Advantage Collapse in Group Relative Policy Optimization: Diagnosis and Mitigation
Pith reviewed 2026-05-21 06:05 UTC · model grok-4.3
The pith
Injecting virtual reward samples guided by a collapse rate metric lets GRPO learn from groups of identical answers without extra model rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
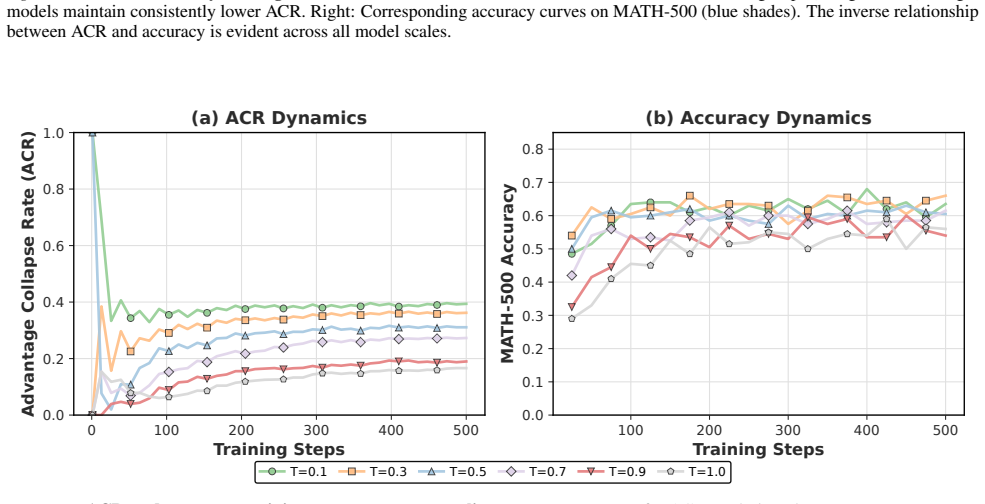
GRPO encounters advantage collapse whenever a group of sampled answers all receive identical rewards, producing near-zero advantages and vanishing policy gradients. The Advantage Collapse Rate quantifies the fraction of batches affected by this condition and correlates strongly with training stagnation. Adaptive Virtual Sample Policy Optimization uses real-time ACR monitoring to insert virtual reward samples into homogeneous groups, restoring a usable learning signal while avoiding any extra model rollouts. On mathematical reasoning tasks this yields a 58-63 percent reduction in collapse rate and 4-6 percentage point accuracy gains that hold across model scales while generalization on the o1
What carries the argument
Advantage Collapse Rate (ACR), the fraction of batches whose rewards are uniform enough to drive advantages to zero, together with Adaptive Virtual Sample Policy Optimization (AVSPO), which adds ACR-guided virtual reward samples to restore gradient signal in homogeneous groups.
If this is right
- Training runs can be monitored in real time for the onset of advantage collapse using the ACR metric.
- Homogeneous reward groups no longer produce zero gradients once virtual samples are injected.
- Accuracy gains appear consistently from 0.5B to 14B parameter models without increasing rollout cost.
- Generalization to at least one out-of-domain task remains comparable to the GRPO baseline.
Where Pith is reading between the lines
- ACR-style monitoring of gradient effectiveness could be applied to other relative advantage estimators beyond GRPO.
- Virtual-sample injection may offer a template for handling reward sparsity or uniformity in broader RLVR pipelines.
- Dynamic adjustment of virtual-sample frequency based on observed collapse rate could be extended to other training hyperparameters.
Load-bearing premise
That adding virtual reward samples guided by ACR does not distort the policy gradient or create systematic bias that would hurt performance outside the tested benchmarks.
What would settle it
An experiment that trains identical models with GRPO and AVSPO, then evaluates both on a broad suite of out-of-domain reasoning tasks never seen during the original training; if AVSPO accuracy falls below GRPO accuracy on those tasks the virtual-sample approach would be shown to introduce harmful bias.
Figures











read the original abstract
Group Relative Policy Optimization (GRPO), a prominent algorithm within the Reinforcement Learning from Verifiable Rewards (RLVR) framework, has achieved strong results in improving the reasoning capabilities of large language models (LLMs). However, GRPO is prone to advantage collapse, a failure mode where homogeneous rewards within a group (e.g., all correct or all incorrect answers) yield near-zero advantages and vanishing gradients. To address this, we introduce the Advantage Collapse Rate (ACR), the first diagnostic metric quantifying the proportion of training batches with ineffective gradients. Across models from 0.5B to 14B parameters on mathematical reasoning benchmarks, we show that ACR strongly predicts training stagnation and final performance. We then propose Adaptive Virtual Sample Policy Optimization (AVSPO), a lightweight extension of GRPO that injects virtual reward samples, guided by real-time ACR monitoring, to enable learning from homogeneous groups without additional model rollouts. AVSPO reduces advantage collapse by 58-63% relative to GRPO and yields consistent accuracy gains of 4-6 percentage points across all model scales, while maintaining generalization on the evaluated out-of-domain task. Code and datasets are available at https://qingyonghu.github.io/AVSPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript diagnoses advantage collapse in Group Relative Policy Optimization (GRPO) for LLM reasoning tasks, where homogeneous group rewards produce near-zero advantages and vanishing gradients. It introduces the Advantage Collapse Rate (ACR) metric to quantify the fraction of ineffective training batches and demonstrates its predictive power for stagnation. The authors then propose Adaptive Virtual Sample Policy Optimization (AVSPO), a lightweight GRPO extension that monitors ACR and injects virtual reward samples to enable learning from homogeneous groups without extra rollouts, reporting 58-63% ACR reduction and 4-6 percentage point accuracy gains across 0.5B-14B models on mathematical benchmarks while preserving out-of-domain generalization.
Significance. If the virtual-sample mechanism preserves unbiased gradients, AVSPO would provide a practical, low-cost stabilization technique for RLVR pipelines that are central to current LLM reasoning improvements. The multi-scale empirical evaluation and public code release are strengths that support reproducibility and potential adoption.
major comments (2)
- [Section 4] AVSPO description (Section 4): no derivation or analysis is given for how advantages are recomputed over the augmented group or whether the zero-mean property of the advantage estimator is preserved. If virtual rewards are assigned fixed heuristic values rather than drawn from the true reward distribution, the resulting advantage estimates become systematically shifted, which could explain the reported gains via altered gradient magnitude rather than genuine collapse mitigation.
- [Section 5] Experimental evaluation (Section 5, Tables 1-2): the 4-6 pp accuracy gains and 58-63% ACR reductions are presented without reporting variance across random seeds, sensitivity to the ACR threshold or injection rate, or explicit data-exclusion rules. This leaves open whether the improvements are robust or could arise from post-hoc tuning of the free parameter governing virtual-sample injection.
minor comments (2)
- [Section 3] The precise formula for ACR (e.g., as a proportion of batches with all-equal rewards) should be stated explicitly as an equation rather than described in prose.
- [Figures 2-3] Figure captions and axis labels in the ACR-vs-performance plots would benefit from clearer indication of whether curves aggregate multiple runs or single seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in turn below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Section 4] AVSPO description (Section 4): no derivation or analysis is given for how advantages are recomputed over the augmented group or whether the zero-mean property of the advantage estimator is preserved. If virtual rewards are assigned fixed heuristic values rather than drawn from the true reward distribution, the resulting advantage estimates become systematically shifted, which could explain the reported gains via altered gradient magnitude rather than genuine collapse mitigation.
Authors: We agree that Section 4 currently lacks an explicit derivation of the recomputed advantages on the augmented group and an analysis of the zero-mean property. In the revised manuscript we will add a dedicated paragraph deriving the advantage estimator after virtual-sample injection and showing that the zero-mean property is preserved when virtual rewards are assigned the negative of the current group-mean reward. This choice ensures the augmented group mean remains zero, so the advantage estimates stay unbiased. We will also clarify that the heuristic is not arbitrary but is chosen precisely to avoid systematic shifts in gradient magnitude. revision: yes
-
Referee: [Section 5] Experimental evaluation (Section 5, Tables 1-2): the 4-6 pp accuracy gains and 58-63% ACR reductions are presented without reporting variance across random seeds, sensitivity to the ACR threshold or injection rate, or explicit data-exclusion rules. This leaves open whether the improvements are robust or could arise from post-hoc tuning of the free parameter governing virtual-sample injection.
Authors: The referee correctly observes that variance across seeds, sensitivity analyses, and explicit data-exclusion rules are not reported. We will revise Section 5 to include standard deviations computed over three independent random seeds for all main results in Tables 1 and 2. We will also add an ablation subsection examining performance sensitivity to the ACR threshold and the virtual-sample injection rate, together with a clear statement of the data-exclusion criteria applied during training and evaluation. These additions will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity; empirical validation of new metric and extension remains independent
full rationale
The paper defines ACR as a diagnostic proportion of batches with near-zero advantages and introduces AVSPO as an empirical extension that injects virtual samples when ACR is high. Reported reductions in ACR (58-63%) and accuracy gains (4-6 pp) are measured outcomes on held-out benchmarks across model scales, not quantities algebraically forced by the definitions or by any fitted parameters within the same work. No equations equate the final performance claims to inputs by construction, no self-citation chain bears the central result, and the released code provides an external reproducibility check. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- virtual sample injection rate or threshold
invented entities (2)
-
Advantage Collapse Rate (ACR)
no independent evidence
-
Adaptive Virtual Sample Policy Optimization (AVSPO)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRPO advantage Â_i = (r_i - μ_R) / (σ_R + ε) and virtual-sample augmentation when σ_R < τ
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ACR monitors batch-level gradient ineffectiveness; AVSPO restores variance without extra rollouts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, B., Wu, H., Ye, P., and Chen, T. M-grpo: Stabilizing self-supervised reinforcement learning for large language models with momentum-anchored policy optimization. arXiv preprint arXiv:2512.13070, 2025
-
[2]
Bengio, Y., Louradour, J., Collobert, R., and Weston, J. Curriculum learning. In ICML, 2009
work page 2009
-
[3]
C., Obando-Ceron, J., Li, L., Bacon, P.-L., Berseth, G., Courville, A., and Castro, P
Castanyer, R. C., Obando-Ceron, J., Li, L., Bacon, P.-L., Berseth, G., Courville, A., and Castro, P. S. Stable gradients for stable learning at scale in deep reinforcement learning. arXiv preprint arXiv:2506.15544, 2025
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Deng, J., Chen, J., Chen, Z., Zhao, W. X., and Wen, J.-R. Decomposing the entropy-performance exchange: The missing keys to unlocking effective reinforcement learning. arXiv preprint arXiv:2508.02260, 2025
-
[6]
Principled data selection for alignment: The hidden risks of difficult examples
Gao, C., Li, H., Liu, L., Xie, Z., Zhao, P., and Xu, Z. Principled data selection for alignment: The hidden risks of difficult examples. In ICML, 2025
work page 2025
-
[7]
Greensmith, E., Bartlett, P. L., and Baxter, J. Variance reduction techniques for gradient estimates in reinforcement learning. JMLR, 5: 0 1471--1530, 2004
work page 2004
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Gupta, A., Tang, S., Song, Q., Zhu, S., Hong, J., Saha, A., Gupta, V., Lee, N., Kim, E., Zhu, S., Agrawal, P., Pillai, N. S., and Keerthi, S. S. Alphapo: Reward shape matters for LLM alignment. In ICML, 2025
work page 2025
-
[10]
LightEval: A Lightweight Framework for LLM Evaluation
Habib, N., Fourrier, C., Kydl\' i c ek, H., Wolf, T., and Tunstall, L. LightEval: A Lightweight Framework for LLM Evaluation . https://github.com/huggingface/lighteval, 2023
work page 2023
-
[11]
L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In ACL, 2024
work page 2024
-
[12]
Vl norm: Rethink loss aggregation in rlvr
He, Z., Luo, X., Zhang, Y., Yang, Y., and Qiu, L. Vl norm: Rethink loss aggregation in rlvr. arXiv preprint arXiv:2509.07558, 2025
-
[13]
Hemmat, R. A., Pezeshki, M., Dohmatob, E., Bordes, F., Astolfi, P., Hall, M., Verbeek, J., Drozdzal, M., and Romero-Soriano, A. Improving the scaling laws of synthetic data with deliberate practice. In ICML, 2025
work page 2025
-
[14]
Deep reinforcement learning that matters
Henderson, P., Islam, R., Bachman, P., Pineau, J., Precup, D., and Meger, D. Deep reinforcement learning that matters. In AAAI, 2018
work page 2018
-
[15]
Measuring mathematical problem solving with the MATH dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. In NeurIPS, 2021
work page 2021
-
[16]
T1 : Advancing language model reasoning through reinforcement learning and inference scaling
Hou, Z., Lv, X., Lu, R., Zhang, J., Li, Y., Yao, Z., Li, J., Tang, J., and Dong, Y. T1 : Advancing language model reasoning through reinforcement learning and inference scaling. In ICML, 2025
work page 2025
-
[17]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Hu, J., Liu, J. K., Xu, H., and Shen, W. Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V., Liu, A., Dziri, N., Lyu, S., et al. Tulu 3: Pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Langford, J. and Zhang, T. The epoch-greedy algorithm for multi-armed bandits with side information. In NeurIPS, 2007
work page 2007
-
[20]
Sharpness-Guided Group Relative Policy Optimization via Probability Shaping
Le, T., Van, L. N., and Le, T. Sharpness-guided group relative policy optimization via probability shaping. arXiv preprint arXiv:2511.00066, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
V., Jeon, M., Vu, K., Lai, V., and Yang, E
Le, T.-L. V., Jeon, M., Vu, K., Lai, V., and Yang, E. No prompt left behind: Exploiting zero-variance prompts in llm reinforcement learning via entropy-guided advantage shaping. arXiv preprint arXiv:2509.21880, 2025
-
[22]
Solving quantitative reasoning problems with language models
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. Solving quantitative reasoning problems with language models. In NeurIPS, 2022
work page 2022
-
[23]
Adaptive group policy optimization: Towards stable training and token-efficient reasoning
Li, C., Liu, N., and Yang, K. Adaptive group policy optimization: Towards stable training and token-efficient reasoning. arXiv preprint arXiv:2503.15952, 2025
-
[24]
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let's verify step by step. In ICLR, 2024
work page 2024
-
[25]
Understanding R1-Zero-Like Training: A Critical Perspective
Liu, Z., Chen, C., Li, W., Qi, P., Pang, T., Du, C., Lee, W. S., and Lin, M. Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2503.06639 , year=
Mroueh, Y. Reinforcement learning with verifiable rewards: Grpo's effective loss, dynamics, and success amplification. arXiv preprint arXiv:2503.06639, 2025
-
[27]
Ngrpo: Negative-enhanced group relative policy optimization
Nan, G., Chen, S., Huang, J., Lu, M., Wang, D., Xie, C., Xiong, W., Zeng, X., Zhou, Q., Li, Y., and Xu, X. Ngrpo: Negative-enhanced group relative policy optimization. arXiv preprint arXiv:2509.18851, 2025
-
[28]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. In NeurIPS, 2022
work page 2022
-
[29]
Maximizing confidence alone improves reasoning.arXiv preprint arXiv:2505.22660,
Prabhudesai, M., Chen, L., Ippoliti, A., Fragkiadaki, K., Liu, H., and Pathak, D. Maximizing confidence alone improves reasoning. arXiv preprint arXiv:2505.22660, 2025
-
[30]
Riedmiller, M., Hafner, R., Lampe, T., Neunert, M., Degrave, J., Van de Wiele, T., Mnih, V., Heess, N., and Springenberg, J. T. Learning by playing solving sparse reward tasks from scratch. In ICML, 2018
work page 2018
-
[31]
Hybrid group relative policy optimization: A multi-sample approach to enhancing policy optimization
Sane, S. Hybrid group relative policy optimization: A multi-sample approach to enhancing policy optimization. arXiv preprint arXiv:2502.01652, 2025
-
[32]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493,
Shen, H. On entropy control in llm-rl algorithms. arXiv preprint arXiv:2509.03493, 2025
-
[36]
Shihab, I. F., Akter, S., and Sharma, A. Detecting proxy gaming in rl and llm alignment via evaluator stress tests. arXiv preprint arXiv:2507.05619, 2025
-
[37]
TRL: Transformers Reinforcement Learning
von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., and Gallouédec, Q. TRL: Transformers Reinforcement Learning . https://github.com/huggingface/trl, 2020
work page 2020
-
[38]
SCOPE-RL: Stable and Quantitative Control of Policy Entropy in RL Post-Training
Wang, C., Li, Z., Bai, J., Zhang, Y., Cui, S., Zhao, Z., and Wang, Y. Arbitrary entropy policy optimization breaks the exploration bottleneck of reinforcement learning. arXiv preprint arXiv:2510.08141, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In NeurIPS, 2024
work page 2024
-
[40]
Xi, Z., Guo, X., Nan, Y., Zhou, E., Shen, J., Chen, W., Liu, J., Huang, J., Zhang, Z., Guo, H., et al. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adaptive clipping. arXiv preprint arXiv:2510.18927, 2025
-
[41]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Your group-relative advantage is biased
Yang, F., Chen, Z., Wang, X., Lu, X., Chai, J., Yin, G., Lin, W., Ma, S., Zhuang, F., Wang, D., Yang, Y., Li, J., and Ban, Y. Your group-relative advantage is biased. arXiv preprint arXiv:2601.08521, 2026
-
[43]
Dcpo: Dynamic clipping policy optimization
Yang, S., Dou, C., Guo, P., Lu, K., Ju, Q., Deng, F., and Xin, R. Dcpo: Dynamic clipping policy optimization. arXiv preprint arXiv:2509.02333, 2025 a
-
[44]
arXiv preprint arXiv:2505.12929 , year=
Yang, Z., Luo, X., Wang, Z., Han, D., He, Z., Li, D., and Xu, Y. Do not let low-probability tokens over-dominate in rl for llms. arXiv preprint arXiv:2505.12929, 2025 b
-
[45]
DAPO : An open-source LLM reinforcement learning system at scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al. DAPO : An open-source LLM reinforcement learning system at scale. In NeurIPS, 2026
work page 2026
-
[46]
Zhang, J. and Zuo, C. GRPO-LEAD: A difficulty-aware reinforcement learning approach for concise mathematical reasoning in language models. arXiv preprint arXiv:2504.09696, 2025
-
[47]
Zhang, X., Wen, S., Wu, W., and Huang, L. EDGE-GRPO: entropy-driven GRPO with guided error correction for advantage diversity. arXiv preprint arXiv:2507.21848, 2025 a
-
[48]
Scaf-grpo: Scaffolded group relative policy optimization for enhancing llm reasoning
Zhang, X., Wu, S., Zhu, Y., Tan, H., Yu, S., He, Z., and Jia, J. Scaf-grpo: Scaffolded group relative policy optimization for enhancing llm reasoning. arXiv preprint arXiv:2510.19807, 2025 b
-
[49]
Learning to Reason without External Rewards
Zhao, X., Kang, Z., Feng, A., Levine, S., and Song, D. Learning to reason without external rewards. arXiv preprint arXiv:2505.19590, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Zheng, C., Dang, K., Yu, B., Li, M., Jiang, H., et al. Stabilizing reinforcement learning with llms: Formulation and practices. arXiv preprint arXiv:2512.01374, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.