PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
Pith reviewed 2026-05-21 04:52 UTC · model grok-4.3
The pith
PlanningBench generates scalable planning data with built-in verification from a taxonomy of real scenarios to evaluate and train LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PlanningBench abstracts practical planning workflows into a taxonomy of more than thirty task types, subtasks, constraint families, and difficulty factors. A constraint-driven synthesis pipeline then creates self-contained problems with adaptive difficulty control, quality filtering, and instance-level verification checklists, shifting data construction from fixed collection to controllable generation while keeping realistic grounding.
What carries the argument
Constraint-driven synthesis pipeline that instantiates planning problems from the taxonomy of task types, subtasks, constraint families, and difficulty factors, supplying built-in verification checklists.
If this is right
- Frontier LLMs continue to struggle when required to produce complete solutions under multiple coupled constraints.
- Reinforcement learning on verified PlanningBench instances raises performance on previously unseen planning benchmarks.
- The same training also improves results on broader instruction-following tasks outside planning.
- Problems that possess determinate optimal solutions supply clearer reward signals and yield more stable training dynamics.
Where Pith is reading between the lines
- The same taxonomy-guided generation approach could be reused to create training data for other structured reasoning domains such as multi-step code synthesis.
- Researchers could isolate individual difficulty factors to map which structural features cause the largest performance drops across model families.
- Hybrid test suites that combine PlanningBench instances with existing benchmarks might reveal whether gains transfer to real-world planning applications.
Load-bearing premise
The taxonomy drawn from real planning scenarios accurately reflects the structural sources of planning difficulty and produces automatic verification that aligns with human judgment of solution quality.
What would settle it
An experiment in which models trained with reinforcement learning on PlanningBench data show no improvement on other planning benchmarks, or in which human judges frequently disagree with the automatic verification checklists about solution correctness.
Figures



read the original abstract
Planning is a fundamental capability for large language models (LLMs) because such complex tasks require models to coordinate goals, constraints, resources, and long-term consequences into executable and verifiable solutions. Existing planning benchmarks, however, usually treat planning data as fixed collections of instances rather than controllable generation targets. This limits scenario coverage, ties difficulty to surface-level proxies rather than structural sources, and offers limited support for scalable generation, automatic verification, or planning-oriented training. We introduce PlanningBench, a framework for generating scalable, diverse, and verifiable planning data for both evaluation and training. PlanningBench starts from real planning scenarios and abstracts practical workflows into a structured taxonomy of more than 30 task types, subtasks, constraint families, and difficulty factors. Guided by this taxonomy, a constraint-driven synthesis pipeline instantiates self-contained planning problems with adaptive difficulty control, quality filtering, and instance-level verification checklists. This shifts planning data construction from fixed benchmark collection to controllable generation while preserving realistic task grounding. We use PlanningBench to evaluate open-source and closed-source frontier LLMs, and find that current models still struggle to produce complete solutions under coupled constraints. Beyond evaluation, reinforcement learning on verified PlanningBench data improves performance on unseen planning benchmarks and broader instruction-following tasks. Further analysis suggests that determinate or well-specified optimal solutions provide clearer reward signals and more stable training dynamics. Overall, PlanningBench provides a controllable source of planning data for diagnosing and improving generalizable planning abilities in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PlanningBench, a framework for generating scalable, diverse, and verifiable planning data for LLM evaluation and training. It abstracts real-world planning scenarios into a taxonomy of over 30 task types, subtasks, constraint families, and difficulty factors, then employs a constraint-driven synthesis pipeline with adaptive difficulty control, quality filtering, and instance-level verification checklists. The authors evaluate open- and closed-source frontier LLMs, reporting struggles with coupled constraints, and demonstrate that reinforcement learning on verified PlanningBench instances yields performance gains on unseen planning benchmarks and broader instruction-following tasks, attributing improved training stability to determinate or well-specified optimal solutions.
Significance. If the empirical claims hold, the work provides a meaningful advance by moving planning benchmarks from static instance collections to controllable, grounded generative systems. The taxonomy and automatic verification approach directly address coverage and verifiability limitations in prior benchmarks. Credit is due for the reproducible synthesis pipeline, the extension of RL gains to general instruction-following, and the emphasis on verifiable data that supports both diagnosis and training of planning abilities.
major comments (2)
- [§6 (RL Training and Analysis)] §6 (RL Training and Analysis): The central claim that determinate or well-specified optimal solutions provide clearer reward signals and more stable training dynamics assumes solution uniqueness across task types. The constraint-driven pipeline and verification checklists certify validity and completeness but do not establish uniqueness; domains such as scheduling and resource allocation commonly admit multiple feasible optima under the stated constraints. If rewards are computed against a single reference plan rather than any valid plan, the asserted stability gains may not follow, directly impacting the load-bearing RL improvement results.
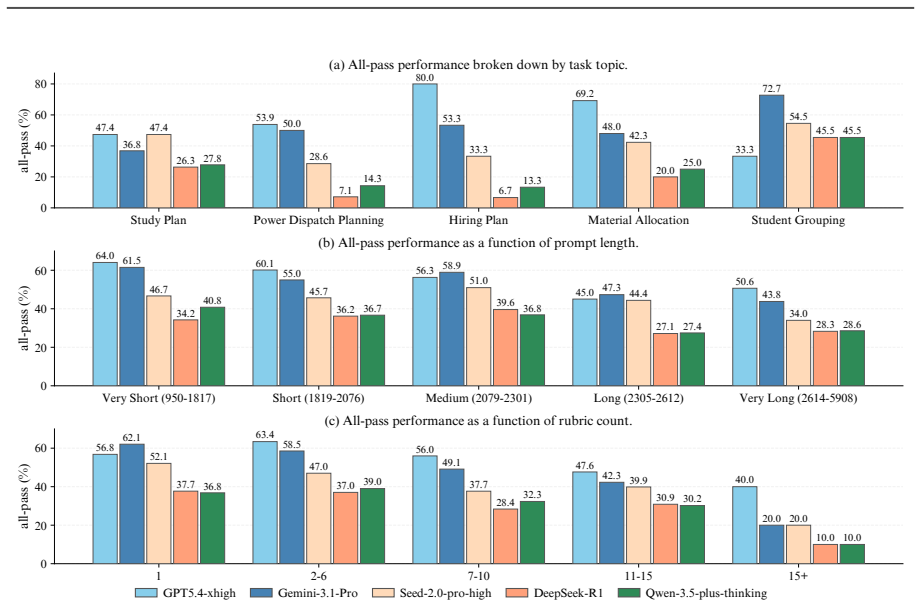
- [§5 (LLM Evaluation Results)] §5 (LLM Evaluation Results): The reported struggles of current models under coupled constraints and the RL performance improvements on unseen benchmarks require explicit quantitative metrics, baseline comparisons, and ablation controls to be verifiable. The abstract states these outcomes without supplying the necessary numbers or experimental details, leaving the strength of the evaluation claims difficult to assess from the provided text.
minor comments (2)
- [Taxonomy section] The taxonomy overview would benefit from a consolidated table listing all task types, subtasks, constraint families, and difficulty factors with brief definitions for quick reference.
- [Pipeline figure] Figure illustrating the synthesis pipeline could include explicit callouts for the quality filtering and verification checklist steps to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments identify important points regarding the rigor of our RL analysis and the presentation of evaluation results. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§6 (RL Training and Analysis)] §6 (RL Training and Analysis): The central claim that determinate or well-specified optimal solutions provide clearer reward signals and more stable training dynamics assumes solution uniqueness across task types. The constraint-driven pipeline and verification checklists certify validity and completeness but do not establish uniqueness; domains such as scheduling and resource allocation commonly admit multiple feasible optima under the stated constraints. If rewards are computed against a single reference plan rather than any valid plan, the asserted stability gains may not follow, directly impacting the load-bearing RL improvement results.
Authors: We appreciate this observation on solution uniqueness. Our constraint-driven synthesis does incorporate families of constraints intended to narrow the solution space, and the verification checklists confirm that generated reference plans are valid and complete. However, we acknowledge that the current pipeline description does not explicitly verify or enforce uniqueness across all task types, and domains such as scheduling can admit multiple optima. In the RL experiments, rewards are computed against a single reference plan. We will revise §6 to include an explicit discussion of this limitation, add analysis of solution multiplicity where feasible (e.g., via post-generation checks), and clarify the conditions under which the observed training stability is expected to hold. This will be presented as a partial revision with additional text and a small-scale diagnostic experiment. revision: partial
-
Referee: [§5 (LLM Evaluation Results)] §5 (LLM Evaluation Results): The reported struggles of current models under coupled constraints and the RL performance improvements on unseen benchmarks require explicit quantitative metrics, baseline comparisons, and ablation controls to be verifiable. The abstract states these outcomes without supplying the necessary numbers or experimental details, leaving the strength of the evaluation claims difficult to assess from the provided text.
Authors: We agree that the abstract is high-level and does not contain the specific quantitative results or cross-references needed for immediate assessment. The body of the manuscript in §5 does report concrete metrics (e.g., success rates under varying constraint coupling, comparisons against standard baselines, and ablation results on RL components), but these are not summarized in the abstract. We will revise the abstract to include key quantitative highlights and will add explicit pointers to the relevant tables and ablation studies. This change will be made in the next version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's contributions center on a taxonomy abstracted from real planning scenarios, a constraint-driven synthesis pipeline for generating verifiable instances, and subsequent empirical evaluations of LLMs plus RL training on the resulting data. No equations, derivations, or self-referential definitions appear that reduce outputs to inputs by construction. Claims regarding clearer reward signals from determinate optimal solutions are presented as observations from experimental analysis rather than tautological fits or renamings. Any self-citations (if present in the full text) are not load-bearing for the core results, which rest on external benchmarks and training dynamics. The verification checklists certify validity independently of the RL claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real planning scenarios can be abstracted into a structured taxonomy of task types, subtasks, constraint families, and difficulty factors that guides scalable synthesis.
Reference graph
Works this paper leans on
-
[1]
Delayed order.The response completes only13 out of 14 batchesof O6, leaving1 batch unfinishedand causing a delay
-
[2]
Incorrect load allocation.In the response,D1-Dayis assignedO1 = 10 batches + O2 = 2 batches, whereas the reference solution requires only11 batchesin this shift, changing the global load profile
-
[3]
Raw-material violation on D3.The response assigns105 kgto D3-Day and72 kgto D3-Night, for a total of 177 kg, which exceeds the available174 kgon D3
-
[4]
Secondary objective not achieved.Because the realized shift loads are12, 10, 12, 11, 12, 12, the maximum load gap becomes2 batches, rather than the optimal value of1 batch. Therefore, the response violates bothprimary-objective optimalityandconstraint correctness, and does not match the intended optimal solution. F Training Details For GRPO-based reinforc...
-
[5]
The task must clearly specify the planning objective to be solved; it must not simply say``make a reasonable plan''.,→
-
[6]
The task must explicitly provide the input information; core parameters must not be left for the test-taker to assume.,→
-
[7]
The task should, as explicitly as possible, provide: - the objects or tasks that need to be arranged; - the available resources; - the time windows or execution period; - upper bounds on capacity, budget, headcount, labor hours, or distance; - conflict relations, precedence dependencies, or non-parallelism constraints; - the required output format
-
[8]
The task must require the test-taker to output the final plan, not merely an analysis process.,→
-
[9]
If appropriate for the scenario, the task may additionally require the test-taker to provide a brief feasibility check, key rationale for major arrangements, a backup plan, or an explanation of infeasibility. ,→ ,→
-
[10]
If the task involves raw data, candidate lists, timetables, text-based tables, or case background, these materials must be sufficiently concrete rather than purely abstract. ,→ ,→
-
[11]
The data and constraints in the task must be internally consistent; the task must not be obviously infeasible without explanation, nor so loose that it lacks planning difficulty. ,→ ,→
-
[12]
The task itself should read like a natural request that a real user might make, while the internal data should remain sufficiently structured for downstream evaluation. ,→ ,→
-
[13]
It should read like a realistic planning request.,→
Do not write the task as a pure checklist; do not begin with a rigid stack of a dozen numbered constraints. It should read like a realistic planning request.,→
-
[14]
If the task involves data to be processed, background information, candidate resource lists, or an existing old plan, that part should contain at least [WORD_COUNT] words to ensure sufficient complexity and information density. ,→ ,→
-
[15]
[TONE] [Requirements for Checklist Design] - Design a 0/1 scoring standard: assign 1 only if all conditions are satisfied; assign 0 if any key condition is not satisfied.,→ - The checklist must be tightly bound to the task and must be suitable for verifying whether the test-taker's answer to this planning task is acceptable.,→ - The checklist should cover...
-
[16]
Whether the required planning result is actually output, rather than only an explanation of the approach;,→
-
[17]
Whether all key objects / tasks / resources in the task are covered
-
[18]
Whether the answer satisfies the core constraints in the task, including time, capacity, budget, headcount, ordering, conflict, and dependency constraints; ,→ ,→
-
[19]
Whether the required output format is followed
-
[20]
Whether the explicitly stated high-priority goal or primary/secondary objectives are handled properly;,→ 25
-
[21]
If the task requires verification, explanation, an alternative plan, minimal-change rescheduling, infeasibility diagnosis, or exception recovery, whether these are completed accordingly. ,→ ,→ - Every condition must be directly verifiable and must include a clear verification method; do not write vague criteria.,→ - Every condition should refer to concret...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.