RCGDet3D: Rethinking 4D Radar-Camera Fusion-based 3D Object Detection with Enhanced Radar Feature Encoding
Pith reviewed 2026-05-21 05:04 UTC · model grok-4.3
The pith
Simply improving radar feature extraction matches or beats elaborate radar-camera fusion for real-time 3D detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that radar feature extraction has been under-optimized; once it is strengthened through ray-centric Gaussian encoding and minimal semantic cues from images, the resulting features support accurate 3D detection with far simpler and faster fusion than existing elaborate cross-modal modules.
What carries the argument
Ray-centric Point Gaussian Encoder (R-PGE) that predicts Gaussian attributes in ray-aligned coordinates before unifying to BEV space, paired with a Semantic Injection module that adds visual cues to radar features.
If this is right
- Detection pipelines can drop heavy cross-modal attention layers and still reach state-of-the-art accuracy.
- Real-time constraints become easier to satisfy because compute stays on sparse radar points rather than dense fused maps.
- Radar-only or lightly fused systems become more competitive for deployment where camera data is unreliable.
Where Pith is reading between the lines
- The finding implies that many current fusion papers may be solving the wrong problem by adding complexity downstream instead of fixing the upstream radar representation.
- A natural next test is whether the same ray-centric encoding principle improves other sparse sensors such as LiDAR in low-density regimes.
Load-bearing premise
The targeted changes to radar point encoding are sufficient on their own to deliver the reported accuracy gains without needing sophisticated multi-modal fusion.
What would settle it
Run the same backbone and fusion on View-of-Delft with R-PGE and Semantic Injection disabled; if detection accuracy drops below the full model while remaining faster than prior fusion methods, the claim holds.
Figures





read the original abstract
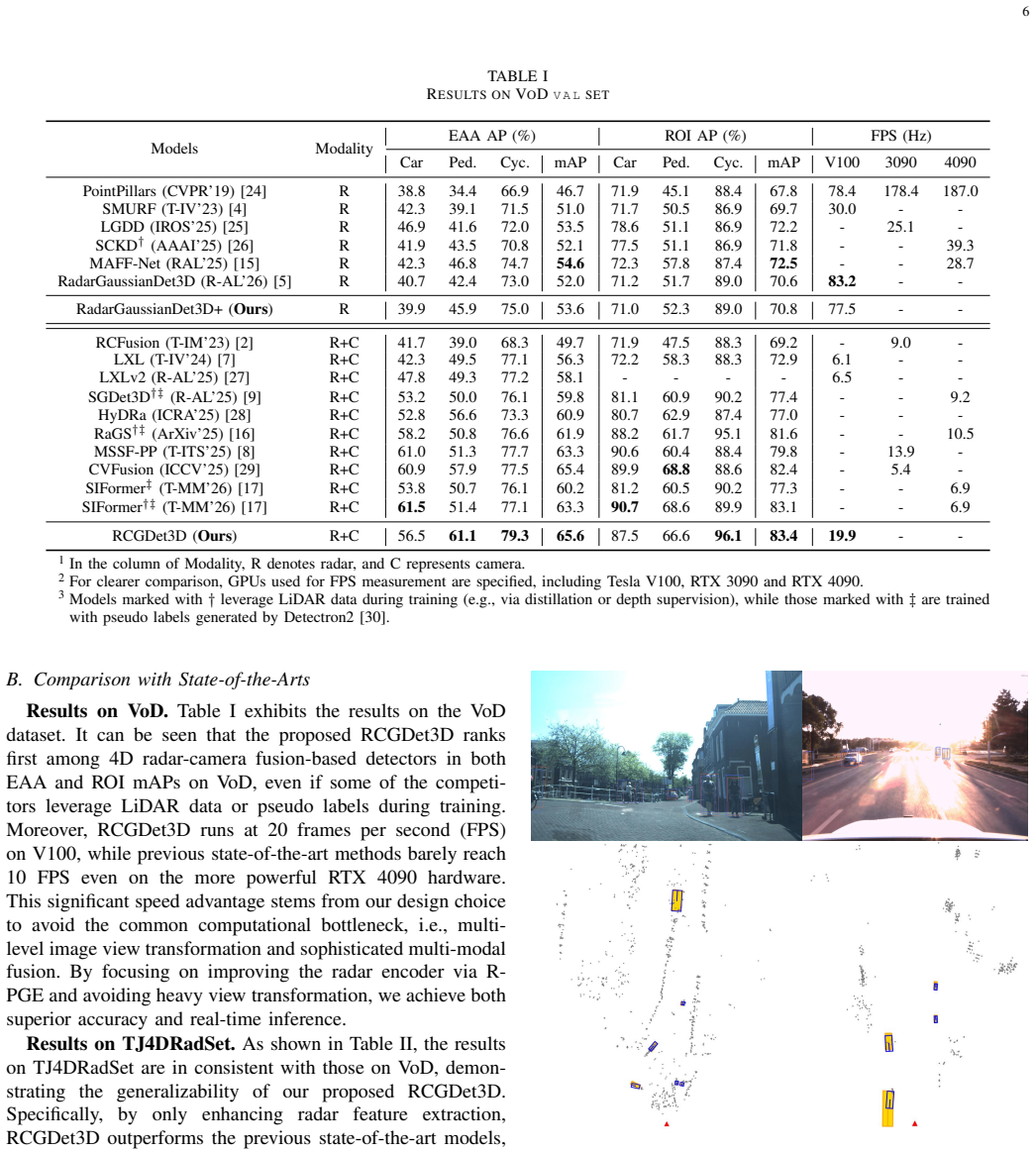
4D automotive radar is indispensable for autonomous driving due to its low cost and robustness, yet its point cloud sparsity challenges 3D object detection. Existing 4D radar-camera fusion methods focus on complex fusion strategies, trading inference speed for marginal gains. This trade-off hinders real-time deployment due to heavy computation on dense feature maps. In contrast, feature extraction from sparse radar points is less time-consuming but remains under-explored. This work uncovers that simply enhancing radar feature extraction can achieve comparable or even higher performance than elaborate fusion modules, while maintaining real-time performance. Based on this finding, we propose RCGDet3D, which centers on radar feature encoding and simplifies multi-modal fusion. Its encoder inherits from the efficient Gaussian Splatting-based Point Gaussian Encoder (PGE) in RadarGaussianDet3D with two key improvements. First, the Ray-centric PGE (R-PGE) predicts Gaussian attributes in ray-aligned coordinate systems before unifying them to Bird's-Eye View (BEV) space, significantly improving geometric consistency and reducing learning difficulty by decoupling the coordinate transformation from representation learning. Second, a Semantic Injection (SI) module incorporates visual cues from images, producing more geometrically accurate and semantically enriched radar features. Experiments on View-of-Delft (VoD) and TJ4DRadSet show that RCGDet3D outperforms state-of-the-art methods in both accuracy and speed, setting a new benchmark for real-time deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that enhancing radar feature extraction from sparse 4D radar points can match or exceed the performance of complex radar-camera fusion modules for 3D object detection while preserving real-time inference. It proposes RCGDet3D, which extends the Gaussian Splatting-based Point Gaussian Encoder (PGE) into a Ray-centric PGE (R-PGE) that predicts Gaussian attributes in ray-aligned coordinates before BEV unification, plus a Semantic Injection (SI) module that incorporates visual cues from images into the radar features. Experiments on the View-of-Delft (VoD) and TJ4DRadSet datasets are reported to show state-of-the-art accuracy and speed.
Significance. If the results and ablations hold, the work would usefully shift emphasis toward efficient radar-centric encoding rather than elaborate cross-modal fusion, with direct relevance to real-time autonomous driving perception. The ray-centric decoupling and Gaussian representation offer a concrete, potentially parameter-light direction for handling radar sparsity.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The central claim that 'simply enhancing radar feature extraction' suffices is load-bearing yet not isolated. The SI module explicitly injects image-derived semantic cues into radar features, so the architecture remains multi-modal; without an ablation that disables SI (or compares against a pure radar-only R-PGE baseline) the reported gains on VoD and TJ4DRadSet cannot be attributed primarily to the radar encoding improvements rather than the added visual semantics.
- [§4] §4 (Experiments): Tables comparing against SOTA methods should include (i) a radar-only variant of RCGDet3D and (ii) an SI-ablated version so that the contribution of R-PGE coordinate decoupling versus semantic injection can be quantified. Current reporting of overall outperformance does not yet falsify the alternative that the simplified fusion via SI is the operative factor.
minor comments (2)
- [§3.1] Clarify in §3.1 whether the ray-aligned coordinate prediction in R-PGE introduces any additional learnable parameters beyond the original PGE or remains strictly parameter-free in the claimed sense.
- [Figure 2] Figure 2 (architecture diagram) would benefit from explicit annotation of the ray-to-BEV unification step and the exact point at which SI occurs to make the data flow unambiguous.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that isolating the contributions of the R-PGE and SI module requires additional ablations, and we will revise the manuscript accordingly to strengthen the evidence for our central claim.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that 'simply enhancing radar feature extraction' suffices is load-bearing yet not isolated. The SI module explicitly injects image-derived semantic cues into radar features, so the architecture remains multi-modal; without an ablation that disables SI (or compares against a pure radar-only R-PGE baseline) the reported gains on VoD and TJ4DRadSet cannot be attributed primarily to the radar encoding improvements rather than the added visual semantics.
Authors: We agree that the SI module renders the system multi-modal and that the current experiments do not fully isolate the radar encoding contribution. In the revised version we will add an ablation that disables SI entirely, reporting performance of the pure radar-only R-PGE variant on both VoD and TJ4DRadSet. This will allow direct quantification of the gains attributable to ray-centric coordinate decoupling versus the lightweight semantic cues provided by SI. revision: yes
-
Referee: [§4] §4 (Experiments): Tables comparing against SOTA methods should include (i) a radar-only variant of RCGDet3D and (ii) an SI-ablated version so that the contribution of R-PGE coordinate decoupling versus semantic injection can be quantified. Current reporting of overall outperformance does not yet falsify the alternative that the simplified fusion via SI is the operative factor.
Authors: We accept the recommendation. The updated §4 tables will explicitly include both the radar-only RCGDet3D variant and the SI-ablated configuration alongside the full model and prior SOTA methods. These additions will demonstrate that the majority of the accuracy improvement stems from the R-PGE design while SI contributes a smaller, complementary semantic boost, thereby supporting rather than undermining the paper's emphasis on efficient radar-centric encoding. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks rather than self-referential derivations
full rationale
The paper presents an empirical finding that radar feature enhancements (via R-PGE coordinate decoupling and SI) can match or exceed complex fusion performance, validated on VoD and TJ4DRadSet. It inherits and modifies the PGE encoder from prior work but justifies the specific changes (ray-aligned prediction before BEV unification, visual cue injection) through geometric consistency arguments, not by reducing new results to fitted inputs or self-citations. No equations equate outputs to inputs by construction, no predictions are statistically forced from subsets of the same data, and the multi-modal SI component is explicitly stated rather than smuggled. The architecture remains self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi- class road user detection with 3+ 1D radar in the View-of-Delft dataset,
A. Palffy, E. Pool, S. Baratam, J. F. Kooij, and D. M. Gavrila, “Multi- class road user detection with 3+ 1D radar in the View-of-Delft dataset,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4961–4968, 2022
work page 2022
-
[2]
RCFusion: Fusing 4-D radar and camera with bird’s-eye view features for 3-D object detection,
L. Zheng, S. Li, B. Tan, L. Yang, S. Chen, L. Huang, J. Bai, X. Zhu, and Z. Ma, “RCFusion: Fusing 4-D radar and camera with bird’s-eye view features for 3-D object detection,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–14, 2023
work page 2023
-
[3]
RPFA-Net: A 4D radar pillar feature attention network for 3D object detection,
B. Xu, X. Zhang, L. Wang, X. Hu, Z. Li, S. Pan, J. Li, and Y . Deng, “RPFA-Net: A 4D radar pillar feature attention network for 3D object detection,” in2021 IEEE International Intelligent Transportation Sys- tems Conference (ITSC). IEEE, 2021, pp. 3061–3066
work page 2021
-
[4]
SMURF: Spatial multi-representation fusion for 3D object detection with 4D imaging radar,
J. Liu, Q. Zhao, W. Xiong, T. Huang, Q.-L. Han, and B. Zhu, “SMURF: Spatial multi-representation fusion for 3D object detection with 4D imaging radar,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 799–812, 2024
work page 2024
-
[5]
W. Xiong, B. Zhu, and Z. Zheng, “Radargaussiandet3d: Gaussian representation-based real-time 3d object detection with 4d automotive radars,”IEEE Robotics and Automation Letters, vol. 11, no. 5, pp. 5709– 5716, 2026
work page 2026
-
[6]
GaussianBeV: 3D gaussian representation meets perception models for BeV segmentation,
F. Chabot, N. Granger, and G. Lapouge, “GaussianBeV: 3D gaussian representation meets perception models for BeV segmentation,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 2250–2259
work page 2025
-
[7]
LXL: LiDAR excluded lean 3D object detection with 4D imaging radar and camera fusion,
W. Xiong, J. Liu, T. Huang, Q.-L. Han, Y . Xia, and B. Zhu, “LXL: LiDAR excluded lean 3D object detection with 4D imaging radar and camera fusion,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 79–92, 2024
work page 2024
-
[8]
H. Liu, J. Liu, G. Jiang, and X. Jin, “Mssf: A 4d radar and camera fusion framework with multi-stage sampling for 3d object detection in autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 6, pp. 8641–8656, 2025
work page 2025
-
[9]
Sgdet3d: Semantics and geometry fusion for 3d object detection using 4d radar and camera,
X. Bai, Z. Yu, L. Zheng, X. Zhang, Z. Zhou, X. Zhang, F. Wang, J. Bai, and H.-L. Shen, “Sgdet3d: Semantics and geometry fusion for 3d object detection using 4d radar and camera,”IEEE Robotics and Automation Letters, vol. 10, no. 1, pp. 828–835, 2024
work page 2024
-
[10]
TJ4DRadSet: A 4D radar dataset for autonomous driving,
L. Zheng, Z. Ma, X. Zhu, B. Tan, S. Li, K. Long, W. Sun, S. Chen, L. Zhang, M. Wanet al., “TJ4DRadSet: A 4D radar dataset for autonomous driving,” in2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 493–498
work page 2022
-
[11]
PointNet: Deep learning on point sets for 3D classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 652–660
work page 2017
-
[12]
RadarPillars: Efficient Object Detection From 4D Radar Point Clouds,
A. Musiat, L. Reichardt, M. Schulze, and O. Wasenm ¨uller, “RadarPillars: Efficient Object Detection From 4D Radar Point Clouds,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2024, pp. 1656–1663
work page 2024
-
[13]
Sd4r: Sparse-to-dense learning for 3d object detection with 4d radar,
X. Bai, J. Cheng, S. Wang, Y . Luo, L. Zheng, X. Zhang, S.-Y . Cao, and H.-L. Shen, “Sd4r: Sparse-to-dense learning for 3d object detection with 4d radar,” in2025 IEEE 28th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2025, pp. 4362–4368
work page 2025
-
[14]
RCBEVDet: Radar-camera fusion in bird’s eye view for 3D object detection,
Z. Lin, Z. Liu, Z. Xia, X. Wang, Y . Wang, S. Qi, Y . Dong, N. Dong, L. Zhang, and C. Zhu, “RCBEVDet: Radar-camera fusion in bird’s eye view for 3D object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 928–14 937
work page 2024
-
[15]
Maff-net: Enhancing 3d object detection with 4d radar via multi-assist feature fusion,
X. Bi, C. Weng, P. Tong, B. Fan, and A. Eichberge, “Maff-net: Enhancing 3d object detection with 4d radar via multi-assist feature fusion,”IEEE Robotics and Automation Letters, vol. 10, no. 5, pp. 4284–4291, 2025
work page 2025
-
[16]
RaGS: Unleashing 3D Gaussian Splatting from 4D Radar and Monocular Cues for 3D Object Detection,
X. Bai, C. Zhou, L. Zheng, S.-Y . Cao, J. Liu, X. Zhang, Z. Zhang, and H.-l. Shen, “RaGS: Unleashing 3D Gaussian Splatting from 4D Radar and Monocular Cues for 3D Object Detection,”arXiv preprint arXiv:2507.19856, 2025
-
[17]
X. Bai, L. Zheng, S.-Y . Cao, X. Zhang, Z. Wu, B. Yu, F. Wang, J. Bai, and H.-L. Shen, “Boosting instance awareness via cross-view correlation with 4d radar and camera for 3d object detection,”arXiv preprint arXiv:2602.20632, 2026
-
[18]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
work page 2023
-
[19]
Toward real-world bev perception: Depth uncertainty estimation via gaussian splatting,
S.-W. Lu, Y .-H. Tsai, and Y .-T. Chen, “Toward real-world bev perception: Depth uncertainty estimation via gaussian splatting,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2025, pp. 17 124–17 133
work page 2025
-
[20]
Gsrender: Deduplicated occupancy prediction via weakly supervised 3d gaussian splatting,
Q. Sun, C. Shu, S. Zhou, R. Cheng, Y . Wei, Z. Yu, D. Yang, S. Han, and Y . Chun, “Gsrender: Deduplicated occupancy prediction via weakly supervised 3d gaussian splatting,”arXiv preprint arXiv:2412.14579, 2024
-
[21]
GaussianFormer: Scene as gaussians for vision-based 3D semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “GaussianFormer: Scene as gaussians for vision-based 3D semantic occupancy prediction,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 376– 393
work page 2024
-
[22]
Odg: Occupancy prediction using dual gaussians,
Y . Shi, Y . Zhu, S. Han, J. Jeong, A. Ansari, H. Cai, and F. Porikli, “Odg: Occupancy prediction using dual gaussians,”arXiv preprint arXiv:2506.09417, 2025
-
[23]
Center-based 3D object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3D object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
work page 2021
-
[24]
PointPillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “PointPillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 697–12 705
work page 2019
-
[25]
Lgdd: Local-global synergistic dual-branch 3d object detection using 4d radar,
X. Bai, Q. Yang, Z. Zhou, F. Zhang, Z. Wu, S.-Y . Cao, L. Zheng, B. Yu, F. Wang, J. Baiet al., “Lgdd: Local-global synergistic dual-branch 3d object detection using 4d radar,” in2025 IEEE/RSJ International 9 Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 13 318–13 325
work page 2025
-
[26]
SCKD: Semi-supervised cross-modality knowledge distillation for 4D radar object detection,
R. Xu, Z. Xiang, C. Zhang, H. Zhong, X. Zhao, R. Dang, P. Xu, T. Pu, and E. Liu, “SCKD: Semi-supervised cross-modality knowledge distillation for 4D radar object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 8933– 8941
work page 2025
-
[27]
LXLv2: Enhanced LiDAR excluded lean 3D object detection with fusion of 4D radar and camera,
W. Xiong, Z. Zou, Q. Zhao, F. He, and B. Zhu, “LXLv2: Enhanced LiDAR excluded lean 3D object detection with fusion of 4D radar and camera,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[28]
Unleashing hydra: Hybrid fusion, depth consistency and radar for unified 3d perception,
P. Wolters, J. Gilg, T. Teepe, F. Herzog, A. Laouichi, M. Hofmann, and G. Rigoll, “Unleashing hydra: Hybrid fusion, depth consistency and radar for unified 3d perception,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 7467–7474
work page 2025
-
[29]
Cvfusion: Cross-view fusion of 4d radar and camera for 3d object detection,
H. Zhong, Z. Xiang, R. Xu, J. Fu, P. Xu, S. Wang, Z. Yang, T. Pu, and E. Liu, “Cvfusion: Cross-view fusion of 4d radar and camera for 3d object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 188–28 197
work page 2025
-
[30]
Y . Wu, A. Kirillov, F. Massa, W.-Y . Lo, and R. Girshick, “Detectron2,” https://github.com/facebookresearch/detectron2, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.