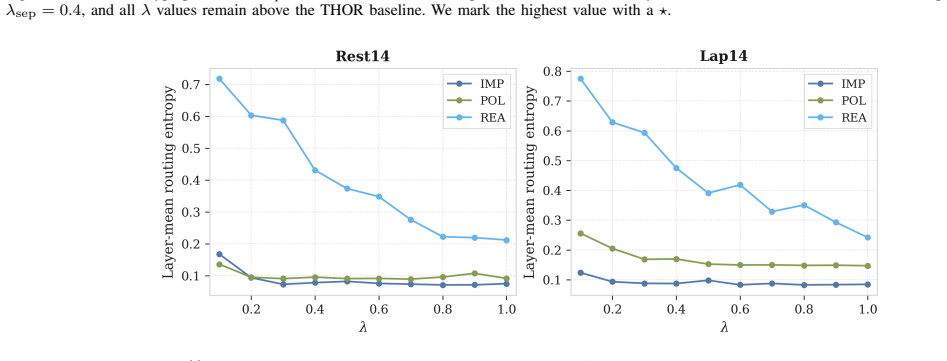
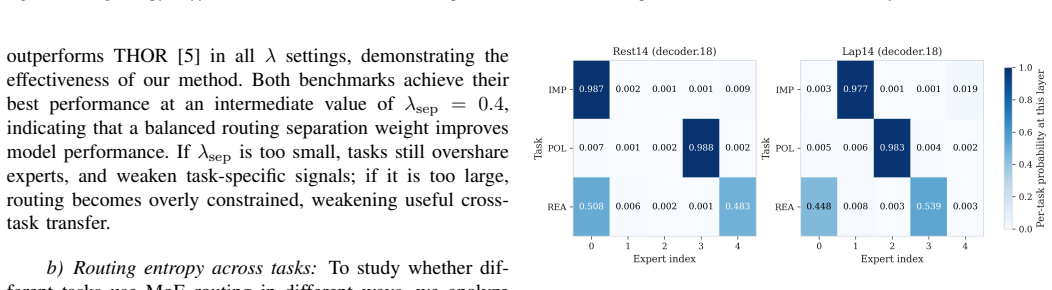
Task-Routed Mixture-of-Experts with Cognitive Appraisal for Implicit Sentiment Analysis
Pith reviewed 2026-05-21 04:38 UTC · model grok-4.3
The pith
Task-routed mixture-of-experts with cognitive appraisal tasks improves implicit sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Motivated by cognitive appraisal theory, the authors propose an appraisal-aware multi-task learning framework for implicit sentiment analysis that supplies polarity prediction with two auxiliary tasks: implicit sentiment detection and cognitive rationale generation. To avoid interference when multiple objectives share one backbone, they introduce task-level mixture-of-experts models in which all tasks share a common expert pool and task identity controls the sparse expert selection. The method replaces a subset of encoder and decoder blocks with these mixtures, employs a task-conditioned router, and adds a task-separated routing objective that pushes different tasks toward distinct selection
What carries the argument
Task-level mixture-of-experts in which task identity selects sparse expert combinations via a task-conditioned router and a task-separated routing objective within an encoder-decoder architecture.
If this is right
- The model outperforms recently proposed approaches on implicit sentiment analysis.
- Gains are strongest on the implicit sentiment subset where sentiment must be inferred from context.
- Auxiliary tasks of detection and rationale generation supply additional signals for polarity reasoning.
- Task-conditioned sparse routing limits negative transfer among related but distinct objectives.
Where Pith is reading between the lines
- The same routing pattern could reduce interference in other multi-task NLP setups that combine detection, generation, and classification objectives.
- Cognitive-rationale generation may prove useful for any inference task where models must articulate unstated information before predicting a label.
- Conditioning expert selection on task identity offers a general knob for controlling capacity allocation when objectives compete.
Load-bearing premise
The two auxiliary tasks supply complementary guidance that improves reasoning about sentiment from context, and task-conditioned routing plus a task-separated routing objective will reduce interference among the objectives.
What would settle it
An ablation that removes the task-separated routing objective or drops one or both auxiliary tasks and measures whether accuracy on the implicit sentiment subset stops improving or declines.
Figures


read the original abstract
Implicit sentiment analysis is challenging because sentiment toward an aspect is often inferred from events rather than expressed through explicit opinion words. Existing models typically learn from the final polarity label, which provides limited guidance for reasoning about sentiment from the context. Motivated by cognitive appraisal theory, we propose an appraisal-aware multi-task learning (MTL) framework for implicit sentiment analysis that provides polarity prediction with two complementary auxiliary tasks: implicit sentiment detection and cognitive rationale generation. However, training several objectives with different targets and sharing a single backbone across tasks in MTL limits flexibility and can lead to task interference. To reduce interference among these related but distinct objectives, we adopt task-level mixture-of-experts models in which all tasks share a common set of experts, and task identity controls the sparse combination of these experts. Our method builds on an encoder-decoder architecture and replaces a subset of encoder and decoder blocks with these sparse mixtures. We use a task-conditioned router to select sparse expert mixtures for each task, and a task-separated routing objective to encourage different tasks to learn distinct expert-selection patterns. Experimental results show that our model outperforms recently proposed approaches, with strong gains on the implicit sentiment subset. Our code is available at https://github.com/yaping166/TRMoE-ISA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Task-Routed Mixture-of-Experts with Cognitive Appraisal for Implicit Sentiment Analysis. It builds an appraisal-aware multi-task learning framework incorporating two auxiliary tasks—implicit sentiment detection and cognitive rationale generation—alongside the main polarity prediction task. To address potential task interference in a shared encoder-decoder backbone, the authors replace select blocks with sparse task-level mixture-of-experts layers controlled by a task-conditioned router and trained with a task-separated routing objective to foster distinct expert selection patterns per task. The paper reports that this model outperforms recently proposed approaches, with particularly strong gains on the implicit sentiment analysis subset.
Significance. If the performance gains are robust and specifically attributable to the task-routed MoE components rather than the auxiliary tasks or other factors, the work could provide a useful technique for managing multiple related objectives in NLP models without interference. The grounding in cognitive appraisal theory adds an interesting interdisciplinary angle to task design for implicit sentiment tasks. Releasing the code is a positive step for reproducibility.
major comments (1)
- [Experimental section] The central claim of strong gains on the implicit-sentiment subset is attributed to the appraisal-aware MTL combined with task-routed MoE that reduces interference via the task-conditioned router and task-separated routing objective. However, the manuscript does not include an ablation that isolates the effect of the task-separated routing objective against a standard multi-task learning baseline with the same auxiliary tasks. Without this, it remains unclear whether the routing machinery is the key driver of improvement or if the gains could be achieved through the auxiliary tasks alone, which is load-bearing for the paper's specific contribution.
minor comments (1)
- [Abstract] The abstract claims 'strong gains' without providing any numerical results or specific baseline names, limiting the reader's ability to immediately gauge the magnitude of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contribution of our task-routed MoE design. We address the major comment below and commit to strengthening the experimental section accordingly.
read point-by-point responses
-
Referee: [Experimental section] The central claim of strong gains on the implicit-sentiment subset is attributed to the appraisal-aware MTL combined with task-routed MoE that reduces interference via the task-conditioned router and task-separated routing objective. However, the manuscript does not include an ablation that isolates the effect of the task-separated routing objective against a standard multi-task learning baseline with the same auxiliary tasks. Without this, it remains unclear whether the routing machinery is the key driver of improvement or if the gains could be achieved through the auxiliary tasks alone, which is load-bearing for the paper's specific contribution.
Authors: We agree that isolating the contribution of the task-separated routing objective is important for substantiating our central claim. Our current ablations compare the full model against variants without the auxiliary tasks and without the MoE layers, but we do not directly contrast the task-separated routing objective against a plain MTL baseline that shares the same auxiliary tasks and backbone. We will add this ablation in the revised version, reporting performance on both the full test set and the implicit-sentiment subset, along with router utilization statistics to show distinct expert selection patterns. This will clarify whether the routing mechanism provides gains beyond the auxiliary tasks alone. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks, not self-referential derivations
full rationale
The paper proposes an appraisal-aware MTL framework augmented with task-routed MoE, using a task-conditioned router and task-separated routing objective to mitigate interference. All performance claims are grounded in experimental comparisons against external baselines on implicit sentiment datasets, with no mathematical derivation, fitted parameter renamed as prediction, or self-citation chain that reduces the central result to its own inputs by construction. The auxiliary tasks and routing design are presented as architectural choices whose value is assessed via ablation-style experiments and outperformance metrics, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cognitive appraisal theory supplies two complementary auxiliary tasks (implicit sentiment detection and cognitive rationale generation) that improve reasoning about sentiment from context.
Reference graph
Works this paper leans on
-
[1]
X. Chen, H. Xie, S. J. Qin, Y . Chai, X. Tao, and F. L. Wang, “Cognitive- inspired deep learning models for aspect-based sentiment analysis: A retrospective overview and bibliometric analysis,”Cogn. Comput., vol. 16, no. 6, pp. 3518–3556, 2024
work page 2024
-
[2]
Z. Li, Y . Zou, C. Zhang, Q. Zhang, and Z. Wei, “Learning implicit sentiment in aspect-based sentiment analysis with supervised contrastive pre-training,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021, pp. 246–256
work page 2021
-
[3]
Relational graph attention network for aspect-based sentiment analysis,
K. Wang, W. Shen, Y . Yang, X. Quan, and R. Wang, “Relational graph attention network for aspect-based sentiment analysis,” inProceedings of the 58th annual meeting of the association for computational linguistics, 2020, pp. 3229–3238
work page 2020
-
[4]
Aspect- based sentiment analysis with explicit sentiment augmentations,
J. Ouyang, Z. Yang, S. Liang, B. Wang, Y . Wang, and X. Li, “Aspect- based sentiment analysis with explicit sentiment augmentations,” in Proceedings of the AAAI conference on artificial intelligence, vol. 38, no. 17, 2024, pp. 18 842–18 850
work page 2024
-
[5]
Reasoning implicit sentiment with chain-of-thought prompting,
H. Fei, B. Li, Q. Liu, L. Bing, F. Li, and T.-S. Chua, “Reasoning implicit sentiment with chain-of-thought prompting,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2023, pp. 1171–1182
work page 2023
-
[6]
Implicit sentiment analysis based on chain of thought prompting,
Z. Duan and J. Wang, “Implicit sentiment analysis based on chain of thought prompting,” arXiv:2211.10986, 2024
-
[7]
G. Yeo, S. Furniturewala, and K. Jaidka, “Beyond text: Leveraging multi- task learning and cognitive appraisal theory for post-purchase intention analysis,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 12 353–12 360
work page 2024
-
[8]
R. S. Lazarus,Emotion and Adaptation. New York: Oxford University Press, 1991
work page 1991
-
[9]
Appraisal considered as a process of multilevel sequen- tial checking,
K. R. Scherer, “Appraisal considered as a process of multilevel sequen- tial checking,” inAppraisal Processes in Emotion: Theory, Methods, Research, K. R. Scherer, A. Schorr, and T. Johnstone, Eds. New York: Oxford University Press, 2001, pp. 92–120
work page 2001
-
[10]
Which tasks should be learned together in multi-task learning?
T. Standley, A. R. Zamir, D. Chen, L. Guibas, J. Malik, and S. Savarese, “Which tasks should be learned together in multi-task learning?” in Proceedings of the 37th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 9120–9132
work page 2020
-
[11]
C. Ding, Z. Lu, S. Wang, R. Cheng, and V . N. Boddeti, “Mitigating task interference in multi-task learning via explicit task routing with non-learnable primitives,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7756–7765
work page 2023
-
[12]
arXiv preprint arXiv:2503.07137 , year=
S. Mu and S. Lin, “A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications,” arXiv:2503.07137, 2025
-
[13]
A survey on mixture of experts in large language models,
W. Cai, J. Jiang, F. Wang, J. Tang, S. Kim, and J. Huang, “A survey on mixture of experts in large language models,”IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[14]
Mod-Squad: Designing mixtures of experts as modular multi- task learners,
Z. Chen, Y . Shen, M. Ding, Z. Chen, H. Zhao, E. G. Learned-Miller, and C. Gan, “Mod-Squad: Designing mixtures of experts as modular multi- task learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 11 828–11 837
work page 2023
-
[15]
Eliciting and understanding cross-task skills with task-level mixture-of-experts,
Q. Ye, J. Zha, and X. Ren, “Eliciting and understanding cross-task skills with task-level mixture-of-experts,” inFindings of the Association for Computational Linguistics: EMNLP 2022. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022, pp. 2567– 2592
work page 2022
-
[16]
C. He, F. Gao, H. Liu, S. Zhu, Y . Jia, H. Zan, and M. Peng, “Task-aware contrastive mixture of experts for quadruple extraction in conversations with code-like replies and non-opinion detection,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (NAA...
work page 2025
-
[17]
Scaling instruction-finetuned language models,
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y . Tay, W. Fedus, Y . Li, X. Wang, M. Dehghani, S. Brahmaet al., “Scaling instruction-finetuned language models,”J. Mach. Learn. Res., vol. 25, no. 70, pp. 1–53, 2024
work page 2024
-
[18]
A contrastive cross-channel data augmentation framework for aspect-based sentiment analysis,
B. Wang, L. Ding, Q. Zhong, X. Li, and D. Tao, “A contrastive cross-channel data augmentation framework for aspect-based sentiment analysis,” inProceedings of the 29th international conference on com- putational linguistics, 2022, pp. 6691–6704
work page 2022
-
[19]
Y . Chai, H. Xie, and S. J. Qin, “Text data augmentation for large language models: a comprehensive survey of methods, challenges, and opportunities,”Artif. Intell. Rev., vol. 59, no. 1, p. 35, 2026
work page 2026
-
[20]
Causal intervention improves implicit sentiment analysis,
S. Wang, J. Zhou, C. Sun, J. Ye, T. Gui, Q. Zhang, and X.-J. Huang, “Causal intervention improves implicit sentiment analysis,” inProceed- ings of the 29th international conference on computational linguistics, 2022, pp. 6966–6977
work page 2022
-
[21]
R. Caruana, “Multitask learning,”Machine learning, vol. 28, no. 1, pp. 41–75, 1997
work page 1997
-
[22]
A. Rietzler, S. Stabinger, P. Opitz, and S. Engl, “Adapt or get left behind: Domain adaptation through bert language model finetuning for aspect- target sentiment classification,” inProceedings of the twelfth language resources and evaluation conference, 2020, pp. 4933–4941
work page 2020
-
[23]
W. Lai, H. Xie, G. Xu, and Q. Li, “Multi-task learning with llms for implicit sentiment analysis: Data-level and task-level automatic weight learning,”IEEE Transactions on Knowledge and Data Engineering, 2025. 8
work page 2025
-
[24]
Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
work page 2022
-
[25]
Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,” inProceedings of the 5th International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[26]
Uni-moe: Scaling unified multimodal llms with mixture of experts,
Y . Li, S. Jiang, B. Hu, L. Wang, W. Zhong, W. Luo, L. Ma, and M. Zhang, “Uni-moe: Scaling unified multimodal llms with mixture of experts,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
work page 2025
-
[27]
Semeval-2014 task 4: Aspect based sentiment analysis,
M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androut- sopoulos, and S. Manandhar, “Semeval-2014 task 4: Aspect based sentiment analysis,” inProceedings of the 8th International Workshop on Semantic Evaluation, SemEval@COLING 2014, Dublin, Ireland, August 23-24, 2014. The Association for Computer Linguistics, 2014, pp. 27– 35
work page 2014
-
[28]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProc. Conf. North Amer. Chapter Assoc. Comput. Linguistics: Human Lang. Technol.Assoc. Comput. Linguistics, 2019, pp. 4171–4186
work page 2019
-
[29]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,” arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Donget al., “Deepseek-v3. 2: Pushing the frontier of open large language models,” arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,” arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Instructabsa: Instruction learning for aspect based sentiment analysis,
K. Scaria, H. Gupta, S. Goyal, S. Sawant, S. Mishra, and C. Baral, “Instructabsa: Instruction learning for aspect based sentiment analysis,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), 2024, pp. 720–736. Yaping Chaiis a Ph.D. cand...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.