Exploiting Multicast for Accelerating Collective Communication
Pith reviewed 2026-05-22 04:04 UTC · model grok-4.3
The pith
MultiWrite adopts multicast principles to remove redundant packet copies in many-to-many collective communications, directly lowering operator latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MultiWrite is a novel many-to-many transmission semantic that eliminates redundant packets by adopting multicast principles while addressing critical limitations of traditional multicast for AI workloads. These limitations include heavy management plane overhead and ecosystem compatibility issues. Implemented on Ascend NPUs, the approach produces collective operators whose latency is reduced by up to 33 percent in long-term stress tests on commercially deployed devices.
What carries the argument
MultiWrite, a many-to-many transmission semantic that transmits each data item once to multiple receivers using multicast principles instead of unicast duplication.
If this is right
- AllGather and AlltoAll operators transmit fewer packets and finish faster when they use the MultiWrite semantic.
- Network links carry only one copy of each data item instead of one copy per receiver.
- Collective communication latency drops without requiring changes to the surrounding AI training software stack.
- End-to-end training and inference times improve because the communication phase no longer dominates as heavily.
Where Pith is reading between the lines
- The same redundancy-removal idea could be ported to other accelerator interconnects that support multicast-like primitives.
- If integrated into standard collective libraries, the technique would lower communication costs for any framework running large-model workloads.
- Further work might combine MultiWrite with topology-aware scheduling to reduce contention on shared network resources.
Load-bearing premise
The critical limitations of traditional multicast can be fixed for AI workloads without creating new performance or compatibility problems.
What would settle it
A head-to-head measurement on the same Ascend NPU cluster in which MultiWrite-based AllGather or AlltoAll operators show no latency reduction or introduce compatibility failures compared with standard unicast implementations.
Figures

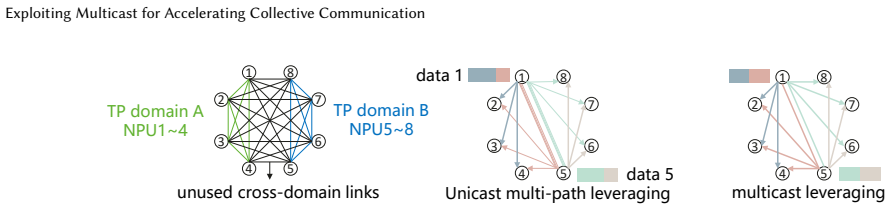

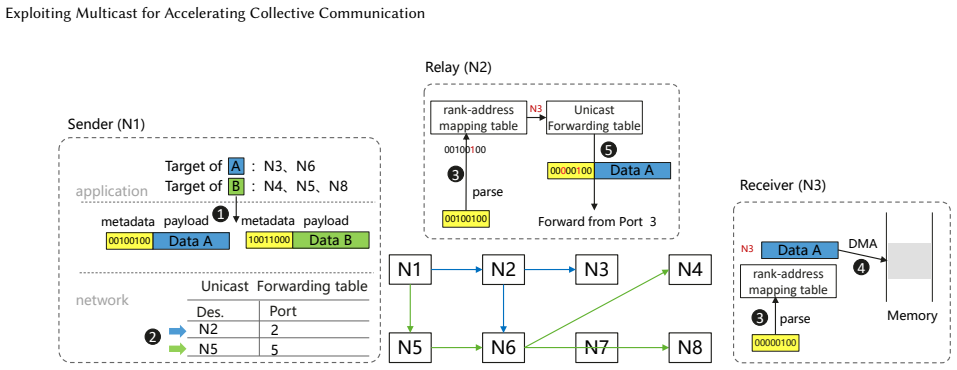





read the original abstract
Reducing collective communication latency is a critical goal for large model training and inference in both academia and industry. Many-to-many communications, such as AllGather and AlltoAll (dispatch), are core components of modern parallelization strategies. State-of-the-art implementations of these communications rely on unicast-based writes and transmit duplicate copies of the same data across physical links for multiple receivers. This redundant transmission congests network bottlenecks and degrades end-to-end latency. We present MultiWrite, a novel many-to-many transmission semantic that eliminates redundant packets to directly reduce operator latency. MultiWrite adopts multicast principles while addressing critical limitations of traditional multicast for AI workloads. These limitations include heavy management plane overhead and ecosystem compatibility issues. We implement MultiWrite on Ascend NPUs. Long-term stress tests demonstrate that our MultiWrite-based operators achieve up to 33% latency reduction on commercially deployed devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MultiWrite, a novel many-to-many transmission semantic that leverages multicast principles to eliminate redundant packet transmissions in collective operations such as AllGather and AlltoAll for AI model training. It claims to address the management overhead and compatibility issues of traditional multicast, with an implementation on Ascend NPUs demonstrating up to 33% latency reduction in long-term stress tests on deployed devices.
Significance. If the empirical claims hold after verification, this could meaningfully advance communication efficiency in large-scale distributed AI training by reducing redundant transmissions without major ecosystem overhauls. The emphasis on practical deployment on commercial hardware and long-term testing is a positive aspect that strengthens applicability.
major comments (2)
- [Abstract] Abstract: The reported up to 33% latency reduction from stress tests on deployed devices lacks any description of experimental setup, baselines, error bars, number of trials, or measurement methodology. This detail is load-bearing for the central empirical claim and prevents assessment of result robustness.
- [Implementation] Implementation section: The assertion that MultiWrite resolves traditional multicast's heavy management plane overhead and ecosystem compatibility issues for AI workloads is not supported by concrete mechanisms (e.g., lightweight group management for dynamic jobs or framework integration details) or quantified overhead measurements showing no new penalties are introduced.
minor comments (1)
- [Abstract] Clarify the exact duration and workload conditions for the 'long-term stress tests' to aid reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and constructive review of our manuscript. Below we respond to each major comment and indicate the revisions made to address them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported up to 33% latency reduction from stress tests on deployed devices lacks any description of experimental setup, baselines, error bars, number of trials, or measurement methodology. This detail is load-bearing for the central empirical claim and prevents assessment of result robustness.
Authors: We concur that the abstract does not include sufficient information on the experimental setup, baselines, error bars, number of trials, or measurement methodology for the reported latency reductions. This is a valid observation. In the revised manuscript, we have updated the abstract to incorporate a high-level description of these elements and have significantly expanded the 'Evaluation' section to provide full details on the experimental methodology, including baselines (unicast-based collective implementations), error bars from multiple runs, number of trials, and the specifics of the long-term stress tests on deployed Ascend NPUs. These changes allow for a thorough assessment of the result robustness. revision: yes
-
Referee: [Implementation] Implementation section: The assertion that MultiWrite resolves traditional multicast's heavy management plane overhead and ecosystem compatibility issues for AI workloads is not supported by concrete mechanisms (e.g., lightweight group management for dynamic jobs or framework integration details) or quantified overhead measurements showing no new penalties are introduced.
Authors: We acknowledge the referee's point that the implementation section lacks concrete mechanisms and quantified measurements supporting the resolution of management plane overhead and ecosystem compatibility issues. To address this, we have revised the implementation section to detail the lightweight group management mechanisms designed for dynamic AI workloads, including framework integration specifics, and have added overhead quantification results demonstrating that MultiWrite introduces no additional penalties compared to traditional approaches. This provides the necessary support for our assertions. revision: yes
Circularity Check
No significant circularity; claims rest on implementation and empirical benchmarks
full rationale
The paper describes an engineering system (MultiWrite) for many-to-many collective communication that adopts multicast principles while addressing management overhead and compatibility. Its central claims are validated through implementation on Ascend NPUs and long-term stress tests reporting up to 33% latency reduction. No mathematical derivation chain, equations, fitted parameters, or predictions appear in the abstract or description. The contribution is self-contained via concrete mechanisms and external benchmark results on deployed hardware, with no reduction of outputs to inputs by construction or self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MultiWrite
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madanlal Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing opti- mal collective algorithms. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 62–75. Exploiting Multicast for Accelerating Collective Communication
work page 2021
-
[2]
Hiascend CANN. 2025. HcclAllGather.https://www.hiascend.com/ document/detail/en/canncommercial/800/apiref/hcclapiref/hcclcpp_ 07_0023.html. Accessed: 2026-05-05
work page 2025
-
[3]
Hiascend CANN. 2025. HcclAlltoAllV.https://www.hiascend.com/ document/detail/en/canncommercial/800/apiref/hcclapiref/hcclcpp_ 07_0027.html. Accessed: 2026-05-05
work page 2025
-
[4]
Mouxiang Chen, Binyuan Hui, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Jianling Sun, Junyang Lin, and Zhongxin Liu. 2026. Parallel scaling law for language models.Advances in Neural Information Processing Systems38 (2026), 118958–118998
work page 2026
-
[5]
DeepSeek-AI, Aixin Liu, et al. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL]https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[7]
Yida Gu, Fakang Wang, Jianhao Fu, Zhenhang Sun, Qianyu Zhang, Hairui Zhao, Xingchen Liu, Yang Tian, Wenjing Huang, Zedong Liu, et al. 2026. CCL-D: A High-Precision Diagnostic System for Slow and Hang Anomalies in Large-Scale Model Training. InProceedings of the 31st ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 425–438
work page 2026
-
[8]
Guoliang He, Youhe Jiang, Wencong Xiao, Jiang Kaihua, Shuguang Wang, Jun Wang, Du Zixian, Zhuo Jiang, Xinlei Zhang, Binhang Yuan, et al. 2026. Efficient pre-training of llms via topology-aware com- munication alignment on more than 9600 gpus.Advances in Neural Information Processing Systems38 (2026), 147100–147126
work page 2026
-
[9]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guid- ance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Torsten Hoefler, Christian Siebert, and Wolfgang Rehm. 2007. A practically constant-time MPI Broadcast Algorithm for large-scale InfiniBand Clusters with Multicast. In2007 IEEE International Parallel and Distributed Processing Symposium. IEEE, 1–8
work page 2007
-
[11]
Chengyuan Huang, Yixiao Gao, Wei Chen, Duoxing Li, Yibo Xiao, Ruyi Zhang, Chen Tian, Xiaoliang Wang, Wanchun Dou, Guihai Chen, et al
-
[12]
In2023 IEEE 31st International Conference on Network Protocols (ICNP)
Mc-rdma: Improving replication performance of rdma-based distributed systems with reliable multicast support. In2023 IEEE 31st International Conference on Network Protocols (ICNP). IEEE, 1–11
-
[13]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. 2019. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems32 (2019)
work page 2019
-
[14]
Huawei Technologies Co., Ltd. 2026. Huawei Collective Communi- cation Library (HCCL).https://www.hiascend.com/software/cann. Online; accessed 14-May-2026
work page 2026
-
[15]
2024.InfiniBand Architecture Specifica- tion, Volume 1: General Specifications(release 1.8 ed.)
InfiniBand Trade Association. 2024.InfiniBand Architecture Specifica- tion, Volume 1: General Specifications(release 1.8 ed.). Technical Report. InfiniBand Trade Association.https://www.infinibandta.org/ibta- specification/
work page 2024
-
[16]
Mikhail Khalilov, Salvatore Di Girolamo, Marcin Chrapek, Rami Nudelman, Gil Bloch, and Torsten Hoefler. 2024. Network-offloaded bandwidth-optimal broadcast and Allgather for distributed AI. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–17
work page 2024
-
[17]
Kyuho J Lee. 2021. Architecture of neural processing unit for deep neural networks. InAdvances in computers. Vol. 122. Elsevier, 217–245
work page 2021
-
[18]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. 2020. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Wenxue Li, Junyi Zhang, Yufei Liu, Gaoxiong Zeng, Zilong Wang, Chaoliang Zeng, Pengpeng Zhou, Qiaoling Wang, and Kai Chen. 2024. Cepheus: accelerating datacenter applications with high-performance roce-capable multicast. In2024 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE, 908–921
work page 2024
-
[21]
Jinkun Lin, Ziheng Jiang, Zuquan Song, Sida Zhao, Menghan Yu, Zhanghan Wang, Chenyuan Wang, Zuocheng Shi, Xiang Shi, Wei Jia, et al. 2025. Understanding stragglers in large model training using what-if analysis. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). 483–498
work page 2025
-
[22]
Jiuxing Liu, Amith R Mamidala, and Dhabaleswar K Panda. 2004. Fast and scalable MPI-level broadcast using InfiniBand’s hardware multi- cast support. In18th International Parallel and Distributed Processing Symposium, 2004. Proceedings.IEEE, 10
work page 2004
-
[23]
Qian Liu and Robert D Russell. 2014. IBRMP: A Reliable Multicast Protocol for InfiniBand. In2014 IEEE 22nd Annual Symposium on High- Performance Interconnects. IEEE, 79–86
work page 2014
-
[24]
Amith R Mamidala, Hyun-Wook Jin, and Dhabaleswar K Panda. 2005. Efficient hardware multicast group management for multiple mpi communicators over infiniband. InEuropean Parallel Virtual Ma- chine/Message Passing Interface Users’ Group Meeting. Springer, 388– 398
work page 2005
-
[25]
Microsoft Research. 2022. MSCCL: Microsoft Collective Communica- tion Library.https://github.com/microsoft/msccl. Online; accessed 14-May-2026
work page 2022
-
[26]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. 2021. Efficient large-scale language model training on gpu clusters using megatron- lm. InProceedings of the international conference for high performance computing, netwo...
work page 2021
-
[27]
NVIDIA Corporation. 2026. NCCL User Guide: Collective Opera- tions.https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/ usage/collectives.html. Online; accessed 14-May-2026
work page 2026
-
[28]
NVIDIA Corporation. 2026. NVIDIA Collective Communication Li- brary (NCCL).https://developer.nvidia.com/nccl. Online; accessed 14-May-2026
work page 2026
-
[29]
NVIDIA Corporation. 2026. NVIDIA Collective Communication Li- brary (NCCL) User Guide.https://docs.nvidia.com/deeplearning/nccl/ user-guide/docs/. Online; accessed 14-May-2026
work page 2026
-
[30]
NVIDIA Corporation. 2026. NVIDIA NVLink and NVLink Switch. https://www.nvidia.com/en-us/data-center/nvlink/. Accessed: 2026- 05-12
work page 2026
-
[31]
Open Compute Project. 2025. Introducing ESUN: Ad- vancing Ethernet for Scale-Up AI Infrastructure at OCP. https://www.opencompute.org/blog/introducing-esun-advancing- ethernet-for-scale-up-ai-infrastructure-at-ocp. Accessed: 2026-05- 12
work page 2025
-
[32]
2025.OCP Scale-Up Ethernet (SUE) Speci- fication
Open Compute Project. 2025.OCP Scale-Up Ethernet (SUE) Speci- fication. Technical Report. Open Compute Project.https://www. opencompute.org/documents/ocp-sue-spec-final-pdf-1Accessed: 2026-05-12
work page 2025
-
[33]
openEuler Community. 2026. UMDK Repository.https://gitcode.com/ openeuler/umdk. Accessed: 2026-05-11
work page 2026
-
[34]
Alexander Sergeev and Mike Del Balso. 2018. Horovod: fast and easy distributed deep learning in TensorFlow.arXiv preprint arXiv:1802.05799(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. {TACCL}: Guiding collective algorithm synthe- sis using communication sketches. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 593–612
work page 2023
-
[36]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. Chao Xu, Xu Zhang, Zihang Luo, Yuyan Wu, Guoxin Qian, Yufeng Yao, and CHIHYUNG WANG, Jingbin Zhou arXiv preprint arXiv:1909.08053(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
UALink Consortium. 2025.UALink 1.0 White Paper. Technical Report. UALink Consortium.https://ualinkconsortium.org/wp- content/uploads/2025/04/UALink-1.0-White_Paper_FINAL.pdfAc- cessed: 2026-05-12
work page 2025
-
[38]
2025.Ultra Ethernet Specification
Ultra Ethernet Consortium. 2025.Ultra Ethernet Specification. Techni- cal Report. Ultra Ethernet Consortium.https://ultraethernet.org/wp- content/uploads/sites/20/2025/06/UE-Specification-6.11.25.pdfAc- cessed: 2026-05-12
work page 2025
-
[39]
vLLM Team. 2024. vLLM v0.6.0: 2.7x Throughput Improvement and 5x Latency Reduction.https://vllm.ai/blog/perf-update. Online; accessed 14-May-2026
work page 2024
-
[40]
Rosen, Andrew Dolganow, Tony Przy- gienda, and Sam Aldrin
IJsbrand Wijnands, Eric C. Rosen, Andrew Dolganow, Tony Przy- gienda, and Sam Aldrin. 2017. Multicast Using Bit Index Explicit Replication (BIER). RFC 8279. doi:10.17487/RFC8279
-
[41]
Rosen, Andrew Dolganow, Jeff Tantsura, Sam Aldrin, and Israel Meilik
IJsbrand Wijnands, Eric C. Rosen, Andrew Dolganow, Jeff Tantsura, Sam Aldrin, and Israel Meilik. 2018. Encapsulation for Bit Index Explicit Replication (BIER) in MPLS and Non-MPLS Networks. RFC
work page 2018
-
[42]
doi:10.17487/RFC8296
- [43]
-
[44]
Xiaohu Xu, Mach Chen, Keyur Patel, IJsbrand Wijnands, Tony Przy- gienda, and Zhaohui (Jeffrey) Zhang. 2025. BGP Extensions for Bit Index Explicit Replication (BIER). RFC 9793. doi:10.17487/RFC9793
- [45]
-
[46]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. 2022. Alpa: Automating inter-and {Intra-Operator} parallelism for distributed deep learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 559–578. CHIHYUNG WANG, Jingbin Zhou„
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.