Trends in Bayesian Methodology with Applications, page 24. Chapman and Hall/CRC,
-
[6]
doi: 10.1201/b18502-5
-
[7]
Eli Bingham, Jonathan P Chen, Martin Jankowiak, Fritz Obermeyer, Neeraj Pradhan, Theofanis Karaletsos, Rohit Singh, Paul Szerlip, Paul Horsfall, and Noah D Goodman. Pyro: Deep universal probabilistic programming.Journal of machine learning research, 20(28):1–6, 2019
work page 2019
-
[8]
Negative binomial loglinear mixed models.Statistical Modelling, 3(3):179–191, 2003
James G Booth, George Casella, Herwig Friedl, and James P Hobert. Negative binomial loglinear mixed models.Statistical Modelling, 3(3):179–191, 2003
work page 2003
-
[9]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/jax-ml/jax
work page 2018
-
[10]
and Kristensen, Kasper and van Benthem, Koen J
Mollie E. Brooks, Kasper Kristensen, Koen J. van Benthem, Arni Magnusson, Casper W. Berg, Anders Nielsen, Hans J. Skaug, Martin Maechler, and Benjamin M. Bolker. glmmTMB balances speed and flexibility among packages for zero-inflated generalized linear mixed modeling.The R Journal, 9(2):378–400, 2017. doi: 10.32614/RJ-2017-066
-
[11]
Sample average approximation for black- box variational inference
Javier Burroni, Justin Domke, and Daniel Sheldon. Sample average approximation for black- box variational inference. In Negar Kiyavash and Joris M. Mooij, editors,Proceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence, volume 244 ofProceedings of Machine Learning Research, pages 471–498. PMLR, 15–19 Jul 2024
work page 2024
-
[12]
BlackJAX: composable Bayesian inference in JAX.arXiv preprint arXiv:2402.10797, 2024
Alberto Cabezas, Adrien Corenflos, Junpeng Lao, Rémi Louf, Antoine Carnec, Kaustubh Chaudhari, Reuben Cohn-Gordon, Jeremie Coullon, Wei Deng, Sam Duffield, et al. BlackJAX: composable Bayesian inference in JAX.arXiv preprint arXiv:2402.10797, 2024. 10
-
[13]
Monte Carlo and quasi-Monte Carlo methods.Acta numerica, 7:1–49, 1998
Russel E Caflisch. Monte Carlo and quasi-Monte Carlo methods.Acta numerica, 7:1–49, 1998
work page 1998
-
[14]
Stan: A probabilistic programming language.Journal of statistical software, 76:1–32, 2017
Bob Carpenter, Andrew Gelman, Matthew D Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell. Stan: A probabilistic programming language.Journal of statistical software, 76:1–32, 2017
work page 2017
-
[15]
Cristian Chiuchiolo, Janet van Niekerk, and Håvard Rue. An extended simplified Laplace strategy for approximate Bayesian inference of latent Gaussian models using R-INLA. arXiv:2203.14304, 2022
-
[16]
Justin Domke and Daniel R Sheldon. Importance weighting and variational inference.Advances in neural information processing systems, 31, 2018
work page 2018
-
[17]
Justin Domke and Daniel R Sheldon. Divide and couple: Using Monte Carlo variational objectives for posterior approximation.Advances in neural information processing systems, 32, 2019
work page 2019
-
[18]
Hybrid Monte Carlo.Physics letters B, 195(2):216–222, 1987
Simon Duane, Anthony D Kennedy, Brian J Pendleton, and Duncan Roweth. Hybrid Monte Carlo.Physics letters B, 195(2):216–222, 1987
work page 1987
-
[19]
Egil Ferkingstad and Håvard Rue. Improving the INLA approach for approximate Bayesian inference for latent Gaussian models.Electronic Journal of Statistics, 9(2):2706–2731, 2015. doi: 10.1214/15-EJS1092
-
[20]
Wally R Gilks, Nicky G Best, and Keith KC Tan. Adaptive rejection Metropolis sampling within Gibbs sampling.Journal of the Royal Statistical Society Series C: Applied Statistics, 44 (4):455–472, 1995
work page 1995
-
[21]
Ryan Giordano, Martin Ingram, and Tamara Broderick. Black box variational inference with a deterministic objective: Faster, more accurate, and even more black box.Journal of Machine Learning Research, 25(18):1–39, 2024
work page 2024
-
[22]
Automatic reparameterisation of proba- bilistic programs
Maria Gorinova, Dave Moore, and Matthew Hoffman. Automatic reparameterisation of proba- bilistic programs. InInternational Conference on Machine Learning, pages 3648–3657. PMLR, 2020
work page 2020
-
[23]
NeuTra-lizing Bad Geometry in Hamiltonian Monte Carlo Using Neural Transport
Matthew Hoffman, Pavel Sountsov, Joshua V Dillon, Ian Langmore, Dustin Tran, and Srinivas Vasudevan. NeuTra-lizing bad geometry in Hamiltonian Monte Carlo using neural transport. arXiv preprint arXiv:1903.03704, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[24]
The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo.J
Matthew D Hoffman, Andrew Gelman, et al. The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo.J. Mach. Learn. Res., 15(1):1593–1623, 2014
work page 2014
-
[25]
Model-informed flows for Bayesian inference
Joohwan Ko and Justin Domke. Model-informed flows for Bayesian inference. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[26]
Kasper Kristensen, Anders Nielsen, Casper W Berg, Hans Skaug, and Bradley M Bell. TMB: automatic differentiation and Laplace approximation.Journal of statistical software, 70:1–21, 2016
work page 2016
-
[27]
Jinlin Lai, Justin Domke, and Daniel R Sheldon. Hamiltonian Monte Carlo inference of marginalized linear mixed-effects models.Advances in Neural Information Processing Systems, 37:29435–29463, 2024
work page 2024
-
[28]
Charles Margossian, Aki Vehtari, Daniel Simpson, and Raj Agrawal. Hamiltonian Monte Carlo using an adjoint-differentiated Laplace approximation: Bayesian inference for latent Gaussian models and beyond.Advances in neural information processing systems, 33:9086–9097, 2020
work page 2020
-
[29]
General adjoint-differentiated Laplace approximation.arXiv preprint arXiv:2306.14976, 2023
Charles C Margossian. General adjoint-differentiated Laplace approximation.arXiv preprint arXiv:2306.14976, 2023
-
[30]
Charles C. Margossian and Lawrence K. Saul. Generalized guarantees for variational inference in the presence of even and elliptical symmetry.arXiv:2511.01064, 2025. 11
-
[31]
Cole C Monnahan and Kasper Kristensen. No-U-turn sampling for fast Bayesian inference in ADMB and TMB: Introducing the adnuts and tmbstan R packages.PloS one, 13(5):e0197954, 2018
work page 2018
-
[32]
Radford M. Neal. MCMC using Hamiltonian dynamics. InHandbook of Markov Chain Monte Carlo. Chapman & Hall / CRC Press, 2012
work page 2012
-
[33]
John Ashworth Nelder and Robert WM Wedderburn. Generalized linear models.Journal of the Royal Statistical Society Series A: Statistics in Society, 135(3):370–384, 1972
work page 1972
-
[34]
Monte Carlo, quasi-Monte Carlo, and randomized quasi-Monte Carlo
Art B Owen. Monte Carlo, quasi-Monte Carlo, and randomized quasi-Monte Carlo. In Monte-Carlo and Quasi-Monte Carlo Methods 1998: Proceedings of a Conference held at the Claremont Graduate University, Claremont, California, USA, June 22–26, 1998, pages 86–97. Springer, 2000
work page 1998
-
[35]
Omiros Papaspiliopoulos, Gareth O Roberts, and Martin Sköld. A general framework for the parametrization of hierarchical models.Statistical Science, pages 59–73, 2007
work page 2007
-
[36]
Matthew D Parno and Youssef M Marzouk. Transport map accelerated Markov chain Monte Carlo.SIAM/ASA Journal on Uncertainty Quantification, 6(2):645–682, 2018
work page 2018
-
[37]
Composable Effects for Flexible and Accelerated Probabilistic Programming in NumPyro
Du Phan, Neeraj Pradhan, and Martin Jankowiak. Composable effects for flexible and acceler- ated probabilistic programming in NumPyro.arXiv preprint arXiv:1912.11554, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[38]
Håvard Rue, Sara Martino, and Nicolas Chopin. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations.Journal of the Royal Statistical Society Series B: Statistical Methodology, 71(2):319–392, 2009
work page 2009
-
[39]
Havard Rue, Andrea Riebler, Sigrunn Sorbye, Janine Illian, Daniel Simson, and Finn Lindgren. Bayesian computing with INLA: A review.Annual Review of Statistics and its Application, 4: 395 – 421, 2017. doi: https://doi.org/10.1146/annurev-statistics-060116-054045
-
[40]
Z. Shun and P. McCullagh. Laplace approximation of high dimensional integrals.Journal of the Royal Statistical Society: Series B, 57(4):749–760, 1995
work page 1995
-
[41]
Luke Tierney and Joseph B Kadane. Accurate approximations for posterior moments and marginal densities.Journal of the american statistical association, 81(393):82–86, 1986
work page 1986
-
[42]
Jarno Vanhatalo, Pasi Jylänki, and Aki Vehtari. Gaussian process regression with a student-t likelihood.Advances in Neural Information Processing Systems, 22:1910–1918, 2009
work page 1910
-
[43]
Jarno Vanhatalo, Ville Pietiläinen, and Aki Vehtari. Approximate inference for disease mapping with sparse Gaussian processes.Statistics in medicine, 29(15):1580–1607, 2010
work page 2010
-
[44]
Jarno Vanhatalo, Jaakko Riihimäki, Jouni Hartikainen, Pasi Jylänki, Ville Tolvanen, and Aki Vehtari. GPstuff: Bayesian modeling with Gaussian processes.The Journal of Machine Learning Research, 14(1):1175–1179, 2013
work page 2013
-
[45]
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learning, volume 2. MIT press Cambridge, MA, 2006
work page 2006
-
[46]
Corrected Integrated Laplace Approximation
Yuling Yao, Aki Vehtari, Daniel Simpson, and Andrew Gelman. Yes, but did it work?: Evalu- ating variational inference. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 5581–5590. PMLR, 2018. 12 Appendices to “Corrected Integrated Laplace Approximation” A Proof of the theori...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.