FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching
Pith reviewed 2026-05-21 05:39 UTC · model grok-4.3
The pith
Overlapping sliding windows blended by Tweedie matching let short video diffusion models generate coherent sequences several times longer than their native length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
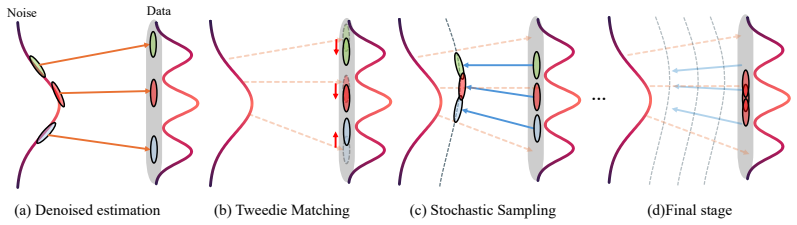
Long videos are produced by running a base diffusion model inside overlapping sliding windows, then blending the clean-sample estimates from adjacent windows with Tweedie matching inside each overlap; this simultaneously projects the blended region onto the data manifold and enforces temporal consistency. Stochastic early-phase sampling, which adds fresh noise after every matching step while the noise level is still high, keeps the independent window trajectories aligned. After the high-noise regime the sampler switches to deterministic ODE integration to retain fine detail. The procedure is architecture-agnostic and yields videos several times longer than the model’s native window while exc
What carries the argument
Tweedie matching on the overlap regions of sliding windows, which fuses predicted clean samples from adjacent windows to satisfy both manifold constraint and temporal consistency, paired with stochastic early-phase noise injection that resynchronizes per-window trajectories.
If this is right
- The same procedure works on any existing video diffusion model without retraining or architecture changes.
- Generated length can exceed the native window by a factor of several while preserving temporal coherence.
- Visual quality and motion consistency exceed those of both training-free extensions and autoregressive baselines.
- The identical overlap-matching recipe transfers directly to audio-video joint generation and text-to-3DGS.
Where Pith is reading between the lines
- Because no training is required, the approach could be used to retrofit large existing video models for longer outputs at far lower cost than retraining.
- The overlap-blending idea may generalize to other sequential diffusion tasks such as long audio or time-lapse image sequences.
- The optimal overlap fraction and number of windows could be studied empirically for different motion speeds or scene complexities.
Load-bearing premise
Tweedie matching performed on overlap regions will enforce both the data manifold and temporal consistency for any base model without creating visible artifacts or requiring per-model adjustments.
What would settle it
Apply the method to a standard short-window video model, generate a sequence spanning at least four windows, and examine whether object trajectories and appearance remain continuous across every overlap boundary; visible jumps, flickering, or manifold violations at those boundaries would falsify the claim.
Figures





read the original abstract
Extending the generation horizon of video diffusion models to long sequences remains a long-standing and important challenge. Existing training-free approaches fall into two categories: extensions of bidirectional models, which are tightly coupled to specific architectures and suffer from quality degradation over long horizons, and autoregressive models, which accumulate drift errors due to exposure bias and tend to produce repetitive motion patterns. To address these issues, we propose a novel but simple inference-time approach for long video generation that is architecture-agnostic and requires no additional training. Our method generates long videos via overlapping sliding windows, where predicted clean samples from adjacent windows are blended via \emph{Tweedie matching} to enforce both \textbf{manifold constraint and temporal consistency} across overlap regions. \emph{Stochastic early-phase sampling} then synchronizes per-window trajectories by injecting fresh noise after each Tweedie matching correction in the high-noise phase, before transitioning to deterministic ODE sampling to preserve fine-grained visual fidelity. Applied to various video generation models, our method generates videos several times longer than the native window length while outperforming both training-free and autoregressive baselines in temporal consistency and visual quality, and further extends to audio-video joint generation and text-to-3DGS without any fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FlowLong, an inference-time, training-free method for long video generation from diffusion models. It processes sequences via overlapping sliding windows, blends predicted clean samples from adjacent windows using Tweedie matching to enforce manifold constraints and temporal consistency, and employs stochastic early-phase sampling to synchronize trajectories before switching to deterministic ODE sampling. The approach is claimed to be architecture-agnostic and to generate videos several times longer than native window lengths while outperforming training-free and autoregressive baselines in temporal consistency and visual quality; extensions to audio-video joint generation and text-to-3DGS are also asserted.
Significance. If the empirical claims hold, the work would supply a simple, broadly applicable inference-time recipe for extending existing video diffusion models to longer horizons without retraining or architecture changes. This addresses a persistent limitation in current video generation pipelines and could enable more practical use in applications requiring extended coherent sequences.
major comments (2)
- [Abstract] Abstract: the claim that the method 'outperforms both training-free and autoregressive baselines in temporal consistency and visual quality' is presented without any quantitative metrics, ablation results, or error analysis. This absence is load-bearing for the central empirical claim of superiority.
- [Method] Method description (Tweedie matching step): the construction assumes that independently denoised clean predictions from adjacent windows lie sufficiently close on the data manifold for their Tweedie-weighted blend to remain on-manifold and temporally coherent. No derivation or continuity argument is supplied showing why this holds for arbitrary base models when per-window trajectories may diverge after stochastic injection; this assumption underpins the architecture-agnostic claim.
minor comments (1)
- [Abstract] The manuscript introduces 'Tweedie matching' and 'stochastic early-phase sampling' without a concise mathematical definition or reference to the underlying Tweedie formula in the main text, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of our empirical claims and theoretical assumptions. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'outperforms both training-free and autoregressive baselines in temporal consistency and visual quality' is presented without any quantitative metrics, ablation results, or error analysis. This absence is load-bearing for the central empirical claim of superiority.
Authors: We agree that the abstract claim would be more convincing with explicit quantitative backing. We will revise the abstract to reference key metrics (e.g., temporal consistency scores and visual quality measures such as FID) along with a brief mention of ablations and error analysis from the experiments, making the superiority statement self-contained while preserving its high-level nature. revision: yes
-
Referee: [Method] Method description (Tweedie matching step): the construction assumes that independently denoised clean predictions from adjacent windows lie sufficiently close on the data manifold for their Tweedie-weighted blend to remain on-manifold and temporally coherent. No derivation or continuity argument is supplied showing why this holds for arbitrary base models when per-window trajectories may diverge after stochastic injection; this assumption underpins the architecture-agnostic claim.
Authors: This is a fair critique of the missing formal support. The stochastic early-phase injection is intended to keep per-window trajectories aligned so that the clean predictions remain close enough for the Tweedie blend to preserve manifold and temporal properties. We will add a concise continuity argument and derivation sketch in the method section, based on the contraction properties induced by noise re-injection, to better justify the assumption and the architecture-agnostic applicability. revision: yes
Circularity Check
No significant circularity; method is a self-contained procedural recipe
full rationale
The paper presents FlowLong as an inference-time procedure that generates long videos by overlapping sliding windows, blending adjacent-window clean predictions via Tweedie matching to enforce manifold constraint and temporal consistency, followed by stochastic early-phase sampling and deterministic ODE sampling. No equations, derivations, or fitted parameters are shown that reduce the claimed temporal consistency or manifold enforcement to a quantity defined in terms of itself or to a self-citation chain. The architecture-agnostic claim rests on the empirical behavior of the blending step rather than any tautological reduction or imported uniqueness theorem. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models admit a Tweedie formula that can be used to blend predictions while staying on the data manifold.
- domain assumption Overlapping windows plus early stochastic noise can synchronize independent generation trajectories without drift.
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14834–14844, 2025
work page 2025
-
[2]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. 2023
work page 2023
-
[3]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[4]
Hyungjin Chung, Suhyeon Lee, and Jong Chul Ye. Decomposed diffusion sampler for acceler- ating large-scale inverse problems.arXiv preprint arXiv:2303.05754, 2023
-
[5]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
work page 2011
-
[7]
Text-to-3d by stitching a multi-view reconstruction network to a video generator
Hyojun Go, Dominik Narnhofer, Goutam Bhat, Prune Truong, Federico Tombari, and Konrad Schindler. Text-to-3d by stitching a multi-view reconstruction network to a video generator. In The Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[8]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Yeobin Hong, Suhyeon Lee, Hyungjin Chung, and Jong Chul Ye. Inversecrafter: Efficient video recapture as a latent domain inverse problem.arXiv preprint arXiv:2512.05672, 2025
-
[11]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[13]
Reangle-a-video: 4d video generation as video-to-video translation
Hyeonho Jeong, Suhyeon Lee, and Jong Chul Ye. Reangle-a-video: 4d video generation as video-to-video translation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11164–11175, 2025
work page 2025
-
[14]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
work page 2025
-
[15]
Flowdps: Flow-driven posterior sampling for inverse problems
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. Flowdps: Flow-driven posterior sampling for inverse problems. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12328–12337, 2025
work page 2025
-
[16]
Fifo-diffusion: Generating infinite videos from text without training
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training. InNeurIPS, 2024
work page 2024
-
[17]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Jangho Park, Taesung Kwon, and Jong Chul Ye. Zero4d: Training-free 4d video generation from single video using off-the-shelf video diffusion model.arXiv e-prints, pages arXiv–2503, 2025
work page 2025
-
[21]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
Junyoung Seo, Hyunwook Choi, Minkyung Kwon, Jinhyeok Choi, Siyoon Jin, Gayoung Lee, Junho Kim, JoungBin Lee, Geonmo Gu, Dongyoon Han, et al. Grounding world simulation models in a real-world metropolis.arXiv preprint arXiv:2603.15583, 2026
-
[24]
Advancing Open-source World Models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
SV3D: Novel multi-view synthesis and 3D generation from a single image using latent video diffusion
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitrii Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. SV3D: Novel multi-view synthesis and 3D generation from a single image using latent video diffusion. InEuropean Conference on Computer Vision (ECCV), 2024
work page 2024
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
4real-video: Learning generalizable photo-realistic 4d video diffusion
Chaoyang Wang, Peiye Zhuang, Tuan Duc Ngo, Willi Menapace, Aliaksandr Siarohin, Michael Vasilkovsky, Ivan Skorokhodov, Sergey Tulyakov, Peter Wonka, and Hsin-Ying Lee. 4real-video: Learning generalizable photo-realistic 4d video diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17723–17732, 2025
work page 2025
-
[28]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26057–26068, 2025
work page 2025
-
[29]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout.arXiv preprint arXiv:2511.20649, 2025
-
[31]
H., Nam, J., Yoon, H., and Kim, S
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081, 2025. 11
-
[32]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
work page 2024
-
[33]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In CVPR, 2025
work page 2025
-
[34]
Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025
work page 2025
-
[35]
Prometheus: 3d-aware latent diffusion models for feed-forward text-to-3d scene generation
Yang Yuanbo, Shao Jiahao, Li Xinyang, Shen Yujun, Geiger Andreas, and Liao Yiyi. Prometheus: 3d-aware latent diffusion models for feed-forward text-to-3d scene generation. arxiv:2412.21117, 2024
-
[36]
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models.arXiv preprint arXiv:2504.12626, 2025
-
[37]
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression.arXiv preprint arXiv:2512.23851, 2025
-
[38]
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. Riflex: A free lunch for length extrapolation in video diffusion transformers.arXiv preprint arXiv:2502.15894, 2025
-
[39]
Min Zhao, Hongzhou Zhu, Yingze Wang, Bokai Yan, Jintao Zhang, Guande He, Ling Yang, Chongxuan Li, and Jun Zhu. Ultravico: Breaking extrapolation limits in video diffusion transformers.arXiv preprint arXiv:2511.20123, 2025. 12 A Tweedie Matching: Implementation Details This appendix expands the practical details of Sec. 4.1. We describe the latent-space wi...
-
[40]
Boundary consistency. λF−O = 0 and λF−1 = 1 . Hence the leftmost frame of the blending zone is taken entirely from chunk k, and the rightmost frame entirely from chunk k+ 1. The matched estimate ¯x(k) 0|t therefore agrees exactly with ˆx(k) 0|t at the seam j=F−O and exactly with ˆx(k+1) 0|t at j=F−1 , eliminating any discontinuity at either side of the overlap
-
[41]
, O−1} , we have λj = i/(O−1)and the mirror identity λj +λ jmir = 1, j mir = (F−O) + (O−1)−i=F−1−i
Symmetry.Setting the local index i=j−(F−O)∈ {0, . . . , O−1} , we have λj = i/(O−1)and the mirror identity λj +λ jmir = 1, j mir = (F−O) + (O−1)−i=F−1−i. 13 Equivalently, chunk k’s update applies weight λj to chunk k+ 1 ’s prediction, while the symmetric update applied to chunk k+ 1 (Sec. 4.1) applies weight 1−λ j to chunk k’s prediction at the same globa...
-
[42]
λj is linear in the frame index, so frame-level transitions across the blending zone are uniform
Smoothness. λj is linear in the frame index, so frame-level transitions across the blending zone are uniform. We did not observe additional gains from smoother schedules (e.g. raised-cosine windows) in preliminary experiments, while the linear form admits the simple equivalence in §A.3. A.3 Multi-chunk pairwise updates collapse to a single weighted aggreg...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.