Choose Wisely and Privately: Proactive Client Selection for Fair and Efficient Federated Learning
Pith reviewed 2026-05-22 10:06 UTC · model grok-4.3
The pith
Selecting clients proactively with mutual information from private tables yields faster, fairer, and more accurate federated models than uniform or adaptive sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
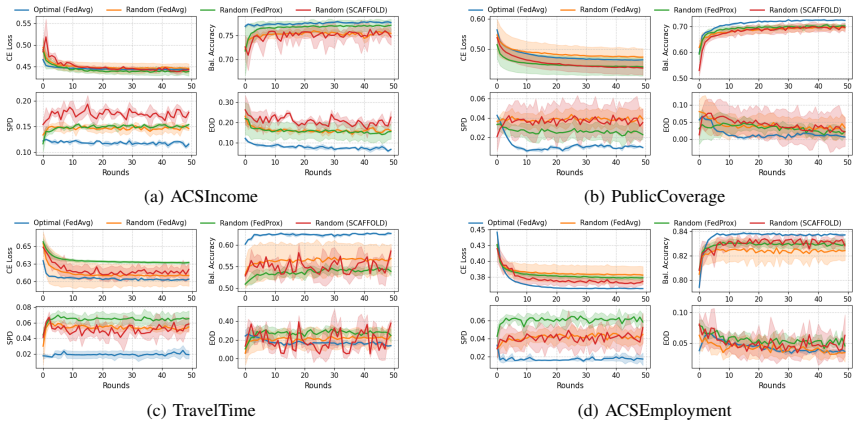
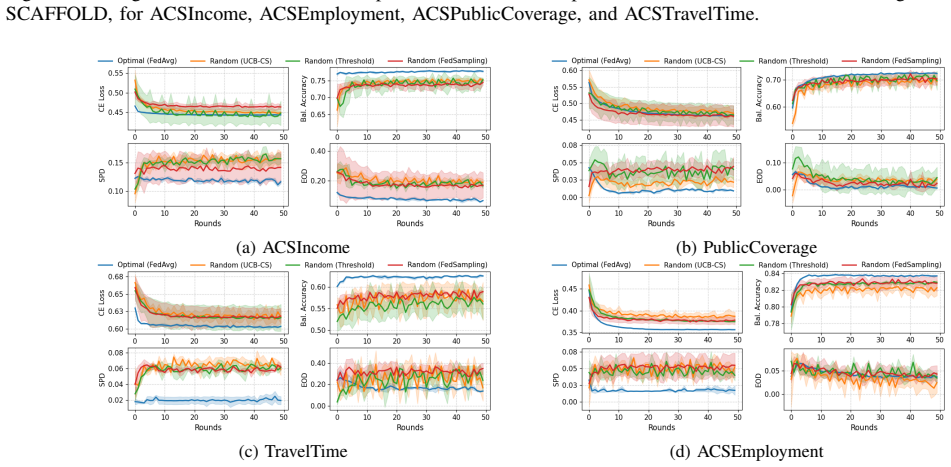
An optimal federation found by minimizing Potential Federation Loss over mutual information from differentially private client statistics produces federated models that train faster, achieve higher final accuracy, and reduce group unfairness compared with uniform or state-of-the-art reactive client sampling.
What carries the argument
The Potential Federation Loss (PFL), a scalar objective that trades off aggregate data utility against cross-feature correlation fairness, optimized by simulated annealing on differentially private contingency tables.
If this is right
- Fewer communication rounds are needed to reach target accuracy because low-utility clients are excluded upfront.
- Total privacy exposure decreases since only the selected clients upload gradients during training.
- Reactive mechanisms that discard or heavily down-weight client contributions become unnecessary.
- Group-level unfairness arising from heterogeneous feature correlations is reduced by explicit fairness terms in the selection objective.
Where Pith is reading between the lines
- The same pre-training selection logic could be applied periodically in long-running federated systems whose data distributions drift.
- Energy and bandwidth savings at edge devices would follow from skipping gradient computations on clients outside the chosen federation.
- The approach might generalize to other collaborative settings that face non-IID data and privacy constraints, such as distributed analytics or multi-party computation.
Load-bearing premise
Mutual information computed from differentially private contingency tables sufficiently captures both collective data utility and cross-feature fairness so that optimizing the Potential Federation Loss produces federations whose downstream models improve performance without excessive noise or search cost.
What would settle it
On the same four benchmarks, training models on the PFL-selected federations yields no statistically significant gains in convergence rounds, test accuracy, or fairness metrics relative to uniform sampling or current adaptive baselines.
Figures







read the original abstract
Federated Learning enables collaborative model training across decentralized data sources without data transfer. Averaging-based FL is limited by the presence of non-IID data, which negatively impacts convergence speed and final model accuracy. Conventional alternatives suffer from significant inefficiency. Clients with noisy or highly heterogeneous data contribute expensive gradient computations that are either discarded or heavily down-weighted before aggregation. These reactive approaches waste computational resources, require more communication rounds and result in unnecessary privacy exposure. In this paper, we propose a proactive client selection framework that aims to find an optimal federation of clients whose combined data match utility and fairness requirements before training begins. Our method relies on mutual information computed from differentially private contingency tables to quantify the relevance of cross-feature correlations in the union dataset. We introduce a Potential Federation Loss (PFL) over the set of fixed-size federations, which balances two objectives. Maximizing collective data utility while ensuring fair cross-features correlations to prevent group unfairness. Client selection is expressed as an optimal subset search problem over the PFL objective, which we solve using simulated annealing under strong differential privacy guarantees for clients' local statistics. Experimental results on four benchmarks show faster, fairer, and more accurate models trained on optimally found federations, compared to uniform sampling, even when state-of-the-art adaptive aggregation or sampling strategies are employed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a proactive client selection framework for federated learning. It computes mutual information from differentially private contingency tables to quantify cross-feature correlations in the union of client data. A Potential Federation Loss (PFL) is introduced to balance collective data utility against fair cross-feature correlations. Client selection is formulated as a fixed-size subset search problem solved via simulated annealing under differential privacy. The central claim is that models trained on the resulting federations converge faster, achieve higher accuracy, and exhibit better fairness than those from uniform sampling or state-of-the-art adaptive aggregation/sampling strategies, as demonstrated on four benchmarks.
Significance. If the empirical results hold, the work would offer a meaningful advance by shifting from reactive client weighting or discarding to proactive, privacy-aware selection that reduces wasted computation and communication while addressing non-IID challenges and group fairness. The introduction of PFL as an explicit utility-fairness objective and the application of simulated annealing to the selection problem under DP guarantees are technically interesting contributions that could influence practical FL system design.
major comments (2)
- [Experimental results and method formulation] The central experimental claim (faster, fairer, more accurate models on four benchmarks) rests on the assumption that mutual information derived from DP contingency tables, when minimized via PFL and simulated annealing, selects federations whose union data genuinely improves downstream performance. However, no analysis is provided on how Laplace or Gaussian noise (controlled by epsilon) affects MI estimates in non-IID or small-client regimes typical of FL benchmarks; moderate privacy budgets can flatten correlations and produce noisy or unrepresentative selections whose reported gains may be illusory.
- [Abstract and experimental evaluation] The abstract states improvements even against SOTA adaptive aggregation or sampling strategies, yet provides no details on experimental setup, exact baselines, statistical significance testing, federation size k, privacy budget epsilon values, or how PFL is precisely formulated and optimized. This absence makes it impossible to verify whether the gains are robust or load-bearing for the proactive-selection thesis.
minor comments (2)
- [Method] Notation for the PFL objective and the contingency-table construction should be introduced with explicit equations early in the method section to improve readability.
- [Experimental results] The paper should clarify whether the four benchmarks are standard FL datasets (e.g., CIFAR-10, FEMNIST) and report client counts, data heterogeneity measures, and number of independent runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of our proactive client selection framework. We address each major comment below, clarifying aspects of our method and experiments while outlining targeted revisions to improve clarity, robustness, and reproducibility.
read point-by-point responses
-
Referee: [Experimental results and method formulation] The central experimental claim (faster, fairer, more accurate models on four benchmarks) rests on the assumption that mutual information derived from DP contingency tables, when minimized via PFL and simulated annealing, selects federations whose union data genuinely improves downstream performance. However, no analysis is provided on how Laplace or Gaussian noise (controlled by epsilon) affects MI estimates in non-IID or small-client regimes typical of FL benchmarks; moderate privacy budgets can flatten correlations and produce noisy or unrepresentative selections whose reported gains may be illusory.
Authors: We agree that a dedicated sensitivity analysis of the impact of differential privacy noise on mutual information estimates would strengthen the empirical claims, particularly for non-IID distributions and smaller client pools. Our current results already evaluate performance across a range of privacy budgets, but we did not include an explicit breakdown of how noise perturbs the contingency tables and resulting MI values. In the revised manuscript we will add new experiments that (i) vary epsilon over a fine-grained grid, (ii) quantify the deviation between noisy and non-private MI estimates, and (iii) report the stability of the selected client sets and downstream accuracy under these conditions. This will directly address whether moderate privacy budgets produce unrepresentative selections. revision: yes
-
Referee: [Abstract and experimental evaluation] The abstract states improvements even against SOTA adaptive aggregation or sampling strategies, yet provides no details on experimental setup, exact baselines, statistical significance testing, federation size k, privacy budget epsilon values, or how PFL is precisely formulated and optimized. This absence makes it impossible to verify whether the gains are robust or load-bearing for the proactive-selection thesis.
Authors: The full experimental protocol—including federation size k, concrete epsilon values, the exact mathematical formulation and simulated-annealing optimization of PFL, the complete list of baselines with citations, and the statistical testing procedure—is presented in Sections 4 (Experimental Setup) and 5 (Results). Nevertheless, we acknowledge that the abstract is too high-level for immediate verification. We will revise the abstract to mention key parameter ranges and will add a concise experimental-configuration table plus explicit reporting of statistical significance (paired t-tests or Wilcoxon signed-rank tests with p-values) to the results section. These changes will make the reproducibility information readily accessible without altering the manuscript’s core claims. revision: partial
Circularity Check
No significant circularity; PFL defined independently as new objective
full rationale
The paper introduces Potential Federation Loss (PFL) explicitly as a novel objective that balances collective data utility (via mutual information on DP contingency tables) against cross-feature fairness. Client selection is framed as a standard combinatorial optimization problem solved by simulated annealing under DP guarantees. Experimental claims rest on benchmark comparisons to external baselines (uniform sampling, adaptive aggregation), not on any reduction of outputs to fitted inputs or self-referential definitions by construction. No load-bearing derivation step collapses to tautology or prior self-citation chains; the method is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- federation size k
- privacy budget epsilon
axioms (1)
- domain assumption Mutual information from cross-feature correlations in the union dataset quantifies relevance for utility and fairness
invented entities (1)
-
Potential Federation Loss (PFL)
no independent evidence
Lean theorems connected to this paper
-
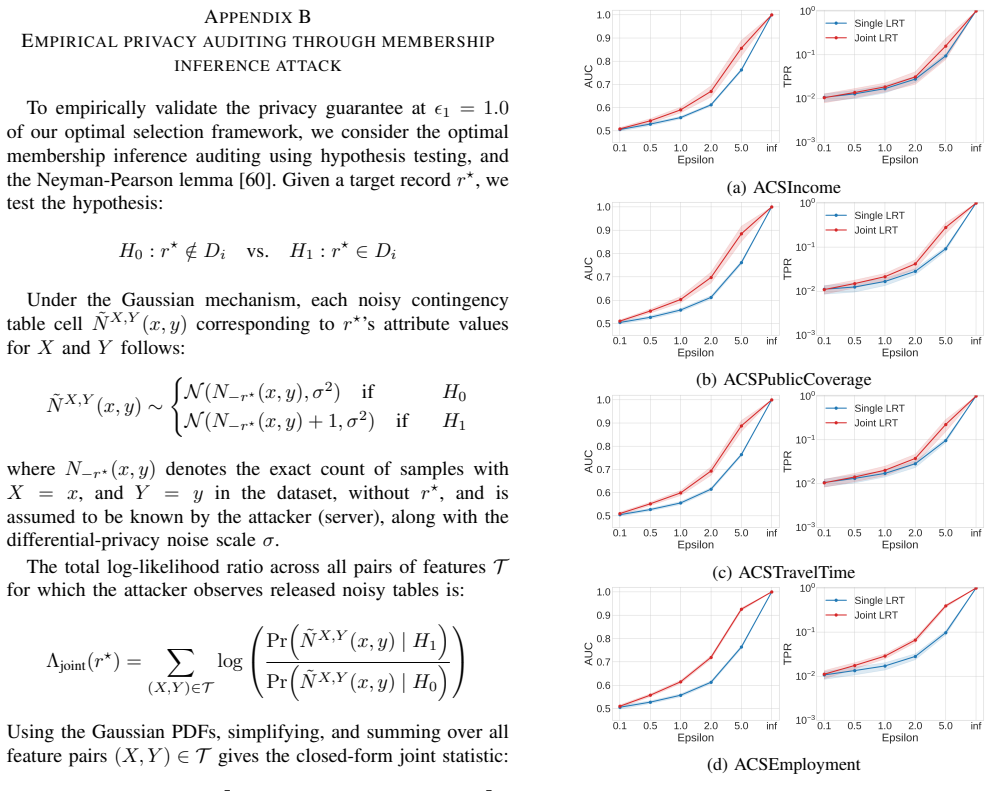
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PFL(W) = α·I_W(S,T) + β Σ I_W(S,Nk) + γ Σ I_W(Nk,Nj) − λ Σ I_W(Nk,T)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. Pmlr, 2017, pp. 1273– 1282
work page 2017
-
[2]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, R. G. L. D’Oliveira, H. Eichner, S. E. Rouayheb, D. Evans, J. Gardner, Z. Garrett, A. Gasc ´on, B. Ghazi, P. B. Gibbons, M. Gruteser, Z. Harchaoui, C. He, L. He, Z. Huo, B. Hutchinson, J. Hsu, M. Jaggi, T. Javidi, G. Joshi, M. Khodak...
-
[3]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” 2020. [Online]. Available: https://arxiv.org/abs/1812.06127
-
[4]
Tackling the objective inconsistency problem in heterogeneous federated optimization,
J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V . Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” 2020. [Online]. Available: https://arxiv.org/abs/2007. 07481
work page 2020
-
[6]
Bias propagation in federated learning,
H. Chang and R. Shokri, “Bias propagation in federated learning,”arXiv preprint arXiv:2309.02160, 2023
-
[7]
Federated learning with partial model personalization,
K. Pillutla, K. Malik, A.-R. Mohamed, M. Rabbat, M. Sanjabi, and L. Xiao, “Federated learning with partial model personalization,” in Proceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, Eds., vol
-
[8]
PMLR, 17–23 Jul 2022, pp. 17 716–17 758. [Online]. Available: https://proceedings.mlr.press/v162/pillutla22a.html
work page 2022
-
[9]
Machine learning with adversaries: Byzantine tolerant gradient descent,
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Machine learning with adversaries: Byzantine tolerant gradient descent,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://p...
work page 2017
-
[10]
Fairfed: Enabling group fairness in federated learning,
Y . H. Ezzeldin, S. Yan, C. He, E. Ferrara, and A. S. Avestimehr, “Fairfed: Enabling group fairness in federated learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 6, 2023, pp. 7494– 7502
work page 2023
-
[11]
Fade: Federated aggregation with discrim- ination elimination,
A.-A. Bendoukha, H. H. Arcolezi, N. Kaaniche, A. Boudguiga, R. Sirdey, and P.-E. Clet, “Fade: Federated aggregation with discrim- ination elimination,” inProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, ser. FAccT ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 3182–3195
work page 2025
-
[12]
Improving fairness via federated learning,
Y . Zeng, H. Chen, and K. Lee, “Improving fairness via federated learning,”arXiv preprint arXiv:2110.15545, 2021
-
[13]
Sok: On gradient leakage in federated learning,
J. Du, J. Hu, Z. Wang, P. Sun, N. Z. Gong, K. Ren, and C. Chen, “Sok: On gradient leakage in federated learning,”arXiv preprint arXiv:2404.05403, 2024
-
[14]
Exploiting unintended feature leakage in collaborative learning,
L. Melis, C. Song, E. De Cristofaro, and V . Shmatikov, “Exploiting unintended feature leakage in collaborative learning,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 691–706
work page 2019
-
[15]
A survey of privacy attacks in machine learning,
M. Rigaki and S. Garcia, “A survey of privacy attacks in machine learning,”ACM Computing Surveys, vol. 56, no. 4, p. 1–34, Nov. 2023. [Online]. Available: http://dx.doi.org/10.1145/3624010
-
[16]
Poseidon: Privacy-preserving federated neural network learning,
S. Sav, A. Pyrgelis, J. R. Troncoso-Pastoriza, D. Froelicher, J.-P. Bossuat, J. S. Sousa, and J.-P. Hubaux, “Poseidon: Privacy-preserving federated neural network learning,”arXiv preprint arXiv:2009.00349, 2020
-
[17]
Towards practical homomorphic aggregation in byzantine- resilient distributed learning,
A. Choffrut, R. Guerraoui, R. Pinot, R. Sirdey, J. Stephan, and M. Zuber, “Towards practical homomorphic aggregation in byzantine- resilient distributed learning,” inProceedings of the 25th International Middleware Conference, ser. Middleware ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 431–444. [Online]. Available: https://doi.o...
-
[18]
Towards privacy-preserving and fairness-aware federated learning framework,
A.-A. Bendoukha, D. Demirag, N. Kaaniche, A. Boudguiga, R. Sirdey, and S. Gambs, “Towards privacy-preserving and fairness-aware federated learning framework,” inPETs 2025 : Privacy Enhancing Technologies, vol. 2025, no. 1, Washinghton, DC, United States, Jul. 2025, pp. 845–865. [Online]. Available: https://hal.science/hal-04782394
work page 2025
-
[19]
A.-A. Bendoukha, R. Sirdey, A. Boudguiga, and N. Kaaniche, “Un- veiling the (in)security of threshold fhe-based federated learning: The practical impact of recent cpad attacks,” in2025 IEEE 38th Computer Security Foundations Symposium (CSF), 2025, pp. 425–440
work page 2025
-
[20]
Practical Secure Aggregation for Federated Learning on User-Held Data
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMa- han, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for federated learning on user-held data,”arXiv preprint arXiv:1611.04482, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
An introduction to variable and feature selection,
I. Guyon and A. Elisseeff, “An introduction to variable and feature selection,”J. Mach. Learn. Res., vol. 3, no. null, p. 1157–1182, Mar. 2003
work page 2003
-
[22]
Data-centric artificial intelligence: A survey,
D. Zha, Z. P. Bhat, K.-H. Lai, F. Yang, Z. Jiang, S. Zhong, and X. Hu, “Data-centric artificial intelligence: A survey,”ACM Computing Surveys, vol. 57, no. 5, pp. 1–42, 2025
work page 2025
-
[23]
Unbiased look at dataset bias,
A. Torralba and A. A. Efros, “Unbiased look at dataset bias,” inCVPR 2011, 2011, pp. 1521–1528
work page 2011
-
[24]
Using mutual information for selecting features in supervised neural net learning,
R. Battiti, “Using mutual information for selecting features in supervised neural net learning,”IEEE Transactions on Neural Networks, vol. 5, no. 4, pp. 537–550, 1994
work page 1994
-
[26]
Fast binary feature selection with conditional mutual infor- mation,
F. Fleuret, “Fast binary feature selection with conditional mutual infor- mation,”J. Mach. Learn. Res., vol. 5, p. 1531–1555, Dec. 2004
work page 2004
-
[27]
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel, “Fairness through awareness,” inProceedings of the 3rd innovations in theoretical computer science conference, 2012, pp. 214–226
work page 2012
-
[28]
Equality of opportunity in supervised learning,
M. Hardt, E. Price, and N. Srebro, “Equality of opportunity in supervised learning,”Advances in neural information processing systems, vol. 29, 2016
work page 2016
-
[29]
Retiring adult: New datasets for fair machine learning,
F. Ding, M. Hardt, J. Miller, and L. Schmidt, “Retiring adult: New datasets for fair machine learning,”Advances in neural information processing systems, vol. 34, pp. 6478–6490, 2021
work page 2021
-
[30]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inAISTATS, 2017
work page 2017
-
[31]
Calibrating noise to sensitivity in private data analysis,
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to sensitivity in private data analysis,” inTheory of cryptography conference. Springer, 2006, pp. 265–284
work page 2006
-
[32]
The algorithmic foundations of differential privacy,
C. Dwork, A. Rothet al., “The algorithmic foundations of differential privacy,”Foundations and Trends® in Theoretical Computer Science, vol. 9, no. 3–4, pp. 211–407, 2014
work page 2014
-
[33]
I. Mironov, “R ´enyi differential privacy,” in2017 IEEE 30th Computer Security Foundations Symposium (CSF). IEEE, Aug. 2017, p. 263–275. [Online]. Available: http://dx.doi.org/10.1109/CSF.2017.11
-
[34]
Bandit-based communication-efficient client selection strategies for federated learn- ing,
Y . Jee Cho, S. Gupta, G. Joshi, and O. Ya ˘gan, “Bandit-based communication-efficient client selection strategies for federated learn- ing,” in2020 54th Asilomar Conference on Signals, Systems, and Computers, 2020, pp. 1066–1069. 14
work page 2020
-
[35]
Fedsampling: a better sampling strategy for federated learning,
T. Qi, F. Wu, L. Lyu, Y . Huang, and X. Xie, “Fedsampling: a better sampling strategy for federated learning,” inProceedings of the Thirty- Second International Joint Conference on Artificial Intelligence, ser. IJCAI ’23, 2023
work page 2023
-
[36]
Federated Learning with Non-IID Data
Y . Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V . Chandra, “Federated learning with non-iid data,”arXiv preprint arXiv:1806.00582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Y . J. Cho, J. Wang, and G. Joshi, “Client selection in federated learning: Convergence analysis and power-of-choice selection strategies,” inarXiv preprint arXiv:2010.01243, 2020
-
[38]
Communication-efficient federated learning via optimal client sampling,
M. Ribero and H. Vikalo, “Communication-efficient federated learning via optimal client sampling,”arXiv preprint arXiv:2007.15197, 2020
-
[39]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 5132–5143
work page 2020
-
[40]
Fairbatch: Batch selection for model fairness,
Y . Roh, K. Lee, S. E. Whang, and C. Suh, “Fairbatch: Batch selection for model fairness,”arXiv preprint arXiv:2012.01696, 2020
-
[41]
Data shapley: Equitable valuation of data for machine learning,
A. Ghorbani and J. Zou, “Data shapley: Equitable valuation of data for machine learning,” inInternational conference on machine learning. PMLR, 2019, pp. 2242–2251
work page 2019
-
[42]
Towards efficient data valuation based on the shapley value,
R. Jia, D. Dao, B. Wang, F. A. Hubis, N. Hynes, N. M. G ¨urel, B. Li, C. Zhang, D. Song, and C. J. Spanos, “Towards efficient data valuation based on the shapley value,” inThe 22nd international conference on artificial intelligence and statistics. PMLR, 2019, pp. 1167–1176
work page 2019
-
[43]
Beta shapley: a unified and noise-reduced data valuation framework for machine learning,
Y . Kwon and J. Zou, “Beta shapley: a unified and noise-reduced data valuation framework for machine learning,”arXiv preprint arXiv:2110.14049, 2021
-
[44]
Data valuation and detections in federated learning,
W. Li, S. Fu, F. Zhang, and Y . Pang, “Data valuation and detections in federated learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 12 027–12 036
work page 2024
-
[45]
Class-aware sample reweighting optimal transport for multi-source domain adaptation,
S. Wang, B. Wang, Z. Zhang, A. A. Heidari, and H. Chen, “Class-aware sample reweighting optimal transport for multi-source domain adaptation,”Neurocomputing, vol. 523, pp. 213–223, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0925231222015545
work page 2023
-
[46]
Lava: Data valuation without pre-specified learning algorithms,
H. A. Just, F. Kang, J. T. Wang, Y . Zeng, M. Ko, M. Jin, and R. Jia, “Lava: Data valuation without pre-specified learning algorithms,”arXiv preprint arXiv:2305.00054, 2023
-
[47]
Gradient driven rewards to guarantee fairness in collaborative machine learning,
X. Xu, L. Lyu, X. Ma, C. Miao, C. S. Foo, and B. K. H. Low, “Gradient driven rewards to guarantee fairness in collaborative machine learning,” inAdvances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 16 104– 16 117. [Online]. Available: http...
work page 2021
-
[48]
H. Peng, F. Long, and C. Ding, “Feature selection based on mu- tual information criteria of max-dependency, max-relevance, and min- redundancy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 8, pp. 1226–1238, 2005
work page 2005
-
[49]
R. Storn and K. Price, “Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces,”J. of Global Optimization, vol. 11, no. 4, p. 341–359, Dec. 1997. [Online]. Available: https://doi.org/10.1023/A:1008202821328
-
[50]
E. Aarts and J. Korst,Simulated annealing and Boltzmann machines. John Wiley & Sons, 1989
work page 1989
-
[51]
Stochastic relaxation, gibbs distributions, and the bayesian restoration of images,
S. Geman and D. Geman, “Stochastic relaxation, gibbs distributions, and the bayesian restoration of images,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 6, no. 6, pp. 721–741, 1984
work page 1984
-
[52]
Cooling schedules for optimal annealing,
B. Hajek, “Cooling schedules for optimal annealing,”Mathematics of Operations Research, vol. 13, no. 2, pp. 311–329, 1988
work page 1988
-
[53]
Optimization by simulated annealing,
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi, “Optimization by simulated annealing,”Science, vol. 220, no. 4598, pp. 671–680, 1983
work page 1983
-
[54]
The theory and practice of simulated annealing,
D. Henderson, S. H. Jacobson, and A. W. Johnson, “The theory and practice of simulated annealing,” inHandbook of metaheuristics. Springer, 2003, pp. 287–319
work page 2003
-
[55]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS’16. ACM, Oct. 2016
work page 2016
-
[56]
N. Homer, S. Szelinger, M. Redman, D. Duggan, W. Tembe, J. Muehling, J. Pearson, D. Stephan, S. Nelson, and D. Craig, “Resolving individuals contributing trace amounts of dna to highly complex mix- tures using high-density snp genotyping microarrays,”PLoS genetics, vol. 4, p. e1000167, 09 2008
work page 2008
-
[57]
Differential privacy and the risk-utility tradeoff for multi-dimensional contingency tables,
S. E. Fienberg, A. Rinaldo, and X. Yang, “Differential privacy and the risk-utility tradeoff for multi-dimensional contingency tables,” inPrivacy in Statistical Databases, J. Domingo-Ferrer and E. Magkos, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 187–199
work page 2010
-
[58]
Structure and sensitivity in differential privacy: Comparing k-norm mechanisms,
J. Awan and A. Slavkovi ´c, “Structure and sensitivity in differential privacy: Comparing k-norm mechanisms,”Journal of the American Statistical Association, vol. 116, no. 534, pp. 935–954, 2021
work page 2021
-
[59]
Parallel simulated annealing techniques,
D. R. Greening, “Parallel simulated annealing techniques,”Physica D: Nonlinear Phenomena, vol. 42, no. 1, pp. 293–306, 1990. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ 0167278990900843
work page 1990
-
[60]
Clusterfl: a similarity-aware federated learning system for human activity recogni- tion,
X. Ouyang, Z. Xie, J. Zhou, J. Huang, and G. Xing, “Clusterfl: a similarity-aware federated learning system for human activity recogni- tion,” inProceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services, ser. MobiSys ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 54–66
work page 2021
-
[61]
On the problem of the most efficient tests of statistical hypotheses,
J. Neyman and E. S. Pearson, “On the problem of the most efficient tests of statistical hypotheses,”Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, vol. 231, pp. 289–337, 1933. [Online]. Available: http://www.jstor.org/stable/91247 APPENDIXA GROUP FAIRNESS METRICS Group fairne...
work page 1933
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.