TERDNet: Transformer Encoder-Recurrent Decoder Network for Scene Change Detection
Pith reviewed 2026-05-21 05:04 UTC · model grok-4.3
The pith
TERDNet uses a transformer encoder and recurrent GRU decoder to generate more accurate scene change masks than earlier methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
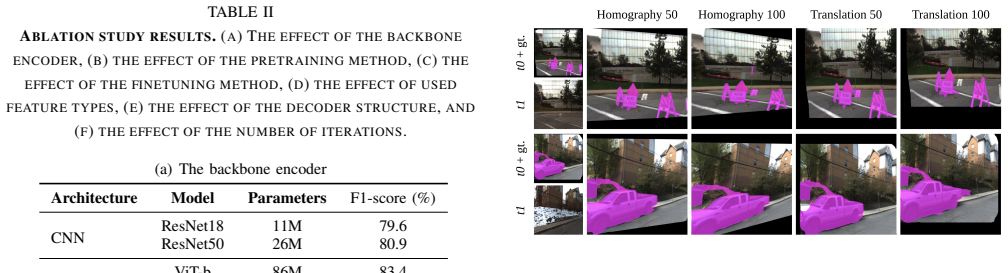
TERDNet consists of a transformer-based encoder that extracts multi-level representations, a feature fusion module that integrates correlation volumes with these features, a recurrent 3-gate-GRU decoder that performs iterative refinement, and a combined convolution-interpolation upsampler that restores fine-grained resolution, yielding more accurate and detailed change masks than prior approaches on four benchmarks.
What carries the argument
Recurrent 3-gate-GRU decoder that iteratively refines the change mask by repeatedly processing fused multi-level features and correlation volumes.
If this is right
- TERDNet produces more accurate and detailed change masks than previous methods across four public benchmarks.
- The recurrent decoder enables iterative refinement that single-step decoders cannot match.
- Segmentation-based pretraining improves results on scene change detection tasks.
- The architecture maintains robustness when viewpoint misalignment occurs between the two input images.
Where Pith is reading between the lines
- The iterative refinement idea could be tested on video sequences to track changes across more than two frames.
- Reducing the number of GRU iterations might trade a small amount of accuracy for faster inference in real-time robotics.
- Pairing the change masks with semantic labels from the same encoder could reveal not only where but why a scene changed.
Load-bearing premise
The performance edge comes from the recurrent decoder and fusion module rather than differences in training length, optimizer settings, or pretraining data not controlled in the ablations.
What would settle it
Retraining the best prior models with identical segmentation-based pretraining, number of epochs, and data augmentation as TERDNet and measuring whether the accuracy gap disappears.
Figures



read the original abstract
In this work, we address the challenge of Scene Change Detection (SCD), where the goal is to identify variations between two images of the same location captured at different times. Existing SCD models often overlook the varying importance of features across layers, employ single-step decoders that confine refinement, and provide limited insight into encoder pretraining strategies. We propose TERDNet, a Transformer Encoder-Recurrent Decoder Network designed to overcome these limitations. TERDNet consists of a transformer-based encoder that extracts multi-level representations, a feature fusion module that integrates correlation volumes with these features, a recurrent 3-gate-GRU decoder that performs iterative refinement, and a combined convolution-interpolation upsampler that restores fine-grained resolution. Extensive experiments on four public benchmarks show that TERDNet consistently outperforms prior approaches and produces more accurate and detailed change masks. Ablation studies confirm the benefit of segmentation-based pretraining and the effectiveness of our fusion design. In addition, robustness tests under viewpoint misalignment confirm TERDNet's potential for deployment in real-world robotic systems, where reliable perception is critical. Our code is available at https://github.com/AutoCompSysLab/TERDNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TERDNet, a Transformer Encoder-Recurrent Decoder Network for scene change detection (SCD). The architecture includes a transformer encoder for multi-level features, a feature fusion module combining correlation volumes, a recurrent 3-gate-GRU decoder for iterative refinement, and a convolution-interpolation upsampler. The central claims are that TERDNet outperforms prior methods on four public benchmarks with more accurate change masks, that segmentation-based pretraining and the fusion design are beneficial (per ablations), and that the model shows robustness to viewpoint misalignment suitable for robotic applications. Code is released.
Significance. If the quantitative results and controlled ablations hold, the work could advance SCD by demonstrating value in recurrent refinement and pretraining strategies over single-step decoders. The combination of transformer features with iterative GRU decoding and explicit robustness testing addresses practical deployment concerns. Code availability supports reproducibility, which strengthens the contribution if the experiments are fully documented.
major comments (2)
- [Ablation studies / Experiments] Ablation studies (referenced in the abstract and likely detailed in the experiments section): The paper claims ablations confirm the benefit of segmentation-based pretraining and the effectiveness of the fusion design. However, it is not stated whether all model variants (e.g., with/without recurrent decoder, different fusion) were trained under identical protocols, including the same number of epochs, optimizer, learning rate schedule, data augmentation, and pretraining data. Without this control, performance deltas cannot be unambiguously attributed to the proposed components rather than optimization differences. This directly impacts the central claim that the recurrent 3-gate-GRU decoder and fusion module deliver the observed gains.
- [Experiments] Quantitative results and tables (experiments section): The abstract asserts consistent outperformance on four benchmarks, yet the provided high-level description lacks specific metrics, error bars, or per-dataset breakdowns. If the full manuscript tables do not include statistical significance tests or comparisons under matched training budgets, the strength of the outperformance claim remains difficult to evaluate.
minor comments (2)
- [Abstract / Experiments] The abstract mentions 'four public benchmarks' without naming them; the experiments section should explicitly list the datasets (e.g., VL-CMU-CD, PCD, etc.) and their characteristics for context.
- [Method] Notation for the 3-gate-GRU decoder and feature fusion module should be formalized with equations in the method section to clarify the iterative refinement process.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our paper. We address each of the major comments below and will make the necessary revisions to improve the clarity and rigor of our experimental analysis.
read point-by-point responses
-
Referee: [Ablation studies / Experiments] Ablation studies (referenced in the abstract and likely detailed in the experiments section): The paper claims ablations confirm the benefit of segmentation-based pretraining and the effectiveness of the fusion design. However, it is not stated whether all model variants (e.g., with/without recurrent decoder, different fusion) were trained under identical protocols, including the same number of epochs, optimizer, learning rate schedule, data augmentation, and pretraining data. Without this control, performance deltas cannot be unambiguously attributed to the proposed components rather than optimization differences. This directly impacts the central claim that the recurrent 3-gate-GRU decoder and fusion module deliver the observed gains.
Authors: We appreciate the referee pointing out this potential ambiguity. All ablation experiments were conducted under strictly identical training protocols: the same optimizer (AdamW), learning rate schedule, number of epochs (200), data augmentation pipeline, and pretraining dataset. The only differences were in the architectural components being ablated. We will add an explicit statement in the revised Experiments section to document this controlled setup, ensuring that the performance gains can be confidently attributed to the proposed modules. revision: yes
-
Referee: [Experiments] Quantitative results and tables (experiments section): The abstract asserts consistent outperformance on four benchmarks, yet the provided high-level description lacks specific metrics, error bars, or per-dataset breakdowns. If the full manuscript tables do not include statistical significance tests or comparisons under matched training budgets, the strength of the outperformance claim remains difficult to evaluate.
Authors: The manuscript includes comprehensive tables in the Experiments section with specific metrics (e.g., F1-score, IoU) for each of the four benchmarks, along with per-dataset breakdowns and comparisons to state-of-the-art methods. To further strengthen the evaluation, we will incorporate error bars based on multiple random seeds and conduct statistical significance tests (e.g., paired t-tests) in the revised tables. Regarding training budgets, all baseline comparisons follow the protocols reported in their respective papers, and we will add a dedicated paragraph clarifying the fairness of these comparisons. revision: yes
Circularity Check
No circularity: empirical architecture evaluated on external benchmarks
full rationale
The paper proposes TERDNet as a transformer-encoder recurrent-decoder architecture for scene change detection and supports its claims solely through experiments on four public benchmarks plus ablation studies. No derivation chain, equations, or first-principles result is presented that could reduce to its own inputs by construction. Performance claims are measured against external datasets and prior methods; ablation statements refer to design choices whose contributions are assessed via controlled comparisons rather than self-definition or fitted-parameter renaming. The work is therefore self-contained against external benchmarks with no load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TERDNet consists of a transformer-based encoder that extracts multi-level representations, a feature fusion module that integrates correlation volumes with these features, a recurrent 3-gate-GRU decoder that performs iterative refinement...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ablation studies confirm the benefit of segmentation-based pretraining and the effectiveness of our fusion design.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
How to reduce change detection to semantic segmentation,
G.-H. Wang, B.-B. Gao, and C. Wang, “How to reduce change detection to semantic segmentation,”Pattern Recognition, vol. 138, p. 109384, 2023
work page 2023
-
[2]
Image change detection algorithms: a systematic survey,
R. J. Radke, S. Andra, O. Al-Kofahi, and B. Roysam, “Image change detection algorithms: a systematic survey,”IEEE Transactions on Image Processing, vol. 14, pp. 294–307, 2005
work page 2005
-
[3]
City-scale scene change detection using point clouds,
Z. J. Yew and G. H. Lee, “City-scale scene change detection using point clouds,” inIEEE International Conference on Robotics and Automation, 2021, pp. 13 362–13 369
work page 2021
-
[4]
Zeroscd: Zero-shot street scene change detection,
S. S. Kannan and B.-C. Min, “Zeroscd: Zero-shot street scene change detection,” inIEEE International Conference on Robotics and Automa- tion, 2025, pp. 4665–4671
work page 2025
-
[5]
Lista: Geometric object-based change detection in cluttered environments,
J. Rowell, L. Zhang, and M. Fallon, “Lista: Geometric object-based change detection in cluttered environments,” inIEEE International Conference on Robotics and Automation, 2024, pp. 3632–3638
work page 2024
-
[6]
3d vsg: Long-term semantic scene change prediction through 3d variable scene graphs,
S. Looper, J. Rodriguez-Puigvert, R. Siegwart, C. Cadena, and L. Schmid, “3d vsg: Long-term semantic scene change prediction through 3d variable scene graphs,” inIEEE International Conference on Robotics and Automation, 2023, pp. 8179–8186
work page 2023
-
[7]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo,et al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
work page 2023
-
[8]
Lightweight event- based optical flow estimation via iterative deblurring,
Y . Wu, F. Paredes-Vall ´es, and G. C. De Croon, “Lightweight event- based optical flow estimation via iterative deblurring,” inIEEE Inter- national Conference on Robotics and Automation, 2024, pp. 14 708– 14 715
work page 2024
-
[9]
Rfl-cdnet: Towards accurate change detection via richer feature learning,
Y . Gan, W. Xuan, H. Chen, J. Liu, and B. Du, “Rfl-cdnet: Towards accurate change detection via richer feature learning,”Pattern Recog- nition, vol. 153, p. 110515, 2024
work page 2024
-
[10]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2117–2125
work page 2017
-
[11]
Zero-shot scene change detection,
K. Cho, D. Y . Kim, and E. Kim, “Zero-shot scene change detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 2509–2517
work page 2025
-
[12]
Robust scene change detection using visual foundation models and cross-attention mecha- nisms,
C.-J. Lin, S. Garg, T.-J. Chin, and F. Dayoub, “Robust scene change detection using visual foundation models and cross-attention mecha- nisms,” inIEEE International Conference on Robotics and Automa- tion, 2025, pp. 8337–8343
work page 2025
-
[13]
Towards generalizable scene change detec- tion,
J.-W. Kim and U.-H. Kim, “Towards generalizable scene change detec- tion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 24 463–24 473
work page 2025
-
[14]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” inEuropean Conference on Computer Vision, 2020, pp. 402–419
work page 2020
-
[15]
Mvflow: Deep optical flow estimation of compressed videos with motion vector prior,
S. Zhou, X. Jiang, W. Tan, R. He, and B. Yan, “Mvflow: Deep optical flow estimation of compressed videos with motion vector prior,” in Proceedings of the ACM International Conference on Multimedia, 2023, pp. 1964–1974
work page 2023
-
[16]
Nonlocal patch similarity based heterogeneous remote sensing change detection,
Y . Sun, L. Lei, X. Li, H. Sun, and G. Kuang, “Nonlocal patch similarity based heterogeneous remote sensing change detection,” Pattern Recognition, vol. 109, p. 107598, 2021
work page 2021
-
[17]
Urban change detection for multispectral earth observation using convolutional neural networks,
R. C. Daudt, B. Le Saux, A. Boulch, and Y . Gousseau, “Urban change detection for multispectral earth observation using convolutional neural networks,” inIEEE International Geoscience and Remote Sensing Symposium, 2018, pp. 2115–2118
work page 2018
-
[18]
Convolutional lstm network: A machine learning approach for precipitation nowcasting,
X. Shi, Z. Chen, H. Wang, D.-Y . Yeung, W.-K. Wong, and W.-c. Woo, “Convolutional lstm network: A machine learning approach for precipitation nowcasting,”Advances in Neural Information Processing Systems, vol. 28, 2015
work page 2015
-
[19]
L-unet: An lstm network for remote sensing image change detection,
S. Sun, L. Mu, L. Wang, and P. Liu, “L-unet: An lstm network for remote sensing image change detection,”IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2020
work page 2020
-
[20]
Background-mixed augmentation for weakly supervised change de- tection,
R. Huang, R. Wang, Q. Guo, J. Wei, Y . Zhang, W. Fan, and Y . Liu, “Background-mixed augmentation for weakly supervised change de- tection,” inProceedings of the AAAI Conference on Artificial Intelli- gence, 2023, pp. 7919–7927
work page 2023
-
[21]
Change detection in synthetic aperture radar images based on deep neural networks,
M. Gong, J. Zhao, J. Liu, Q. Miao, and L. Jiao, “Change detection in synthetic aperture radar images based on deep neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 27, pp. 125–138, 2015
work page 2015
-
[22]
Fully convolutional siamese networks for change detection,
R. C. Daudt, B. Le Saux, and A. Boulch, “Fully convolutional siamese networks for change detection,” inIEEE International Conference on Image Processing, 2018, pp. 4063–4067
work page 2018
-
[23]
Fully convolutional networks for semantic segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431–3440
work page 2015
-
[24]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical Image Com- puting and Computer-Assisted Intervention: International Conference, 2015, pp. 234–241
work page 2015
-
[25]
Weakly supervised silhouette-based semantic scene change detection,
K. Sakurada, M. Shibuya, and W. Wang, “Weakly supervised silhouette-based semantic scene change detection,” inIEEE Interna- tional Conference on Robotics and Automation, 2020, pp. 6861–6867
work page 2020
-
[26]
Dr-tanet: Dynamic receptive temporal attention network for street scene change detection,
S. Chen, K. Yang, and R. Stiefelhagen, “Dr-tanet: Dynamic receptive temporal attention network for street scene change detection,” inIEEE Intelligent Vehicles Symposium, 2021, pp. 502–509
work page 2021
-
[27]
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, pp. 834–848, 2017
work page 2017
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby,et al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. D. M.-W. C. Kenton and L. K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of Human Language Technology: Conference of the North American Chapter of the Association of Computational Linguistics, 2019, pp. 4171–4186
work page 2019
-
[30]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[31]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[32]
L. H. Mormille, C. Broni-Bediako, and M. Atsumi, “Introducing inductive bias on vision transformers through gram matrix similarity based regularization,”Artificial Life and Robotics, vol. 28, pp. 106– 116, 2023
work page 2023
-
[33]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022
work page 2021
-
[34]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision, 2020, pp. 213–229
work page 2020
-
[35]
Delving deeper into convolutional networks for learning video representations,
N. Ballas, L. Yao, C. Pal, and A. Courville, “Delving deeper into convolutional networks for learning video representations,” inInter- national Conference on Learning Representations, 2016
work page 2016
-
[36]
Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms,
Y . Wang, M. Long, J. Wang, Z. Gao, and P. S. Yu, “Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms,” Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[37]
Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning,
Y . Wang, Z. Gao, M. Long, J. Wang, and S. Y . Philip, “Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning,” inInternational Conference on Machine Learn- ing, 2018, pp. 5123–5132
work page 2018
-
[38]
Flownet: Learning optical flow with convolutional networks,
A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V . Golkov, P. Van Der Smagt, D. Cremers, and T. Brox, “Flownet: Learning optical flow with convolutional networks,” inProceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2758–2766
work page 2015
-
[39]
Change detection from a street image pair using cnn features and superpixel segmentation,
K. Sakurada and T. Okatani, “Change detection from a street image pair using cnn features and superpixel segmentation,” inBritish Machine Vision Conference, 2015
work page 2015
-
[40]
Street- view change detection with deconvolutional networks,
P. F. Alcantarilla, S. Stent, G. Ros, R. Arroyo, and R. Gherardi, “Street- view change detection with deconvolutional networks,”Autonomous Robots, vol. 42, pp. 1301–1322, 2018
work page 2018
-
[41]
Changesim: Towards end-to-end online scene change detection in industrial indoor environments,
J.-M. Park, J.-H. Jang, S.-M. Yoo, S.-K. Lee, U.-H. Kim, and J.-H. Kim, “Changesim: Towards end-to-end online scene change detection in industrial indoor environments,” inIEEE/RSJ International Confer- ence on Intelligent Robots and Systems, 2021, pp. 8578–8585
work page 2021
-
[42]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009
work page 2022
-
[43]
Electra: Pre- training text encoders as discriminators rather than generators,
K. Clark, M.-T. Luong, Q. V . Le, and C. D. Manning, “Electra: Pre- training text encoders as discriminators rather than generators,” in International Conference on Learning Representations, 2020
work page 2020
-
[44]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[45]
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean Conference on Computer Vision, 2022, pp. 709–727
work page 2022
-
[46]
Hierarchical paired channel fusion network for street scene change detection,
Y . Lei, D. Peng, P. Zhang, Q. Ke, and H. Li, “Hierarchical paired channel fusion network for street scene change detection,”IEEE Transactions on Image Processing, vol. 30, pp. 55–67, 2020
work page 2020
-
[47]
J.-M. Park, U.-H. Kim, S.-H. Lee, and J.-H. Kim, “Dual task learning by leveraging both dense correspondence and mis-correspondence for robust change detection with imperfect matches,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 749–13 759
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.