Adaptive RBF-KAN: A Comparative Evaluation of Dynamic Shape Parameters in Kolmogorov-Arnold Networks
Pith reviewed 2026-05-22 01:56 UTC · model grok-4.3
The pith
LOOCV initialization plus adaptive kernels improves RBF-based KAN models on 2D benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that combining LOOCV-based kernel scale estimation with adaptive refinement during training, together with the introduction of Matern and Wendland kernels, supplies a practical strategy for improving RBF-based KAN models, as evidenced by comparative results on two-dimensional benchmark functions where kernel selection yields advantages for different function classes.
What carries the argument
LOOCV-based initialization of the radial kernel shape parameter that is subsequently refined during deep KAN training.
If this is right
- Kernel selection can be guided by the smoothness, presence of discontinuities, or oscillatory character of the target function.
- Adaptive shape parameters deliver measurable gains over the fixed-parameter approach used in FastKAN.
- The overall framework retains the computational efficiency of RBF replacements while increasing representational flexibility compared with spline-based KANs.
- LOOCV supplies a reproducible, data-driven starting value that removes manual tuning of the initial scale.
Where Pith is reading between the lines
- The same initialization-plus-adaptation pattern could be tested on higher-dimensional or noisy data sets where kernel scale choice is even more critical.
- Hybrid models might combine the new RBF options with spline or other basis functions inside a single KAN layer.
- Similar cross-validation warm-start techniques could be applied to tune other learnable parameters in related neural architectures for function approximation.
Load-bearing premise
That the LOOCV estimate supplies a useful starting scale for the kernel which training can improve and that performance patterns observed on 2D functions indicate advantages for broader classes of targets.
What would settle it
A head-to-head test on the same 2D benchmark functions in which the adaptive RBF-KAN versions produce no lower approximation error or no faster convergence than the original fixed-kernel FastKAN.
Figures

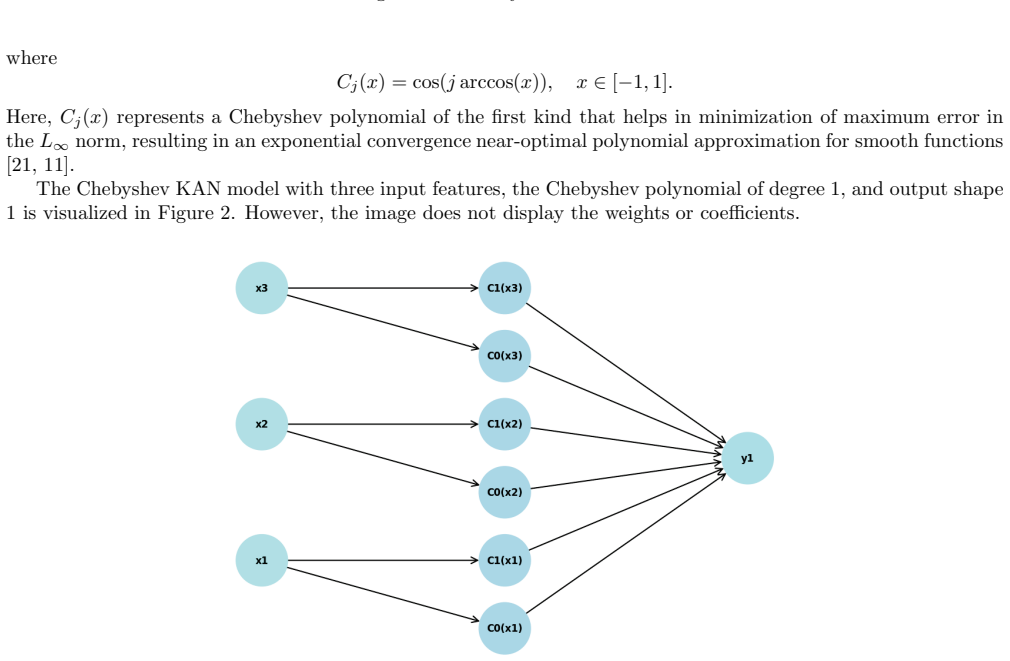

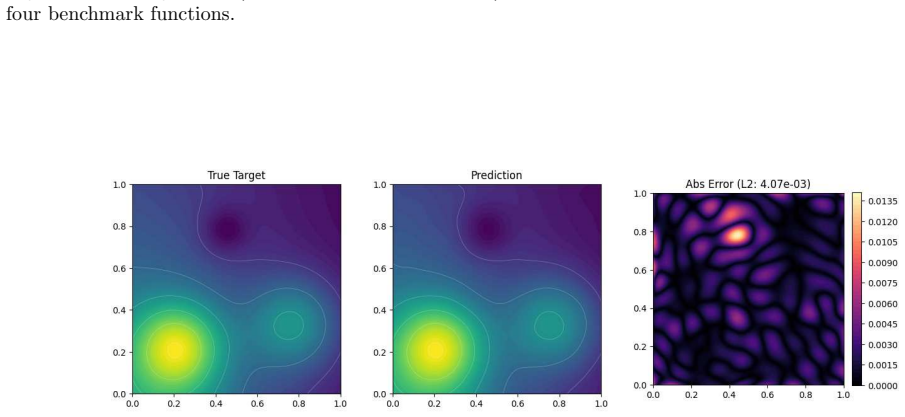



read the original abstract
Kolmogorov-Arnold Networks (KANs) approximate multivariate functions using learnable univariate edge functions, typically parameterized by B-spline bases. Although effective, spline-based implementations can be computationally expensive. A modified version of KANs, called FastKAN, improves efficiency by replacing splines with Gaussian radial basis functions (RBFs), but it relies on a fixed kernel and shape parameter. In this work, we extend the RBF-based KAN framework by introducing a broader family of radial basis kernels and by initializing the kernel shape parameter using leave-one-out cross-validation (LOOCV). To the best of our knowledge, this is the first study that integrates LOOCV-based kernel scale estimation with deep KAN training. We also introduce Mat\'ern and Wendland kernels into the KAN framework for the first time, enabling more flexible basis representations beyond the Gaussian kernel used in FastKAN. The LOOCV estimate provides a data-driven initialization of the kernel scale, which is subsequently refined during network training. The proposed adaptive RBF-KAN is evaluated on several two-dimensional benchmark functions. The results highlight the importance of kernel selection and adaptive shape parameters, with different kernels showing advantages for smooth functions, discontinuities, and oscillatory patterns. Overall, combining LOOCV-based initialization with adaptive kernel learning provides a practical strategy for improving RBF-based KAN models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the FastKAN framework by replacing fixed Gaussian RBFs with a broader family of radial basis kernels (including Matérn and Wendland) and by initializing the kernel shape parameter via leave-one-out cross-validation (LOOCV) before refining it during training. The adaptive RBF-KAN is evaluated on several two-dimensional benchmark functions, with the central claim that kernel selection and adaptive shape parameters yield practical improvements over fixed-shape baselines, with different kernels suiting smooth, discontinuous, and oscillatory targets.
Significance. If the reported gains hold under scaling, the work supplies a concrete, data-driven strategy for kernel choice and initialization in RBF-KANs. Notable strengths include the first integration of LOOCV-based scale estimation with deep KAN training and the introduction of Matérn and Wendland kernels into the KAN setting; these are reproducible, falsifiable extensions that could be directly adopted by practitioners.
major comments (2)
- [Experiments] Experiments section: All reported benchmarks are confined to two-dimensional functions. Because the number of adaptive shape parameters grows linearly with the number of edges and layers, the stability and benefit of per-edge or per-layer adaptation remain untested once input dimension or network width increases; this directly affects whether the claimed practical strategy generalizes beyond the toy regime.
- [Abstract] Abstract and Method description: The central claim of practical improvement rests on benchmark outcomes, yet the abstract supplies no quantitative metrics, error bars, training hyperparameters, or statistical significance tests. Without these details it is impossible to judge the magnitude or reliability of the reported kernel advantages.
minor comments (2)
- [Method] Notation for the shape parameter is introduced without an explicit equation linking the LOOCV objective to the subsequent gradient-based refinement; a short derivation or pseudocode would clarify the two-stage procedure.
- [Experiments] The paper asserts that different kernels are advantageous for different function classes, but does not report per-function quantitative comparisons (e.g., MSE tables with standard deviations across multiple runs).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recognition of the novelty in integrating LOOCV-based initialization and additional kernels into the RBF-KAN framework. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: All reported benchmarks are confined to two-dimensional functions. Because the number of adaptive shape parameters grows linearly with the number of edges and layers, the stability and benefit of per-edge or per-layer adaptation remain untested once input dimension or network width increases; this directly affects whether the claimed practical strategy generalizes beyond the toy regime.
Authors: We agree that confining the benchmarks to two-dimensional functions leaves the scalability of per-edge adaptive shape parameters untested for higher input dimensions or wider networks. The current study deliberately focuses on standard 2D benchmarks to isolate and compare kernel-specific behaviors on smooth, discontinuous, and oscillatory targets. In the revised manuscript we have added a new paragraph in the Discussion section that explicitly analyzes the linear growth in adaptive parameters, discusses potential stability implications, and proposes per-layer sharing of shape parameters as a practical mitigation. We also outline higher-dimensional scaling experiments as a clear direction for future work. No new empirical results on higher-dimensional cases are added in this revision. revision: partial
-
Referee: [Abstract] Abstract and Method description: The central claim of practical improvement rests on benchmark outcomes, yet the abstract supplies no quantitative metrics, error bars, training hyperparameters, or statistical significance tests. Without these details it is impossible to judge the magnitude or reliability of the reported kernel advantages.
Authors: We accept that the original abstract was insufficiently quantitative. We have revised the abstract to include specific performance metrics (e.g., relative MSE reductions for each kernel on the benchmark suite), a brief reference to the LOOCV initialization procedure, and a note that results are reported with error bars from repeated runs. Full tables with hyperparameters and statistical comparisons remain in the Experiments section; the abstract now points readers to these details so that the magnitude and reliability of the kernel advantages can be assessed directly. revision: yes
Circularity Check
Empirical extension with no circular derivation chain
full rationale
The paper introduces LOOCV-based initialization for kernel shape parameters in RBF-KANs, adds Matérn and Wendland kernels, and evaluates the resulting adaptive model on 2D benchmark functions. No mathematical derivation is claimed that reduces a prediction or result to its own fitted inputs by construction. The central practical strategy is supported by reported benchmark comparisons rather than self-referential fitting, self-citation load-bearing premises, or imported uniqueness theorems. The work is self-contained as an empirical study whose claims rest on external performance data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Radial basis functions with adjustable shape parameters can serve as effective univariate edge functions in KAN architectures
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., Hinton, G. E. Layer normalization. arXiv pre print arXiv:1607.06450 (2016). https://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Kernel-based methods and function app roximation
Baudat, G., Anouar, F. Kernel-based methods and function app roximation. IJCNN’01. International Joint Conference on Neural Networks. Proceedings (Cat. No.01CH372 22), Washington, DC, USA, vol. 2, pp. 1244– 1249, 2001. https://doi.org/10.1109/IJCNN.2001.939539
-
[3]
Blealtan, A. D. An efficient implementation of Kolmogorov-Arnold ne twork. GitHub Repository. Available at: https://github.com/Blealtan/efficient-kan (2024)
work page 2024
-
[4]
Buhmann, M. D. Radial basis functions. Acta Numerica 9 (2000), 1–38. https://doi.org/10.1017/S0962492900000015
-
[5]
Cavoretto, R., De Rossi, A., Mukhametzhanov, M. S., Sergeyev, Y. D. On the search of the shape parameter in radial basis functions using univariate global optimization methods. Journal of Global Optimization 79 (2021), 305–327. https://doi.org/10.1007/s10898-019-00853-3
-
[6]
Bayesian approach fo r radial kernel parameter tuning
Cavoretto, R., De Rossi, A., Lancellotti, S. Bayesian approach fo r radial kernel parameter tuning. Journal of Computational and Applied Mathematics 441 (2024) 115716. https://doi.org/10.1016/j.cam.2023.115716 18
-
[7]
The effects of training algorithms in MLP netw ork on image classification
Coskun, N., Yildirim, T. The effects of training algorithms in MLP netw ork on image classification. Proceedings of the International Joint Conference on Neural Ne tworks, vol. 2, pp. 1223–1226, 2003. https://doi.org/10.1109/IJCNN.2003.1223867
-
[8]
DeVore, R., Hanin, B., Petrova, G. Neural network approximatio n. Acta Numerica 30 (2021), 327–444. https://doi.org/10.1017/S0962492921000052
-
[9]
Fasshauer, G. E. Meshfree Approximation Methods with MATLAB . Interdisciplinary Mathematical Sciences, Volume 6, World Scientific, Singapore, 2007. https://doi.org/10.1142/6437
-
[10]
Kernel-based Approximation Meth ods using MATLAB
Fasshauer, G., McCourt, M. Kernel-based Approximation Meth ods using MATLAB. Interdisciplinary Mathe- matical Sciences, Volume 19, World Scientific, Singapore, 2015. https://doi.org/10.1142/9335
- [11]
-
[12]
Representation properties of networks: Kolmogorov’s theorem is irrelevant
Girosi, F., Poggio, T. Representation properties of networks: Kolmogorov’s theorem is irrelevant. Neural Computation, 1(4), 465–469 (1989). https://doi.org/10.1162/neco.1989.1.4.465
-
[13]
Kolmogorov’s mapping neural network existe nce theorem
Hecht-Nielsen, R. Kolmogorov’s mapping neural network existe nce theorem. In Proceedings of the IEEE First International Conference on Neural Networks, San D iego, CA, Vol. 3, pp. 11–14, 1987. https://cs.uwaterloo.ca/~y328yu/classics/Hecht-Nielsen.pdf
work page 1987
-
[14]
Gaussian Error Linear Units (GELUs)
Hendrycks, D., Gimpel, K. Gaussian error linear units (GELUs). arXiv preprint arXiv:1606.08415 (2016). https://arxiv.org/abs/1606.08415
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Multilayer feedforward ne tworks are universal approximators
Hornik, K., Stinchcombe, M., White, H. Multilayer feedforward ne tworks are universal approximators. Neural Networks, 2 (1989), 359–366. https://doi.org/10.1016/0893-6080(89)90020-8
-
[16]
Kolmogorov, A. N. On the representation of continuous funct ions of several variables by superpo- sitions of continuous functions of fewer variables. Doklady Akademii Nauk SSSR , 108 (1956), 179–
work page 1956
-
[17]
https://cs.uwaterloo.ca/~y328yu/classics/Kolmogorov56.pdf
[English translation in American Mathematical Society Translations (2) 17 (1961), 369–373]. https://cs.uwaterloo.ca/~y328yu/classics/Kolmogorov56.pdf
work page 1961
-
[18]
Learning multiple layers of features f rom tiny images
Krizhevsky, A., Hinton, G. Learning multiple layers of features f rom tiny images. Technical Report, University of Toronto (2009). https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
work page 2009
-
[19]
Kolmogorov’s theorem is relevant
Kurkova, V. Kolmogorov’s theorem is relevant. Neural Comput ation 3 (1991), 617–622. https://direct.mit.edu/neco/article-abstract/3/4/61 7/5612/Kolmogorov-s-Theorem-Is-Relevant?redirectedF r
work page 1991
-
[20]
Gradient-based le arning applied to document recognition
Lecun, Y., Bottou, L., Bengio, Y., Haffner, P. Gradient-based le arning applied to document recognition. Proceedings of the IEEE, Vol. 86(11), 1998, pp. 2278–2324. https://ieeexplore.ieee.org/document/726791
work page 1998
-
[21]
Kolmogorov-Arnold networks are radial basis function ne tworks
Li, Z. Kolmogorov-Arnold networks are radial basis function ne tworks. arXiv preprint arXiv:2405.06721 (2024). https://arxiv.org/abs/2405.06721
-
[22]
Granger Causality Detect ion with Kolmogorov-Arnold Networks
Lin, H., Ren, M., Barucca, P., Aste, T. Granger Causality Detect ion with Kolmogorov-Arnold Networks. arXiv preprint arXiv:2412.15373 (2024). https://arxiv.org/abs/2412.15373
-
[23]
KAN: Kolmogorov-Arnold Networks
Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljaˇ ci´ c , M., Hou, T.Y., Tegmark, M. KAN: Kolmogorov-Arnold networks. arXiv preprint arXiv:2404.19756 (20 24). https://arxiv.org/abs/2404.19756
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Approximation of function and its de rivatives using ra- dial basis function networks
Mai-Duy, N., Tran-Cong, T. Approximation of function and its de rivatives using ra- dial basis function networks. Applied Mathematical Modelling, 27(3) , 197–220 (2003). https://doi.org/10.1016/S0307-904X(02)00101-4
-
[25]
Error bounds for deep ReLU networks u sing the Kolmogorov-Arnold superposition theorem
Montanelli, H., Yang, H. Error bounds for deep ReLU networks u sing the Kolmogorov-Arnold superposition theorem. arXiv preprint arXiv:1906.11945 (2020). https://arxiv.org/abs/1906.11945
-
[26]
Efficie nt truncated randomized SVD for mesh-free kernel methods
Noorizadegan, A., Chen, C.-S., Cavoretto, R., De Rossi, A. Efficie nt truncated randomized SVD for mesh-free kernel methods. Computers & Mathematics with Applications 164 (2 024), 12–20. 19
-
[27]
Noorizadegan, A., Cavoretto, R., Young, D. L., Chen, C. S. Sta ble weight updating: A key to reliable PDE solutions using deep learning. Engineering Analysis with Boundary Elements 168 (2024), 105933. https://doi.org/10.1016/j.enganabound.2024.105933
-
[28]
Noorizadegan, A., Young, D. L., Hon, Y. C., Chen, C. S. Power-e nhanced residual network for function approximation and physics-informed inverse problems. Applied Math ematics and Computation 480 (2024), 128910. https://doi.org/10.1016/j.amc.2024.128910
-
[29]
Noorizadegan, A., Hon, Y. C., Young, D.-L., Chen, C.-S. Enhancin g supervised surface reconstruction through implicit weight regularization. Engineering Analysis with Bound ary Elements 180 (2025), 106439. https://doi.org/10.1016/j.enganabound.2025.106439
-
[30]
Noorizadegan, A., Wang, S., Ling, L., Dominguez-Morales, J. P. A practitioner’s guide to Kolmogorov–Arnold networks. Computer Science Review , 62, 100991, 2026. https://doi.org/10.1016/j.cosrev.2026.100991
-
[31]
Approximation theory of the MLP model in neural net works
Pinkus, A. Approximation theory of the MLP model in neural net works. Acta Numerica 8, 143–195 (1999). https://doi.org/10.1017/S0962492900002919
-
[32]
An algorithm for selecting a good value for the paramet er c in radial basis function interpolation
Rippa, S. An algorithm for selecting a good value for the paramet er c in radial basis function interpolation. Advances in Computational Mathematics 11 (1999), 193–210. https://doi.org/10.1023/A:1018975909870
-
[33]
Learning representations b y back-propagating errors
Rumelhart, D., Hinton, G., Williams, R. Learning representations b y back-propagating errors. Nature 323 (1986), 533–536. https://doi.org/10.1038/323533a0
-
[34]
The Kolmogorov-Arnold representation th eorem revisited
Schmidt-Hieber, J. The Kolmogorov-Arnold representation th eorem revisited. Neural Networks 137 (2021), 119–126. https://doi.org/10.1016/j.neunet.2021.01.020
- [35]
-
[36]
Sidharth, S. S., Keerthana, A. R., Gokul, R., Anas, K. P. Chebys hev polynomial-based Kolmogorov-Arnold networks: An efficient architecture for nonlinear function approx imation. arXiv preprint arXiv:2405.07200 (2024). https://arxiv.org/abs/2405.07200
-
[37]
Wendland, H. Scattered Data Approximation. Cambridge Monog raphs on Applied and Computational Mathematics, Volume 17, Cambridge University Pres s, Cambridge, 2005. https://doi.org/10.1017/CBO9780511617539
-
[38]
KAN or MLP: A fairer comparison
Yu, R., Yu, W., Wang, X. KAN or MLP: A fairer comparison. arXiv pr eprint arXiv:2407.16674 (2024). https://arxiv.org/abs/2407.16674
-
[39]
Kolmogorov-Arnold Fourier N etworks
Zhang, J., Fan, Y., Cai, K., Wang, K. Kolmogorov-Arnold Fourier N etworks. arXiv preprint arXiv:2502.06018 (2025). https://arxiv.org/abs/2502.06018 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.