ROAR-3D: Routing Arbitrary Views for High-Fidelity 3D Generation
Pith reviewed 2026-05-21 05:00 UTC · model grok-4.3
The pith
A token-wise router and dual-stream attention upgrade pretrained single-view 3D models to accept arbitrary unposed images and raise output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
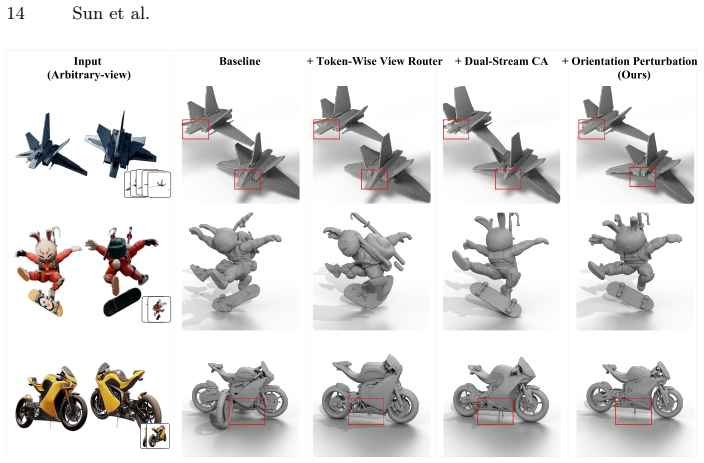
ROAR-3D upgrades a pretrained single-view model to accept an arbitrary number of unposed images. A token-wise view router assigns each 3D latent token to its most relevant view, implicitly establishing 2D-to-3D correspondences without explicit pose input. A dual-stream attention design preserves the pretrained primary-view behavior while routing auxiliary views through a separate path dedicated to geometric enrichment. An orientation perturbation strategy ensures the auxiliary path learns orientation-independent geometry transfer. These components introduce minimal trainable parameters and add negligible inference overhead relative to the single-view baseline.
What carries the argument
Token-wise view router paired with dual-stream attention, which assigns each 3D latent token to its most relevant input view and routes auxiliary views through a separate path while preserving primary-view behavior.
If this is right
- Multi-view 3D generation quality reaches state-of-the-art levels compared with prior methods that require fixed views or heavy external modules.
- Generation quality improves consistently when the number of input views is scaled from 1 to 12 or more at test time.
- Only minimal additional parameters are introduced and inference overhead stays negligible relative to the single-view baseline.
- The model operates on arbitrary unposed images without needing explicit camera poses or external reconstruction steps.
Where Pith is reading between the lines
- The routing approach could extend to combining inputs from different modalities such as text descriptions or depth maps in the same pretrained backbone.
- Test-time view scaling implies that applications with many casual photos of an object could achieve higher fidelity simply by feeding all available images without retraining.
- Implicit 2D-to-3D correspondence via token routing may lower the need for explicit pose estimation or multi-view supervision in related reconstruction pipelines.
Load-bearing premise
The orientation control and geometry transfer functions inside a pretrained single-view 3D model can be cleanly separated by routing and dual attention without retraining the core model or losing original performance.
What would settle it
An ablation that adds extra views but removes the token-wise router or dual-stream attention and shows no quality gain or even degradation would falsify the claim that these components enable effective separation and reuse.
Figures






read the original abstract
Single-image-to-3D generative models can now produce high-quality geometry, yet conditioning on a single view inevitably introduces ambiguity about unseen regions. Multi-view conditioning can reduce this ambiguity, but existing methods either require fixed canonical viewpoints or rely on external reconstruction modules that impose heavy training costs and limit generation quality. We observe that pretrained single-view models already possess strong 2D-to-3D grounding that can be reused for multi-view conditioning. However, a closer analysis reveals that their conditioning mechanism entangles orientation control with geometry transfer, two functions that conflict when images from different viewpoints are naively combined. Based on this analysis, we propose ROAR-3D, a lightweight method that upgrades a pretrained single-view model to accept an arbitrary number of unposed images. A token-wise view router assigns each 3D latent token to its most relevant view, implicitly establishing 2D-to-3D correspondences without explicit pose input. A dual-stream attention design preserves the pretrained primary-view behavior while routing auxiliary views through a separate path dedicated to geometric enrichment. An orientation perturbation strategy ensures the auxiliary path learns orientation-independent geometry transfer. These components introduce minimal trainable parameters and add negligible inference overhead relative to the single-view baseline. ROAR-3D achieves state-of-the-art multi-view 3D generation quality and supports test-time view scaling from 1 to 12+ views with consistent improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ROAR-3D, a lightweight method to upgrade pretrained single-view 3D generative models to handle an arbitrary number of unposed images for high-fidelity 3D generation. It uses a token-wise view router to assign 3D latent tokens to the most relevant view without explicit pose input, a dual-stream attention design to preserve primary-view behavior while routing auxiliary views for geometric enrichment, and an orientation perturbation strategy to ensure the auxiliary path learns orientation-independent geometry transfer. The method claims to achieve state-of-the-art multi-view 3D generation quality, support test-time view scaling from 1 to 12+ views with consistent improvements, and introduce minimal trainable parameters with negligible inference overhead relative to the single-view baseline.
Significance. If the central claims hold under empirical validation, this work would be significant for enabling flexible multi-view conditioning in 3D generation by reusing strong 2D-to-3D grounding from existing pretrained models, avoiding the need for fixed canonical viewpoints or costly external reconstruction modules. The lightweight design and test-time scalability represent practical advances that could improve generation quality for arbitrary input views with low overhead.
major comments (2)
- [Abstract and Method Description] The central claim that a token-wise router and dual-stream attention can cleanly separate orientation control from geometry transfer (without retraining the core model) is load-bearing for the entire method and its ability to scale to 12+ views. The analysis of entanglement in the abstract and method description does not demonstrate that the pretrained latent space already encodes view-specific relevance distinctly enough to prevent ambiguous routing decisions or leakage of orientation cues into the geometry stream for distant or similar views.
- [Abstract and Experiments] The abstract states that ROAR-3D achieves SOTA multi-view 3D generation quality and consistent improvements with view scaling, but the provided description contains no quantitative tables, ablation studies, or error analysis to support these results. This is load-bearing because the effectiveness of the router, dual-stream attention, and perturbation strategy cannot be assessed without such evidence.
minor comments (1)
- [Method] The notation for the token-wise router and dual-stream attention could be clarified with explicit equations or pseudocode to make the separation of primary and auxiliary paths easier to follow.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below in a point-by-point fashion and indicate the changes made to strengthen the work.
read point-by-point responses
-
Referee: [Abstract and Method Description] The central claim that a token-wise router and dual-stream attention can cleanly separate orientation control from geometry transfer (without retraining the core model) is load-bearing for the entire method and its ability to scale to 12+ views. The analysis of entanglement in the abstract and method description does not demonstrate that the pretrained latent space already encodes view-specific relevance distinctly enough to prevent ambiguous routing decisions or leakage of orientation cues into the geometry stream for distant or similar views.
Authors: We agree that a clear demonstration of this separation is essential for the method's validity and scalability. Section 3 of the full manuscript analyzes the entanglement through both theoretical motivation and empirical observations, including attention visualizations showing how naive fusion mixes orientation and geometry signals. The token-wise router computes relevance scores directly from the pretrained latents to assign tokens, while the dual-stream attention and orientation perturbation explicitly isolate orientation control to the primary view. To address the concern about ambiguous routing or leakage for similar or distant views, we have added new quantitative routing accuracy metrics and additional attention visualizations in the revised manuscript and supplementary material. revision: yes
-
Referee: [Abstract and Experiments] The abstract states that ROAR-3D achieves SOTA multi-view 3D generation quality and consistent improvements with view scaling, but the provided description contains no quantitative tables, ablation studies, or error analysis to support these results. This is load-bearing because the effectiveness of the router, dual-stream attention, and perturbation strategy cannot be assessed without such evidence.
Authors: The full manuscript contains the requested evidence: Table 1 reports quantitative SOTA comparisons on standard 3D generation benchmarks, Table 2 and Section 4.3 present ablations isolating the router, dual-stream attention, and perturbation strategy, and Figure 4 shows consistent quality gains when scaling from 1 to 12+ views at test time. We have expanded the error analysis and failure-case discussion in the revision. While the abstract is necessarily concise, we have updated it to explicitly reference these supporting results and sections. revision: yes
Circularity Check
No circularity in derivation; method builds on external pretrained models
full rationale
The paper describes an empirical method that reuses pretrained single-view 3D models via added components (token-wise router, dual-stream attention, orientation perturbation). No equations, derivations, or fitted parameters are presented that reduce the claimed multi-view improvements or view-scaling behavior to quantities defined by the method itself. The analysis of entanglement is observational, and performance claims are positioned as empirical outcomes on external benchmarks rather than self-referential predictions. No self-citation chains or uniqueness theorems are invoked as load-bearing. The derivation chain is self-contained against external pretrained models and test-time scaling results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained single-view models possess strong 2D-to-3D grounding reusable for multi-view conditioning.
Reference graph
Works this paper leans on
- [1]
-
[2]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, D.Z., Siddiqui, Y., Lee, H.Y., Tulyakov, S., Nießner, M.: Text2tex: Text- driven texture synthesis via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 18558–18568 (2023)
work page 2023
- [3]
- [4]
-
[5]
Chen, Y., Li, Z., Wang, Y., Zhang, H., Li, Q., Zhang, C., Lin, G.: Ultra3d: Efficient and high-fidelity 3d generation with part attention. arXiv preprint arXiv:2507.17745 (2025)
- [6]
-
[7]
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. NeurIPS36(2024)
work page 2024
- [8]
-
[9]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Feng, Y., Yang, M., Yang, S., Zhang, S., Yu, J., Zhao, Z., Liu, Y., Jiang, J., Guo, C.: Romantex: Decoupling 3d-aware rotary positional embedded multi-attention network for texture synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17203–17213 (2025)
work page 2025
-
[10]
Foundations and trends®in Computer Graphics and Vision9(1-2), 1–148 (2015)
Furukawa, Y., Hernández, C., et al.: Multi-view stereo: A tutorial. Foundations and trends®in Computer Graphics and Vision9(1-2), 1–148 (2015)
work page 2015
- [11]
- [12]
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
He, Z., Yang, M., Yang, S., Tang, Y., Wang, T., Zhang, K., Chen, G., Liu, Y., Jiang, J., Guo, C., et al.: Materialmvp: Illumination-invariant material genera- tion via multi-view pbr diffusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 26294–26305 (2025)
work page 2025
-
[14]
Hitem3D Team: Hitem3d: High-quality 3d model generation service (2024),https: //www.hitem3d.ai/, accessed: 2024-05-20
work page 2024
-
[15]
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. In: ICLR (2023)
work page 2023
-
[16]
Hui, K.H., Li, R., Hu, J., Fu, C.W.: Neural wavelet-domain diffusion for 3d shape generation. In: SIGGRAPH Aisa. pp. 1–9 (2022)
work page 2022
-
[17]
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., Lin, Q., Lai, Z., Yang, X., Shi, H., Zhao, Z., Zhang, B., Yan, H., Wang, L., Liu, S., Zhang, J., Chen, M., Dong, L., Jia, Y., Cai, Y., Yu, J., Tang, Y., Guo, D., Yu, J., Zhang, H., Ye, Z., He, P., Wu, R., Wei, S., Zhang, C., Tan, Y., 16 Sun et al. Sun, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Hy-3D Team: Hy-3d (2024),https://hy-3d.com, accessed: 2024-05-20
work page 2024
-
[19]
Hyper3D Team: Hyper3d: High-fidelity 3d asset generation (2024),https:// hyper3d.ai/, accessed: 2024-05-20
work page 2024
-
[20]
Categorical Reparameterization with Gumbel-Softmax
Jang, E., Gu, S., Poole, B.: Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. TOG42(4), 139–1 (2023)
work page 2023
-
[22]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Lai, Z., Zhao, Y., Liu, H., Zhao, Z., Lin, Q., Shi, H., Yang, X., Yang, M., Yang, S., Feng, Y., et al.: Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details. arXiv preprint arXiv:2506.16504 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
arXiv preprint arXiv:2512.03052 (2025)
Lai, Z., Zhao, Y., Zhao, Z., Liu, H., Lin, Q., Huang, J., Guo, C., Yue, X.: Lattice: Democratize high-fidelity 3d generation at scale. arXiv preprint arXiv:2512.03052 (2025)
-
[24]
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model
Li, J., Tan, H., Zhang, K., Xu, Z., Luan, F., Xu, Y., Hong, Y., Sunkavalli, K., Shakhnarovich, G., Bi, S.: Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. arXiv preprint arXiv:2311.06214 (2023)
-
[25]
arXiv preprint arXiv:2405.11616 (2024)
Li, P., Liu, Y., Long, X., Zhang, F., Lin, C., Li, M., Qi, X., Zhang, S., Luo, W., Tan, P., et al.: Era3d: High-resolution multiview diffusion using efficient row-wise attention. arXiv preprint arXiv:2405.11616 (2024)
-
[26]
2025.doi:10.48550/arXiv.2405.14979
Li, W., Liu, J., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Craftsman: High-fidelity mesh generation with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979 (2024)
-
[27]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
- [29]
- [30]
-
[31]
Liu, M., Xu, C., Jin, H., Chen, L., Varma T, M., Xu, Z., Su, H.: One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization. NeurIPS 36(2023)
work page 2023
-
[32]
In: SIGGRAPH Asia 2024 Conference Papers
Liu,Y.,Xie,M.,Liu,H.,Wong,T.T.:Text-guidedtexturingbysynchronizedmulti- view diffusion. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
work page 2024
-
[33]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
arXiv preprint arXiv:2511.16957 (2025)
Luo,D.,Yang,S.,Yang,M.,Lu,J.,Tang,Y.,Han,X.,Chen,Z.,Wang,B.,Guo,C.: Matpedia: A universal generative foundation for high-fidelity material synthesis. arXiv preprint arXiv:2511.16957 (2025)
- [35]
-
[36]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.:Nerf:Representingscenesasneuralradiancefieldsforviewsynthesis.In:ECCV. pp. 405–421 (2020)
work page 2020
- [37]
-
[38]
Nichol, A., Jun, H., Dhariwal, P., Mishkin, P., Chen, M.: Point-e: A system for generating3dpointcloudsfromcomplexprompts.arXivpreprintarXiv:2212.08751 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Transactions on Machine Learning Research Journal pp
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal pp. 1–31 (2024)
work page 2024
-
[40]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [41]
- [42]
- [43]
- [44]
-
[45]
Tang, J., Ren, J., Zhou, H., Liu, Z., Zeng, G.: Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. In: ICLR (2024)
work page 2024
- [46]
-
[47]
Tang, Z., Gu, S., Wang, C., Zhang, T., Bao, J., Chen, D., Guo, B.: Volumediffusion: Flexible text-to-3d generation with efficient volumetric encoder. arXiv preprint arXiv:2312.11459 (2023)
-
[48]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
https://3d.hunyuan.tencent.com/ (2024)
Tencent Hunyuan: Hunyuan3d. https://3d.hunyuan.tencent.com/ (2024)
work page 2024
-
[50]
Tripo AI: Tripo: Fast 3d object generation from text and image (2024),https: //www.tripo3d.ai/, accessed: 2024-05-20
work page 2024
- [51]
-
[52]
arXiv preprint arXiv:2503.11651 (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. arXiv preprint arXiv:2503.11651 (2025)
- [53]
- [54]
-
[55]
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. NeurIPS36(2024) 18 Sun et al
work page 2024
- [56]
-
[57]
Wang, Z., Wu, S., Xie, W., Chen, M., Prisacariu, V.A.: Nerf–: Neural radiance fields without known camera parameters (2021)
work page 2021
-
[58]
Meshlrm: Large reconstruction model for high- quality meshes.arXiv preprint arXiv:2404.12385, 2024
Wei, X., Zhang, K., Bi, S., Tan, H., Luan, F., Deschaintre, V., Sunkavalli, K., Su, H., Xu, Z.: Meshlrm: Large reconstruction model for high-quality mesh. arXiv preprint arXiv:2404.12385 (2024)
-
[59]
arXiv preprint arXiv:2312.17250 (2023)
Wu, C.H., Chen, Y.C., Solarte, B., Yuan, L., Sun, M.: ifusion: Inverting diffusion for pose-free reconstruction from sparse views. arXiv preprint arXiv:2312.17250 (2023)
-
[60]
arXiv preprint arXiv:2405.20343 (2024)
Wu, K., Liu, F., Cai, Z., Yan, R., Wang, H., Hu, Y., Duan, Y., Ma, K.: Unique3d: High-quality and efficient 3d mesh generation from a single image. arXiv preprint arXiv:2405.20343 (2024)
-
[61]
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. arXiv preprint arXiv:2405.14832 (2024)
-
[62]
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., Yang, J.: Native and compact structured latents for 3d generation (2025),https://arxiv.org/abs/2512.14692
work page internal anchor Pith review arXiv 2025
-
[63]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [64]
-
[65]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [66]
-
[67]
arXiv preprint arXiv:2403.14621 (2024)
Xu, Y., Shi, Z., Yifan, W., Chen, H., Yang, C., Peng, S., Shen, Y., Wetzstein, G.: Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation. arXiv preprint arXiv:2403.14621 (2024)
-
[68]
Xu, Y., Tan, H., Luan, F., Bi, S., Wang, P., Li, J., Shi, Z., Sunkavalli, K., Wet- zstein, G., Xu, Z., et al.: Dmv3d: Denoising multi-view diffusion using 3d large reconstruction model. In: ICLR (2024)
work page 2024
-
[69]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1179–1189 (June 2023)
work page 2023
- [70]
- [71]
- [72]
-
[73]
Ye, C., Wu, Y., Lu, Z., Chang, J., Guo, X., Zhou, J., Zhao, H., Han, X.: Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging. arXiv preprint arXiv:2503.222363(2025) ROAR-3D 19
-
[74]
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3dshape2vecset: A 3d shape rep- resentation for neural fields and generative diffusion models. TOG42(4), 1–16 (2023)
work page 2023
-
[75]
Zhang, B., Cheng, Y., Yang, J., Wang, C., Zhao, F., Tang, Y., Chen, D., Guo, B.: Gaussiancube: Structuring gaussian splatting using optimal transport for 3d generative modeling. arXiv e-prints pp. arXiv–2403 (2024)
work page 2024
-
[76]
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. TOG43(4), 1–20 (2024)
work page 2024
-
[77]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Zhao, Z., Liu, W., Chen, X., Zeng, X., Wang, R., Cheng, P., Fu, B., Chen, T., Yu, G., Gao, S.: Michelangelo: Conditional 3d shape generation based on shape-image- text aligned latent representation. NeurIPS36(2024)
work page 2024
-
[79]
In: International Conference on Learning Rep- resentations (ICLR) (2024)
Zhou, J., Wang, J., Ma, B., Liu, Y.S., Huang, T., Wang, X.: Uni3d: Exploring unified 3d representation at scale. In: International Conference on Learning Rep- resentations (ICLR) (2024)
work page 2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.