A Robust Deep Learning Framework for Prominence Detection through Composite Feature Representations
Pith reviewed 2026-05-22 04:13 UTC · model grok-4.3
The pith
Composite three-channel images enable deep learning models to detect solar prominences based on physical features rather than image artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
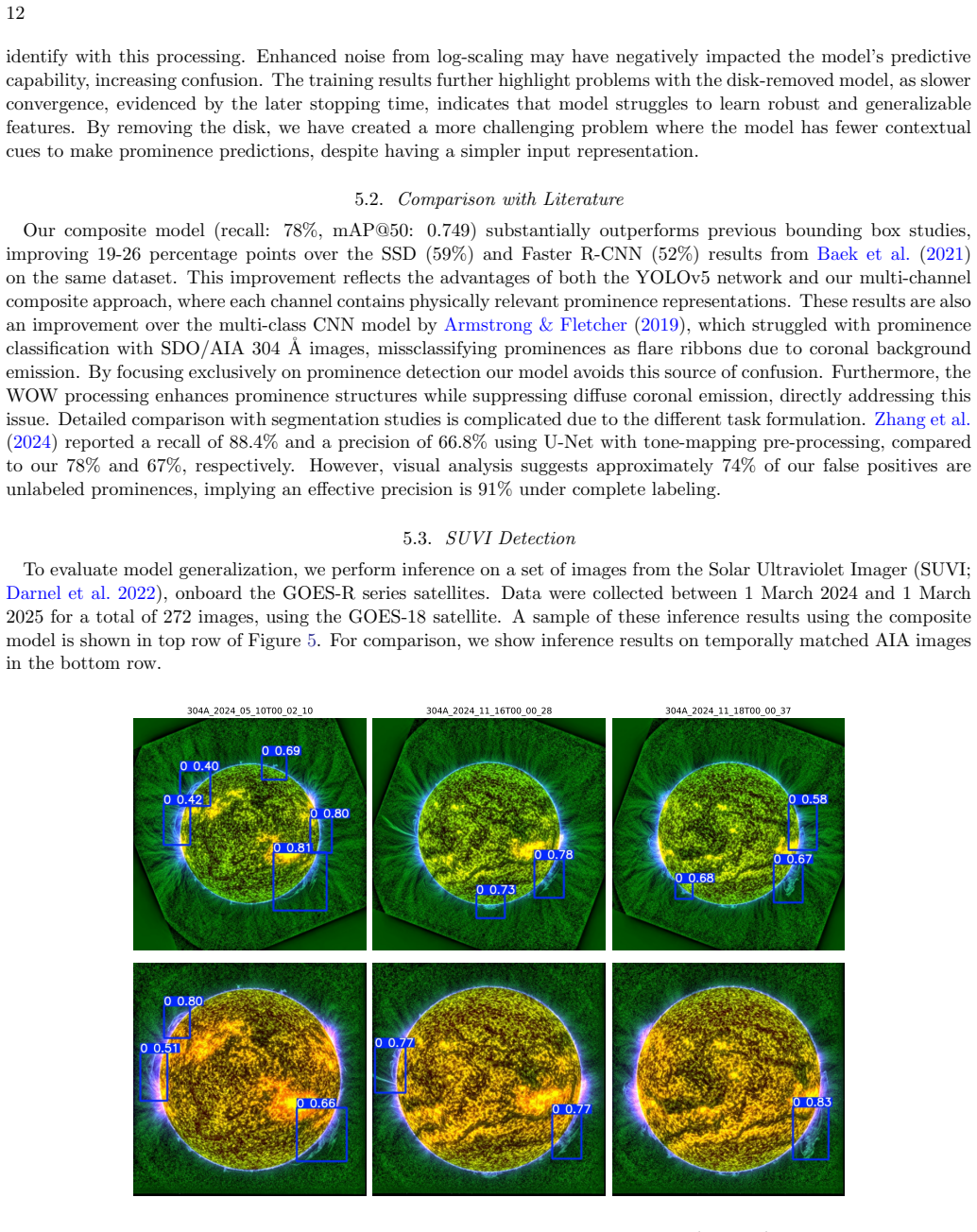
Using an existing labeled dataset, trained YOLOv5 models show bias toward the 304 Å colormap. The authors develop composite models with three-channel images from a preprocessing pipeline that includes full-disk grayscale, full-disk enhanced corona, and disk-removed images, with corrections for instrument degradation. The composite model achieves a mAP@50 of 0.749 and a recall of 78% on the test set, outperforming previous bounding box methods. Visual analysis reveals many apparent false positives are valid unlabeled prominences, and the model generalizes to SUVI data.
What carries the argument
The composite feature representation from a dataset preprocessing pipeline that constructs three-channel images combining full-disk grayscale, enhanced corona, and disk-removed views while correcting for instrument degradation to maintain consistent features across the solar cycle.
If this is right
- The composite model outperforms previous bounding box methods for prominence detection in EUV images.
- Many apparent false positives turn out to be valid but unlabeled prominences.
- The model demonstrates cross-instrument generalization when tested on SUVI image data.
- Recommendations for robust dataset construction help avoid biases in future models.
Where Pith is reading between the lines
- Similar composite preprocessing could improve detection of other dynamic solar features such as filaments or coronal mass ejections.
- Real-time application of this model might support automated space weather alert systems.
- Extending the approach to time-series data could track prominence evolution and eruption risks more effectively.
Load-bearing premise
The existing labeled prominence dataset is complete enough and free of systematic labeling bias so that the model's performance numbers and reclassified false positives reflect real physical feature detection.
What would settle it
Independent expert labeling of model outputs on a fresh set of EUV images from the same or different instruments, checking whether the detections correspond to actual prominences not present in the original training labels.
Figures





read the original abstract
Solar prominences are dynamic structures suspended within the solar corona and are manifestation of solar activity. Their evolution includes eruptions linked to coronal mass ejections, making their detection critical for space weather monitoring and forecasting. The vast amounts of high-cadence data provided by missions such as SDO/AIA motivate the application of deep learning frameworks capable of assimilating large-scale datasets. However, previous studies have reported poor model performance caused by contamination from hot coronal emission from the EUV HeII 304 {\AA} channel. Using an existing labeled prominence dataset, we find that trained YOLOv5 object detection models exhibit a strong bias towards the 304 {\AA} colormap, rather than physically meaningful prominence features. We develop a further two models comprising three-channel images constructed through an original dataset preprocessing pipeline: (i) full-disk grayscale, full-disk enhanced corona, and disk-removed, (ii) same as (i) with all disk-removed images. Our pipeline corrects instrument degradation to maintain more consistent feature representations across the solar cycle. The composite model (i) achieves a mAP@50 of 0.749 and a recall of $78\%$ on the test set, outperforming previous bounding box methods. Visual analysis of the composite models reveals that many apparent false positives are valid unlabeled prominences. We additionally demonstrate cross-instrument generalization by testing the composite model on SUVI image data. By examining dataset biases that propagate into model predictions, we provide recommendations for robust dataset construction. We present a reliable, physically-motivated, and versatile deep learning model to automatically detect prominences in EUV images, providing a framework beneficial for space weather applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a deep learning approach using YOLOv5 for solar prominence detection in SDO/AIA EUV images. It identifies bias in standard models toward the 304 Å channel and introduces composite three-channel inputs (full-disk grayscale, enhanced corona, and disk-removed) via a preprocessing pipeline that corrects instrument degradation. The composite model (i) reports mAP@50 = 0.749 and 78% recall on a held-out test set, outperforming prior bounding-box methods; visual inspection is used to reclassify many false positives as valid but unlabeled prominences. Cross-instrument generalization to SUVI data is demonstrated, along with recommendations for robust dataset construction.
Significance. If the performance gains and reclassification of false positives are substantiated, the work would offer a practical advance for automated prominence detection in high-cadence solar imagery, with direct relevance to space-weather monitoring. The emphasis on addressing label incompleteness and channel bias through composite representations and preprocessing is a constructive contribution, and the SUVI generalization test provides evidence of broader applicability.
major comments (2)
- [Abstract / Results] Abstract and Results section: The headline mAP@50 = 0.749 and recall = 78 % (and the claim of outperformance over previous bounding-box methods) rest on post-hoc visual reclassification of a substantial fraction of apparent false positives as true but unlabeled prominences. This procedure is described as subjective visual analysis without reported quantitative cross-validation (e.g., inter-rater agreement, comparison against an independent catalog, or blinded expert scoring). If the original training labels contain systematic omissions (faint off-limb structures, morphological classes, or cycle-dependent features), the metrics may reflect dataset artifacts rather than improved physical-feature learning.
- [Methods / Dataset] Methods / Dataset section: The preprocessing pipeline corrects instrument degradation to maintain consistent feature representations across the solar cycle, yet no quantitative assessment is provided of how this affects label completeness or the distribution of missed prominences in the reference dataset. The assumption that the existing labeled dataset is sufficiently complete therefore remains untested and load-bearing for the interpretation of false positives.
minor comments (3)
- [Methods] Clarify the exact train/validation/test split ratios, the number of images per split, and whether any data augmentation or balancing was applied to address class imbalance.
- [Results] Provide error bars or confidence intervals on the reported mAP and recall values, and state whether they were obtained from a single run or multiple random seeds.
- [Methods] Specify the precise channel weights or combination rule used to construct the three-channel composite images; the abstract lists them as free parameters but does not give their values or selection procedure.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive and detailed review of our manuscript on solar prominence detection. The comments have prompted us to clarify key aspects of our methodology and results presentation. We respond to each major comment below, providing honest clarifications drawn from the manuscript content and indicating revisions where we concur that adjustments improve the work.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: The headline mAP@50 = 0.749 and recall = 78 % (and the claim of outperformance over previous bounding-box methods) rest on post-hoc visual reclassification of a substantial fraction of apparent false positives as true but unlabeled prominences. This procedure is described as subjective visual analysis without reported quantitative cross-validation (e.g., inter-rater agreement, comparison against an independent catalog, or blinded expert scoring). If the original training labels contain systematic omissions (faint off-limb structures, morphological classes, or cycle-dependent features), the metrics may reflect dataset artifacts rather than improved physical-feature learning.
Authors: We thank the referee for this observation. The reported mAP@50 of 0.749 and recall of 78% are computed strictly against the original test-set labels using standard object-detection evaluation protocols; no reclassification of false positives is applied to these figures. The visual analysis is presented separately in the Results section solely to illustrate that many model detections correspond to physically plausible but unlabeled prominences, thereby highlighting label incompleteness in the reference dataset rather than modifying the quantitative metrics. We acknowledge that this visual inspection is subjective and lacks the quantitative safeguards mentioned. In the revised manuscript we have inserted explicit language in both the Abstract and Results sections stating that performance numbers rely exclusively on the original labels, added a dedicated paragraph discussing the implications of label incompleteness as a dataset limitation, and noted the desirability of future blinded expert validation or cross-catalog comparisons. revision: yes
-
Referee: [Methods / Dataset] Methods / Dataset section: The preprocessing pipeline corrects instrument degradation to maintain consistent feature representations across the solar cycle, yet no quantitative assessment is provided of how this affects label completeness or the distribution of missed prominences in the reference dataset. The assumption that the existing labeled dataset is sufficiently complete therefore remains untested and load-bearing for the interpretation of false positives.
Authors: We agree that a direct quantitative evaluation of the preprocessing pipeline’s influence on label completeness would be desirable. Such an evaluation would require expert re-annotation of a substantial subset of images or construction of an independent reference catalog, tasks that exceed the scope of the present study, which centers on the design of the composite three-channel representation and the resulting detector. The pipeline’s primary purpose is to mitigate long-term instrument degradation so that feature statistics remain more stable across the solar cycle; we have expanded the Methods section to include a qualitative explanation of this consistency benefit and its role in reducing channel-specific bias. We have also added an explicit statement in the revised text acknowledging that completeness of the reference labels is an assumption and discussing its bearing on false-positive interpretation. revision: yes
- Quantitative cross-validation (inter-rater agreement, blinded scoring, or independent catalog comparison) for the visual reclassification of false positives
Circularity Check
Empirical ML evaluation on held-out test set is self-contained with no derivation reducing to inputs by construction
full rationale
The paper trains YOLOv5-based object detectors on an existing labeled prominence dataset and reports standard performance metrics (mAP@50 = 0.749, recall 78%) computed against a held-out test set. These quantities are direct empirical outputs of the supervised learning pipeline and do not involve any fitted parameter that is then renamed as a prediction, nor any self-definitional loop in which the target is defined in terms of the model output. The supplementary visual reclassification of false positives is presented as an observational note rather than a load-bearing step in any derivation chain. No uniqueness theorems, ansatzes, or self-citations are invoked to justify core claims. The central results therefore remain independent of the inputs by construction and constitute a normal, non-circular empirical benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- channel combination weights
axioms (1)
- domain assumption The provided labeled prominence dataset accurately reflects physical prominences without systematic labeling bias
Lean theorems connected to this paper
-
IndisputableMonolith/CostJcost unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The composite model (i) achieves a mAP@50 of 0.749 and a recall of 78% on the test set... three-channel images constructed through an original dataset preprocessing pipeline: (i) full-disk grayscale, full-disk enhanced corona, and disk-removed
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our pipeline corrects instrument degradation to maintain more consistent feature representations across the solar cycle
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2024, SoPh, 299, 94, doi: 10.1007/s11207-024-02337-4
Antolin, P., Auch` ere, F., Winch, E., Soubri´ e, E., & Oliver, R. 2024, SoPh, 299, 94, doi: 10.1007/s11207-024-02337-4
-
[2]
Armstrong, J. A., & Fletcher, L. 2019, SoPh, 294, 80, doi: 10.1007/s11207-019-1473-z
-
[3]
Aschwanden, M. J. 2010, SoPh, 262, 235, doi: 10.1007/s11207-009-9474-y Asensio Ramos, A., Cheung, M. C. M., Chifu, I., & Gafeira, R. 2023, Living Reviews in Solar Physics, 20, 4, doi: 10.1007/s41116-023-00038-x Auch` ere, F., Soubri´ e, E., Pelouze, G., & Buchlin,´E. 2023, A&A, 670, A66, doi: 10.1051/0004-6361/202245345
-
[4]
2021, SoPh, 296, 160, doi: 10.1007/s11207-021-01902-5
Baek, J.-H., Kim, S., Choi, S., et al. 2021, SoPh, 296, 160, doi: 10.1007/s11207-021-01902-5
-
[5]
Baker, N., Lu, H., Erlikhman, G., & Kellman, P. J. 2018, PLOS Computational Biology, 14, 1, doi: 10.1371/journal.pcbi.1006613
-
[6]
2025, ApJ, 985, 161, doi: 10.3847/1538-4357/adcba3
Birch, H., & R´ egnier, S. 2025, ApJ, 985, 161, doi: 10.3847/1538-4357/adcba3
-
[7]
Darnel, J. M., Seaton, D. B., Bethge, C., et al. 2022, Space Weather, 20, e2022SW003044, doi: 10.1029/2022SW00304410.1002/essoar.10510311.1
work page doi:10.1029/2022sw00304410.1002/essoar.10510311.1 2022
-
[8]
2024, A&A, 686, A213, doi: 10.1051/0004-6361/202348314
Diercke, A., Jarolim, R., Kuckein, C., et al. 2024, A&A, 686, A213, doi: 10.1051/0004-6361/202348314
-
[9]
2024, Roboflow (Version 1.0) [Software], https://roboflow.com
Dwyer, B., Nelson, J., Hansen, T., et al. 2024, Roboflow (Version 1.0) [Software], https://roboflow.com
work page 2024
-
[10]
2018, in International conference on learning representations
Geirhos, R., Rubisch, P., Michaelis, C., et al. 2018, in International conference on learning representations
work page 2018
-
[11]
2014, in Proceedings of the IEEE conference on computer vision and pattern recognition, 580–587
Girshick, R., Donahue, J., Darrell, T., & Malik, J. 2014, in Proceedings of the IEEE conference on computer vision and pattern recognition, 580–587
work page 2014
-
[12]
2022, SoPh, 297, 104, doi: 10.1007/s11207-022-02019-z
Guo, X., Yang, Y., Feng, S., et al. 2022, SoPh, 297, 104, doi: 10.1007/s11207-022-02019-z
-
[13]
2017, in Proceedings of the IEEE international conference on computer vision, 2961–2969
He, K., Gkioxari, G., Doll´ ar, P., & Girshick, R. 2017, in Proceedings of the IEEE international conference on computer vision, 2961–2969
work page 2017
-
[14]
Hosseini, H., Xiao, B., Jaiswal, M., & Poovendran, R. 2018, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 1923–1931
work page 2018
-
[15]
2020, Ultralytics YOLOv5, 7.0, doi: 10.5281/zenodo.3908559
Jocher, G. 2020, Ultralytics YOLOv5, 7.0, doi: 10.5281/zenodo.3908559
-
[16]
2010a, SoPh, 262, 449, doi: 10.1007/s11207-009-9492-9
Labrosse, N., Dalla, S., & Marshall, S. 2010a, SoPh, 262, 449, doi: 10.1007/s11207-009-9492-9
-
[17]
2010b, SSRv, 151, 243, doi: 10.1007/s11214-010-9630-6
Labrosse, N., Heinzel, P., Vial, J.-C., et al. 2010b, SSRv, 151, 243, doi: 10.1007/s11214-010-9630-6
-
[18]
Lemen, J. R., Title, A. M., Akin, D. J., et al. 2012, SoPh, 275, 17, doi: 10.1007/s11207-011-9776-8
-
[19]
2016, in European conference on computer vision, Springer, 21–37
Liu, W., Anguelov, D., Erhan, D., et al. 2016, in European conference on computer vision, Springer, 21–37
work page 2016
-
[20]
Mackay, D. H., Karpen, J. T., Ballester, J. L., Schmieder, B., & Aulanier, G. 2010, SSRv, 151, 333, doi: 10.1007/s11214-010-9628-0
-
[21]
McMullan, L., Antolin, P., Kleint, L., & Panos, B. 2026, Astronomy & Astrophysics, doi: 10.1051/0004-6361/202557855 O’Dwyer, B., Del Zanna, G., Mason, H. E., Weber, M. A., & Tripathi, D. 2010, A&A, 521, A21, doi: 10.1051/0004-6361/201014872
-
[22]
2014, Living Reviews in Solar Physics, 11, 1, doi: 10.12942/lrsp-2014-1
Parenti, S. 2014, Living Reviews in Solar Physics, 11, 1, doi: 10.12942/lrsp-2014-1
-
[23]
2019, Advances in neural information processing systems, 32
Paszke, A., Gross, S., Massa, F., et al. 2019, Advances in neural information processing systems, 32
work page 2019
-
[24]
Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, SoPh, 275, 3, doi: 10.1007/s11207-011-9841-3
-
[25]
2016, in Proceedings of the IEEE conference on computer vision and pattern recognition, 779–788
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. 2016, in Proceedings of the IEEE conference on computer vision and pattern recognition, 779–788
work page 2016
-
[26]
2017, in Proceedings of the IEEE conference on computer vision and pattern recognition, 7263–7271 16
Redmon, J., & Farhadi, A. 2017, in Proceedings of the IEEE conference on computer vision and pattern recognition, 7263–7271 16
work page 2017
-
[27]
YOLOv3: An Incremental Improvement
Redmon, J., & Farhadi, A. 2018, arXiv e-prints, arXiv:1804.02767, doi: 10.48550/arXiv.1804.02767
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1804.02767 2018
-
[28]
A., Muglach, K., M¨ ostl, C., et al
Reiss, M. A., Muglach, K., M¨ ostl, C., et al. 2021, ApJ, 913, 28, doi: 10.3847/1538-4357/abf2c8
-
[29]
2015, Advances in neural information processing systems, 28
Ren, S., He, K., Girshick, R., & Sun, J. 2015, Advances in neural information processing systems, 28
work page 2015
-
[30]
2019, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 658–666
Rezatofighi, H., Tsoi, N., Gwak, J., et al. 2019, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 658–666
work page 2019
-
[31]
Ronneberger, O., Fischer, P., & Brox, T. 2015, in International Conference on Medical image computing and computer-assisted intervention, Springer, 234–241
work page 2015
-
[32]
arXiv preprint arXiv:2012.06917 (2020)
Singh, A., Bay, A., & Mirabile, A. 2020, arXiv e-prints, arXiv:2012.06917, doi: 10.48550/arXiv.2012.06917 SunPy Community, Barnes, W. T., Bobra, M. G., et al. 2020, ApJ, 890, 68, doi: 10.3847/1538-4357/ab4f7a
-
[33]
Thompson, W. T., & Brekke, P. 2000, SoPh, 195, 45, doi: 10.1023/A:1005203001242
-
[34]
2010, ApJ, 717, 973, doi: 10.1088/0004-637X/717/2/973
Wang, Y., Cao, H., Chen, J., et al. 2010, ApJ, 717, 973, doi: 10.1088/0004-637X/717/2/973
-
[35]
Zeiler, M. D., & Fergus, R. 2014, in European conference on computer vision, Springer, 818–833
work page 2014
-
[36]
Zhang, T., Hao, Q., & Chen, P. F. 2024, ApJS, 272, 5, doi: 10.3847/1538-4365/ad3039
-
[37]
2024, ApJ, 965, 150, doi: 10.3847/1538-4357/ad2be9
Zheng, Z., Hao, Q., Qiu, Y., et al. 2024, ApJ, 965, 150, doi: 10.3847/1538-4357/ad2be9
-
[38]
2019, SoPh, 294, 117, doi: 10.1007/s11207-019-1517-4
Zhu, G., Lin, G., Wang, D., Liu, S., & Yang, X. 2019, SoPh, 294, 117, doi: 10.1007/s11207-019-1517-4
-
[39]
2025, ApJ, 980, 176, doi: 10.3847/1538-4357/adadff
Zhu, G., Lin, G., Yang, X., & Zeng, C. 2025, ApJ, 980, 176, doi: 10.3847/1538-4357/adadff
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.