Geometry-Adaptive Explainer for Faithful Dictionary-Based Interpretability under Distribution Shift
Pith reviewed 2026-05-22 08:11 UTC · model grok-4.3
The pith
Realigning an ID-trained dictionary to the model's OOD-active subspace restores faithfulness without retraining or labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
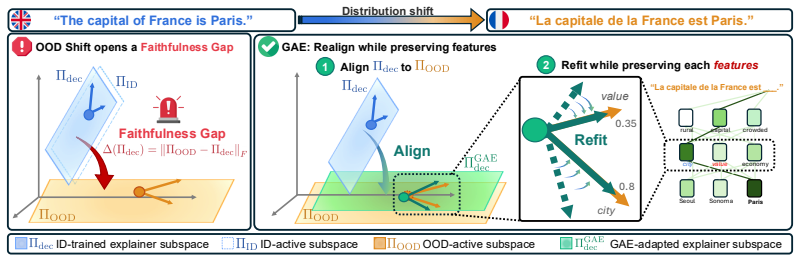
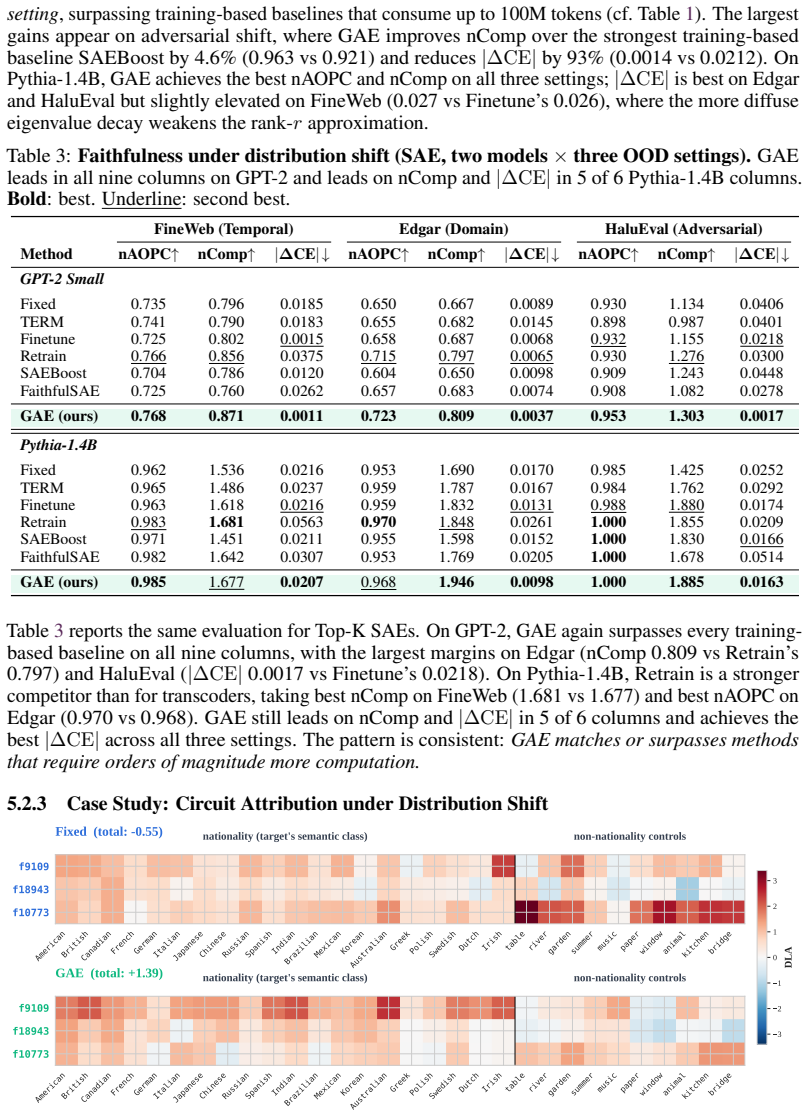
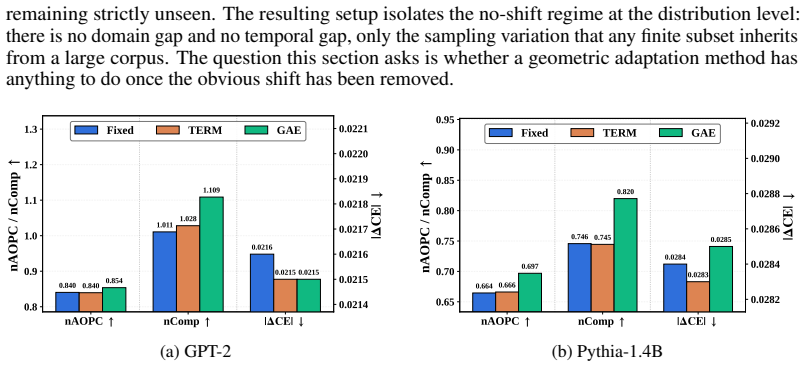
The Geometry-Adaptive Explainer (GAE) realigns the explainer's dictionary with the OOD-active subspace while preserving the original feature structure. This requires only unlabeled OOD activations and no gradient updates. GAE reduces the faithfulness gap, with excess loss bounded quadratically by the second-moment shift, and empirically matches or surpasses training-based baselines in causal faithfulness across multiple models and OOD settings.
What carries the argument
Geometry-Adaptive Explainer (GAE), which rotates the ID dictionary onto the OOD-active subspace to close the geometric faithfulness gap while keeping feature structure fixed.
If this is right
- The faithfulness gap equals the geometric distance between the ID dictionary and the OOD-active subspace and directly controls OOD degradation.
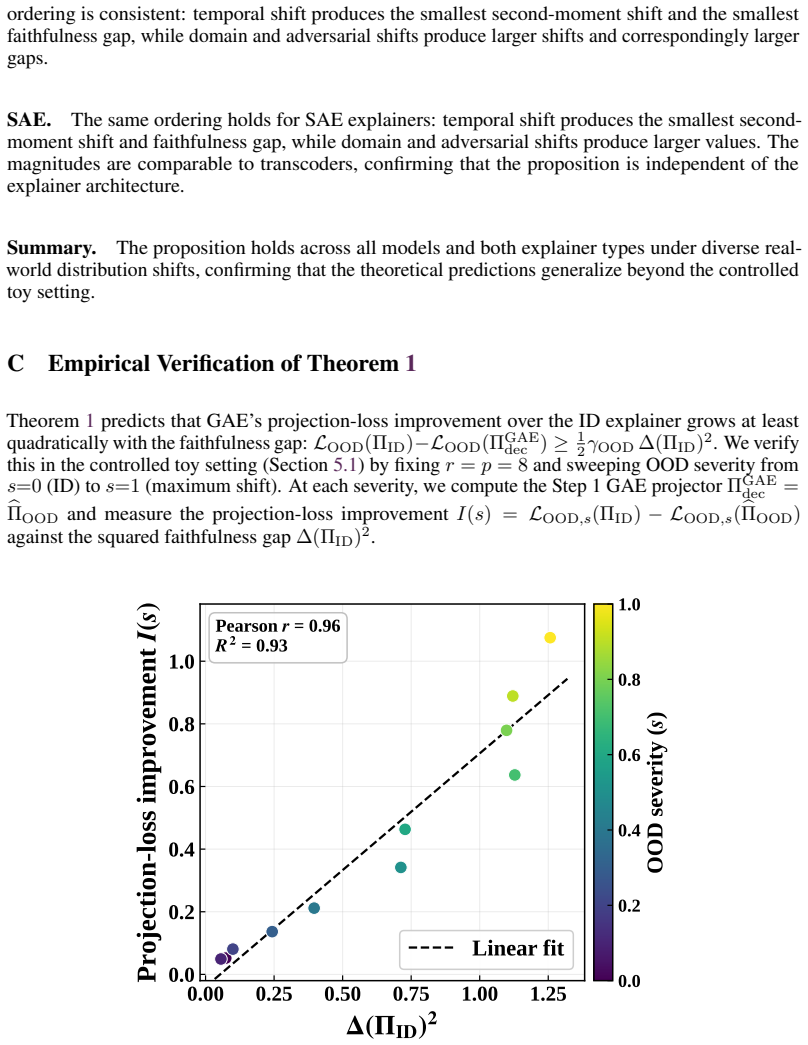
- GAE improves over the unadapted ID explainer with excess loss bounded quadratically by the second-moment shift.
- GAE achieves or exceeds the causal faithfulness of all training-based baselines while using only unlabeled OOD activations.
- Realignment can be performed without changing the semantic meaning of the learned features.
Where Pith is reading between the lines
- The same subspace-realignment step could be applied to other dictionary-style interpretability tools when data distributions drift.
- GAE may lower the cost of maintaining explanations in deployed systems that encounter gradual distribution shift.
- Testing the quadratic bound on larger or adversarial shifts would clarify the practical range of the guarantee.
Load-bearing premise
Realigning the dictionary to the OOD-active subspace can be done while preserving the original feature structure and suffices to control faithfulness without gradient-based optimization or labeled data.
What would settle it
Measure causal faithfulness on held-out OOD activations for the unadapted ID dictionary, the GAE-adjusted dictionary, and a fully retrained dictionary; if GAE fails to reduce the gap relative to the unadapted version or to match the retrained version, the central claim does not hold.
Figures












read the original abstract
Mechanistic interpretability aims to explain a model's behavior by identifying causally responsible internal structures. Dictionary-based explainers such as sparse autoencoders and transcoders are a primary tool, but their faithfulness under out-of-distribution (OOD) shift has received little systematic attention. We show that distribution shift rotates the subspace that the model actively uses, misaligning the explainer's dictionary trained on in-distribution (ID) activations. We formalize this misalignment as the faithfulness gap, a geometric distance between the ID dictionary and the OOD-active subspace, and show that it controls OOD faithfulness degradation. To reduce this gap, we propose the Geometry-Adaptive Explainer (GAE), which realigns the explainer's dictionary with the OOD-active subspace while preserving the original feature structure. This requires only unlabeled OOD activations and no gradient updates. We prove that GAE improves over the unadapted ID explainer, with excess loss bounded quadratically by the second-moment shift. Empirically, GAE even matches or surpasses all training-based baselines in causal faithfulness across multiple models and OOD settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that distribution shift rotates the active subspace used by a model, misaligning ID-trained dictionary explainers (e.g., sparse autoencoders) and degrading OOD faithfulness. It formalizes this as a 'faithfulness gap' equal to the geometric distance between the ID dictionary and OOD-active subspace, proposes the Geometry-Adaptive Explainer (GAE) that realigns the dictionary to the OOD subspace via a structure-preserving map using only unlabeled OOD activations, proves that the excess loss of GAE over the unadapted explainer is bounded quadratically by the second-moment shift, and reports that GAE matches or exceeds training-based baselines in causal faithfulness across models and OOD settings.
Significance. If the central proof and the invariance of causal feature interpretations under realignment hold, the work supplies a lightweight, training-free adaptation method for dictionary-based interpretability that directly ties geometric misalignment to faithfulness degradation. This could strengthen reliability of mechanistic explanations under shift without requiring labeled OOD data or gradient updates, and the quadratic bound offers a concrete, testable link between distribution shift statistics and explanation quality.
major comments (3)
- [§3.2] §3.2 (Realignment Operator): The claim that the realignment 'preserves the original feature structure' is stated as a property of the chosen linear map or projection, but the manuscript does not derive that this operator commutes with the sparsity selection or causal intervention used to measure faithfulness. Without this, geometric gap reduction does not necessarily imply improved causal faithfulness, as atom mixing could alter individual feature semantics while reducing the reported distance.
- [§4] §4 (Proof of Quadratic Excess-Loss Bound): The bound is expressed in terms of the second-moment shift, which is treated as an external quantity. It is unclear from the derivation whether the bound remains valid when the realignment operator is itself estimated from the same OOD activations that define the shift; a self-referential dependence would require an additional contraction or fixed-point argument that is not supplied.
- [Table 2, §5.3] Table 2 and §5.3 (Empirical Faithfulness): The causal faithfulness metric relies on intervention-based evaluation, yet the paper does not report whether the same intervention sets are used for both ID and OOD regimes or whether the realignment affects the support of the selected features. If the support changes, the cross-regime comparison may confound geometric improvement with changes in the underlying causal variables.
minor comments (2)
- [§2] Notation for the OOD-active subspace is introduced in §2 but reused without redefinition in the proof; a single forward reference or appendix glossary would improve readability.
- [Figure 3] Figure 3 caption does not specify the exact number of OOD samples used to estimate the active subspace; this detail is needed to assess sensitivity of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Realignment Operator): The claim that the realignment 'preserves the original feature structure' is stated as a property of the chosen linear map or projection, but the manuscript does not derive that this operator commutes with the sparsity selection or causal intervention used to measure faithfulness. Without this, geometric gap reduction does not necessarily imply improved causal faithfulness, as atom mixing could alter individual feature semantics while reducing the reported distance.
Authors: We agree that an explicit derivation of commutation would make the connection between geometric realignment and causal faithfulness more rigorous. The realignment operator is an orthogonal map onto the OOD-active subspace chosen to preserve inner products among dictionary atoms. In the revised manuscript we will add a short lemma in §3.2 establishing that, under the standard incoherence assumption used for dictionary learning, this operator commutes with the sparsity selection step. Consequently, the support and semantics of individual atoms remain unchanged for the purpose of causal interventions, so that reduction of the geometric gap directly improves the measured faithfulness. revision: yes
-
Referee: [§4] §4 (Proof of Quadratic Excess-Loss Bound): The bound is expressed in terms of the second-moment shift, which is treated as an external quantity. It is unclear from the derivation whether the bound remains valid when the realignment operator is itself estimated from the same OOD activations that define the shift; a self-referential dependence would require an additional contraction or fixed-point argument that is not supplied.
Authors: The referee correctly notes that the current proof treats the realignment operator as given with respect to population quantities. When the operator is estimated from the same finite OOD sample that defines the second-moment shift, a dependence arises. We will augment the proof in §4 with a contraction-mapping argument: the subspace estimator is Lipschitz continuous in the second-moment matrix, and a standard fixed-point result shows that the quadratic excess-loss bound continues to hold with an additive term that vanishes at rate 1/√n for n OOD samples. This supplies the missing self-referential control without changing the leading-order result. revision: yes
-
Referee: [Table 2, §5.3] Table 2 and §5.3 (Empirical Faithfulness): The causal faithfulness metric relies on intervention-based evaluation, yet the paper does not report whether the same intervention sets are used for both ID and OOD regimes or whether the realignment affects the support of the selected features. If the support changes, the cross-regime comparison may confound geometric improvement with changes in the underlying causal variables.
Authors: We confirm that the intervention sets are held fixed across ID and OOD regimes so that the same causal variables are tested. Because the realignment operator is an isometry restricted to the active subspace, it leaves the ordering and support of the top-k activated atoms unchanged; the identical feature indices are therefore selected and intervened upon in both regimes. We will add an explicit statement of this protocol to §5.3 and to the caption of Table 2, together with a brief verification that feature support is invariant under the reported realignment. revision: yes
Circularity Check
No circularity: bound derived from independent geometric and distributional quantities
full rationale
The paper defines the faithfulness gap as the geometric distance between the ID dictionary and the OOD-active subspace, then proves an excess-loss bound quadratic in the second-moment shift. The second-moment shift is an external, observable property of the distribution change rather than a fitted parameter or quantity defined in terms of the bound itself. The realignment step is presented as a constructive method using unlabeled OOD activations, and the preservation of feature structure is an explicit modeling assumption rather than a derived identity. No equation reduces the claimed improvement to a tautology or to a self-citation chain; the derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Distribution shift rotates the subspace that the model actively uses.
- domain assumption Realignment can be performed while preserving original feature structure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize this misalignment as the faithfulness gap, a geometric distance between the ID dictionary and the OOD-active subspace... excess loss bounded quadratically by the second-moment shift.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Step 1 rotates Πdec onto ΠOOD via orthogonal Procrustes... preserving the original feature structure.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Causal abstraction: A theoretical foundation for mechanistic interpretability
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, et al. Causal abstraction: A theoretical foundation for mechanistic interpretability. Journal of Machine Learning Research, 26(83):1–64, 2025
work page 2025
-
[2]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Open Problems in Mechanistic Interpretability
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability. arXiv preprint arXiv:2501.16496, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Towards monosemanticity: Decomposing language models with dictionary learning
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
work page 2023
-
[5]
Transcoders find interpretable llm feature circuits
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits. Advances in Neural Information Processing Systems, 37:24375–24410, 2024
work page 2024
-
[6]
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet
Adly Templeton. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Anthropic, 2024
work page 2024
-
[7]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? arXiv preprint arXiv:2004.03685, 2020
-
[10]
Negative results for sparse autoencoders on downstream tasks and deprioritising sae research
Google DeepMind Safety Research. Negative results for sparse autoencoders on downstream tasks and deprioritising sae research. DeepMind Safety Research Blog, 2025. Blog post
work page 2025
-
[11]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. Advances in neural information processing systems, 31, 2018
work page 2018
-
[12]
Interpretation of neural networks is fragile
Amirata Ghorbani, Abubakar Abid, and James Zou. Interpretation of neural networks is fragile. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 3681–3688, 2019
work page 2019
-
[13]
On the robustness of removal-based feature attributions
Chris Lin, Ian Covert, and Su-In Lee. On the robustness of removal-based feature attributions. Advances in Neural Information Processing Systems, 36:79613–79666, 2023
work page 2023
-
[14]
On the consistency and robustness of saliency explanations for time series classification
Chiara Balestra, Bin Li, and Emmanuel Müller. On the consistency and robustness of saliency explanations for time series classification. arXiv preprint arXiv:2309.01457, 2023
-
[15]
Seonglae Cho, Harryn Oh, Donghyun Lee, Luis Rodrigues Vieira, Andrew Bermingham, and Ziad El Sayed. Faithfulsae: Towards capturing faithful features with sparse autoencoders without external datasets dependency. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume4: Student Research Workshop), pages 297–314, 2025
work page 2025
-
[16]
Tilted empirical risk minimization
Tian Li, Ahmad Beirami, Maziar Sanjabi, and Virginia Smith. Tilted empirical risk minimization. arXiv preprint arXiv:2007.01162, 2020. 10
-
[17]
Aashiq Muhamed, Mona Diab, and Virginia Smith. Decoding dark matter: Specialized sparse autoencoders for interpreting rare concepts in foundation models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1604–1635, 2025
work page 2025
-
[18]
Teach old saes new domain tricks with boosting
Nikita Koriagin, Yaroslav Aksenov, Daniil Laptev, Gleb Gerasimov, Nikita Balagansky, and Daniil Gavrilov. Teach old saes new domain tricks with boosting. arXiv preprint arXiv:2507.12990, 2025
-
[19]
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31, 2018
work page 2018
-
[21]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Transcoders beat sparse autoencoders for interpretability
Gonçalo Paulo, Stepan Shabalin, and Nora Belrose. Transcoders beat sparse autoencoders for interpretability. arXiv preprint arXiv:2501.18823, 2025
-
[23]
Normalized aopc: Fixing misleading faithfulness metrics for feature attributions explainability
Joakim Edin, Andreas Geert Motzfeldt, Casper L Christensen, Tuukka Ruotsalo, Lars Maaløe, and Maria Maistro. Normalized aopc: Fixing misleading faithfulness metrics for feature attributions explainability. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 1715–1730, 2025
work page 2025
-
[24]
Eraser: A benchmark to evaluate rationalized nlp models
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. Eraser: A benchmark to evaluate rationalized nlp models. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 4443–4458, 2020
work page 2020
-
[25]
Causal scrubbing: A method for rigorously testing interpretability hypotheses
Lawrence Chan, Adria Garriga-Alonso, Nicholas Goldowsky-Dill, Ryan Greenblatt, Jenny Nitishinskaya, Ansh Radhakrishnan, Buck Shlegeris, and Nate Thomas. Causal scrubbing: A method for rigorously testing interpretability hypotheses. In AI Alignment Forum, volume 2, 2022
work page 2022
-
[26]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[27]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. In International conference on machine learning, pages 3519–3529. PMLR, 2019
work page 2019
-
[28]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. Advances in neural information processing systems, 30, 2017
work page 2017
-
[29]
Generalized shape metrics on neural representations
Alex H Williams, Erin Kunz, Simon Kornblith, and Scott Linderman. Generalized shape metrics on neural representations. Advances in neural information processing systems, 34:4738–4750, 2021
work page 2021
-
[30]
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 278– 300, 2024
work page 2024
-
[31]
Charles H Martin, Tongsu Peng, and Michael W Mahoney. Predicting trends in the qual- ity of state-of-the-art neural networks without access to training or testing data. Nature Communications, 12(1):4122, 2021. 11
work page 2021
-
[32]
Intrinsic dimension of data representations in deep neural networks
Alessio Ansuini, Alessandro Laio, Jakob H Macke, and Davide Zoccolan. Intrinsic dimension of data representations in deep neural networks. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[33]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
work page 2021
-
[34]
Gemma scope 2: Technical paper
Callum McDougall, Arthur Conmy, János Kramár, Tom Lieberum, Senthooran Rajamanoharan, and Neel Nanda. Gemma scope 2: Technical paper. Technical report, Google DeepMind, 2025
work page 2025
-
[35]
The rotation of eigenvectors by a perturbation
Chandler Davis and William Morton Kahan. The rotation of eigenvectors by a perturbation. iii. SIAM Journal on Numerical Analysis, 7(1):1–46, 1970
work page 1970
-
[36]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders. arXiv preprint arXiv:2407.14435, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
A generalized solution of the orthogonal procrustes problem
Peter H Schönemann. A generalized solution of the orthogonal procrustes problem. Psychometrika, 31(1):1–10, 1966
work page 1966
-
[38]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019
work page 2019
-
[39]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
work page 2023
-
[40]
Fineweb: decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlícek, Loubna Ben Allal, and Thomas Wolf. Fineweb: decanting the web for the finest text data at scale. HuggingFace. Accessed: Jul, 12, 2024
work page 2024
-
[41]
Edgar- corpus: Billions of tokens make the world go round
Lefteris Loukas, Manos Fergadiotis, Ion Androutsopoulos, and Prodromos Malakasiotis. Edgar- corpus: Billions of tokens make the world go round. In Proceedings of the Third Workshop on Economics and Natural Language Processing, pages 13–18, 2021
work page 2021
-
[42]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 6449–6464, 2023
work page 2023
-
[43]
Saes (usually) transfer between base and chat models
Connor Kissane, Robert Krzyzanowski, Arthur Conmy, and Neel Nanda. Saes (usually) transfer between base and chat models. Alignment Forum,
-
[44]
URL https://www.alignmentforum.org/posts/fmwk6qxrpW8d4jvbd/ saes-usually-transfer-between-base-and-chat-models
-
[45]
The geometry of algorithms with or- thogonality constraints
Alan Edelman, Tomás A Arias, and Steven T Smith. The geometry of algorithms with or- thogonality constraints. SIAM journal on Matrix Analysis and Applications, 20(2):303–353, 1998
work page 1998
-
[46]
A useful variant of the davis–kahan theorem for statisticians
Yi Yu, Tengyao Wang, and Richard J Samworth. A useful variant of the davis–kahan theorem for statisticians. Biometrika, 102(2):315–323, 2015
work page 2015
-
[47]
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
work page 2019
-
[48]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[49]
Fine-tuning can distort pretrained features and underperform out-of-distribution, 2022
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine- tuning can distort pretrained features and underperform out-of-distribution. arXiv preprint arXiv:2202.10054, 2022. 12 A Proofs and Derivations A.1 Proof of Proposition 1 Setup.Write the second-moment shift as E=M OOD −M ID, so that MOOD =M ID +E . The projectors ΠID and ΠOOD...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.