APM: Evaluating Style Personalization in LLMs with Arbitrary Preference Mappings
Pith reviewed 2026-05-21 05:11 UTC · model grok-4.3
The pith
The APM benchmark shows routing as the most reliable way to adapt LLMs to users' unspoken style preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
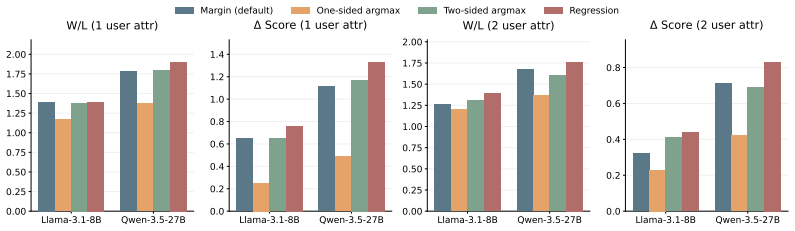
The paper claims that by decoupling user attributes from response principles through a randomized mapping C with no semantic content, the APM benchmark forces models to perform genuine inference from history. Under this methodology, routing personalization emerges as the most reliable adapted method, retrieval-augmented generation improves only with stronger base models, and soft prompt optimization fails to exceed non-personalized baselines, indicating that effective style personalization remains challenging but achievable with appropriate techniques.
What carries the argument
The hidden randomized mapping C in the Arbitrary Preference Mapping (APM) benchmark, which assigns user attributes to response trait preferences without carrying semantic meaning, thereby requiring inference solely from conversation context.
Load-bearing premise
The hidden randomized mapping C truly prevents models from exploiting stereotypical associations and forces genuine inference from conversation history rather than pattern matching on user attributes.
What would settle it
If a model achieves strong personalization scores even after the mapping C is revealed to it or when conversation history is withheld, this would show that the benchmark does not fully require inference from history.
Figures




read the original abstract
Typical LLM responses tend to follow a default style, even though users often have distinct preferences regarding tone, verbosity, and formality that they do not explicitly state in their prompts. Evaluating whether personalization methods can adapt to these implicit preferences is challenging, since users typically provide prompts rather than reference responses, style preferences are not factually verifiable, and reference-free LLM judges may conflate personalization with general response quality. To address these challenges, we introduce the Arbitrary Preference Mapping (APM) benchmark, which decouples user attributes (e.g. enthusiastic) from response principles (e.g. persuasive) via a hidden, randomized mapping $\mathbf{C}$ that maps user attributes to preferences about response traits. Because $\mathbf{C}$ carries no semantic content and is resampled across runs, models cannot exploit stereotypical associations and must infer preferences from conversation history. Using this unbiased evaluation methodology, we adapt retrieval-augmented, prompt-optimization, and routing personalization methods and evaluate them on Llama-3.1-8B and Qwen-3.5-27B. Our results show that routing is the most reliable approach, while RAG only improves with the stronger base LLM, and soft prompt optimization fails to improve significantly over a non-personalized baseline. Our extensive evaluation reveals that in this realistic setting, personalization remains challenging, but our adapted methods show promise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Arbitrary Preference Mapping (APM) benchmark to evaluate implicit style personalization in LLMs. It decouples user attributes (e.g., enthusiastic) from response principles (e.g., persuasive) via a hidden randomized mapping C that carries no semantic content and is resampled across runs, forcing models to infer preferences from conversation history rather than stereotypical associations. The authors adapt retrieval-augmented generation, soft prompt optimization, and routing methods, then evaluate them on Llama-3.1-8B and Qwen-3.5-27B, reporting that routing is the most reliable approach, RAG improves only with the stronger base model, and soft prompt optimization fails to outperform a non-personalized baseline.
Significance. If the APM construction holds and truly isolates inference to conversation history, the benchmark addresses a genuine gap in evaluating personalization without reference responses or biased LLM judges. The comparative findings across methods and model scales would offer practical guidance for deployment. The randomized mapping approach is a creative strength that enables controlled, falsifiable testing of whether personalization methods can adapt to implicit preferences.
major comments (2)
- [Abstract / APM benchmark] Abstract and APM benchmark description: the central claim that C 'carries no semantic content and is resampled' prevents models from exploiting stereotypical associations or recovering the mapping from attribute names rests on an unverified assumption. No quantitative check, ablation, or analysis is provided showing that the evaluated LLMs (Llama-3.1-8B, Qwen-3.5-27B) cannot approximate C via meta-reasoning or partial history correlations; this directly undermines the 'unbiased' status of the reported performance differences.
- [Evaluation and results] Results on method comparisons: the headline conclusions (routing most reliable; RAG helps only stronger models; soft prompt optimization no better than baseline) are load-bearing on the validity of the C isolation. Without evidence that the hidden mapping blocks pattern matching on user attributes, the relative rankings cannot be interpreted as evidence of genuine personalization capability.
minor comments (2)
- [Abstract] The abstract would benefit from explicit mention of the number of resampled C realizations, conversation lengths, and any statistical tests used to support the 'fails to improve significantly' claim.
- [Method] Notation for the mapping matrix C and its resampling procedure could be illustrated with a small concrete example to improve clarity for readers unfamiliar with the construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the APM benchmark to address challenges in evaluating implicit style personalization without reference responses or biased judges. We address the two major comments below regarding the validity of the hidden mapping C. We agree that additional verification would strengthen the claims and will incorporate the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / APM benchmark] Abstract and APM benchmark description: the central claim that C 'carries no semantic content and is resampled' prevents models from exploiting stereotypical associations or recovering the mapping from attribute names rests on an unverified assumption. No quantitative check, ablation, or analysis is provided showing that the evaluated LLMs (Llama-3.1-8B, Qwen-3.5-27B) cannot approximate C via meta-reasoning or partial history correlations; this directly undermines the 'unbiased' status of the reported performance differences.
Authors: We agree that the manuscript would benefit from a quantitative check confirming that the evaluated LLMs cannot reliably approximate or recover C through meta-reasoning or correlations in partial histories. The current design relies on C being a randomly generated mapping with no semantic content between user attributes and response principles, resampled independently for each run, which prevents exploitation of fixed stereotypes or attribute-name associations. To directly address this concern, we will add an ablation analysis in the revised manuscript that tests model performance when predicting preferences using only attribute names or truncated histories, quantifying any potential leakage or pattern matching. revision: yes
-
Referee: [Evaluation and results] Results on method comparisons: the headline conclusions (routing most reliable; RAG helps only stronger models; soft prompt optimization no better than baseline) are load-bearing on the validity of the C isolation. Without evidence that the hidden mapping blocks pattern matching on user attributes, the relative rankings cannot be interpreted as evidence of genuine personalization capability.
Authors: We acknowledge that the comparative results and conclusions depend on the effectiveness of C in isolating inference to conversation history. As outlined in our response to the first comment, the added ablation will provide evidence that models do not achieve meaningful gains from attribute-based pattern matching alone. With this addition, the observed differences—such as routing being the most reliable method, RAG benefiting only the stronger base model, and soft prompt optimization not outperforming the baseline—can be more confidently interpreted as reflecting genuine personalization capabilities rather than exploitation of the mapping structure. revision: yes
Circularity Check
APM benchmark and results are self-contained with no reduction to inputs by construction
full rationale
The paper defines the APM benchmark via an externally specified hidden randomized mapping C that carries no semantic content and is resampled across runs, which by design forces inference from conversation history rather than attribute stereotypes. This methodological choice is stated directly in the abstract and does not rely on any fitted parameters, self-referential predictions, or load-bearing self-citations within the provided text. The reported results (routing most reliable, RAG benefits only stronger models, soft prompts no better than baseline) are empirical evaluations of adapted methods on Llama-3.1-8B and Qwen-3.5-27B, not quantities that reduce to the benchmark definition itself. No equations, uniqueness theorems, or ansatzes from prior self-work are invoked to force the central claims. The evaluation framework therefore remains independent and falsifiable outside the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomized hidden mapping C prevents exploitation of stereotypical associations between user attributes and response styles.
invented entities (1)
-
Arbitrary Preference Mapping C
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Persobench: Benchmarking personalized response generation in large language models
Saleh Afzoon, Zahra Jamali, Usman Naseem, and Amin Beheshti. Persobench: Benchmarking personalized response generation in large language models. InarXiv, 2024
work page 2024
-
[2]
gpt-oss-120b & gpt-oss-20b model card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. InarXiv, 2025
work page 2025
-
[3]
Aligning llms by predicting preferences from user writing samples
Stéphane Aroca-Ouellette, Natalie Mackraz, Barry-John Theobald, and Katherine Metcalf. Aligning llms by predicting preferences from user writing samples. InICML, 2025
work page 2025
-
[4]
Training a helpful and harmless assistant with reinforcement learning from human feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. InarXiv, 2022
work page 2022
-
[5]
Nvidia nemotron 3: Efficient and open intelligence
Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, et al. Nvidia nemotron 3: Efficient and open intelligence. InarXiv, 2025
work page 2025
-
[6]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. InACL (Findings), 2024
work page 2024
-
[7]
ULTRAFEEDBACK: Boosting language models with scaled AI feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. ULTRAFEEDBACK: Boosting language models with scaled AI feedback. InICML, 2024
work page 2024
-
[8]
Yuhao Dan, Jie Zhou, Qin Chen, Junfeng Tian, and Liang He. P-react: Synthesizing topic- adaptive reactions of personality traits via mixture of specialized lora experts. InACL (Findings), 2025
work page 2025
-
[9]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. InEMNLP, 2023
work page 2023
-
[10]
Pref: Reference-free evaluation of personalised text generation in llms
Xiao Fu, Hossein A Rahmani, Bin Wu, Jerome Ramos, Emine Yilmaz, and Aldo Lipani. Pref: Reference-free evaluation of personalised text generation in llms. InarXiv, 2025
work page 2025
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. InarXiv, 2024
work page 2024
-
[12]
Persoma: Personalized soft prompt adapter architecture for personalized language prompting
Liam Hebert, Krishna Sayana, Ambarish Jash, Alexandros Karatzoglou, Sukhdeep Sodhi, Sumanth Doddapaneni, Yanli Cai, and Dima Kuzmin. Persoma: Personalized soft prompt adapter architecture for personalized language prompting. InarXiv, 2024
work page 2024
-
[13]
A rationale and test for the number of factors in factor analysis
John L Horn. A rationale and test for the number of factors in factor analysis. InPsychometrika, 1965. 10
work page 1965
-
[14]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale. InCOLM, 2025
work page 2025
-
[15]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards personalized intelligence via learning implicit user personas and agentic memory. InarXiv, 2025
work page 2025
-
[16]
The varimax criterion for analytic rotation in factor analysis
Henry F Kaiser. The varimax criterion for analytic rotation in factor analysis. InPsychometrika, 1958
work page 1958
-
[17]
Drift: Decoding-time personalized alignments with implicit user preferences
Minbeom Kim, Kang-il Lee, Seongho Joo, Hwaran Lee, Thibaut Thonet, and Kyomin Jung. Drift: Decoding-time personalized alignments with implicit user preferences. InEMNLP (Findings), 2025
work page 2025
-
[18]
Longlamp: A benchmark for personalized long-form text generation
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A Rossi, Franck Der- noncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, et al. Longlamp: A benchmark for personalized long-form text generation. InarXiv, 2024
work page 2024
-
[19]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InEMNLP, 2021
work page 2021
-
[20]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. InNeurIPS, 2020
work page 2020
-
[21]
A personalized conversational benchmark: Towards simulating personalized conversations
Li Li, Peilin Cai, Ryan A Rossi, Franck Dernoncourt, Branislav Kveton, Junda Wu, Tong Yu, Linxin Song, Tiankai Yang, Yuehan Qin, et al. A personalized conversational benchmark: Towards simulating personalized conversations. InarXiv, 2025
work page 2025
-
[22]
Personalized reasoning: Just-in-time personalization and why llms fail at it
Shuyue Stella Li, Avinandan Bose, Faeze Brahman, Simon Shaolei Du, Pang Wei Koh, Maryam Fazel, and Yulia Tsvetkov. Personalized reasoning: Just-in-time personalization and why llms fail at it. InarXiv, 2025
work page 2025
-
[23]
A survey of personalization: From rag to agent
Xiaopeng Li, Pengyue Jia, Derong Xu, Yi Wen, Yingyi Zhang, Wenlin Zhang, Wanyu Wang, Yichao Wang, Zhaocheng Du, Xiangyang Li, et al. A survey of personalization: From rag to agent. InACM Transactions on Information Systems, 2025
work page 2025
-
[24]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InACL, 2022
work page 2022
-
[25]
Llms+ persona-plug= personalized llms
Jiongnan Liu, Yutao Zhu, Shuting Wang, Xiaochi Wei, Erxue Min, Yu Lu, Shuaiqiang Wang, Dawei Yin, and Zhicheng Dou. Llms+ persona-plug= personalized llms. InACL, 2025
work page 2025
-
[26]
Nemotron-Personas-USA: Synthetic personas aligned to real-world distributions, June 2025
Yev Meyer and Dane Corneil. Nemotron-Personas-USA: Synthetic personas aligned to real-world distributions, June 2025. URL https://huggingface.co/datasets/nvidia/ Nemotron-Personas-USA
work page 2025
-
[27]
Learning to route among specialized experts for zero-shot generalization
Mohammed Muqeeth, Haokun Liu, Yufan Liu, and Colin Raffel. Learning to route among specialized experts for zero-shot generalization. InICML, 2024
work page 2024
-
[28]
Pearl: Personalizing large language model writing assistants with generation-calibrated retrievers
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Bahareh Sarrafzadeh, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, and Tara Safavi. Pearl: Personalizing large language model writing assistants with generation-calibrated retrievers. In EMNLP Workshop on Customizable NLP (CustomNLP4U), 2024
work page 2024
-
[29]
User-llm: Efficient llm contextualization with user embeddings
Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O’Banion, and Jun Xie. User-llm: Efficient llm contextualization with user embeddings. InACM Web Conference (WWW), 2025
work page 2025
-
[30]
Benchmarking and improving llm robustness for personalized generation
Chimaobi Okite, Naihao Deng, Kiran Bodipati, Huaidian Hou, Joyce Chai, and Rada Mihalcea. Benchmarking and improving llm robustness for personalized generation. InEMNLP (Findings), 2025. 11
work page 2025
-
[31]
Samuel J. Paech. Judgemark v2.1, 2025. URL https://github.com/EQ-bench/ Judgemark-v2
work page 2025
-
[32]
Bbq: A hand-built bias benchmark for question answering
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thomp- son, Phu Mon Htut, and Samuel Bowman. Bbq: A hand-built bias benchmark for question answering. InACL (Findings), 2022
work page 2022
-
[33]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
work page 2026
-
[34]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023
work page 2023
-
[35]
Integrating summarization and retrieval for enhanced personalization via large language models
Chris Richardson, Yao Zhang, Kellen Gillespie, Sudipta Kar, Arshdeep Singh, Zeynab Raeesy, Omar Zia Khan, and Abhinav Sethy. Integrating summarization and retrieval for enhanced personalization via large language models. InarXiv, 2023
work page 2023
-
[36]
Optimization methods for personalizing large language models through retrieval augmentation
Alireza Salemi, Surya Kallumadi, and Hamed Zamani. Optimization methods for personalizing large language models through retrieval augmentation. InSIGIR, 2024
work page 2024
-
[37]
Lamp: When large language models meet personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. Lamp: When large language models meet personalization. InACL, 2024
work page 2024
-
[38]
Expert: Effective and explainable evaluation of personalized long-form text generation
Alireza Salemi, Julian Killingback, and Hamed Zamani. Expert: Effective and explainable evaluation of personalized long-form text generation. InACL (Findings), pages 17516–17532, 2025
work page 2025
-
[39]
Judgebench: A benchmark for evaluating llm-based judges
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Y Tang, Alejandro Cuadron, Chenguang Wang, Raluca Ada Popa, and Ion Stoica. Judgebench: A benchmark for evaluating llm-based judges. InICLR, 2025
work page 2025
-
[40]
Personalized pieces: Efficient personalized large language models through collaborative efforts
Zhaoxuan Tan, Zheyuan Liu, and Meng Jiang. Personalized pieces: Efficient personalized large language models through collaborative efforts. InEMNLP, 2024
work page 2024
-
[41]
Democ- ratizing large language models via personalized parameter-efficient fine-tuning
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. Democ- ratizing large language models via personalized parameter-efficient fine-tuning. InEMNLP, 2024
work page 2024
-
[42]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. InNeurIPS, 2024
work page 2024
-
[43]
Zhilin Wang, Jiaqi Zeng, Olivier Delalleau, Daniel Egert, Ellie Evans, Hoo-Chang Shin, Felipe Soares, Yi Dong, and Oleksii Kuchaiev. Helpsteer3: Human-annotated feedback and edit data to empower inference-time scaling in open-ended general-domain tasks. InACL, 2025
work page 2025
-
[44]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, et al. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InACL, 2025
work page 2025
-
[45]
Prefix-tuning: Optimizing continuous prompts for generation
Lisa Li Xiang and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InACL-IJCNLP, 2021
work page 2021
-
[46]
Personalized text generation with contrastive activation steering
Jinghao Zhang, Yuting Liu, Wenjie Wang, Qiang Liu, Shu Wu, Liang Wang, and Tat-Seng Chua. Personalized text generation with contrastive activation steering. InACL, 2025
work page 2025
-
[47]
Linhai Zhang, Jialong Wu, Deyu Zhou, and Yulan He. Proper: A progressive learning framework for personalized large language models with group-level adaptation. InACL, 2025
work page 2025
-
[48]
Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Barrow, Tong Yu, Sungchul Kim, Ruiyi Zhang, Jiuxiang Gu, Tyler Derr, Hongjie Chen, Junda Wu, Xiang Chen, Zichao Wang, Subrata Mitra, Nedim Lipka, Nesreen K. Ahmed, and Yu Wang. Personalization of large language models: A survey. In TMLR, 2025. 12
work page 2025
-
[49]
Do llms recognize your preferences? evaluating personalized preference following in llms
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Hazarika, and Kaixiang Lin. Do llms recognize your preferences? evaluating personalized preference following in llms. InICLR, 2025
work page 2025
-
[50]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InNeurIPS, 2023. 13 Supplementary Material A Limitations and Broader Impact Limitations. Our evaluation relies on synthetic data, e.g. conversation histories are LL...
work page 2023
-
[51]
Additionally, we rate per-principle compliance for each of the 10 response principles in Tab
persona. Additionally, we rate per-principle compliance for each of the 10 response principles in Tab. 6 and aggregate these into asign-balanced principle score, a single-response analog of the APM reward (Eq. (2)). For each (prompt, principle) pair we take the judge’s score and, with probability0.5, replace it with 11−score before averaging across the 10...
-
[52]
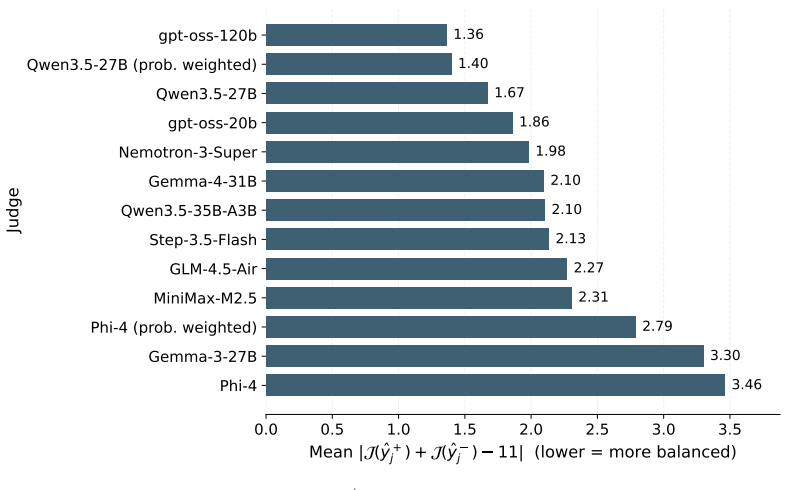
Balance:Whether the sum s+ +s − is approximately constant (≈11 on our scale). A judge that assigns high scores to both directions of a principle injects systematic noise into training labels. We report the mean L1 distanceE[|s + +s − −11|](Fig. 6)
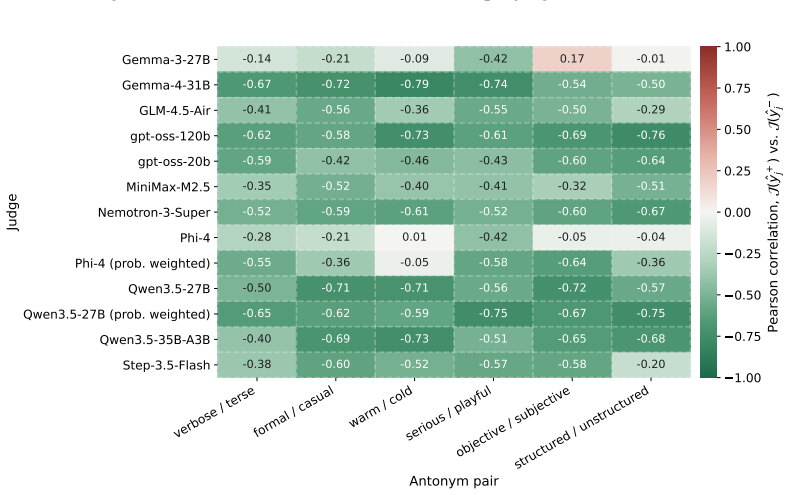
-
[53]
Anticorrelation:Whether s+ and s− are negatively correlated across responses. A correla- tion near −1 indicates reliable discrimination between poles, and near 0 suggests the judge conflates them. We report per-pair Pearson correlations (Fig. 7). Selection. Among the evaluated models, gpt-oss-120b shows the best trade-off, as it achieves consistently low ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.