Instant GPU Efficiency Visibility at Fleet Scale
Pith reviewed 2026-05-21 02:38 UTC · model grok-4.3
The pith
Two on-chip GPU counters predict application MFU to within two percentage points after tile-quantization correction
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
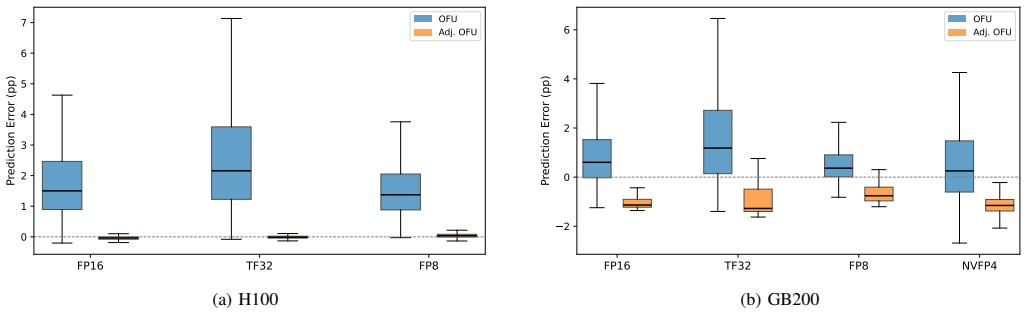
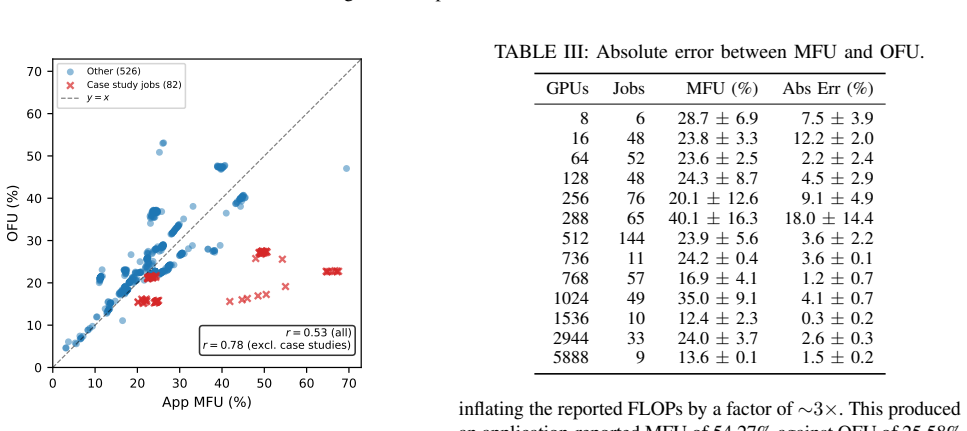
Overall FLOP Utilization (OFU) is obtained directly from the product of two on-chip counters, Tensor Pipe Activity and SM clock frequency, yielding a precision-agnostic proxy for total FLOP throughput. After a tile-quantization correction the resulting value matches application-reported model FLOPs utilization to within two percentage points on GEMM workloads spanning multiple precisions and GPU generations. Applied to hundreds of real training jobs OFU surfaces both misreported FLOPs in frameworks and measurable utilization shifts during mixed-precision pretraining.
What carries the argument
Overall FLOP Utilization (OFU), the normalized product of Tensor Pipe Activity and SM clock frequency that serves as a hardware proxy for aggregate floating-point throughput without per-application calibration
If this is right
- OFU can be collected fleet-wide without modifying or instrumenting any running applications
- The metric has already identified a 2.5 times efficiency regression in deployed production systems
- It reveals framework-level errors in reported FLOP counts on hundreds of real jobs
- OFU tracks utilization changes that occur when switching precisions during pretraining
- Correlation of 0.78 with measured MFU on 608 production jobs supports its role as a complement to application-level monitoring
Where Pith is reading between the lines
- Fleet schedulers could use live OFU readings to pause or migrate inefficient jobs automatically
- The same counter-based approach might transfer to other accelerators if comparable activity and frequency signals are exposed
- Long-term fleet data from OFU could expose systematic efficiency differences across model families or software stacks
- Adding further counters might shrink the remaining error for workloads that under-count non-tensor operations
Load-bearing premise
The two on-chip counters provide a sufficient and unbiased proxy for total FLOP throughput across all workload types and precisions without requiring per-application calibration
What would settle it
A workload where the tile-quantization-corrected OFU deviates by more than two percentage points from independently measured application MFU, such as a non-GEMM task or an untested precision or GPU generation
Figures





read the original abstract
We present Overall FLOP Utilization (OFU), a hardware-level, precision-agnostic GPU efficiency metric for AI workloads on HPC systems, derived from two on-chip performance counters: Tensor Pipe Activity and SM clock frequency. OFU requires no application instrumentation and works across GPU generations and numeric precisions. We characterize five properties of the OFU approximation -- tile quantization, floating-point precision scaling, clock sampling noise, Tensor Core clock domains, and non-tensor undercounting -- through controlled GEMM experiments on H100 and GB200 across FP16, TF32, FP8, and NVFP4. After tile-quantization correction, OFU predicts application-level MFU to within <=2 percentage points. Against 608 production training jobs, OFU achieves r = 0.78 correlation with application-level MFU and surfaces two framework-level FLOPs miscalculations. Deployed across large-scale GPU fleets, OFU has detected a 2.5x efficiency regression and tracked precision-dependent utilization changes in mixed-precision pretraining. Our evaluation and operational experience suggest OFU is a practical, deployment-ready complement to application-level MFU for continuous fleet-wide efficiency monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Overall FLOP Utilization (OFU), a hardware-level, precision-agnostic GPU efficiency metric derived solely from Tensor Pipe Activity and SM clock frequency counters. It characterizes five properties of the approximation (tile quantization, floating-point precision scaling, clock sampling noise, Tensor Core clock domains, and non-tensor undercounting) via controlled GEMM experiments on H100 and GB200 across FP16/TF32/FP8/NVFP4, applies a tile-quantization correction, and claims that the corrected OFU predicts application-level MFU to within <=2 percentage points. On 608 production training jobs, OFU achieves r=0.78 correlation with application MFU, detects two framework-level FLOP miscalculations, and in fleet deployment has identified a 2.5x efficiency regression while tracking precision-dependent changes.
Significance. If the accuracy and generalization claims hold, OFU would provide a valuable, low-overhead complement to application-level MFU for continuous fleet-scale efficiency monitoring in large AI/HPC systems, requiring no instrumentation and spanning GPU generations and precisions. The authors merit explicit credit for deriving the metric directly from raw hardware counters without fitting to target MFU values, for the controlled multi-precision GEMM characterization of its limitations, and for the concrete operational evidence of detecting real regressions and miscalculations in production.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that 'After tile-quantization correction, OFU predicts application-level MFU to within <=2 percentage points' immediately follows the GEMM characterization but precedes the separate statement of r=0.78 on 608 production jobs. The manuscript must explicitly state on which workloads (GEMM kernels only, or full training applications) and with what error statistics (e.g., MAE, 95th-percentile deviation, or per-precision breakdown) this bound was measured, because non-tensor undercounting and mixed kernels in arbitrary workloads could exceed 2pp and undermine the generalization to fleet-scale use.
- [Production evaluation section] Production evaluation section: The reported r=0.78 correlation on 608 jobs is presented as validation, yet without the distribution of absolute per-job errors or relation to MFU variance across the fleet it is impossible to determine whether typical deviations remain within the claimed 2pp or are substantially larger. This directly affects whether the metric supports the central goal of reliable, instant efficiency visibility.
minor comments (2)
- [Definition section] The explicit formula combining Tensor Pipe Activity and SM clock frequency into OFU should be stated as an equation in the definition section to aid reproducibility and clarity.
- [GEMM characterization figures] Figures in the GEMM characterization should include error bars or sample sizes for the measured properties across precisions to allow readers to assess variability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the clarity of our accuracy claims. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that 'After tile-quantization correction, OFU predicts application-level MFU to within <=2 percentage points' immediately follows the GEMM characterization but precedes the separate statement of r=0.78 on 608 production jobs. The manuscript must explicitly state on which workloads (GEMM kernels only, or full training applications) and with what error statistics (e.g., MAE, 95th-percentile deviation, or per-precision breakdown) this bound was measured, because non-tensor undercounting and mixed kernels in arbitrary workloads could exceed 2pp and undermine the generalization to fleet-scale use.
Authors: We agree the abstract phrasing creates ambiguity about the source of the <=2pp bound. This bound was measured as the maximum observed deviation between corrected OFU and known utilization on the controlled GEMM kernels across FP16/TF32/FP8/NVFP4 on H100 and GB200. For full applications we rely on the separate r=0.78 correlation result. We will revise the abstract to explicitly attribute the 2pp bound to the GEMM characterization, state the error metric used (maximum deviation after tile correction), and add a per-precision breakdown of errors to the evaluation section. Non-tensor undercounting is already characterized as one of the five properties and its effect is reflected in the production correlation. revision: yes
-
Referee: [Production evaluation section] Production evaluation section: The reported r=0.78 correlation on 608 jobs is presented as validation, yet without the distribution of absolute per-job errors or relation to MFU variance across the fleet it is impossible to determine whether typical deviations remain within the claimed 2pp or are substantially larger. This directly affects whether the metric supports the central goal of reliable, instant efficiency visibility.
Authors: We acknowledge that absolute error statistics would help readers assess whether deviations stay within the 2pp range in practice. The r=0.78 correlation on 608 diverse production jobs quantifies a strong linear relationship across the observed range of fleet MFU values. We will add a short discussion in the production evaluation section explaining how this correlation, combined with the fleet MFU variance, is consistent with typical deviations remaining small. However, the full distribution of absolute per-job errors is not pre-computed from the raw data. revision: partial
- Distribution of absolute per-job errors for the 608 production jobs
Circularity Check
No significant circularity; derivation self-contained from hardware counters
full rationale
OFU is defined directly from two raw on-chip counters (Tensor Pipe Activity and SM clock frequency) with no fitting to target MFU values. The five properties are characterized via independent controlled GEMM experiments on H100/GB200 across precisions; the tile-quantization correction is derived from those experiments and the <=2pp claim follows as a reported outcome. The r=0.78 correlation is measured separately on 608 production training jobs and presented as validation, not as part of the metric definition. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or described chain. The approach remains externally falsifiable against application-level MFU.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tensor Pipe Activity and SM clock frequency counters are available and stable across GPU generations and precisions.
invented entities (1)
-
Overall FLOP Utilization (OFU)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present Overall FLOP Utilization (OFU), a hardware-level, precision-agnostic GPU efficiency metric... derived from two on-chip performance counters: Tensor Pipe Activity and SM clock frequency.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
After tile-quantization correction, OFU predicts application-level MFU to within ≤2 percentage points.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Microsoft, “Microsoft fy2025 q4 earnings,” Microsoft Investor Relations,
-
[2]
Available: https://www.microsoft.com/en-us/investor/eve nts/fy-2025/earnings-fy-2025-q4
[Online]. Available: https://www.microsoft.com/en-us/investor/eve nts/fy-2025/earnings-fy-2025-q4
work page 2025
-
[3]
Alphabet announces fourth quarter and fiscal year 2025 results,
Alphabet Inc., “Alphabet announces fourth quarter and fiscal year 2025 results,” February 2026. [Online]. Available: https: //www.sec.gov/Archives/edgar/data/1652044/000165204426000012/goo gexhibit991q42025.htm
-
[4]
Meta reports fourth quarter and full year 2025 results,
Meta Platforms, “Meta reports fourth quarter and full year 2025 results,” January 2026. [Online]. Available: https://investor.atmeta.com/investor-n ews/press-release-details/2026/Meta-Reports-Fourth-Quarter-and-Ful l-Year-2025-Results/default.aspx
work page 2025
-
[5]
Citigroup forecasts big tech’s ai spending to cross $2.8 trillion by 2029,
Reuters, “Citigroup forecasts big tech’s ai spending to cross $2.8 trillion by 2029,” September 2025. [Online]. Available: https://www.reuters.com/world/china/citigroup-forecasts-big-techs-ai-s pending-cross-28-trillion-by-2029-2025-09-30/
work page 2029
-
[6]
PyTorch Contributors, “Pytorch profiler,” PyTorch Documentation, 2024. [Online]. Available: https://pytorch.org/tutorials/recipes/recipes/profiler r ecipe.html
work page 2024
-
[7]
Microsoft DeepSpeed Team, “Deepspeed flops profiler,” DeepSpeed Documentation, 2024. [Online]. Available: https://www.deepspeed.ai/tut orials/flops-profiler/
work page 2024
-
[8]
Hpctoolkit: Tools for performance analysis of optimized parallel programs,
L. Adhianto, S. Banerjee, M. Fagan, M. Krentel, G. Marin, J. Mellor- Crummey, and N. R. Tallent, “Hpctoolkit: Tools for performance analysis of optimized parallel programs,” inConcurrency and Computation: Practice and Experience, vol. 22, no. 6, 2010, pp. 685–701. [Online]. Available: https://doi.org/10.1002/cpe.1553
-
[9]
Nvidia/megatron-lm: Ongoing research training transformer models at scale,
NVIDIA, “Nvidia/megatron-lm: Ongoing research training transformer models at scale,” GitHub README, 2025. [Online]. Available: https://github.com/NVIDIA/Megatron-LM
work page 2025
-
[10]
Lightning AI, “Pytorch lightning,” GitHub repository, 2024. [Online]. Available: https://github.com/Lightning-AI/pytorch-lightning
work page 2024
-
[11]
Nvidia nemo: A toolkit for building ai models,
NVIDIA, “Nvidia nemo: A toolkit for building ai models,” GitHub repository, 2024. [Online]. Available: https://github.com/NVIDIA/NeMo
work page 2024
-
[12]
PaLM: Scaling Language Modeling with Pathways
A. Chowdheryet al., “Palm: Scaling language modeling with pathways,”arXiv:2204.02311, 2022. [Online]. Available: https: //doi.org/10.48550/arXiv.2204.02311
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.02311 2022
-
[13]
NVIDIA, “Nvidia dcgm exporter,” GitHub repository, 2025. [Online]. Available: https://github.com/NVIDIA/dcgm-exporter
work page 2025
-
[14]
nv-one-logger: Nvidia’s distributed metrics logging system,
——, “nv-one-logger: Nvidia’s distributed metrics logging system,” GitHub repository, 2024. [Online]. Available: https://github.com/NVIDI A/nv-one-logger
work page 2024
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, “Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,”arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
[Online]. Available: https://doi.org/10.48550/arXiv.2405.04434
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434
-
[17]
Nvidia tesla v100 gpu architecture,
NVIDIA, “Nvidia tesla v100 gpu architecture,” NVIDIA, Tech. Rep. WP-08608-001 v1.1, 2017. [Online]. Available: https://images.nvidia.co m/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf
work page 2017
-
[18]
Nvidia a100 tensor core gpu architecture,
——, “Nvidia a100 tensor core gpu architecture,” NVIDIA, Tech. Rep.,
-
[19]
[Online]. Available: https://images.nvidia.com/aem-dam/en-zz/So lutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
-
[20]
Nvidia h100 tensor core gpu architecture,
——, “Nvidia h100 tensor core gpu architecture,” NVIDIA, Tech. Rep., 2022, whitepaper. [Online]. Available: https://www.advancedclustering.c om/wp-content/uploads/2022/03/gtc22-whitepaper-hopper.pdf
work page 2022
-
[21]
Nvidia tensor core evolution: From volta to blackwell,
SemiAnalysis, “Nvidia tensor core evolution: From volta to blackwell,” SemiAnalysis Newsletter, June 2025. [Online]. Available: https: //newsletter.semianalysis.com/p/nvidia-tensor-core-evolution-from-vol ta-to-blackwell
work page 2025
-
[22]
Accelerating ai training with nvidia tf32 tensor cores,
D. Stosic and P. Micikevicius, “Accelerating ai training with nvidia tf32 tensor cores,” NVIDIA Technical Blog, January 2021. [Online]. Available: https://developer.nvidia.com/blog/accelerating-ai-training-wit h-tf32-tensor-cores/
work page 2021
-
[23]
Nvidia h100 tensor core gpu architecture,
NVIDIA, “Nvidia h100 tensor core gpu architecture,” NVIDIA, Tech. Rep., 2022, whitepaper. [Online]. Available: https://www.advancedcluste ring.com/wp-content/uploads/2022/03/gtc22-whitepaper-hopper.pdf
work page 2022
-
[24]
Floating-point 8: An introduction to efficient, lower-precision ai training,
K. Sevegnani, G. Fiameni, U. Uppal, S. Perez, and A. Pilzer, “Floating-point 8: An introduction to efficient, lower-precision ai training,” NVIDIA Technical Blog, June 2025. [Online]. Available: https://developer.nvidia.com/blog/floating-point-8-an-introduction-to-e fficient-lower-precision-ai-training/
work page 2025
-
[25]
Cutlass tutorial: Fast matrix-multiplication with wgmma on nvidia hopper gpus,
Colfax Research, “Cutlass tutorial: Fast matrix-multiplication with wgmma on nvidia hopper gpus,” Colfax Research Blog, August 2024. [Online]. Available: https://research.colfax-intl.com/cutlass-tutorial-wgm ma-hopper/
work page 2024
-
[26]
Introducing nvfp4 for efficient and accurate low- precision inference,
E. Alvarez, O. Almog, E. Chung, S. Layton, D. Stosic, R. Krashinsky, and K. Aubrey, “Introducing nvfp4 for efficient and accurate low- precision inference,” NVIDIA Technical Blog, June 2025. [Online]. Available: https://developer.nvidia.com/blog/introducing-nvfp4-for-effic ient-and-accurate-low-precision-inference/
work page 2025
-
[27]
Nvidia rtx blackwell gpu architecture,
NVIDIA, “Nvidia rtx blackwell gpu architecture,” NVIDIA, Tech. Rep., 2025, architecture Whitepaper. [Online]. Available: https: //images.nvidia.com/aem-dam/Solutions/geforce/blackwell/nvidia-rtx-b lackwell-gpu-architecture.pdf
work page 2025
-
[28]
Pretraining large language models with NVFP4
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu, N. Mellempudi, S. Oberman, M. Shoeybi, M. Renber, K. Siu, and H. Wu, “Pretraining large language models with NVFP4,”arXiv preprint arXiv:2509.25149,
-
[29]
Pretraining large language models with NVFP4
[Online]. Available: https://doi.org/10.48550/arXiv.2509.25149
-
[30]
Data movement is all you need: A case study on optimizing transformers,
A. Ivanov, N. Dryden, T. Ben-Nun, S. Li, and T. Hoefler, “Data movement is all you need: A case study on optimizing transformers,” in Proceedings of Machine Learning and Systems (MLSys), vol. 3, 2021, pp. 711–732. [Online]. Available: https://doi.org/10.48550/arXiv.2007.00072
-
[31]
Matrix multiplication background user’s guide,
NVIDIA, “Matrix multiplication background user’s guide,” NVIDIA Deep Learning Performance Documentation, 2024. [Online]. Available: https://docs.nvidia.com/deeplearning/performance/dl-performance-matri x-multiplication/index.html
work page 2024
-
[32]
——, “cublas library user’s guide,” CUDA Toolkit Documentation, 2025. [Online]. Available: https://docs.nvidia.com/cuda/cublas/index.html
work page 2025
-
[33]
——, “nvmatmulheuristics,” 2025. [Online]. Available: https://developer. nvidia.com/blog/improving-gemm-kernel-auto-tuning-efficiency-on-nvi dia-gpus-with-heuristics-and-cutlass-4-2/
work page 2025
-
[34]
Improving gemm kernel auto-tuning efficiency on nvidia gpus with heuristics and cutlass 4.2,
H. Zhao, D. Yan, A. Wang, A. Kerr, and M. Yan, “Improving gemm kernel auto-tuning efficiency on nvidia gpus with heuristics and cutlass 4.2,” NVIDIA Technical Blog, January 2025. [Online]. Available: https://developer.nvidia.com/blog/improving-gemm-kernel-auto-tunin g-efficiency-on-nvidia-gpus-with-heuristics-and-cutlass-4-2/
work page 2025
-
[35]
NVIDIA, “Nvidia h100 tensor core gpu,” NVIDIA Data Center GPU Product Page, 2024. [Online]. Available: https://www.nvidia.com/en-us/ data-center/h100/
work page 2024
-
[36]
——, “Nvidia gb200 tensor core gpu,” NVIDIA Data Center GPU Product Page, 2024. [Online]. Available: https://www.nvidia.com/en-us/ data-center/gb200-nvl72/
work page 2024
-
[37]
V . Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,”arXiv preprint arXiv:2205.05198, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2205.05198
-
[38]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020. [Online]. Available: https://doi.org/10.48550/arXiv.2001.08361
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[39]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2312.00752
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.00752 2024
-
[40]
Nvidia osmo: Cloud-native orchestration platform for physical ai,
NVIDIA, “Nvidia osmo: Cloud-native orchestration platform for physical ai,” Product page, 2025. [Online]. Available: https: //us-west-2-aws.osmo.nvidia.com/
work page 2025
-
[41]
Training Deep Nets with Sublinear Memory Cost
T. Chen, B. Xu, C. Zhang, and C. Guestrin, “Training deep nets with sublinear memory cost,”arXiv preprint arXiv:1604.06174, 2016. [Online]. Available: https://doi.org/10.48550/arXiv.1604.06174
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1604.06174 2016
-
[42]
Benchmarking flops utilization on tpu v4,
J. Bradbury, Q. Zhang, and A. Selvan, “Benchmarking flops utilization on tpu v4,” Google Cloud (whitepaper), 2023. [Online]. Available: https://services.google.com/fh/files/blogs/tpu v4 benchmarking.pdf
work page 2023
-
[43]
Megascale: Scaling large language model training to more than 10,000 gpus,
Z. Jiang, H. Linet al., “Megascale: Scaling large language model training to more than 10,000 gpus,” inNSDI 2024, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.15627
-
[44]
P. Mattson, C. Cheng, G. Diamos, C. Coleman, P. Micikevicius, D. Patterson, H. Tang, G.-Y . Wei, P. Bailis, V . Bittorf, D. Brooks, D. Chen, D. Dutta, U. Gupta, K. Hazelwood, A. Hock, X. Huang, A. Ike, B. Jia, D. Kang, D. Kanter, N. Kumar, J. Liao, G. Ma, D. Narayanan, T. Oguntebi, G. Pekhimenko, L. Pentecost, V . J. Reddi, T. Robie, T. St. John, T. Tabbe...
-
[45]
Datacenter-scale analysis and optimization of GPU machine learning workloads,
C.-J. Wu, D. Brooks, K. Chen, D. Chen, S. Choudhury, M. Dukhan, K. Hazelwood, E. Isaac, Y . Jia, B. Jia, T. Leesatapornwongsa, H. Li, Y . Lianget al., “Datacenter-scale analysis and optimization of GPU machine learning workloads,”IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 11, pp. 2766–2780, 2021. [Online]. Available: https://doi.o...
-
[46]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: An insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009. [Online]. Available: https://doi.org/10.1145/1498765.1498785
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.