PGC: Peak-Guided Calibration for Generalizable AI-Generated Image Detection
Pith reviewed 2026-05-21 05:39 UTC · model grok-4.3
The pith
Peak-sensitive feature aggregation lets detectors recover subtle AI generation clues that global views bury.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PGC aggregates the most salient local features via a peak-sensitive mechanism that accentuates discriminative generation clues and then applies those clues to calibrate the global image representation, recovering patterns otherwise submerged in high-fidelity content and yielding higher accuracy across diverse generators.
What carries the argument
Peak-sensitive aggregation of local features that identifies and weights the strongest discriminative clues to calibrate the global decision.
If this is right
- Detectors maintain performance as commercial generators produce higher-fidelity outputs.
- No generator-specific fine-tuning is required for competitive results on varied models.
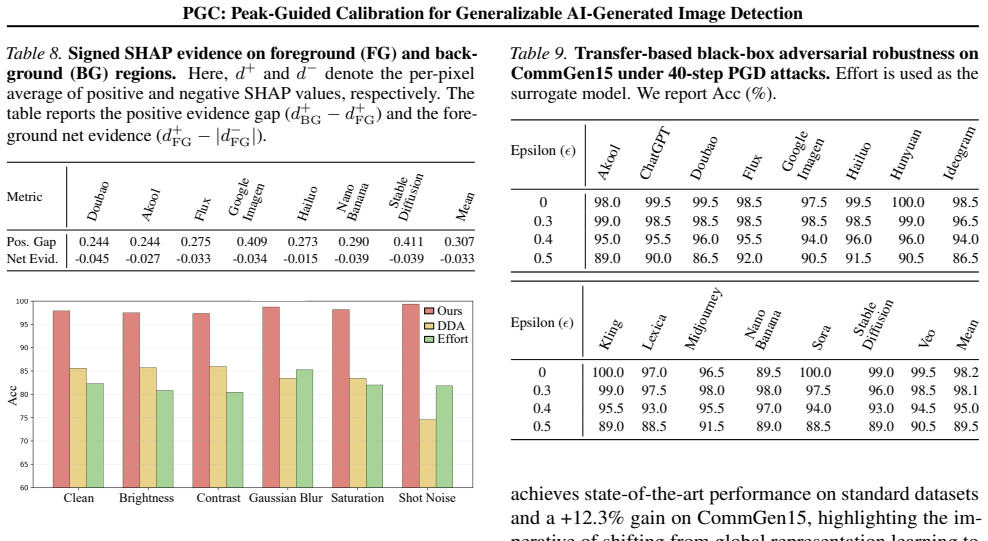
- Mean accuracy rises by 12.3 percent on the 15-model CommGen15 benchmark and by smaller margins on GenImage, AIGI, and UniversalFakeDetect.
- Local clue recovery becomes a viable alternative to purely global or post-hoc selection strategies.
Where Pith is reading between the lines
- The same peak-focusing idea could be tested on other tasks where faint local signals matter, such as deepfake video detection or medical image anomaly spotting.
- If peaks reliably mark generation artifacts, future work could examine whether those locations also appear in adversarial attacks or compression artifacts.
- The approach suggests that feature maps retain localized generator information even when overall image quality is high.
Load-bearing premise
The most reliable subtle generation clues sit at consistent peaks in the feature map and can be extracted and used for calibration without extra tuning or loss of surrounding context.
What would settle it
A new collection of AI-generated images from generators outside the training set and CommGen15 where PGC shows no accuracy gain over standard global-feature baselines.
Figures










read the original abstract
The rapid evolution of generative AI, from GANs to modern diffusion models, has resulted in increasingly subtle discriminative clues. These fine-grained signals are often overshadowed by dominant, high-fidelity image content (e.g., the main subject), limiting the reliability of existing detectors that predominantly rely on global representations. To address this challenge, we propose the Peak-Guided Calibration (PGC) framework. PGC introduces a novel strategy that aggregates salient features via a peak-focusing mechanism. Specifically, by employing a peak-sensitive aggregation that accentuates the most discriminative local clues, PGC leverages these critical signals to calibrate the global decision. This approach recovers subtle patterns that would otherwise be submerged in the global context. Furthermore, to better simulate real-world threats, we introduce the CommGen15 dataset, a challenging benchmark comprising samples from 15 commercial models. Extensive experiments demonstrate that PGC achieves state-of-the-art performance. Specifically, it improves mean accuracy by +12.3% on our CommGen15 dataset, and sets new records on standard benchmarks, including GenImage (+2.1%), AIGI (+3.5%), and UniversalFakeDetect (+1.7%). Code is available at https://github.com/xiaoyu6868/PGC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Peak-Guided Calibration (PGC), a framework for detecting AI-generated images that addresses the challenge of subtle discriminative clues being overshadowed by high-fidelity global image content. PGC employs a peak-sensitive aggregation mechanism to accentuate the most discriminative local features and uses these to calibrate the global decision. The authors also present the CommGen15 dataset, comprising images from 15 commercial generative models, to better reflect real-world threats. Experiments claim state-of-the-art results, including a +12.3% mean accuracy improvement on CommGen15 and smaller gains (+2.1% on GenImage, +3.5% on AIGI, +1.7% on UniversalFakeDetect).
Significance. If the peak-guided mechanism reliably surfaces generator-agnostic subtle artifacts without implicit dataset-specific tuning, the work would offer a meaningful advance in generalizable AIGC detection. The CommGen15 benchmark itself is a useful addition for evaluating detectors against commercial models.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The +12.3% accuracy gain on the newly introduced CommGen15 dataset substantially exceeds the modest gains on established benchmarks. This discrepancy raises a load-bearing concern for the central generalizability claim, as it is unclear whether the peak-sensitive aggregation recovers universal local clues or instead exploits magnitude patterns correlated with the specific 15 commercial generators used in CommGen15. Without ablations that isolate the peak mechanism on held-out generators or cross-dataset transfer tests, the reported SOTA on CommGen15 does not yet demonstrate the claimed generator-agnostic recovery of submerged clues.
- [§3] §3 (Method): The peak-focusing mechanism is described only at a high level ('accentuates the most discriminative local clues' via 'peak-sensitive aggregation'). No equations, pseudocode, or implementation details are supplied for peak detection, weighting, or how the local calibration is fused with the global representation. This absence prevents verification that the approach avoids post-hoc selection or generator-specific hyperparameters, which is required to support the generalizability premise.
minor comments (2)
- [Abstract] The abstract states that code is available at the provided GitHub link, but the manuscript does not include a reproducibility checklist, license information, or details on random seeds and hyperparameter ranges used in the reported experiments.
- [§4] Figure and table captions in the experimental section could more explicitly state the number of runs and standard deviations to allow readers to assess the stability of the reported percentage improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and indicate the revisions we will make to improve the presentation and support for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The +12.3% accuracy gain on the newly introduced CommGen15 dataset substantially exceeds the modest gains on established benchmarks. This discrepancy raises a load-bearing concern for the central generalizability claim, as it is unclear whether the peak-sensitive aggregation recovers universal local clues or instead exploits magnitude patterns correlated with the specific 15 commercial generators used in CommGen15. Without ablations that isolate the peak mechanism on held-out generators or cross-dataset transfer tests, the reported SOTA on CommGen15 does not yet demonstrate the claimed generator-agnostic recovery of submerged clues.
Authors: We appreciate the referee's concern about the disparity in reported gains. CommGen15 was intentionally constructed with images from 15 commercial models that produce higher-fidelity outputs and correspondingly subtler artifacts than the generators featured in GenImage, AIGI, or UniversalFakeDetect. The larger improvement on this more challenging benchmark is therefore expected under PGC's design, which targets recovery of local clues that are most easily overwhelmed in high-quality imagery. The fact that PGC still delivers consistent (if smaller) gains on the three established benchmarks, which use different model families and distributions, provides supporting evidence that the peak-guided mechanism is not merely fitting to the specific 15 generators. We nevertheless agree that explicit held-out generator ablations and additional cross-dataset transfer results would further strengthen the generalizability argument, and we will incorporate these analyses in the revised manuscript. revision: yes
-
Referee: [§3] §3 (Method): The peak-focusing mechanism is described only at a high level ('accentuates the most discriminative local clues' via 'peak-sensitive aggregation'). No equations, pseudocode, or implementation details are supplied for peak detection, weighting, or how the local calibration is fused with the global representation. This absence prevents verification that the approach avoids post-hoc selection or generator-specific hyperparameters, which is required to support the generalizability premise.
Authors: We acknowledge that the current description of the peak-focusing mechanism in §3 is high-level. In the revised manuscript we will expand this section to include the precise mathematical definitions of peak detection, the weighting function used in the aggregation, the fusion operation that calibrates the global representation, and pseudocode for the complete PGC pipeline. These additions will make explicit that the mechanism relies on a fixed, magnitude-based operation without generator-specific hyperparameters or post-hoc selection steps. revision: yes
Circularity Check
No significant circularity; empirical framework with performance claims on external benchmarks
full rationale
The paper introduces the PGC framework as a peak-sensitive aggregation strategy to recover subtle local generation artifacts and calibrate global decisions, with claims supported solely by empirical accuracy gains on CommGen15 (+12.3%) and standard benchmarks (GenImage +2.1%, AIGI +3.5%, UniversalFakeDetect +1.7%). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central premise is validated through direct comparison to baselines on held-out datasets rather than reducing to inputs by construction, making the work self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Peak responses in feature maps correspond to the most discriminative local clues for distinguishing AI-generated from real images
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Zres = τ log(1/N ∑ exp(sres_i / τ)) ... peak-focusing mechanism ... approximates the max operator
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Peak-Guided Calibration (PGC) framework ... aggregates salient features via a peak-focusing mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brock, A., Donahue, J., and Simonyan, K
Accessed: 2026-05-20. Brock, A., Donahue, J., and Simonyan, K. Large scale gan training for high fidelity natural image synthesis. InICLR,
work page 2026
-
[2]
Real-time deepfake detection in the real-world, 2024
Cavia, B., Horwitz, E., Reiss, T., and Hoshen, Y . Real- time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398,
-
[3]
Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., and Guo, B
Ac- cessed: 2026-05-20. Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., and Guo, B. Vector quantized diffusion model for text-to-image synthesis. InCVPR, pp. 10696–10706,
work page 2026
-
[4]
Miao, B., Li, C., Wang, X., Zhang, A., Sun, R., Wang, Z., and Zhu, Y
Accessed: 2026-05-20. Miao, B., Li, C., Wang, X., Zhang, A., Sun, R., Wang, Z., and Zhu, Y . Noise diffusion for enhancing semantic faithfulness in text-to-image synthesis. InCVPR, pp. 23575–23584,
work page 2026
-
[5]
Midjourney Team. Midjourney v6.1. https://www. midjourney.com/home. Accessed: 2026-05-20. MindSpore. Wukong. https://xihe.mindspore. cn/modelzoo/wukong,
work page 2026
-
[6]
Accessed: 2026-05-20. Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal,
work page 2026
-
[7]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Accessed: 2026-05-20. Wang, Q., Bai, X., Wang, H., Qin, Z., Chen, A., Li, H., Tang, X., and Hu, Y . Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Wu, Y ., Li, Z., Zheng, H., Wang, C., and Li, B
Accessed: 2026-05-20. Wu, Y ., Li, Z., Zheng, H., Wang, C., and Li, B. Infinite- id: Identity-preserved personalization via id-semantics decoupling paradigm. InECCV, pp. 279–296,
work page 2026
-
[9]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Yan, S., Li, O., Cai, J., Hao, Y ., Jiang, X., Hu, Y ., and Xie, W. A sanity check for ai-generated image detection. ICLR, 2025a. Yan, Z., Wang, J., Jin, P., Zhang, K.-Y ., Liu, C., Chen, S., Yao, T., Ding, S., Wu, B., and Yuan, L. Orthogonal subspace decomposition for generalizable ai-generated image detection.ICML, 2025b. Ye, H., Zhang, J., Liu, S., Han...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Yu, F., Seff, A., Zhang, Y ., Song, S., Funkhouser, T., and Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Patchcraft: Exploring texture patch for efficient ai-generated image detection
Zhong, N., Xu, Y ., Li, S., Qian, Z., and Zhang, X. Patchcraft: Exploring texture patch for efficient ai-generated image detection.arXiv preprint arXiv:2311.12397,
-
[12]
Standardization Pipeline.To mitigate confounding factors arising from heterogeneous resolutions and compression ar- tifacts, we implement a unified preprocessing pipeline. For video platforms, we apply a fixed-interval frame sampling strategy to ensure temporal diversity:Hunyuanis sampled at a rate of 1 frame per 30 frames, while all other platforms are s...
work page 2048
-
[13]
Type Platform Name Count Original Format Platform Link Data SourceImage ChatGPT 355 PNG, JPEGhttps://chatgpt.com/images https://prompthero.com/chatgpt-image-promptsFlux 2106 PNG, JPGhttps://bfl.ai/models https://prompthero.com/flux-promptsGoogle Imagen 1942 PNG, JPGhttps://deepmind.google/models/imagen/ https://prompthero.com/search?model=Google+ImagenIde...
work page 1942
-
[14]
2000 1024×1024BlendFace (Shiohara et al.,
work page 2000
-
[15]
9000 1024×1024Midjourney-V6 (Midjourney Team) 6000 2048×2048Glide (Nichol et al.,
work page 2048
-
[16]
2000 256×256LDM (200 steps) (Rombach et al.,
work page 2000
-
[17]
2000 256×256LDM (200 steps w/cfg) (Rombach et al.,
work page 2000
-
[18]
2000 256×256LDM (100 steps) (Rombach et al.,
work page 2000
-
[19]
2000 256×256Glide (100-27) (Nichol et al.,
work page 2000
-
[20]
2000 256×256Glide (50-27) (Nichol et al.,
work page 2000
-
[21]
2000 256×256Glide (100-10) (Nichol et al.,
work page 2000
-
[22]
2000 256×256Dalle (Ramesh et al.,
work page 2000
-
[23]
Outputs are MP4, with typical resolutions including1088×1888, 1440×1440, and1920×1080
2000 256×256 15 PGC: Peak-Guided Calibration for Generalizable AI-Generated Image Detection Kling (v1.6).Kling AI (v1.6) supports multimodally condi- tioned video generation and enhancement. Outputs are MP4, with typical resolutions including1088×1888, 1440×1440, and1920×1080. Veo (Veo-2 / Veo-3; Google DeepMind).The Veo se- ries supports text- and refere...
work page 2000
-
[24]
As shown in Table 14, there is a clear inverse correlation between patch size and detection accuracy
Given the input resolution of224×224, a smaller patch size yields a denser feature grid (e.g., p= 14 results in 16× 16 tokens). As shown in Table 14, there is a clear inverse correlation between patch size and detection accuracy. The standard 14×14 setting achieves the best performance (98.3%), while increasing p to 112 degrades accuracy to 92.1%. This co...
work page 2025
-
[25]
as the training set. Method Ref Akool ChatGPT Doubao Flux Google Imagen Hailuo Hunyuan Ideogram Acc AP Acc AP Acc AP Acc AP Acc AP Acc AP Acc AP Acc AP NPR CVPR 2024 51.3 79.3 40.3 35.9 51.6 77.3 44.0 36.7 42.3 36.2 48.4 60.5 47.5 60.7 40.9 34.6 B-Free CVPR 2025 75.0 90.5 66.1 81.6 65.2 81.7 79.2 92.0 78.9 91.2 83.5 93.8 74.0 93.3 83.3 93.3 AIDE ICLR 2025...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.