Compositional Transduction with Latent Analogies for Offline Goal-Conditioned Reinforcement Learning
Pith reviewed 2026-05-21 06:47 UTC · model grok-4.3
The pith
A context-invariant latent analogy representation enables synthesizing optimal plans for unseen context-goal combinations in offline goal-conditioned reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Grounded in theory, the analogy representation captures what changes under optimal task execution, remains invariant to contextual variations, and is sufficient for optimal goal reaching, which allows a new offline GCRL approach to perform analogy transduction to unseen combinations and substantially outperform prior methods on manipulation tasks.
What carries the argument
Analogy transduction via a latent representation of task-endogenous changes that composes with new contexts to generate plans.
If this is right
- Offline agents can reach unseen goals under novel contextual variations by composing from existing data.
- Generalization becomes possible for analogy-context pairs absent from the training trajectories.
- Behavior composition no longer requires temporally contiguous segments from the same context.
- Performance on goal-conditioned tasks improves over methods without explicit analogy transduction.
Where Pith is reading between the lines
- The same invariance principle might transfer to other planning or control domains with factored task and context elements.
- If the representation generalizes reliably, it could lower sample requirements for learning generalist agents in robotics.
- Further work could test whether the approach scales to higher-dimensional state spaces or longer task horizons.
Load-bearing premise
The learned latent analogy representation is invariant to contextual variations and sufficient to produce optimal goal-reaching behavior when composed with new contexts.
What would settle it
A test where policies built from the learned analogies composed with held-out contexts fail to reach goals at optimal performance levels in the OGBench environments.
Figures









read the original abstract
Compositional generalization is essential for reaching unseen goals under novel contextual variations in offline goal-conditioned reinforcement learning (GCRL), where a generalist goal-reaching agent must be learned from limited data. Most prior approaches pursue this via trajectory stitching over temporally contiguous segments, which limits composing behaviors across varying contexts. To overcome this limitation, we formalize analogy transduction as synthesizing new plans by composing task-endogenous analogies with given contexts and propose a novel analogy representation tailored for it. Grounded in our theory, this analogy representation captures what changes under optimal task execution, remains invariant to contextual variations, and is sufficient for optimal goal reaching. We further contend that generalization to unseen analogy-context pairs is a practical obstacle in analogy transduction, and introduce a new approach for offline GCRL that enables analogy transduction beyond seen pairs to unseen combinations. We empirically demonstrate the effectiveness of our approach on OGBench manipulation environments, substantially outperforming prior methods that do not perform analogy transduction. Project page: https://rllab-snu.github.io/projects/CTA/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes analogy transduction for offline goal-conditioned RL as composing task-endogenous analogies with contexts to synthesize plans for unseen goals under novel variations. It introduces a latent analogy representation claimed to capture changes under optimal execution, remain invariant to context, and suffice for optimal goal-reaching policies. A transduction mechanism is proposed to handle unseen analogy-context pairs, with empirical evaluation on OGBench manipulation environments showing outperformance over prior non-transduction methods.
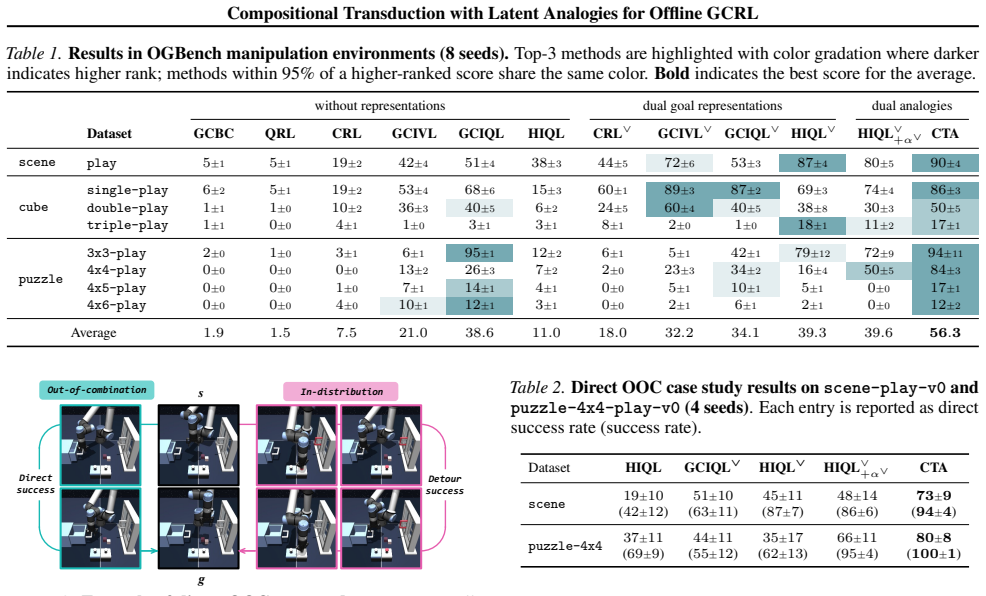
Significance. If the invariance and sufficiency properties hold, the work offers a principled alternative to trajectory stitching for compositional generalization in GCRL, potentially enabling more flexible generalist agents from limited offline data. The grounding in theory and focus on unseen pairs address a practical obstacle, and the OGBench results provide initial evidence of effectiveness in manipulation tasks.
major comments (2)
- [Abstract and §3] Abstract and §3 (Theory of Analogy Representation): The central claim that the latent analogy z_a 'remains invariant to contextual variations' and 'is sufficient for optimal goal reaching' when composed with new contexts is load-bearing but lacks a direct verification mechanism. The offline objective must be shown to enforce strict separation (e.g., via an explicit invariance loss or mutual information bound) rather than relying on empirical success rates; without this, leakage of context into z_a would invalidate compositional generalization to unseen pairs even if OGBench metrics improve.
- [§4] §4 (Transduction Mechanism): The approach for enabling transduction beyond seen analogy-context pairs is presented as solving a practical obstacle, but the manuscript does not specify how the learned latent space guarantees recovery of an optimal policy for g when z_a ⊕ c_new is used. A concrete test (e.g., policy optimality gap or value function comparison on held-out pairs) is needed to confirm sufficiency, as the current formulation risks reducing to standard goal-conditioned fitting.
minor comments (2)
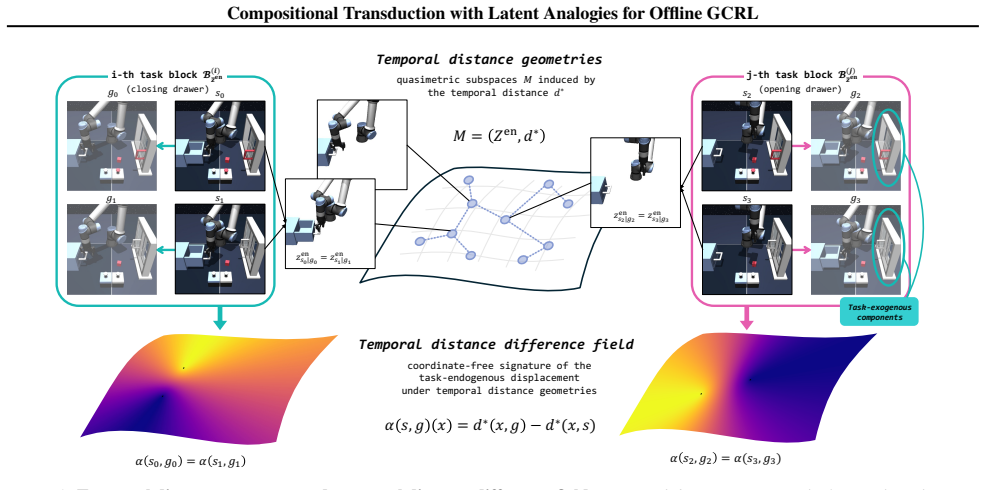
- [Figure 1] Figure 1 or equivalent diagram: The visualization of analogy-context composition would benefit from explicit notation for the latent variables z_a and c to clarify the transduction step.
- [Related Work] Related work section: The distinction from prior trajectory-stitching methods in GCRL could be sharpened with a direct comparison table of generalization mechanisms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical claims and empirical validation. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Theory of Analogy Representation): The central claim that the latent analogy z_a 'remains invariant to contextual variations' and 'is sufficient for optimal goal reaching' when composed with new contexts is load-bearing but lacks a direct verification mechanism. The offline objective must be shown to enforce strict separation (e.g., via an explicit invariance loss or mutual information bound) rather than relying on empirical success rates; without this, leakage of context into z_a would invalidate compositional generalization to unseen pairs even if OGBench metrics improve.
Authors: We agree that an explicit verification mechanism strengthens the central claims. Section 3 derives invariance and sufficiency from the properties of optimal policies and value functions under the analogy representation, with the offline objective structured to promote separation via the analogy extraction and composition losses. To address the concern directly, the revised manuscript adds an appendix with quantitative verification: we report mutual information estimates between the learned z_a and context variables on held-out data, showing low dependence consistent with invariance. We also include an ablation that removes the context-separation terms from the objective and demonstrates degraded compositional performance, supporting that the objective enforces the required properties rather than relying solely on downstream success rates. revision: yes
-
Referee: [§4] §4 (Transduction Mechanism): The approach for enabling transduction beyond seen analogy-context pairs is presented as solving a practical obstacle, but the manuscript does not specify how the learned latent space guarantees recovery of an optimal policy for g when z_a ⊕ c_new is used. A concrete test (e.g., policy optimality gap or value function comparison on held-out pairs) is needed to confirm sufficiency, as the current formulation risks reducing to standard goal-conditioned fitting.
Authors: The sufficiency of z_a ⊕ c_new for recovering the optimal policy follows from the invariance and sufficiency properties proven in §3, which ensure that the analogy encodes only the task-endogenous changes independent of context. The transduction mechanism in §4 is designed to generalize the composition operator to unseen pairs while preserving these properties. To provide the requested concrete test, the revised manuscript adds experiments on held-out analogy-context pairs in the OGBench environments. We compare the success rates and trajectory quality of the composed policies against a non-transductive goal-conditioned baseline trained directly on the same data, showing consistent improvements that cannot be explained by standard fitting alone. We have also expanded the discussion in §4.2 to explicitly link the composition step to the theoretical guarantees. revision: partial
Circularity Check
No significant circularity; claims rest on presented theory and empirical validation rather than self-referential reduction
full rationale
The paper develops a theory for analogy representations in offline GCRL within the manuscript itself, defining the latent analogy z_a to capture task-endogenous changes while remaining invariant to context c and sufficient for goal-reaching when composed. This is not a reduction by construction to fitted inputs or prior self-citations; the invariance and sufficiency are posited as properties of the novel representation and then tested via a transduction mechanism on OGBench. No equations equate the claimed generalization directly to the offline objective or rename a fitted parameter as a prediction. The central derivation chain remains self-contained with independent theoretical content and external empirical benchmarks, consistent with a low circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The analogy representation captures what changes under optimal task execution, remains invariant to contextual variations, and is sufficient for optimal goal reaching.
invented entities (1)
-
latent analogy representation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the temporal distance difference field is a task-endogenous analogy... sufficient for optimal goal-reaching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gaussian Error Linear Units (GELUs)
Hendrycks, D. and Gimpel, K. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Levine, S., Kumar, A., Tucker, G., and Fu, J. Offline rein- forcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, May
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[4]
Efficient Estimation of Word Representations in Vector Space
Mikolov, T., Chen, K., Corrado, G., and Dean, J. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781, Jan
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Playing Atari with Deep Reinforcement Learning
Mnih, V ., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., and Riedmiller, M. Playing Atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, Dec
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, Oct
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[7]
Wang, T. and Isola, P. Improved representation of asym- metrical distances with interval quasimetric embeddings. arXiv preprint arXiv:2211.15120, Nov. 2022a. Wang, T. and Isola, P. On the learning and learnability of quasimetrics. InProc. of the International Conference on Learning Representations (ICLR), Virtual conference, Apr. 2022b. Wang, T., Torralba...
-
[8]
13 Compositional Transduction with Latent Analogies for Offline GCRL A. Extended Related Work Compositional generalization in sequential decision making.In sequential decision making, compositional generaliza- tion is most commonly studied through trajectory stitching, which synthesizes new trajectories by connecting segments from different demonstrations...
work page 2013
-
[9]
and sequence-modeling approaches (Janner et al., 2022; Kim et al., 2024; Li et al., 2024; Luo et al., 2025). In this paper, we study analogy transduction as a new axis of compositional generalization, where task-endogenous analogies are transplanted across contexts beyond trajectory stitching. Metric learning for sequential decision making.Metric learning...
work page 2022
-
[10]
Hence, d∗(x, g) =D ∗ en(ρ¯z(x), z2), d ∗(x, s) =D ∗ en(ρ¯z(x), z1). Therefore, α(s, g)(x) =D ∗ en(ρ¯z(x), z2)−D ∗ en(ρ¯z(x), z1). Now defineδ:Z en × Zen →(S →R)by δ(z1, z2)(x) :=D ∗ en(ρ(z1,z2)(x), z2)−D ∗ en(ρ(z1,z2)(x), z1). Then, for every(s, g)∈ B ¯z, α(s, g)(x) =δ(z en s|g, zen g|s)(x) for all relevantx∈ S. Hence, α(s, g) =δ(z en s|g, zen g|s), which...
work page 2022
-
[11]
for all possible actions. Definition C.1(Bisimulation Relations (Givan et al., 2003)).Given an MDP M, an equivalence relation B over the state space S is abisimulation relationif, for all states si, sj ∈S that are equivalent under B (denoted si ≡B sj), the following conditions hold: R(si, a) =R(s j, a)∀a∈A, P(G|s i, a) =P(G|s j, a)∀a∈A,∀G∈ S B, (17) where...
work page 2003
-
[12]
is defined with a pseudometric space (S, dbisim) where the distance function dbisim :S × S →R ≥0 on S refers to the “behavioral similarity" between two states. Our work is motivated by the goal-conditioned bisimulation (GCB) metric (Hansen-Estruch et al., 2022): dπ bisim((si,g i),(s j,g j)) =|R(s i, π(si,g i),g i)− R(s j, π(sj,g j),g j)| +γW 1(dπ bisim)(P...
work page 2022
-
[13]
is a BCMP that additionally assumes a product structure on the latent space and a corresponding decoupling of initialization and dynamics. Formally, the latent state space decomposes as Z=Z en × Zex with z= (z en, zex), and there exist initial distributions µen ∈∆(Z en), µex ∈∆(Z ex) and latent transition dynamicsP en :Z en × A →∆(Z en),P ex :Z ex →∆(Z ex...
work page 2019
-
[14]
as Z=Z en × Zex, and accordingly ¯Z= (Z en × Zex)×(Z en × Zex). Under this factorization, for each (s, g)∈supp(f e) we can uniquely write zs|g =f ℓ g(s) = νg(s), ξ g(s) , z g|s =f ℓ s(g) = νs(g), ξ s(g) , whereν g, νs, ξg, ξs are deterministic maps defined on the relevant domains induced bysupp(f e). For brevity, we define zen s|g :=ν g(s), z ex s|g :=ξ g...
work page 2026
-
[15]
on the summed objective min ϕ,φ,Q Lanalogy(ϕ, φ, Q) :=L(ϕ, φ) +L(Q).(37) After training, thedual analogyis extracted as the displacement in the learned goal embedding space, α∨(s, g) :=φ(g)−φ(s)∈R d,(38) so that for any probe statex, ˜V(x, g)− ˜V(x, s) =ϕ(x) ⊤α∨(s, g). E.2. Details of the CTA Analogy compression for practical deployment.The dual analogy α...
work page 2026
-
[16]
on the summed objective, min Ω1,Ω2,ωh1,ωh2,ωℓ1,ωℓ2,η LCTA :=L(Ω 1,Ω 2, η)− L(ω h1, ωh2)− L(ω ℓ1, ωℓ2),(45) where the negative signs reflect that the actor objectives are maximized andη is updated only through the value objective L(Ω1,Ω 2, η). Bilinear architecture of the value and policy functions.Applying bilinear transduction requires departing from a m...
work page 2024
-
[17]
benchmark manipulation suite, which consists of the following three environments: cube, scene, and puzzle. These tasks are built on MuJoCo with a 6-DoF UR5e robot arm, and are explicitly designed to probe object manipulation, sequential (long-horizon) reasoning, and combinatorial generalization—making them a natural testbed for compositional generalizatio...
work page 2021
-
[18]
and refer readers to Park et al. (2026) for details. For Table 1 and Table 6, whenever results for a given environment are reported in OGBench (Park et al.,
work page 2026
-
[19]
or the dual goal representation paper (Park et al., 2026), we use those reported numbers; all remaining results are obtained from our own experiments. In particular, we implement GCIQL∨ in the same manner by replacing the TD update with the IQL update while keeping the representation module identical toGCIVL ∨ in the original implementation of Park et al....
work page 2026
-
[20]
(see Table 7). In particular, Park et al. (2026) argue that representation-conditioned formulations cannot directly exploit early fusion of visual state and goal, since the goal must be processed separately before conditioning the policy. This architectural constraint effectively enforces a late-fusion design, which is often weaker than early fusion in vi...
work page 2026
-
[21]
Layer normalization (Ba et al., 2016)True Discount factorγ0.99 Target network update rateτ0.005 Dual representation expectileι0.7 IQL expectileκ0.7 Low-level AWR temperatureβ ℓ 3.0 High-level AWR temperatureβ h 3.0 Subgoal stepsk10 (scene) 30 (cube) 20 (puzzle) 25 (maze) Analogy projectionηrepresentation dimension32 Dual representation dimensiond256 Visua...
work page 2016
-
[22]
Layer normalization (Ba et al., 2016)True Discount factorγ0.99 Target network update rateτ0.005 Dual representation expectileι0.7 IQL expectileκ0.7 Low-level AWR temperatureβ ℓ 3.0 High-level AWR temperatureβ h 3.0 Subgoal stepsk10 (scene) 30 (cube) 20 (puzzle) 25 (maze) Goal representationηdimension32 Dual representation dimensiond256 Visual encoderimpal...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.