SynCB: A Synergy Concept-Based Model with Dynamic Routing Between Concepts and Complementary Neural Branches
Pith reviewed 2026-05-21 05:43 UTC · model grok-4.3
The pith
SynCB uses dynamic routing between a concept-based branch and a neural branch to raise task accuracy while keeping test-time human interventions effective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SynCB keeps the concept-based and neural branches distinct rather than fusing their outputs, coordinates them via a trainable routing module that selects the branch for each input, and trains both jointly through a common backbone. It introduces a test-time intervention policy and matching loss to improve human responsiveness. On five datasets the model exceeds the full neural baseline by up to 3.9 percentage points in accuracy and the strongest prior competitor by up to 6.43 percentage points in intervention performance.
What carries the argument
The trainable routing module that dynamically assigns each input to either the concept-based branch or the complementary neural branch while both branches share a backbone for joint learning.
If this is right
- Hybrid models can exceed pure neural accuracy while retaining or improving the effectiveness of human concept interventions at test time.
- Keeping the two branches distinct and routing between them avoids the intervention degradation seen when predictions are fused.
- Joint training through a shared backbone allows information to flow from the concept branch into the neural branch and back.
- An explicit intervention policy and loss can be added without sacrificing the accuracy gains from the neural branch.
Where Pith is reading between the lines
- The routing approach could be tested in domains outside computer vision where concept annotations are available, such as medical imaging or autonomous driving.
- If the routing module learns stable assignments, it might reduce the need for manual branch selection in future hybrid systems.
- One could measure whether the shared backbone creates unintended dependencies that affect branch independence under distribution shift.
Load-bearing premise
The central claim assumes that a trainable routing module can reliably assign inputs to either the concept-based or neural branch in a manner that simultaneously improves accuracy and preserves or improves responsiveness to test-time concept interventions, without the routing itself becoming a new source of opacity or error.
What would settle it
A controlled experiment on a new dataset in which the routing module either drops accuracy below the pure neural baseline or reduces intervention effectiveness below the best prior hybrid model would falsify the central claim.
Figures





read the original abstract
Concept-based (CB) models provide interpretability and support test-time human intervention, while standard neural networks (NN) offer strong task performance but little transparency. Prior work has explored hybrid formulations that integrate concepts and additional representations to improve accuracy, often at the cost of human interventions. We introduce the \emph{Synergy Concept-Based Model (SynCB)} framework, that combines a CB branch with a complementary neural branch, and a trainable routing module that dynamically selects which branch to use for each input. Unlike prior models, which fuse residual and concept-based predictions, SynCB keeps the two branches distinct and coordinates them through the routing module. Moreover, both branches are learned jointly, allowing information sharing between the complementary neural branch and CB branches through their common backbone. To improve responsiveness to interventions, we further introduce a test-time intervention policy and a corresponding loss. Across five datasets and CB benchmarks, SynCB consistently achieves higher task accuracy while remaining more responsive to human interventions, surpassing the full neural baseline by up to 3.9 percentage points and exceeding the strongest competitor in intervention performance by up to 6.43 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Synergy Concept-Based Model (SynCB), a hybrid framework that pairs a concept-based (CB) branch with a complementary neural branch. A trainable routing module dynamically assigns each input to one branch while the branches remain distinct and are trained jointly through a shared backbone. A test-time intervention policy together with an associated loss is proposed to preserve or improve responsiveness to human concept interventions. Experiments on five datasets and CB benchmarks report higher task accuracy (up to 3.9 pp above a full neural baseline) and superior intervention performance (up to 6.43 pp above the strongest competitor).
Significance. If the reported accuracy and intervention gains are reproducible and the routing-intervention interaction is shown to function as claimed, the work would offer a concrete mechanism for reducing the accuracy-interpretability trade-off in concept-based models. The combination of distinct branches, joint learning, and an explicit intervention policy could influence subsequent hybrid architectures that aim to support both high performance and test-time human control.
major comments (1)
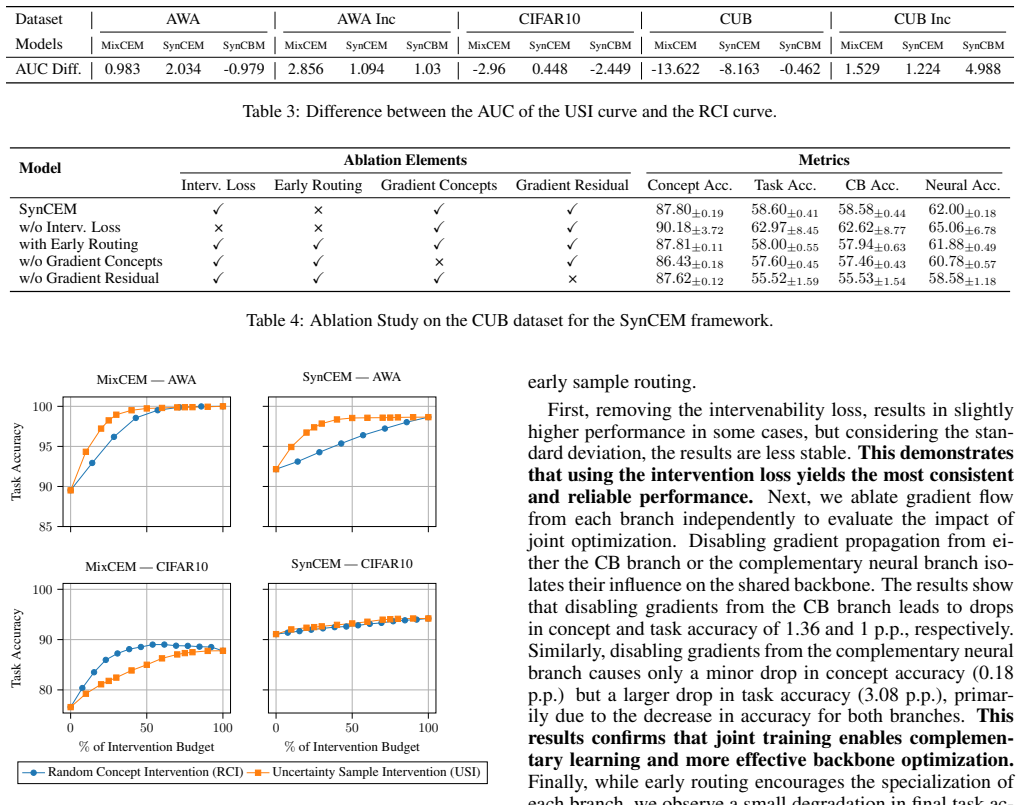
- [Routing module and intervention policy (likely §3.2–3.3)] The responsiveness claim (abstract and §4) depends on the routing module continuing to select the CB branch after interventions are applied. If the router operates on backbone features or pre-intervention logits (as suggested by the joint-training description through the shared backbone), interventions performed only on the CB branch’s concept predictions will leave routing decisions unchanged. In that case a non-negligible fraction of intervened samples could be routed to the neural branch, where the intervention has no effect, undermining the reported 6.43 pp intervention gain. Post-intervention routing statistics or an ablation that isolates the policy-routing interaction are required to substantiate the central claim.
minor comments (1)
- [Abstract] The abstract states results are obtained “across five datasets and CB benchmarks” but does not name the datasets or benchmarks; this information should appear in the main text or a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The observation concerning the routing module's behavior after interventions is important, and we will revise the manuscript to provide the requested evidence.
read point-by-point responses
-
Referee: [Routing module and intervention policy (likely §3.2–3.3)] The responsiveness claim (abstract and §4) depends on the routing module continuing to select the CB branch after interventions are applied. If the router operates on backbone features or pre-intervention logits (as suggested by the joint-training description through the shared backbone), interventions performed only on the CB branch’s concept predictions will leave routing decisions unchanged. In that case a non-negligible fraction of intervened samples could be routed to the neural branch, where the intervention has no effect, undermining the reported 6.43 pp intervention gain. Post-intervention routing statistics or an ablation that isolates the policy-routing interaction are required to substantiate the central claim.
Authors: We agree that explicit evidence of post-intervention routing behavior is necessary to fully support the intervention performance claims. The current manuscript describes the routing module operating on shared backbone features and the introduction of a test-time intervention policy with an associated loss, but does not report routing statistics after interventions are applied. In the revised manuscript we will add (i) tables showing the fraction of samples routed to each branch before versus after interventions on all five datasets and (ii) an ablation that evaluates intervention responsiveness while forcing the router to select the concept-based branch. These additions will directly address the interaction between routing and the intervention policy. revision: yes
Circularity Check
No circularity: claims rest on empirical comparisons
full rationale
The paper proposes the SynCB architecture (CB branch + neural branch + trainable router + test-time intervention policy) and supports its claims exclusively through accuracy and intervention metrics on five datasets. No equations, derivations, or first-principles results are presented that reduce any reported gain to a quantity defined by the model's own fitted parameters or prior self-citations. The central performance numbers (up to 3.9 pp and 6.43 pp) are direct experimental outcomes against external baselines, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
trainable routing module that dynamically selects which branch to use for each input... USI intervention policy... L = λ_t L_task + λ_c L_concept + λ_r L_routing + λ_i L_intervention
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SynCEM and SynCBM... outperforming prior state-of-the-art methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
arXiv:1312.4314 [cs]. [Espinosa Zarlengaet al., 2022 ] Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, Pietro Lio, and Mateja Jamnik. Concept embed- ding models: Beyond the accuracy-explainability trade- off.Advances i...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
[Espinosa Zarlengaet al., 2023 ] Mateo Espinosa Zarlenga, Katie Collins, Krishnamurthy Dvijotham, Adrian Weller, Zohreh Shams, and Mateja Jamnik. Learning to receive help: Intervention-aware concept embedding models.Ad- vances in Neural Information Processing Systems, 36,
work page 2023
-
[4]
Avoiding leakage poisoning: Concept in- terventions under distribution shifts
[Espinosa Zarlengaet al., 2025 ] Mateo Espinosa Zarlenga, Gabriele Dominici, Pietro Barbiero, Zohreh Shams, and Mateja Jamnik. Avoiding leakage poisoning: Concept in- terventions under distribution shifts. InProceedings of the 42nd International Conference on Machine Learning,
work page 2025
-
[5]
[Feduset al., 2022 ] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion param- eter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
work page 2022
-
[6]
[Havasiet al., 2022 ] Marton Havasi, Sonali Parbhoo, and Fi- nale Doshi-Velez. Addressing leakage in concept bottle- neck models.Advances in Neural Information Processing Systems, 35:23386–23397,
work page 2022
-
[7]
Deep residual learning for image recog- nition
[Heet al., 2016 ] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), June
work page 2016
-
[8]
[Jacobset al., 1991 ] Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mix- tures of local experts.Neural Computation, 3(1):79–87,
work page 1991
-
[9]
[Kimet al., 2018 ] Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InProceedings of the 35th International Conference on Machine Learning, page 2668–2677. PMLR, july
work page 2018
-
[11]
[Kingma and Ba, 2014] Diederik P Kingma and Jimmy Ba
arXiv:2306.01574 [cs]. [Kingma and Ba, 2014] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[12]
[Kohet al., 2020 ] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInterna- tional conference on machine learning, pages 5338–5348. PMLR,
work page 2020
-
[13]
Learning multiple layers of features from tiny im- ages
[Krizhevskyet al., 2009 ] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny im- ages. Technical Report TR-2009, University of Toronto,
work page 2009
-
[15]
Promises and pitfalls of black-box concept learning models
arXiv:2106.13314 [cs]. [Margeloiuet al., 2021 ] Andrei Margeloiu, Matthew Ash- man, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended? (arXiv:2105.04289), May
-
[16]
[Oikarinen and Nguyen, 2023] Tuomas Oikarinen and Lam M Nguyen
arXiv:2105.04289 [cs]. [Oikarinen and Nguyen, 2023] Tuomas Oikarinen and Lam M Nguyen. Label-free concept bottleneck models. InInternational Conference on Learning Representations (ICLR),
-
[18]
[Platt and others, 1999] John Platt et al
arXiv:2504.18026 [cs]. [Platt and others, 1999] John Platt et al. Probabilistic outputs for support vector machines and comparisons to regular- ized likelihood methods.Advances in large margin classi- fiers, 10(3):61–74,
-
[20]
[Wahet al., 2011 ] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie
arXiv:2202.01459 [cs]. [Wahet al., 2011 ] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech- ucsd birds-200-2011 dataset,
-
[21]
[Xianet al., 2018 ] Yongqin Xian, Christoph H Lampert, Bernt Schiele, and Zeynep Akata. Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly.IEEE transactions on pattern analysis and machine intelligence, 41(9):2251–2265,
work page 2018
-
[23]
[Yuksekgonulet al., 2023 ] Mert Yuksekgonul, Maggie Wang, and James Zou
arXiv:2401.14142 [cs]. [Yuksekgonulet al., 2023 ] Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models. InThe Eleventh International Conference on Learning Representations,
-
[24]
We optimize using SGD with momentum 0.9. When using a pretrained backbone, the learning rate is set to 0.01 with a weight decay of4×10 −6; for CIFAR10, we use a learning rate of 0.1 with a weight decay of1×10 −6. 5.2 Model description In this section, we describe the models and their hyperparameters. When possible, we followed the choice from the original...
work page 2025
-
[25]
List the most important features for recognizing something as a{class}
The goal of this construction is to obtain a concept set that is incomplete with respect to the final classification task, such that the retained concepts alone are insufficient to perfectly identify the animal species. TheCIFAR10image classification task is constructed from the original CIFAR10 dataset [Krizhevskyet al., 2009 ], in which each image is an...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.