Most Transformer Modifications Still Do Not Transfer at 1-3B: A 2020-2026 Update to Narang et al. (2021) with Downstream Evaluation and a Noise Floor
Pith reviewed 2026-05-21 06:11 UTC · model grok-4.3
The pith
Most post-2021 Transformer modifications do not transfer to 1-3B models under strict controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
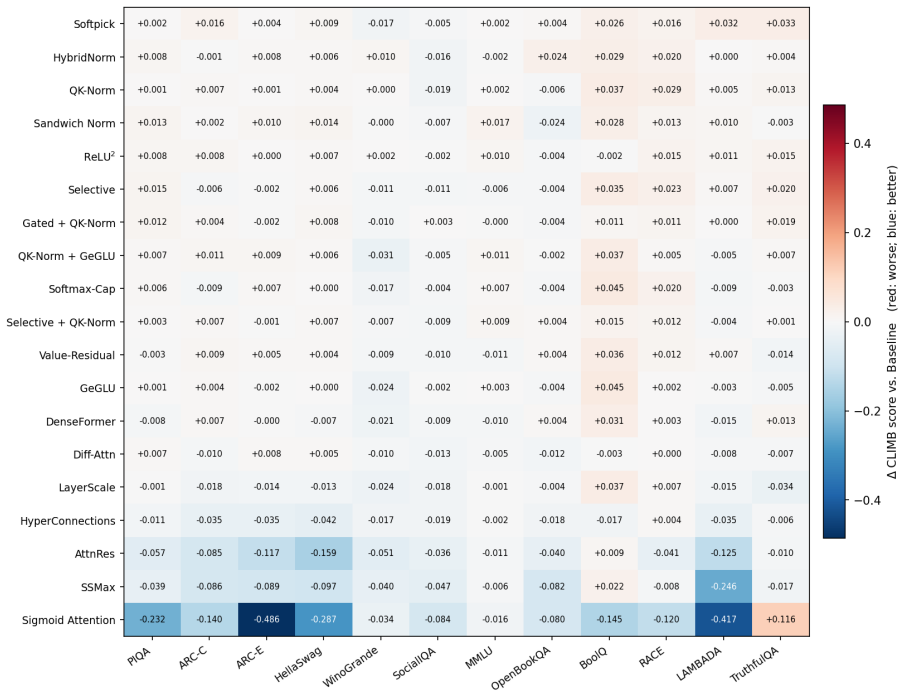
Of the twenty modifications examined, only two reach statistical significance after multiple-comparison correction at 1.2B parameters under the shared training recipe; one of those two becomes unstable at 3B. The loss-to-downstream gap widens markedly for attention-output changes, with two near-baseline loss runs still dropping 6-16 CLIMB points. The work concludes that noise-floor reporting, downstream evaluation, and cross-scale stability checks have become necessary for credible architecture comparisons at 1-3B.
What carries the argument
Iso-data, iso-compute, and iso-recipe controls paired with multi-seed baseline noise floor and CLIMB-12 downstream evaluation.
If this is right
- Architecture comparisons at 1-3B require noise-floor reporting to avoid false positives from single-run variance.
- Downstream metrics must take precedence over validation loss, especially for attention-output changes.
- Cross-scale stability testing between 1.2B and 3B is required before claiming transfer.
- Most modifications will not meet the threshold when all factors are held equal.
- The gap between loss and downstream performance can enlarge several-fold for certain modification classes.
Where Pith is reading between the lines
- Implementation details and optimizer interactions may explain more variance than the modification itself at these scales.
- Allowing each modification its own tuned recipe could raise the transfer rate, offering a testable next experiment.
- The results link to the broader question of whether data scaling or architectural novelty drives recent gains.
- Repeating the protocol on a different data mixture would test whether the non-transfer finding is data-specific.
Load-bearing premise
Holding the training recipe, data, and compute fixed isolates each modification's effect without hidden biases from implementation details or stability differences at 3B.
What would settle it
A modification that fails Bonferroni correction here but shows reliable gains when the same authors rerun it with a different optimizer schedule or additional seeds at 3B.
Figures

read the original abstract
Narang et al. (2021) evaluated 40+ Transformer modifications at T5-base scale and concluded that most did not transfer. Five years later, the typical working regime has moved to 1-3B parameters, downstream evaluation has replaced pretraining perplexity, and a substantially different catalogue of modifications has emerged. We revisit their question by testing 20 post-2021 Transformer modifications at 1.2B and 3B under strict iso-data, iso-compute, iso-recipe control, with a multi-seed baseline noise floor and CLIMB-12 downstream evaluation as the primary metric. The central finding reproduces theirs at this curated set: most modifications do not transfer. Of the 20 modifications, only two clear Bonferroni correction at 1.2B; one of those two further fails to train stably at 3B under the shared recipe. We also find that the loss-downstream gap reported by Tay et al. (2023) enlarges several-fold for attention-output modifications: two significant failures converge to within 2-3% of baseline validation loss yet drop 6-16 CLIMB-points. We conclude that noise-floor reporting, downstream evaluation, and cross-scale stability testing are now prerequisites for architecture comparisons at 1-3B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper updates Narang et al. (2021) by evaluating 20 post-2021 Transformer modifications at 1.2B and 3B scales under strict iso-data, iso-compute, and iso-recipe controls. It incorporates multi-seed baseline noise floors, Bonferroni correction, and CLIMB-12 downstream evaluation as the primary metric. The central finding is that most modifications do not transfer: only two clear Bonferroni correction at 1.2B, and one of those fails to train stably at 3B under the shared recipe. The work also reports that the loss-downstream performance gap enlarges several-fold for attention-output modifications.
Significance. If the controls hold, this provides a timely empirical update showing that rigorous statistical thresholds, downstream tasks, and cross-scale stability checks are now essential for credible architecture comparisons at 1-3B. The reproduction of the negative result with modern methods and the explicit noise-floor reporting are strengths that could help calibrate expectations in the field.
major comments (2)
- [Methods / Experimental Setup] Methods / Experimental Setup (iso-recipe control): The claim that modifications 'do not transfer' is load-bearing on the assumption that a single fixed hyperparameter recipe (LR schedule, optimizer, etc.) fairly isolates each change's effect. Architectural modifications can alter gradient variance, activation scales, or optimization curvature, so the baseline recipe may be mismatched; the reported stability failure at 3B for one of the two 1.2B-significant modifications is direct evidence of this risk. Without per-modification retuning or sensitivity analysis, apparent non-transfer could be a tuning artifact rather than an intrinsic result.
- [Results] Results (Bonferroni and stability reporting): The abstract states that only two of 20 modifications clear Bonferroni at 1.2B and one fails stability at 3B, but exact p-values, effect sizes, and full multi-seed statistics for all 20 (including the non-significant ones) are needed to verify the correction was applied uniformly and that the curated set does not introduce selection bias.
minor comments (2)
- [Abstract] Abstract: briefly define or cite what CLIMB-12 consists of (task composition, number of examples) to improve accessibility.
- [Figures] Figures: ensure error bars from the multi-seed runs are visible and labeled consistently across performance plots.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our update to Narang et al. (2021). We address each major point below, indicating where revisions will be made to improve clarity and completeness while preserving the core experimental design.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods / Experimental Setup (iso-recipe control): The claim that modifications 'do not transfer' is load-bearing on the assumption that a single fixed hyperparameter recipe (LR schedule, optimizer, etc.) fairly isolates each change's effect. Architectural modifications can alter gradient variance, activation scales, or optimization curvature, so the baseline recipe may be mismatched; the reported stability failure at 3B for one of the two 1.2B-significant modifications is direct evidence of this risk. Without per-modification retuning or sensitivity analysis, apparent non-transfer could be a tuning artifact rather than an intrinsic result.
Authors: We agree that architectural modifications can influence optimization dynamics and that the observed instability at 3B for one modification provides direct evidence of this. Our iso-recipe protocol is intentional and follows the design of Narang et al. (2021) to evaluate whether modifications transfer under a shared, fixed training recipe without per-modification hyperparameter retuning. This mirrors how many modifications are proposed and initially tested in the literature. A full per-modification retuning study would address a different question and require substantially more compute. We will expand the discussion section to explicitly note this limitation, discuss the implications of potential optimization mismatches, and clarify that the reported non-transfer results are conditioned on the fixed recipe. revision: yes
-
Referee: [Results] Results (Bonferroni and stability reporting): The abstract states that only two of 20 modifications clear Bonferroni at 1.2B and one fails stability at 3B, but exact p-values, effect sizes, and full multi-seed statistics for all 20 (including the non-significant ones) are needed to verify the correction was applied uniformly and that the curated set does not introduce selection bias.
Authors: We agree that detailed statistics aid verification. The manuscript already reports the multi-seed noise floor, Bonferroni correction, and stability observations in the main text and appendix. In revision we will add a table providing exact p-values, effect sizes, and complete per-seed performance for all 20 modifications. For the curated set, the 20 modifications were chosen to cover major post-2021 categories (attention, normalization, activation, and positional variants); we will add explicit selection criteria to the methods to address potential bias concerns. revision: yes
Circularity Check
No significant circularity: empirical reproduction via new controlled experiments
full rationale
The paper reports fresh experimental results at 1.2B and 3B scales under iso-recipe, iso-data, iso-compute conditions, measuring downstream CLIMB-12 performance and stability for 20 post-2021 modifications. No derivation chain, equations, or fitted parameters are presented that reduce by construction to prior inputs or self-cited results; the central claim (most modifications fail to transfer) rests on direct multi-seed measurements and Bonferroni-corrected comparisons against a reported noise floor. The work cites Narang et al. (2021) only as the historical baseline being updated, not as a load-bearing uniqueness theorem or ansatz. This is a standard self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- 1.2B and 3B model sizes
- CLIMB-12 benchmark selection
axioms (2)
- domain assumption Training recipe, data, and compute can be held strictly identical across modifications
- domain assumption Multi-seed runs provide a reliable baseline noise floor for statistical testing
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
most modifications do not transfer... only two clear Bonferroni correction at 1.2B; one of those two further fails to train stably at 3B under the shared recipe
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
noise-floor protocol... three independent seeds... σbaseline=0.00208
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. PIQA : Reasoning about physical commonsense in natural language. AAAI
work page 2020
-
[2]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ : Exploring the surprising difficulty of natural yes/no questions. In NAACL
work page 2019
-
[5]
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, and 2 others. 2023. Scaling V ision T ransformers...
-
[7]
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. 2021. CogView : Mastering text-to-image generation via transformers. In NeurIPS. Introduces Sandwich Normalization for stabilizing large Transformers
work page 2021
-
[8]
Bradley Efron. 1987. Better bootstrap confidence intervals. Journal of the American Statistical Association, 82(397):171--185
work page 1987
-
[10]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In ICLR
work page 2021
-
[11]
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. 2020. Query-key normalization for transformers. EMNLP Findings
work page 2020
-
[13]
Andrej Karpathy. 2025. nanochat: The best ChatGPT that \ 100 can buy. https://github.com/karpathy/nanochat. Open-source small-LM reproduction stack; source of the 65 , 664-entry BPE tokenizer used in this work
work page 2025
-
[14]
Kimi Team , Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, Yutian Chen, Junjie Yan, Ming Wei, Y. Zhang, Fanqing Meng, Chao Hong, Xiaotong Xie, Shaowei Liu, Enzhe Lu, and 18 others. 2026. Attention residuals. arXiv:2603.15031. Submitted 16 Mar 2026
work page internal anchor Pith review arXiv 2026
-
[15]
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. RACE : Large-scale ReAding comprehension dataset from examinations. In EMNLP
work page 2017
-
[17]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA : Measuring how models mimic human falsehoods. In ACL
work page 2022
-
[18]
Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. 2023. Same pre-training loss, better downstream: Implicit bias matters for language models. In ICML
work page 2023
-
[19]
Nicholas Lourie, Michael Y. Hu, and Kyunghyun Cho. 2025. Scaling laws are unreliable for downstream tasks: A reality check. In Findings of EMNLP. ArXiv:2507.00885
-
[20]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. EMNLP
work page 2018
-
[22]
Sharan Narang, Hyung Won Chung, Yi Tay, William Fedus, Thibault Fevry, Michael Matena, Karishma Malkan, Noah Fiedel, Noam Shazeer, Zhenzhong Lan, Yanqi Zhou, Wei Li, Nan Ding, Jake Marcus, Adam Roberts, and Colin Raffel. 2021. Do Transformer modifications transfer across implementations and applications? In EMNLP
work page 2021
-
[24]
Denis Paperno, Germ\' a n Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern\' a ndez. 2016. The LAMBADA dataset: Word prediction requiring a broad discourse context. ACL
work page 2016
-
[25]
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. In NeurIPS. ArXiv:2505.06708; per-head sigmoid gate on attention output
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2020. WinoGrande : An adversarial Winograd schema challenge at scale. AAAI
work page 2020
-
[28]
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. Social IQa : Commonsense reasoning about social interactions. In EMNLP
work page 2019
-
[30]
So, Wojciech Ma\' n ke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V
David R. So, Wojciech Ma\' n ke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V. Le. 2022. Primer: Searching for efficient transformers for language modeling. In ICML. Introduces non-gated ReLU ^ 2 activation; adopted by PaLM-540B
work page 2022
- [31]
-
[32]
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herv \'e J \'e gou. 2021. Going deeper with image transformers. In ICCV
work page 2021
-
[34]
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. On layer normalization in the transformer architecture. In ICML. Demonstrates Post-LN activation variance growth with depth; motivates Pre-LN
work page 2020
-
[36]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag : Can a machine really finish your sentence? In ACL
work page 2019
- [37]
- [39]
-
[41]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Training Compute-Optimal Large Language Models
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Sharan Narang and Hyung Won Chung and Yi Tay and William Fedus and Thibault Fevry and Michael Matena and Karishma Malkan and Noah Fiedel and Noam Shazeer and Zhenzhong Lan and Yanqi Zhou and Wei Li and Nan Ding and Jake Marcus and Adam Roberts and Colin Raffel , title =. EMNLP , year =
-
[44]
Yi Tay and Mostafa Dehghani and Samira Abnar and Hyung Won Chung and Sharan Narang and Dani Yogatama and Ashish Vaswani and Donald Metzler , title =. Findings of EMNLP , year =
-
[45]
Hong Liu and Sang Michael Xie and Zhiyuan Li and Tengyu Ma , title =. ICML , year =
-
[46]
Hu and Kyunghyun Cho , title =
Nicholas Lourie and Michael Y. Hu and Kyunghyun Cho , title =. Findings of EMNLP , year =
-
[47]
Alex Henry and Prudhvi Raj Dachapally and Shubham Pawar and Yuxuan Chen , title =. EMNLP Findings , year =
-
[48]
Mostafa Dehghani and Josip Djolonga and Basil Mustafa and Piotr Padlewski and Jonathan Heek and Justin Gilmer and Andreas Steiner and Mathilde Caron and Robert Geirhos and Ibrahim Alabdulmohsin and Rodolphe Jenatton and Lucas Beyer and Michael Tschannen and Anurag Arnab and Xiao Wang and Carlos Riquelme and Matthias Minderer and Joan Puigcerver and Utku E...
-
[49]
Yaniv Leviathan and Matan Kalman and Yossi Matias , title =. arXiv:2410.02703 , year =
-
[50]
Differential transformer, 2024
Tianzhu Ye and Li Dong and Yuqing Xia and Yutao Sun and Yi Zhu and Gao Huang and Furu Wei , title =. arXiv:2410.05258 , year =
-
[51]
Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Fares Obeid and Zhenzhong Lan , title =. ACL , year =
-
[52]
Zayd M. K. Zuhri and Erland Hilman Fuadi and Alham Fikri Aji , title =. arXiv:2504.20966 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Jason Ramapuram and Federico Danieli and Eeshan Dhekane and Floris Weers and Dan Busbridge and Pierre Ablin and Tatiana Likhomanenko and Jagrit Digani and Zijin Gu and Amitis Shidani and Russ Webb , title =. arXiv:2409.04431 , year =
- [54]
-
[55]
Matteo Pagliardini and Amirkeivan Mohtashami and Francois Fleuret and Martin Jaggi , title =. arXiv:2402.02622 , year =
-
[56]
Hyper-Connections.arXiv preprint arXiv:2409.19606, 2024
Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou , title =. arXiv:2409.19606 , year =
-
[57]
DeepSeek-AI , title =. arXiv:2412.19437 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Going Deeper with Image Transformers , booktitle =
Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Herv. Going Deeper with Image Transformers , booktitle =
- [59]
-
[60]
GLU Variants Improve Transformer
Noam Shazeer , title =. arXiv:2002.05202 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[61]
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. AAAI , year =
-
[62]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , title =. ACL , year =
-
[64]
Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi , title =. AAAI , year =
-
[65]
Maarten Sap and Hannah Rashkin and Derek Chen and Ronan LeBras and Yejin Choi , title =. EMNLP , year =
-
[66]
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. ICLR , year =
-
[67]
Todor Mihaylov and Peter Clark and Tushar Khot and Ashish Sabharwal , title =. EMNLP , year =
-
[68]
Christopher Clark and Kenton Lee and Ming-Wei Chang and Tom Kwiatkowski and Michael Collins and Kristina Toutanova , title =. NAACL , year =
-
[69]
Guokun Lai and Qizhe Xie and Hanxiao Liu and Yiming Yang and Eduard Hovy , title =. EMNLP , year =
-
[70]
Denis Paperno and Germ\'. The. ACL , year =
- [71]
-
[72]
Leo Gao and Jonathan Tow and Baber Abbasi and Stella Biderman and Sid Black and Anthony DiPofi and Charles Foster and Laurence Golding and Jeffrey Hsu and Alain Le Noac'h and Haonan Li and Kyle McDonell and Niklas Muennighoff and Chris Ociepa and Jason Phang and Laria Reynolds and Hailey Schoelkopf and Aviya Skowron and Lintang Sutawika and Eric Tang and ...
-
[73]
Journal of the American Statistical Association , volume =
Bradley Efron , title =. Journal of the American Statistical Association , volume =
-
[74]
Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang , title =. NeurIPS , year =
-
[75]
Zhijian Zhuo and Yutao Zeng and Ya Wang and Sijun Zhang and Jian Yang and Xiaoqing Li and Xun Zhou and Jinwen Ma , title =. NeurIPS , year =
-
[76]
David R. So and Wojciech Ma\'. Primer: Searching for Efficient Transformers for Language Modeling , booktitle =. 2022 , note =
work page 2022
-
[77]
Zihan Qiu and Zekun Wang and Bo Zheng and Zeyu Huang and Kaiyue Wen and Songlin Yang and Rui Men and Le Yu and Fei Huang and Suozhi Huang and Dayiheng Liu and Jingren Zhou and Junyang Lin , title =. NeurIPS , year =
-
[78]
Ruibin Xiong and Yunchang Yang and Di He and Kai Zheng and Shuxin Zheng and Chen Xing and Huishuai Zhang and Yanyan Lan and Liwei Wang and Tie-Yan Liu , title =. ICML , year =
-
[79]
Shizhe Diao and Yu Yang and Yonggan Fu and Xin Dong and Dan Su and Markus Kliegl and Zijia Chen and Peter Belcak and Yoshi Suhara and Hongxu Yin and Mostofa Patwary and Celine Lin and Jan Kautz and Pavlo Molchanov , title =. arXiv:2504.13161 , year =
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.