To Select or not to Select, that is the Question: Distilling Robot Skill Prediction into a Small Ensemble
Pith reviewed 2026-05-21 03:51 UTC · model grok-4.3
The pith
A small ensemble of sentence encoders outperforms much larger LLMs in predicting robot skills from tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
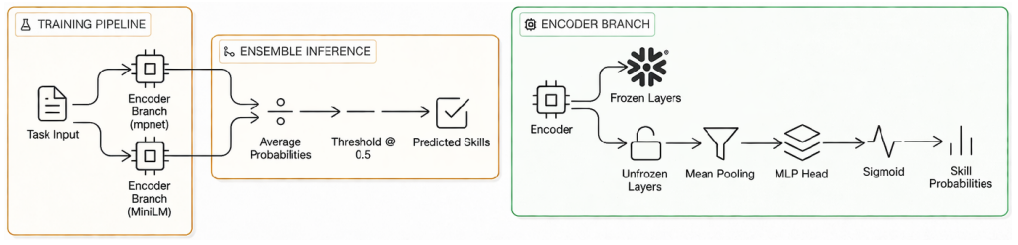
Trained on a synthetic task-to-skill dataset built with LLM-assisted generation and targeted auditing, a 133-million-parameter ensemble of mpnet and MiniLM sentence encoders achieves 83.5 percent accuracy matching tasks to required physical capabilities. Under identical zero-shot prompts the same ensemble surpasses Kimi K2 (72.0 percent), GPT-OSS-120B (71.5 percent), and Llama-4-Scout-17B (69.0 percent). The work therefore claims that small specialized models suffice for fleet-level task routing when the robot skill taxonomy is held fixed.
What carries the argument
The ensemble of two fine-tuned sentence encoders (mpnet plus MiniLM) that classifies task text into a fixed set of physical capabilities including fly, wheels, legs, surface water, under water, and hands.
If this is right
- Robot fleets can route tasks with lightweight models that run on modest hardware instead of querying large language models.
- Task-to-skill accuracy improves when training data is tailored to a fixed capability taxonomy rather than relying on general pretraining.
- Computational cost and latency for fleet coordination drop because the matching step no longer requires a trillion-parameter model.
- New robot types can be added by extending the taxonomy and retraining the small ensemble rather than retraining an entire large language model.
Where Pith is reading between the lines
- Periodic evaluation against real executed tasks could reveal whether the synthetic labels drift over time and suggest a retraining schedule.
- The same distillation approach might transfer to other robotics decisions such as estimating energy cost or required payload once suitable synthetic labels are created.
- Pairing the skill predictor with a simulator that tests whether a chosen robot can actually complete the task would close the loop between prediction and verification.
Load-bearing premise
The synthetic task-to-skill dataset generated and audited with LLM assistance faithfully represents real-world task requirements and the fixed skill taxonomy without systematic biases or coverage gaps.
What would settle it
Running the trained ensemble on a fresh collection of task descriptions written and labeled by human robotics experts or end users and measuring whether accuracy remains near 83.5 percent or falls substantially.
Figures


read the original abstract
As robot fleets become more heterogeneous, including humanoids, rovers, quadrupeds, and drones, selecting the right robot for a task becomes a core systems problem. We study robot skill prediction: mapping a natural-language task description to the physical capabilities required to execute it, such as fly, wheels, legs, surface water, under water and hands. Since labelled data that maps natural-language task descriptions to robot's physical capabilities does not exist, we construct a synthetic task-to-skill dataset using LLM-assisted generation and targeted label auditing. Trained on this data, a ~133M-parameter ensemble of two fine-tuned sentence encoders (mpnet + MiniLM) reaches 83.5% task-to-skill matching on a stratified 200 task dataset, outperforming Kimi K2 (1T MoE) at 72.0%, GPT-OSS-120B at 71.5%, and Llama-4-Scout-17B at 69.0% under the same zero-shot prompt. These results suggest that, for fixed robot skill taxonomies, small specialized models trained on synthetic data can outperform much larger general-purpose LLMs for fleet-level task routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses robot skill prediction for heterogeneous fleets by mapping natural language task descriptions to required physical capabilities (e.g., fly, wheels, legs). Due to lack of labeled data, they generate a synthetic dataset using LLM-assisted generation and targeted auditing. A ~133M-parameter ensemble of fine-tuned sentence encoders (mpnet + MiniLM) is trained and achieves 83.5% accuracy on a stratified 200-task held-out set, outperforming zero-shot large models including Kimi K2 (72.0%), GPT-OSS-120B (71.5%), and Llama-4-Scout-17B (69.0%). The authors conclude that small specialized models can outperform larger general LLMs for this task when the skill taxonomy is fixed.
Significance. Should the synthetic dataset prove representative of real-world robot tasks, the result would demonstrate the viability of distilling complex reasoning into compact models for practical robotics applications like fleet routing. This could reduce computational costs in deployment. The empirical comparison provides concrete numbers, but the significance is tempered by the unvalidated nature of the training and test data.
major comments (2)
- [Dataset Generation and Auditing] The construction of the synthetic task-to-skill dataset relies entirely on LLM-assisted generation and auditing without reported independent human validation or cross-check against real robot execution logs. Given that the headline 83.5% accuracy and superiority over large LLMs is measured on this same synthetic distribution, any systematic bias in the LLM-generated labels (e.g., over- or under-representation of certain capabilities) would directly undermine the performance claims and the generalization argument. An external validation step, such as human expert labeling of a random subset, is required to establish the reliability of the reported metrics.
- [Experimental Evaluation] The abstract and results report accuracy on a 200-task stratified test set but provide no details on statistical significance testing, confidence intervals, or variance across multiple runs. With a relatively small test set size, it is unclear whether the 83.5% vs. 72% gap is statistically meaningful or could be due to sampling variability in the synthetic data.
minor comments (2)
- [Notation and Terminology] The skill taxonomy (fly, wheels, legs, surface water, under water, hands) is introduced without a formal definition or table listing all possible skills and their precise meanings, which could affect reproducibility.
- [Model Details] The ensemble is described as 'mpnet + MiniLM' but the exact fine-tuning procedure, loss function, and how the two encoders are combined (e.g., averaging embeddings or separate classifiers) is not elaborated in the provided text.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and outline the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset Generation and Auditing] The construction of the synthetic task-to-skill dataset relies entirely on LLM-assisted generation and auditing without reported independent human validation or cross-check against real robot execution logs. Given that the headline 83.5% accuracy and superiority over large LLMs is measured on this same synthetic distribution, any systematic bias in the LLM-generated labels (e.g., over- or under-representation of certain capabilities) would directly undermine the performance claims and the generalization argument. An external validation step, such as human expert labeling of a random subset, is required to establish the reliability of the reported metrics.
Authors: We agree that the absence of independent human validation is a limitation of the current synthetic dataset construction. In the revised manuscript we will add a new subsection reporting human expert labeling of a randomly sampled subset of 100 tasks. Two domain experts will independently annotate the required skills for each task description; we will report inter-annotator agreement (Cohen's kappa) and agreement with the original synthetic labels. This analysis will be placed in Section 3 and referenced in the discussion of generalization. revision: yes
-
Referee: [Experimental Evaluation] The abstract and results report accuracy on a 200-task stratified test set but provide no details on statistical significance testing, confidence intervals, or variance across multiple runs. With a relatively small test set size, it is unclear whether the 83.5% vs. 72% gap is statistically meaningful or could be due to sampling variability in the synthetic data.
Authors: We acknowledge that the current manuscript lacks statistical characterization of the reported accuracies. In the revision we will add bootstrap resampling (1,000 iterations) to compute 95% confidence intervals for all models on the 200-task test set. We will also apply McNemar's test to evaluate the statistical significance of the performance differences between our ensemble and each baseline LLM. These results, together with the exact methodology, will be included in the updated experimental section. revision: yes
Circularity Check
No circularity: empirical evaluation on held-out synthetic test set is independent of model construction
full rationale
The paper generates a synthetic task-to-skill dataset via LLM assistance and auditing, fine-tunes a small ensemble of sentence encoders on a training split, and reports accuracy on a stratified held-out test split while comparing zero-shot performance of external large models under identical prompting. This pipeline measures generalization to unseen synthetic examples and does not contain any self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central accuracy claim to the inputs by construction. The result remains a standard empirical benchmark even if the synthetic labels carry unvalidated biases.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-assisted generation plus targeted auditing produces a high-quality labeled dataset that generalizes to real tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
construct a synthetic task-to-skill dataset using LLM-assisted generation and targeted label auditing... ~133M-parameter ensemble of two fine-tuned sentence encoders (mpnet + MiniLM) reaches 83.5% task-to-skill matching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GenSim: Generating Robotic Simulation Tasks Via Large Language Models,
L. Wang, Y . Ling, Z. Yuan, M. Shridhar, C. Bao, Y . Qinet al., “GenSim: Generating Robotic Simulation Tasks Via Large Language Models,” inInternational Conference on Learning Representations (ICLR), 2024, arXiv:2310.01361
-
[2]
MimicGen: A Data Generation System For Scalable Robot Learning Using Human Demonstrations,
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan et al., “MimicGen: A Data Generation System For Scalable Robot Learning Using Human Demonstrations,” inProceedings of The 7th Conference on Robot Learning (CoRL), ser. Proceedings of Machine Learning Research, vol. 229, 2023, pp. 1820–1864
work page 2023
-
[3]
Few-Shot Object Grounding And Mapping For Natural Language Robot Instruction Following,
V . Blukis, R. Knepper, and Y . Artzi, “Few-Shot Object Grounding And Mapping For Natural Language Robot Instruction Following,” inProceedings of the 2020 Conference on Robot Learning, ser. Proceedings of Machine Learning Research, vol. 155, 2021, pp. 1829– 1854
work page 2020
-
[4]
SayPlan: Grounding Large Language Models Using 3D Scene Graphs For Scalable Robot Task Planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Sunder- hauf, “SayPlan: Grounding Large Language Models Using 3D Scene Graphs For Scalable Robot Task Planning,” inProceedings of The 7th Conference on Robot Learning (CoRL), ser. Proceedings of Machine Learning Research, vol. 229, 2023, pp. 23–72
work page 2023
-
[5]
Sentence-BERT: Sentence Embed- dings Using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embed- dings Using Siamese BERT-Networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, Nov. 2019, pp. 3982–3992
work page 2019
-
[6]
K. Song, X. Tan, T. Qin, J. Lu, and T. Liu, “MPNet: Masked And Permuted Pre-Training For Language Understanding,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 16 857–16 867, arXiv:2004.09297
-
[7]
MINILM: Deep Self-Attention Distillation for Task- Agnostic Compression of Pre-Trained Transformers
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “MiniLM: Deep Self-Attention Distillation For Task-Agnostic Com- pression Of Pre-Trained Transformers,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), vol. 33, 2020, pp. 5776–5788, arXiv:2002.10957
-
[8]
SMART-LLM: Smart Multi-Agent Robot Task Planning Using Large Language Mod- els,
S. S. Kannan, V . L. N. Venkatesh, and B.-C. Min, “SMART-LLM: Smart Multi-Agent Robot Task Planning Using Large Language Mod- els,”arXiv preprint arXiv:2309.10062, 2023
-
[9]
Large Language Models For Robot Task Allocation,
S. A. Prieto and B. G. de Soto, “Large Language Models For Robot Task Allocation,” inICRA 2024 Future of Construction Workshop Papers, 2024, pp. 17–20
work page 2024
- [10]
-
[11]
A. Singh, A. P. Adam Fry, A. Tart, A. Ganeshet al., “Introducing GPT-5,” 2025
work page 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Songet al., “DeepSeek-R1: In- centivizing Reasoning Capability In Large Language Models Via Reinforcement Learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Kimi k2: Open agentic intelligence,
Y . Bai, Y . Bao, Y . Charles, C. Chen, G. Chenet al., “Kimi k2: Open agentic intelligence,” 2026
work page 2026
-
[14]
Gpt-oss-120b & gpt- oss-20b model card,
S. Agarwal, L. Ahmad, J. Ai, S. Altmanet al., “Gpt-oss-120b & gpt- oss-20b model card,” 2025
work page 2025
-
[15]
The Llama 4 Herd: Llama 4 Scout And Llama 4 Maverick,
Meta AI, “The Llama 4 Herd: Llama 4 Scout And Llama 4 Maverick,” Apr. 2025
work page 2025
- [16]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.