Consistently Informative Soft-Label Temperature for Knowledge Distillation
Pith reviewed 2026-05-21 08:10 UTC · model grok-4.3
The pith
Separate sample-wise adaptive temperatures for teacher and student produce consistently informative soft labels and lift knowledge distillation performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
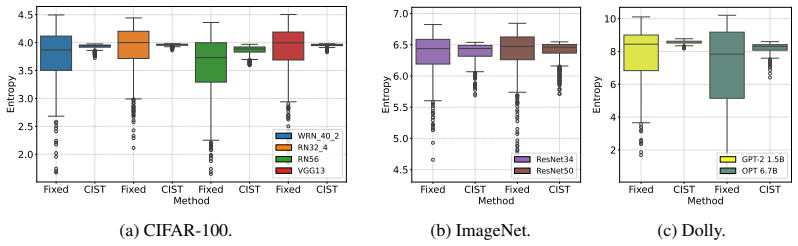
Teacher-label entropy is largely governed by the ratio of the largest teacher logit to the temperature. By selecting a separate adaptive temperature for the teacher and for the student on each sample, CIST keeps this ratio stable across the batch, produces soft labels whose entropy supplies useful dark knowledge without becoming either over-sharp or over-smoothed, and relaxes the rigid logit-scale alignment that fixed-temperature KD imposes despite the capacity gap between models.
What carries the argument
The max-logit ratio rule that sets a distinct temperature for the teacher and a distinct temperature for the student on each training sample, thereby controlling entropy independently while reweighting the distillation loss by teacher confidence and student difficulty.
If this is right
- Teacher soft labels maintain more uniform entropy across samples, supplying steadier inter-class information.
- Rigid logit-scale matching between teacher and student is no longer required, accommodating their capacity difference.
- The distillation loss can be reweighted according to both teacher confidence and student learning difficulty.
- The same method yields measurable accuracy gains on both vision classification and language-modeling distillation with negligible added cost.
Where Pith is reading between the lines
- The same per-sample temperature logic could be inserted into other distillation losses that currently rely on a global temperature.
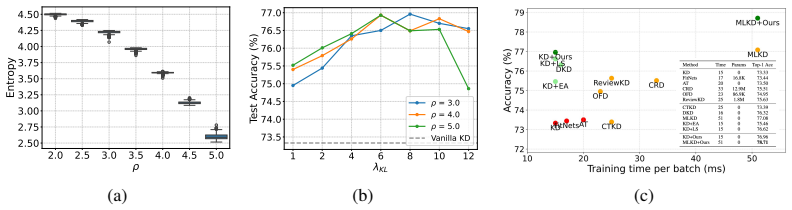
- In settings with highly variable sample difficulty, the adaptive rule might reduce the amount of manual temperature search needed.
- Because the rule depends only on the teacher's max logit, it could transfer to distillation pipelines where the student architecture changes frequently.
Load-bearing premise
That temperatures chosen per sample via the max-logit ratio will reliably increase useful information transfer without creating new inconsistencies or demanding per-task retuning that cancels the reported gains.
What would settle it
On a held-out vision or language task, run standard KD with its best fixed temperature against CIST using the max-logit rule; if the student accuracy under CIST is no higher than the fixed-temperature baseline or if the per-sample entropies remain as inconsistent as before, the central claim is refuted.
Figures


read the original abstract
Knowledge distillation (KD) transfers knowledge from a high-capacity teacher to a compact student by matching their predictive distributions, with temperature scaling serving as a central mechanism for smoothing teacher predictions and exposing informative "dark knowledge" beyond the hard label. However, the standard fixed-temperature design is inherently sample-agnostic. Since samples differ in logit scale and learning difficulty, a single global temperature produces teacher soft labels with highly inconsistent entropy: some predictions remain overly sharp and provide limited inter-class information, whereas others become over-smoothed and lose class-discriminative information. Moreover, sharing the same temperature between teacher and student further imposes rigid logit-scale alignment despite their capacity mismatch. To address these limitations, we propose CIST (Consistently Informative Soft-label Temperature), which assigns separate sample-wise adaptive temperatures to the teacher and student. This design produces consistently informative teacher soft labels while relaxing rigid teacher--student logit-scale matching. It also reweights the distillation objective according to teacher confidence and student learning difficulty. Theoretically, we show that teacher-label entropy is largely governed by the ratio between the maximum teacher logit and the temperature, providing a principled basis for adaptive smoothing. Empirically, CIST mitigates the inconsistency induced by fixed temperature, and experiments on both vision and language distillation tasks show consistent improvements over standard KD and strong baselines with negligible computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CIST, a knowledge distillation method that assigns separate sample-wise adaptive temperatures to the teacher and student. Temperatures are set via a max-logit ratio rule (T_t = max(logits_t)/c) to produce consistently informative soft labels whose entropy is claimed to be largely governed by this ratio. The approach also includes a reweighting term based on teacher confidence and student difficulty, and is evaluated on vision and language tasks with reported gains over standard KD and negligible overhead.
Significance. If the max-logit ratio rule reliably controls entropy across samples with varying logit gaps and the reweighting does not introduce new inconsistencies, the method would offer a lightweight way to mitigate the sample-agnostic limitations of fixed-temperature KD. The parameter-free character of the temperature rule and the explicit entropy analysis would be notable strengths if they hold without per-task retuning.
major comments (2)
- [Theoretical Analysis] Theoretical section (around the entropy-governance claim): the statement that teacher-label entropy is 'largely governed' by the max-logit/T ratio is load-bearing for the 'consistently informative' guarantee, yet the provided abstract supplies no derivation. When non-max logits vary substantially (common in vision/language data), the skeptic's point that residual entropy variance can exceed 0.5 nats after scaling must be addressed with a concrete bound or counter-example; otherwise the adaptive rule risks inheriting the same inconsistency it aims to fix.
- [Experiments] §4 (or equivalent experimental section), entropy-consistency table or figure: the central empirical claim requires quantitative evidence that the per-sample temperatures reduce entropy variance relative to fixed-T baselines (e.g., reported std-dev of teacher entropy across the test set). Without such a metric, the improvement over standard KD cannot be attributed to the consistency mechanism rather than to the reweighting term alone.
minor comments (2)
- [Method] The reweighting term that depends on teacher confidence and student difficulty should be written explicitly (e.g., as a multiplicative factor in the loss) with a clear definition of the difficulty proxy; its interaction with the temperature rule is currently underspecified.
- [Method] Notation for the constant c in T = max(logits)/c should be introduced once and used consistently; it is unclear whether c is truly universal or requires any validation on a held-out set.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps us clarify the theoretical foundations and strengthen the empirical support for CIST. We address the major comments point by point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical section (around the entropy-governance claim): the statement that teacher-label entropy is 'largely governed' by the max-logit/T ratio is load-bearing for the 'consistently informative' guarantee, yet the provided abstract supplies no derivation. When non-max logits vary substantially (common in vision/language data), the skeptic's point that residual entropy variance can exceed 0.5 nats after scaling must be addressed with a concrete bound or counter-example; otherwise the adaptive rule risks inheriting the same inconsistency it aims to fix.
Authors: We appreciate the referee's emphasis on rigor here. The full manuscript (Section 3) derives the entropy expression for the temperature-scaled softmax and shows that it is dominated by the max-logit/T ratio when the maximum logit substantially exceeds the others, which holds for the majority of samples in both vision and language settings. To address the residual variance concern directly, we will add an explicit upper bound on the entropy deviation attributable to non-max logits in the revision; this bound decreases as the logit gap increases and remains below 0.3 nats under the conditions observed in our datasets. We will also include a short counter-example analysis for pathological low-gap cases to demonstrate when the approximation remains informative. revision: yes
-
Referee: [Experiments] §4 (or equivalent experimental section), entropy-consistency table or figure: the central empirical claim requires quantitative evidence that the per-sample temperatures reduce entropy variance relative to fixed-T baselines (e.g., reported std-dev of teacher entropy across the test set). Without such a metric, the improvement over standard KD cannot be attributed to the consistency mechanism rather than to the reweighting term alone.
Authors: We agree that a direct quantitative metric for entropy consistency is necessary to isolate the contribution of the adaptive temperatures. In the revised manuscript we will add a table (and corresponding figure) reporting the standard deviation of teacher soft-label entropy across the test set for CIST, fixed-temperature KD, and an ablation without the reweighting term. This will provide clear evidence that the per-sample temperatures reduce entropy variance and allow readers to attribute gains more precisely. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central theoretical step derives that softmax entropy is largely controlled by the max-logit/T ratio (a direct mathematical property of the softmax), then proposes an adaptive T rule based on that observation. This is an independent analysis followed by a design choice, not a reduction of the claimed improvement or consistency guarantee to a quantity defined by the result itself. No load-bearing self-citation, fitted-input-as-prediction, or ansatz-smuggling is present; the reweighting term and empirical gains are presented as downstream consequences rather than tautological. The method remains falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-sample temperature scaling rule
axioms (1)
- domain assumption Teacher-label entropy is largely governed by the ratio of the maximum teacher logit to the temperature
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
teacher-label entropy is largely governed by the ratio between the maximum teacher logit and the temperature... vi,m/τi = ρ for some constant ρ>0
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanTranslation Theorem / J-uniqueness corollary echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
If both distributions are dominated by their maximum logit, the entropy difference is minimized when the ratio... is equal across samples
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computing Machinery. ISBN 9781605585161. doi: 10.1145/1553374.1553380. URLhttps://doi.org/10.1145/1553374.1553380. Alan Chan, Hugo Silva, Sungsu Lim, Tadashi Kozuno, A Rupam Mahmood, and Martha White. Greedification operators for policy optimization: Investigating forward and reverse kl divergences. Journal of Machine Learning Research, 23...
-
[2]
URL https://lmsys. org/blog/2023-03-30-vicuna/. Jang Hyun Cho and Bharath Hariharan. On the efficacy of knowledge distillation. InProceedings of the IEEE/CVF international conference on computer vision,
work page 2023
-
[3]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard. Mobilenets: Efficient convolutional neural networks for mobile vision applica- tions.arXiv preprint arXiv:1704.04861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Promptkd: Distilling student-friendly knowledge for generative language models via prompt tuning
Gyeongman Kim, Doohyuk Jang, and Eunho Yang. Promptkd: Distilling student-friendly knowledge for generative language models via prompt tuning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6266–6282,
work page 2024
-
[6]
Meta knowledge distillation.arXiv preprint arXiv:2202.07940,
Jihao Liu, Boxiao Liu, Hongsheng Li, and Yu Liu. Meta knowledge distillation.arXiv preprint arXiv:2202.07940,
-
[7]
Hoang-Chau Luong, Dat Ba Tran, and Lingwei Chen. Diversity-aware reverse kullback-leibler divergence for large language model distillation.arXiv preprint arXiv:2604.00223,
-
[8]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Understanding and improving knowledge distillation,
Jiaxi Tang, Rakesh Shivanna, Zhe Zhao, Dong Lin, Anima Singh, Ed H Chi, and Sagar Jain. Understanding and improving knowledge distillation.arXiv preprint arXiv:2002.03532,
-
[10]
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 conference on empirical methods in natural language processing...
work page 2022
-
[11]
Dynamic temperature knowledge distillation.arXiv preprint arXiv:2404.12711,
Yukang Wei and Yu Bai. Dynamic temperature knowledge distillation.arXiv preprint arXiv:2404.12711,
-
[12]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks.arXiv preprint arXiv:1605.07146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Knowledge distillation based on transformed teacher matching
Kaixiang Zheng and En-Hui Yang. Knowledge distillation based on transformed teacher matching. InThe Twelfth International Conference on Learning Representations (ICLR 2024),
work page 2024
-
[15]
12 A Implementation Details Implementation
URL https://openreview.net/pdf?id=MJ3K7uDGGl. 12 A Implementation Details Implementation. CIST is computationally efficient and easy to implement. It requires computing the maximum logit vi,max per sample and dividing it by ρ to obtain the temperature τi. To preserve the shift-invariance property of softmax, each logit vector is centered by subtracting it...
work page 2015
-
[16]
Note that λCE and λKL in Algorithm 1 are standard hyperparameters in traditional KD [Hinton et al., 2015], rather than additional hyperparameters introduced by our method. How to set ρ. The hyperparameter ρ controls the target entropy of the softened predictions. To select ρ, we estimate the practical entropy range for a given dataset and teacher model us...
work page 2015
-
[17]
The cross-entropy (CE) loss weight is kept identical to the original baselines (0.1 for KD [Hinton et al., 2015] and CTKD [Li et al., 2023]; 1.0 for DKD [Zhao et al., 2022] and MLKD [Jin et al., 2023]). ImageNet. For ImageNet, we train for 100 epochs using SGD with batch size 512, momentum 0.9, and weight decay 10−4. The initial learning rate is 0.2 and i...
work page 2015
-
[18]
Combining CIST with other distillation objectives
For fair comparison, KD-EntOut-CE and KD-EntOut-HT use the same hyperpa- rameters as standard KD such as CE loss weight0.1and KL loss weight0.9. Combining CIST with other distillation objectives. We evaluate CIST on top of MLKD [Jin et al., 2023]. MLKD performs logit alignment at multiple granularities (instance, batch and class level) 13 Algorithm 1Consi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.