How Much Online RL is Enough? Informative Rollouts for Offline Preference Optimization in RLVR
Pith reviewed 2026-05-21 06:19 UTC · model grok-4.3
The pith
Short GRPO warm-up followed by offline DPO outperforms full online GRPO on reasoning tasks at lower compute cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
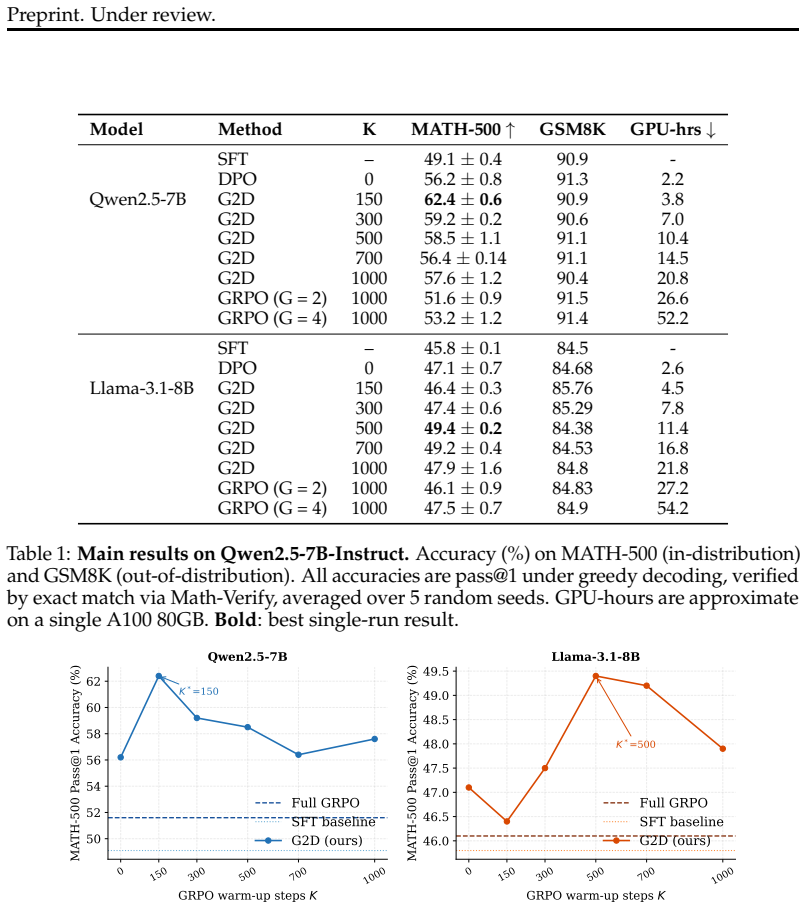
Moderate GRPO warm-up generates rollouts with calibrated uncertainty that yield stronger contrastive signals, allowing a static preference dataset to support offline DPO that surpasses full online GRPO on MATH-500 at roughly four times lower compute.
What carries the argument
The G2D three-stage pipeline that performs limited GRPO warm-up to create an informative static preference dataset before offline DPO training.
If this is right
- Performance in RLVR depends primarily on the informativeness of preference data rather than the total number of online steps or pairs.
- Excessive warm-up produces overconfident policies whose rollouts supply weaker training signals for DPO.
- Offline methods can close or reverse the usual gap with online RL when the initial dataset is calibrated for difficulty.
- The offline-online distinction in RLVR reduces to a data-quality problem solvable with short online phases.
Where Pith is reading between the lines
- Hybrid online-offline schedules may cut compute in other reasoning or alignment settings that currently rely on long online RL.
- Optimal warm-up length likely varies with model size and task, pointing toward adaptive calibration methods.
- The emphasis on informativeness suggests new techniques for curating preference data without additional online steps.
Load-bearing premise
That moderate warm-up improves performance because it produces rollouts with calibrated uncertainty that create stronger contrastive signals rather than from other unmeasured factors in the setup.
What would settle it
Experiments that measure rollout uncertainty and contrast strength across K values and find no systematic difference tied to moderate warm-up, or that the performance advantage disappears when holding other variables fixed.
Figures


read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for reasoning in language models, with GRPO as its primary example. However, GRPO requires continuous online rollout generation, making it computationally expensive and difficult to scale. While Direct Preference Optimization (DPO) offers a stable and efficient offline alternative, it is typically expected to underperform w.r.t. online RL methods such as GRPO when trained on rollouts from a cold supervised fine-tuned (SFT) policy. We introduce G2D (GRPO to DPO)}, a three-stage pipeline that performs a short GRPO warm-up, constructs a static preference dataset, and fine-tunes a model offline with DPO. Across a set of values of the number of online steps (K) in GRPO on Qwen2.5-7B and Llama-3.1-8B, we find that offline DPO with moderate warm-up matches or outperforms GRPO at substantially lower compute cost in our setting. On Qwen2.5-7B, G2D at K=150 achieves 62.4% on MATH-500, outperforming GRPO (51.6%) by 10.8% at ~4x lower compute. On Llama-3.1-8B, G2D at K=500 achieves 49.4%, surpassing GRPO in our experimental setting. We show that performance is not governed by the number of preference pairs, which does not vary much w.r.t. K, but by their informativeness. Moderate warm-up produces rollouts with calibrated uncertainty, yielding stronger contrastive signal, while excessive warm-up leads to overconfident policies and less informative data. Our results recast the offline-online gap in RLVR as primarily a data informativeness problem, and identify short online RL warm-up with appropriate difficulty calibration of the fine-tuning dataset as a compute-efficient alternative to online RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces G2D, a three-stage pipeline that performs a short GRPO warm-up for K online steps, constructs a static preference dataset from the resulting rollouts, and then applies offline DPO. Experiments on Qwen2.5-7B and Llama-3.1-8B across multiple K values show that moderate warm-up (e.g., K=150 on Qwen2.5-7B) yields DPO models that match or exceed full GRPO performance (62.4% vs 51.6% on MATH-500) at roughly 4x lower compute; the authors attribute this to rollout informativeness rather than the number of preference pairs, which remains roughly constant with K.
Significance. If the central experimental findings hold under more rigorous controls, the work offers a practical, lower-cost route to strong RLVR performance by replacing continuous online rollouts with a short warm-up plus offline optimization. It reframes the offline-online performance gap as primarily a data-informativeness issue and supplies concrete evidence that moderate online exposure can produce higher-quality contrastive signals than either cold-start or fully converged online policies.
major comments (2)
- [Abstract] Abstract and experimental sections: the claim that 'performance is governed by their informativeness' and that 'moderate warm-up produces rollouts with calibrated uncertainty, yielding stronger contrastive signal' rests on the indirect observations that pair count is stable across K and that accuracy peaks at moderate K before declining. No explicit informativeness metric (policy entropy, reward variance, or preference-margin distribution) or ablation that holds K fixed while varying uncertainty is reported, leaving open the possibility that gains arise from unmeasured factors such as changes in rollout correctness rate or group diversity.
- [Experimental results] Experimental results (Qwen2.5-7B and Llama-3.1-8B tables): the headline numbers (62.4% vs 51.6%, 49.4% surpassing GRPO) are presented without error bars, statistical tests, or full hyperparameter schedules, which undermines assessment of whether the moderate-K advantage is robust or sensitive to random seeds and dataset-construction details.
minor comments (2)
- [Method] The manuscript would benefit from a clearer description of the exact rule used to form (chosen, rejected) pairs from GRPO trajectories and from an explicit statement of how many rollouts per prompt are retained at each K.
- Consider adding a small ablation that fixes K and varies prompt difficulty or temperature to isolate the uncertainty-calibration effect from other variables.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the claim that 'performance is governed by their informativeness' and that 'moderate warm-up produces rollouts with calibrated uncertainty, yielding stronger contrastive signal' rests on the indirect observations that pair count is stable across K and that accuracy peaks at moderate K before declining. No explicit informativeness metric (policy entropy, reward variance, or preference-margin distribution) or ablation that holds K fixed while varying uncertainty is reported, leaving open the possibility that gains arise from unmeasured factors such as changes in rollout correctness rate or group diversity.
Authors: We appreciate this observation. Our current support for the informativeness interpretation is indeed indirect, based on stable preference-pair counts and non-monotonic accuracy with respect to K. We agree that direct metrics would make the argument more robust and rule out alternative factors more convincingly. In the revised manuscript we will add explicit analyses of rollout policy entropy and preference-margin distributions across K values, together with a brief discussion of rollout correctness rates and group diversity as potential confounders. revision: yes
-
Referee: [Experimental results] Experimental results (Qwen2.5-7B and Llama-3.1-8B tables): the headline numbers (62.4% vs 51.6%, 49.4% surpassing GRPO) are presented without error bars, statistical tests, or full hyperparameter schedules, which undermines assessment of whether the moderate-K advantage is robust or sensitive to random seeds and dataset-construction details.
Authors: We agree that error bars, statistical tests, and complete hyperparameter details would improve evaluation of robustness. All reported runs used single random seeds because of the high compute cost of the online GRPO warm-up phase. In the revision we will include the full hyperparameter schedules in the appendix and highlight the consistency of the moderate-K trend across the two different base models (Qwen2.5-7B and Llama-3.1-8B). We will also note sensitivity to random seeds as a limitation of the current experimental design. revision: partial
- Providing error bars or statistical significance tests from multiple independent random seeds would require repeating the full set of computationally expensive GRPO warm-up experiments, which we cannot perform within the scope of this revision.
Circularity Check
No circularity: empirical results from controlled K-variation experiments
full rationale
The paper's central claims rest on direct experimental comparisons: varying the GRPO warm-up steps K, constructing static preference datasets, and measuring downstream DPO performance on MATH-500 and similar benchmarks for Qwen2.5-7B and Llama-3.1-8B. Performance is reported as not tracking preference-pair count (observed to be roughly constant) but instead peaking at moderate K. These are observational findings from ablation-style runs rather than any derivation, equation, or first-principles argument that reduces to its own inputs. No self-citations, uniqueness theorems, or ansatzes are invoked to justify load-bearing steps; the informativeness interpretation is presented as a post-hoc reading of the K-sweep results. The work is therefore self-contained against external benchmarks and contains no circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Warm-up step count K
axioms (1)
- domain assumption Moderate GRPO warm-up produces rollouts with calibrated uncertainty that yield stronger contrastive signals than low or high K
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[3]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
work page 2025
-
[5]
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , eprint=
work page 2025
-
[6]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[7]
International Conference on Machine Learning , pages=
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[8]
Understanding the performance gap between online and offline alignment algorithms , author=. 2024 , eprint=
work page 2024
-
[9]
Advances in Neural Information Processing Systems , volume=
The importance of online data: Understanding preference fine-tuning via coverage , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Forty-first International Conference on Machine Learning , year=
Self-rewarding language models , author=. Forty-first International Conference on Machine Learning , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Iterative reasoning preference optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
RLHF Workflow: From Reward Modeling to Online RLHF
Rlhf workflow: From reward modeling to online rlhf , author=. arXiv preprint arXiv:2405.07863 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Enhancing llm reasoning with iterative dpo: A comprehensive empirical investigation,
Enhancing LLM Reasoning with Iterative DPO: A Comprehensive Empirical Investigation , author=. arXiv preprint arXiv:2503.12854 , year=
-
[14]
It Takes Two: Your GRPO Is Secretly DPO
It takes two: Your grpo is secretly dpo , author=. arXiv preprint arXiv:2510.00977 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Advances in Neural Information Processing Systems , volume=
Bridging offline reinforcement learning and imitation learning: A tale of pessimism , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
- [17]
- [18]
-
[19]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems , author=. 2020 , eprint=
work page 2020
-
[20]
Introducing Gemini: Our Largest and Most Capable AI Model , year =
-
[21]
GPT-4 Technical Report , author =. arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
- [23]
-
[24]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.