SR-Ground: Image Quality Grounding for Super-Resolved Content
Pith reviewed 2026-05-21 05:31 UTC · model grok-4.3
The pith
SR-Ground dataset trains quality models to locate specific artifacts in super-resolved images at the pixel level.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
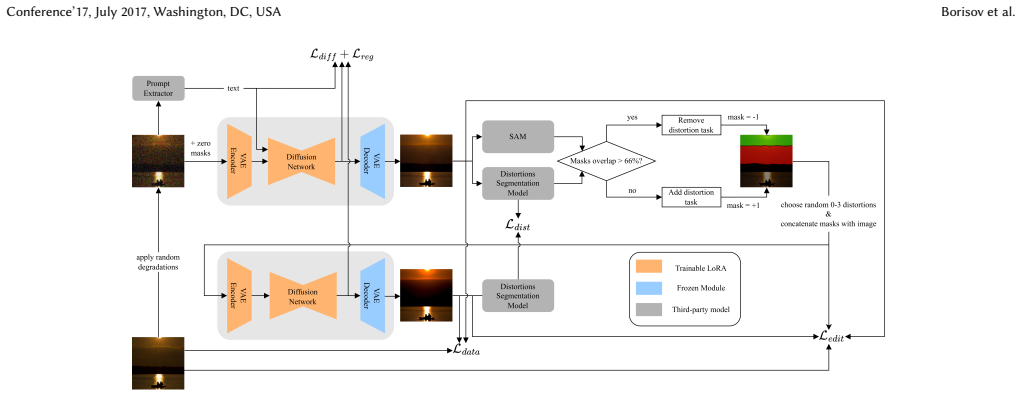
The central claim is that a large-scale dataset SR-Ground, built from state-of-the-art super-resolution outputs and equipped with crowdsourced pixel-level segmentations across six artifact types, enables IQA models trained with grounding to achieve stronger performance on downstream tasks while also supporting a fine-tuning procedure that measurably reduces perceptible artifacts in final SR images.
What carries the argument
The SR-Ground dataset of pixel-level artifact segmentations for six categories, which supplies the location-specific supervision needed to turn holistic IQA scores into grounded, interpretable predictions.
If this is right
- IQA models gain the ability to distinguish among artifact types rather than returning only a single quality number.
- A grounding-based fine-tuning loop can be applied to existing SR models to suppress specific visible flaws without retraining from scratch.
- Future SR methods can be evaluated and improved against explicit per-artifact maps instead of relying solely on global metrics.
Where Pith is reading between the lines
- The same grounding strategy could be extended to other generative tasks such as video super-resolution or image synthesis to target correction of particular failure modes.
- SR model developers might incorporate SR-Ground-style supervision directly into their training objectives to minimize artifact formation at the source.
- Crowdsourced refinement pipelines like the one used here offer a scalable way to create similar datasets for emerging artifact types in new SR architectures.
Load-bearing premise
The crowdsourced pixel-level annotations accurately mark the locations of artifacts that actually matter to human perception across the range of tested super-resolution models.
What would settle it
A controlled comparison in which IQA models trained on SR-Ground grounding labels show no improvement over standard non-grounded models when tested on held-out super-resolved images for artifact localization accuracy or quality prediction.
Figures





read the original abstract
Super-Resolution (SR) has advanced rapidly in recent years, with diffusion-based models achieving unprecedented fidelity at the cost of introducing new types of visual artifacts. While existing Image Quality Assessment (IQA) methods provide holistic quality scores, they lack interpretability and fail to distinguish between different artifact types arising from modern SR approaches. To address this gap, we introduce SR-Ground, a large-scale dataset specifically designed for fine-grained artifact segmentation in super-resolved images. The dataset comprises images processed by a diverse set of state-of-the-art SR models, with pixel-level annotations for multiple artifact categories. We conduct a large-scale crowdsourcing study involving 1,062 participants to validate and refine automatically generated segmentations, resulting in a high-quality dataset of 63,000 images spanning 6 distinct artifact types. We demonstrate that training IQA models with grounding capabilities on SR-Ground significantly improves performance on downstream tasks. Furthermore, we introduce a fine-tuning pipeline that leverages our grounding model to reduce perceptible artifacts in SR outputs, showcasing the practical utility of our dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SR-Ground, a dataset of 63,000 super-resolved images spanning diverse state-of-the-art SR models and annotated at the pixel level for six artifact categories. Annotations are produced by automatic generation followed by refinement from 1,062 crowd participants. The authors claim that IQA models trained with grounding capabilities on SR-Ground achieve improved performance on downstream tasks and that a fine-tuning pipeline leveraging the resulting grounding model reduces perceptible artifacts in SR outputs.
Significance. If the central claims hold, the work would provide a valuable resource for interpretable, fine-grained IQA tailored to modern diffusion-based SR artifacts, enabling more targeted mitigation strategies. The scale of the dataset, diversity of SR models, and use of large-scale crowdsourcing represent concrete strengths that could support reproducible progress in perceptual SR evaluation.
major comments (2)
- [§3.2] §3.2 (Crowdsourcing and Annotation Refinement): No inter-annotator agreement statistics (e.g., mean IoU, Cohen's kappa, or pixel-wise consistency across workers) or correlation with expert labels are reported for the refinement of the automatically generated segmentations. This is load-bearing for the claim that the 63k annotations accurately capture perceptually salient artifact locations across the six categories, as downstream IQA gains and artifact reduction could otherwise reflect annotation biases rather than true perceptual grounding.
- [§4] §4 (Experiments): The reported improvements from training IQA models on SR-Ground lack explicit baseline comparisons, ablation on annotation quality, or error analysis showing robustness across SR model types; without these, it is unclear whether the gains are attributable to the grounding annotations or to other factors in the training pipeline.
minor comments (3)
- [Abstract] The abstract states that training 'significantly improves performance' without referencing specific quantitative metrics or tables; ensure all such claims in the abstract are directly tied to results presented in the main body.
- [§3.1] Notation for the six artifact categories is introduced but could be more explicitly linked to visual examples in the figures to aid reader understanding of the grounding task.
- [§5] The fine-tuning pipeline description would benefit from a clear diagram or pseudocode to illustrate how the grounding model is integrated with the SR output refinement step.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. Revisions have been made to strengthen the validation of the dataset and the experimental analysis.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Crowdsourcing and Annotation Refinement): No inter-annotator agreement statistics (e.g., mean IoU, Cohen's kappa, or pixel-wise consistency across workers) or correlation with expert labels are reported for the refinement of the automatically generated segmentations. This is load-bearing for the claim that the 63k annotations accurately capture perceptually salient artifact locations across the six categories, as downstream IQA gains and artifact reduction could otherwise reflect annotation biases rather than true perceptual grounding.
Authors: We agree that explicit inter-annotator agreement statistics are necessary to substantiate the quality of the refined annotations. In the revised version, we have expanded §3.2 to include mean IoU and pixel-wise consistency metrics computed across multiple workers on overlapping annotations. We have also added results from a correlation analysis against a small set of expert-annotated images, which shows strong alignment with perceptual artifact locations. These additions directly address the concern regarding potential annotation biases. revision: yes
-
Referee: [§4] §4 (Experiments): The reported improvements from training IQA models on SR-Ground lack explicit baseline comparisons, ablation on annotation quality, or error analysis showing robustness across SR model types; without these, it is unclear whether the gains are attributable to the grounding annotations or to other factors in the training pipeline.
Authors: We acknowledge the need for more rigorous controls in the experimental section. The revised §4 now includes explicit comparisons against standard non-grounded IQA baselines, an ablation study contrasting models trained on automatic versus crowd-refined annotations, and a per-SR-model error analysis (covering diffusion-based and other architectures). These additions confirm that the observed gains in downstream tasks and artifact reduction are attributable to the grounding annotations provided by SR-Ground rather than other pipeline elements. revision: yes
Circularity Check
No circularity: empirical dataset and training results are self-contained
full rationale
The paper introduces SR-Ground as a crowdsourced dataset of 63k images with pixel-level annotations across 6 artifact categories, then reports empirical gains from training IQA models on it and from a fine-tuning pipeline. No derivations, equations, or predictions are present that reduce by construction to author-defined inputs or self-citations. Central claims rest on external crowdsourcing (1,062 participants) and standard model training, which are independent of any self-referential definitions or fitted parameters renamed as predictions. This is the expected non-finding for a dataset-plus-application paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Crowdsourced annotations after refinement accurately reflect perceptible artifact locations
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct SR-Ground through an iterative data generation and refinement pipeline, combining automated annotation with large-scale crowdsourced validation... prominence of each artifact as the fraction of annotators who confirm its presence.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an SR-guided training pipeline that leverages grounding predictions to mitigate artifact formation during training, using Mask2Former-based framework.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lorenzo Agnolucci, Leonardo Galteri, Marco Bertini, and Alberto Del Bimbo
-
[2]
In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
ARNIQA: Learning Distortion Manifold for Image Quality Assessment. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 189–198
-
[3]
Nisar Ahmed and S. Asif. 2022. BIQ2021: a large-scale blind image quality assessment database.Journal of Electronic Imaging31, 5 (2022), 053010
work page 2022
-
[4]
Evgeney Bogatyrev, Ivan Molodetskikh, and Dmitriy S. Vatolin. 2024. SR+Codec: a Benchmark of Super-Resolution for Video Compression Bitrate Reduction. In 35th British Machine Vision Conference 2024, BMVC 2024, Glasgow, UK, November 25-28, 2024. BMVA. https://papers.bmvc2024.org/0959.pdf
work page 2024
-
[5]
Borisov, Artem and Bogatyrev, Evgeney, Molodetskikh, Ivan, and Vatolin, Dmitriy. 2026. MSU Super-Resolution Quality Assessment Benchmark. https: //videoprocessing.ai/benchmarks/super-resolution-metrics.html. Online; ac- cessed 2026-03-28
work page 2026
-
[6]
Chaofeng Chen, Jiadi Mo, Jingwen Hou, Haoning Wu, Liang Liao, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2024. TOPIQ: A Top-Down Approach From Seman- tics to Distortions for Image Quality Assessment.IEEE Transactions on Image Processing33 (2024), 2404–2418. doi:10.1109/TIP.2024.3378466
-
[7]
Chaofeng Chen, Sensen Yang, Haoning Wu, Liang Liao, Zicheng Zhang, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2024. Q-ground: Image quality grounding with large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia. 486–495
work page 2024
- [8]
-
[9]
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. 2022. Masked-attention mask transformer for universal image segmen- tation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1290–1299
work page 2022
-
[10]
Ji-Hwan Choe, Tae-Uk Jeong, Hyunsoo Choi, and Eun-Jae Lee. 2007. Subjective Video Quality Assessment Methods for Multimedia Applications.Journal of Broadcast Engineering12, 2 (2007). doi:10.5909/JBE.2007.12.2.177
-
[11]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. 2020. Image Quality Assessment: Unifying Structure and Texture Similarity.CoRRabs/2004.07728 (2020). https://arxiv.org/abs/2004.07728
-
[12]
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy S Ren, Chunle Guo, and Chongyi Li. 2025. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision. 18948–18958
work page 2025
-
[13]
Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, and Zhou Wang. 2020. Perceptual quality assessment of smartphone photography. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3677–3686
work page 2020
-
[14]
Vlad Hosu, Hanhe Lin, Tamas Sziranyi, and Dietmar Saupe. 2020. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Transactions on Image Processing29 (2020), 4041–4056
work page 2020
-
[15]
Xiaozhong Ji, Yun Cao, Ying Tai, Chengjie Wang, Jilin Li, and Feiyue Huang
-
[16]
InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Real-World Super-Resolution via Kernel Estimation and Noise Injection. InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
-
[17]
Ziheng Jia, Zicheng Zhang, Jiaying Qian, Haoning Wu, Wei Sun, Chunyi Li, Xiaohong Liu, Weisi Lin, Guangtao Zhai, and Xiongkuo Min. 2025. Vqa2: visual question answering for video quality assessment. InProceedings of the 33rd ACM International Conference on Multimedia. 6751–6760
work page 2025
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. 2023. Segment Anything.arXiv:2304.02643(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Eric C Larson and Damon M Chandler. 2010. Most apparent distortion: full- reference image quality assessment and the role of strategy.Journal of Electronic Imaging19, 1 (2010), 011006
work page 2010
- [20]
-
[21]
Jie Liang, Hui Zeng, and Lei Zhang. 2022. Details or artifacts: A locally discrimi- native learning approach to realistic image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5657–5666
work page 2022
-
[22]
Jie Liang, Hui Zeng, and Lei Zhang. 2022. Details or Artifacts: A Locally Discrim- inative Learning Approach to Realistic Image Super-Resolution. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition
work page 2022
-
[23]
Wenjie Liao, Haotian Fan, Yifang Xu, Meijia Song, Qiufang Ma, Shuhao Han, Chunle Guo, Chongyi Li, Jianhui Sun, Xinli Yue, Yuhao Xie, Tao Shao, Zhaoran Zhao, Xinjun Ma, Lu Liu, Chunlei Cai, Qiang Hu, Shaocheng Shen, Huiyu Duan, Tianxiao Ye, Xiaoyun Zhang, Hong Yi, Yupeng Zhang, Linnan Zhao, Xinyi You, Ziang Li, Chenhao Qiu, Alireza Talebpour, Azadeh Mansou...
work page 2025
-
[24]
Kede Ma, Zhengfang Duanmu, Qingbo Wu, Zhou Wang, Hongwei Yong, Hongliang Li, and Lei Zhang. 2017. Waterloo Exploration Database: New Chal- lenges for Image Quality Assessment Models.IEEE Transactions on Image Pro- cessing26, 2 (2017), 1004–1016. doi:10.1109/TIP.2016.2631888
- [25]
-
[26]
Naila Murray, Luca Marchesotti, and Florent Perronnin. 2012. AVA: A large-scale database for aesthetic visual analysis. In2012 IEEE conference on computer vision and pattern recognition. IEEE, 2408–2415
work page 2012
-
[27]
Go Ohtani, Ryu Tadokoro, Ryosuke Yamada, Yuki M. Asano, Iro Laina, Christian Rupprech, Nakamasa Inoue, Rio Yokota, Hirokatsu Kataoka, and Yoshimitsu Aoki
-
[28]
In Proceedings of the European Conference on Computer Vision (ECCV)
Rethinking Image Super-Resolution from Training Data Perspectives. In Proceedings of the European Conference on Computer Vision (ECCV)
-
[29]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2024. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. InInternational Conference on Learning Representations, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (Eds.), Vol. 2024. 1862–1874. http...
work page 2024
-
[30]
Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen. 2018. PieAPP: Perceptual Image-Error Assessment Through Pairwise Preference. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2018
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML
work page 2021
-
[32]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
work page 2022
-
[33]
Hamid R Sheikh, Muhammad F Sabir, and Alan C Bovik. 2006. A statistical evaluation of recent full reference image quality assessment algorithms.IEEE Transactions on Image Processing15, 11 (2006), 3440–3451
work page 2006
-
[34]
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. 2021. Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data. InInter- national Conference on Computer Vision Workshops (ICCVW)
work page 2021
-
[35]
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Kaixin Xu, Chunyi Li, Jingwen Hou, Guangtao Zhai, Geng Xue, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2023. Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models. arXiv:2311.06783 [cs.CV]
-
[36]
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al . 2023. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [37]
-
[38]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. 2021. SegFormer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems34 (2021), 12077–12090
work page 2021
-
[39]
Liangbin Xie, Xintao Wang, Xiangyu Chen, Gen Li, Ying Shan, Jiantao Zhou, and Chao Dong. 2023. DeSRA: Detect and Delete the Artifacts of GAN-based Real-World Super-Resolution Models. (2023)
work page 2023
-
[40]
Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. 2024. Pixel- aware stable diffusion for realistic image super-resolution and personalized stylization. InEuropean conference on computer vision. Springer, 74–91
work page 2024
- [41]
- [42]
-
[43]
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. 2021. Designing a Practical Degradation Model for Deep Blind Image Super-Resolution. InIEEE International Conference on Computer Vision. 4791–4800
work page 2021
-
[44]
Leheng Zhang, Yawei Li, Xingyu Zhou, Xiaorui Zhao, and Shuhang Gu. 2024. Transcending the Limit of Local Window: Advanced Super-Resolution Trans- former with Adaptive Token Dictionary. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2856–2865
work page 2024
-
[45]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[46]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595. Conference’17, July 2017, Washington, DC, USA Borisov et al
work page 2017
- [47]
-
[48]
Libo Zhu, Jianze Li, Haotong Qin, Yulun Zhang, Yong Guo, and Xiaokang Yang
-
[49]
PassionSR: Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution. InCVPR
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.