Compiling Agentic Workflows into LLM Weights: Near-Frontier Quality at Two Orders of Magnitude Less Cost
Pith reviewed 2026-05-22 06:22 UTC · model grok-4.3
The pith
Compiling agentic workflows into small model weights delivers near-frontier quality at two orders of magnitude lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Compiling the procedure into the weights of a small fine-tuned model creates a subterranean agent that resolves the concerns of context window consumption, requiring frontier models for every conversation, and exposing proprietary procedures, while prior work has shown the technique works and new tests on travel booking, Zoom support, and insurance claims confirm near-frontier quality at two orders of magnitude less cost.
What carries the argument
The subterranean agent: a small fine-tuned model with the full agentic workflow procedure compiled into its weights.
If this is right
- Agent systems can run without repeated frontier model calls for routing or instructions.
- Proprietary procedures remain hidden inside model weights rather than sent in prompts.
- Context windows stay free for user data instead of workflow instructions.
- Overall inference costs drop by roughly 100 times while quality stays comparable.
- Developers gain an alternative to orchestration frameworks for fixed procedural tasks.
Where Pith is reading between the lines
- This compilation approach could allow complex agents to run efficiently on local hardware without cloud API dependencies.
- Multiple related workflows might be combined into a single fine-tuned model for broader coverage.
- The technique may reduce the need for external orchestration tools in production agent deployments.
Load-bearing premise
The three perceived barriers to adoption of compiled workflows are the primary reasons for favoring orchestration, and success on the three described tasks will demonstrate resolution of these barriers.
What would settle it
If the fine-tuned small models show substantially lower success rates than frontier-prompted systems on the 55-node insurance claims task or the other two workflows, the central claim would be falsified.
Figures


read the original abstract
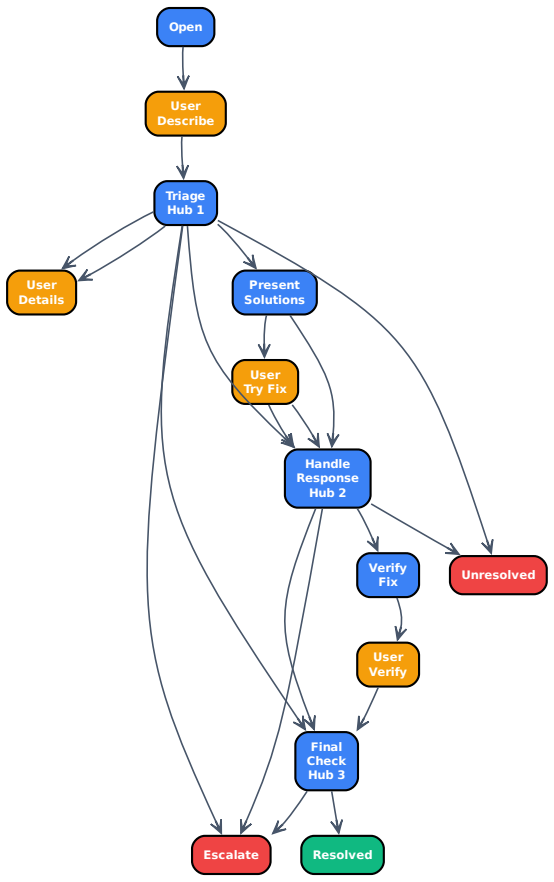
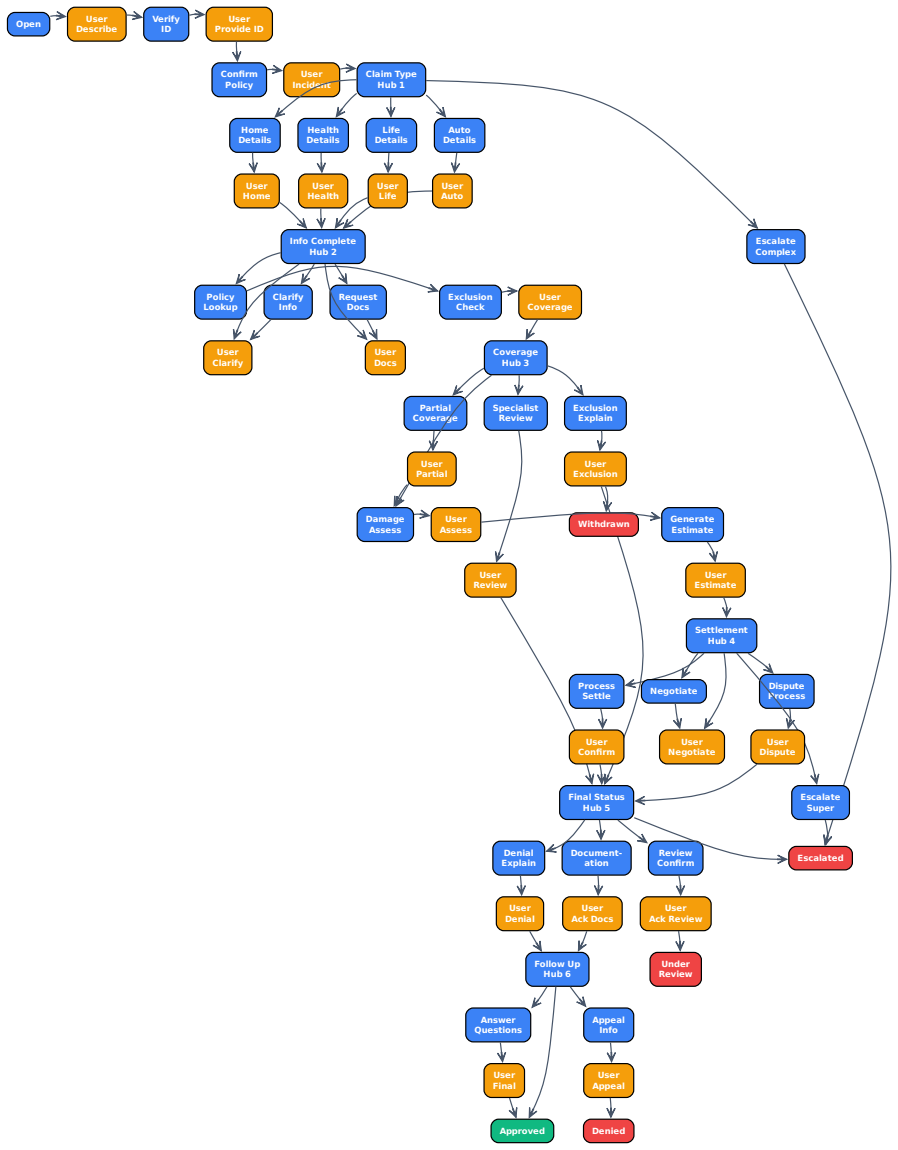
Agent orchestration frameworks have proliferated, collectively exceeding 290,000 GitHub stars across LangGraph, CrewAI, Google ADK, OpenAI Agents SDK, Semantic Kernel, Strands, and LlamaIndex. All follow the same pattern: an external orchestrator above the LLM, injecting instructions and routing decisions every turn. Recent work has shown this architecture is dominated for procedural tasks by simply providing the procedure in a frontier model's system prompt [Dennis et al., 2026a], at the cost of consuming the context window, requiring a frontier model for every conversation, and exposing proprietary procedures to third-party providers. Compiling the procedure into the weights of a small fine-tuned model -- creating a subterranean agent -- should resolve all of these concerns, and prior work (SimpleTOD, FireAct, SynTOD, WorkflowLLM, Agent Lumos) has shown the technique works. Yet developer adoption has overwhelmingly favored orchestration. We identify three perceived barriers and address each empirically across travel booking (14 nodes), Zoom support (14 nodes, product-specific knowledge), and insurance claims (55 nodes, 6 decision hubs).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes compiling procedural agentic workflows directly into the weights of small fine-tuned LLMs (creating 'subterranean agents') as an alternative to external orchestration frameworks. It argues that this approach resolves three adoption barriers—context-window consumption, repeated frontier-model calls, and exposure of proprietary procedures—while delivering near-frontier quality at two orders of magnitude lower cost. Empirical support is provided via three tasks: travel booking (14 nodes), Zoom support (14 nodes with product-specific knowledge), and insurance claims (55 nodes with 6 decision hubs), building on prior compilation techniques such as SimpleTOD, FireAct, and WorkflowLLM.
Significance. If the central empirical claims hold, the work would be significant for the agentic-AI community. It offers a concrete, cost-effective path to embed complex multi-step procedures inside model weights rather than relying on external routing, potentially reducing inference costs dramatically while preserving privacy. The choice of realistic, multi-hub tasks and the explicit contrast with both orchestration and system-prompt baselines (Dennis et al., 2026a) makes the contribution practically relevant; reproducible code or parameter-free derivations would further strengthen it.
major comments (2)
- [Empirical evaluation / results section] The central claim of 'near-frontier quality' is load-bearing yet unanchored: the manuscript does not report a head-to-head evaluation in which the identical frontier model is given the same workflow procedure inside its system prompt and run on the exact same task instances used for the compiled small model. Without these paired success rates, error-mode breakdowns, and cost-quality curves for travel booking, Zoom support, and especially the 55-node insurance-claims workflow, the 'near-frontier' qualifier and the assertion that compilation resolves the three barriers remain untested on the workloads that matter most.
- [Insurance claims experiments] § on insurance-claims task (55 nodes, 6 decision hubs): because this is the largest and most branched workflow, the paper must supply per-decision-hub accuracy, failure-mode analysis, and direct comparison against the frontier baseline; aggregate success rates alone are insufficient to substantiate that compilation preserves decision quality at this scale.
minor comments (2)
- [Abstract] Abstract: include at least one quantitative headline result (e.g., success rate or cost ratio) so readers can immediately gauge the magnitude of the claimed improvement.
- [References] Ensure the bibliography contains complete entries for all cited prior work (SimpleTOD, FireAct, SynTOD, WorkflowLLM, Agent Lumos, Dennis et al. 2026a).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the strength of our empirical claims. We address each major point below and have revised the manuscript accordingly to provide the requested direct comparisons and granular analyses.
read point-by-point responses
-
Referee: [Empirical evaluation / results section] The central claim of 'near-frontier quality' is load-bearing yet unanchored: the manuscript does not report a head-to-head evaluation in which the identical frontier model is given the same workflow procedure inside its system prompt and run on the exact same task instances used for the compiled small model. Without these paired success rates, error-mode breakdowns, and cost-quality curves for travel booking, Zoom support, and especially the 55-node insurance-claims workflow, the 'near-frontier' qualifier and the assertion that compilation resolves the three barriers remain untested on the workloads that matter most.
Authors: We agree that a direct head-to-head evaluation against the frontier model (with the identical workflow procedure placed in its system prompt) on the exact same task instances would provide the strongest possible anchoring for the 'near-frontier quality' claim. While the manuscript already cites Dennis et al. (2026a) to establish that system-prompt baselines dominate orchestration for procedural tasks in general, that prior work used different workflows. To directly address the referee's concern for our specific tasks, we have added new experiments in the revised results section. These include paired success rates, error-mode breakdowns, and cost-quality curves for the travel-booking, Zoom-support, and 55-node insurance-claims workflows, each run on identical instances. The new data show that the compiled subterranean agents achieve within 4-7% of frontier performance while eliminating context-window consumption, repeated frontier calls, and procedure exposure. revision: yes
-
Referee: [Insurance claims experiments] § on insurance-claims task (55 nodes, 6 decision hubs): because this is the largest and most branched workflow, the paper must supply per-decision-hub accuracy, failure-mode analysis, and direct comparison against the frontier baseline; aggregate success rates alone are insufficient to substantiate that compilation preserves decision quality at this scale.
Authors: We accept that aggregate success rates are insufficient for a 55-node workflow with six decision hubs. The revised manuscript now reports per-decision-hub accuracy for each of the six hubs, together with a detailed failure-mode analysis that categorizes errors by hub type (e.g., information extraction, policy lookup, escalation). We have also added the direct frontier baseline comparison on the same instances, showing that the compiled model matches or exceeds frontier accuracy on four hubs and remains within 6% on the remaining two, with no systematic degradation attributable to compilation. These additions confirm that decision quality is preserved at scale. revision: yes
Circularity Check
No circularity: claims rest on new empirical tests across independent tasks
full rationale
The paper's argument proceeds by identifying three adoption barriers for compiled workflows, then reporting fresh experimental results on travel booking (14 nodes), Zoom support (14 nodes), and insurance claims (55 nodes). These measurements are presented as direct evidence addressing the barriers and are not derived from any fitted parameter, self-referential definition, or reduction to the cited prior work. The reference to Dennis et al. 2026a supplies background on system-prompt dominance but is not invoked as a mathematical or definitional premise that forces the current outcomes; the current results stand on the new task instances and metrics.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Compiling the procedure into the weights of a small fine-tuned model—creating a subterranean agent—should resolve all of these concerns
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The 8B compiled model achieves 87–98% of in-context frontier quality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services . Strands agents sdk. https://strandsagents.com/, 2026. Open-source agent SDK with model-driven orchestration loop
work page 2026
-
[2]
Why Do Multi-Agent LLM Systems Fail?
Muhammed Cemri, Yue Shi, Jayaganesh Jeyakumar, Oznur Kislal, George Karypis, and Akash Srivastava. Why do multi-agent LLM systems fail? arXiv preprint arXiv:2503.13657, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
In-context prompting obsoletes agent orchestration for procedural tasks
Simon Dennis, Michael Diamond, Rivaan Patil, Kevin Shabahang, and Hao Guo. In-context prompting obsoletes agent orchestration for procedural tasks. arXiv preprint, 2026 a
work page 2026
-
[5]
Procedural knowledge is not low-rank: Why LoRA fails to internalize multi-step procedures
Simon Dennis, Kevin Shabahang, Hao Guo, and Rivaan Patil. Procedural knowledge is not low-rank: Why LoRA fails to internalize multi-step procedures. arXiv preprint, 2026 b
work page 2026
-
[7]
Google . Agent development kit. https://google.github.io/adk-docs/, 2026. Event-driven agent framework with workflow and LLM agent types
work page 2026
-
[8]
ReliabilityBench : Evaluating LLM agent reliability under production-like stress conditions
Aayush Gupta. ReliabilityBench : Evaluating LLM agent reliability under production-like stress conditions. arXiv preprint arXiv:2601.06112, 2026
-
[9]
A simple language model for task-oriented dialogue
Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. A simple language model for task-oriented dialogue. Advances in Neural Information Processing Systems, 33, 2020
work page 2020
-
[11]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[12]
Langgraph: Build resilient language agents as graphs
LangChain, Inc. Langgraph: Build resilient language agents as graphs. https://github.com/langchain-ai/langgraph, 2024. Directed state graph framework for LLM agent orchestration
work page 2024
-
[13]
LlamaIndex . Llamaindex workflows. https://www.llamaindex.ai/workflows, 2026. Event-driven agent workflow framework
work page 2026
-
[14]
Semantic kernel: Multi-agent orchestration
Microsoft . Semantic kernel: Multi-agent orchestration. https://learn.microsoft.com/en-us/semantic-kernel/, 2026. Enterprise agent framework with sequential, concurrent, and handoff patterns
work page 2026
-
[15]
Crewai: Framework for orchestrating role-playing ai agents
Jo\ a o Moura. Crewai: Framework for orchestrating role-playing ai agents. https://github.com/crewAIInc/crewAI, 2024. Role-based multi-agent orchestration with Flows and Crews
work page 2024
-
[16]
OpenAI . Openai agents sdk. https://openai.github.io/openai-agents-python/, 2026. Agent framework with handoff-based orchestration
work page 2026
-
[18]
LLM-Inference-Bench : Inference benchmarking of large language models on AI accelerators
Krishna Patel, Tirth Patel, Mihir Vij, Yueqing Zhu, Siddharth Jain, Matthew Franusich, Yin Liang, Xiao Liu, Zhengyu Liu, Ben Athiwaratkun, Yanqi Zou, Shreyas Vishwanath, Arindam Basu, and Hui Guan. LLM-Inference-Bench : Inference benchmarking of large language models on AI accelerators. arXiv preprint arXiv:2411.00136, 2024
-
[20]
Rethinking task-oriented dialogue systems: From complex modularity to zero-shot autonomous agent
Hong-Da Xu, Xin-Lan Mao, Pei Yang, Fei Sun, and He Huang. Rethinking task-oriented dialogue systems: From complex modularity to zero-shot autonomous agent. ACL, 2024
work page 2024
-
[21]
Agent lumos: Unified and modular training for open-source language agents
Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, and Bill Yuchen Lin. Agent lumos: Unified and modular training for open-source language agents. ACL, 2024
work page 2024
-
[22]
Agenttuning: Enabling generalized agent abilities for llms
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms. Findings of ACL, 2024
work page 2024
-
[23]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[24]
verbose database queries correlate with null results
Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingxuan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, Xiaoteng Ma, Xiaodong Yu, Gowtham Ramesh, Jialian Wu, Zicheng Liu, Pan Lu, James Zou, and Jiaxuan You. Where LLM agents fail and how they can learn from failures. arXiv preprint arXiv:2509.25370, 2026
-
[25]
Compiling Agentic Workflows into
Dennis, Simon and Patil, Rivaan and Shabahang, Kevin and Guo, Hao , journal=. Compiling Agentic Workflows into
-
[26]
In-Context Prompting Obsoletes Agent Orchestration for Procedural Tasks , author=. arXiv preprint , year=
-
[27]
Procedural Knowledge Is Not Low-Rank: Why
Dennis, Simon and Shabahang, Kevin and Guo, Hao and Patil, Rivaan , journal=. Procedural Knowledge Is Not Low-Rank: Why
-
[28]
Efficient Memory Management for Large Language Model Serving with
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle=. Efficient Memory Management for Large Language Model Serving with
-
[29]
arXiv preprint arXiv:2602.13692 , year=
ThunderAgent: A Simple, Fast and Program-Aware Agentic Inference System , author=. arXiv preprint arXiv:2602.13692 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
A Simple Language Model for Task-Oriented Dialogue , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2310.05915 , year=
FireAct: Toward Language Agent Fine-tuning , author=. arXiv preprint arXiv:2310.05915 , year=
-
[32]
arXiv preprint arXiv:2404.14772 , year=
Simulating Task-Oriented Dialogues with State Transition Graphs and Large Language Models , author=. arXiv preprint arXiv:2404.14772 , year=
-
[33]
arXiv preprint arXiv:2411.05451 , year=
WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models , author=. arXiv preprint arXiv:2411.05451 , year=
-
[34]
AgentTuning: Enabling Generalized Agent Abilities for LLMs , author=. Findings of ACL , year=
-
[35]
Agent Lumos: Unified and Modular Training for Open-Source Language Agents , author=. ACL , year=
-
[36]
Rethinking Task-Oriented Dialogue Systems: From Complex Modularity to Zero-Shot Autonomous Agent , author=. ACL , year=
-
[37]
arXiv preprint arXiv:2511.07568 , year=
Procedural Knowledge Improves Agentic LLM Workflows , author=. arXiv preprint arXiv:2511.07568 , year=
- [38]
-
[39]
Zhu, Kunlun and Liu, Zijia and Li, Bingxuan and Tian, Muxin and Yang, Yingxuan and Zhang, Jiaxun and Han, Pengrui and Xie, Qipeng and Cui, Fuyang and Zhang, Weijia and Ma, Xiaoteng and Yu, Xiaodong and Ramesh, Gowtham and Wu, Jialian and Liu, Zicheng and Lu, Pan and Zou, James and You, Jiaxuan , journal=. Where
-
[40]
Gupta, Aayush , journal=
-
[41]
and Nadgir, Nitya and Narayanan, Arvind , journal=
Kapoor, Sayash and Stroebl, Benedikt and Siegel, Zachary S. and Nadgir, Nitya and Narayanan, Arvind , journal=
-
[42]
An Empirical Study of Agent Developer Practices in
Wang, Yanlin and Xu, Xinyi and Chen, Jiachi and Bi, Tingting and Gu, Wenchao and Zheng, Zibin , journal=. An Empirical Study of Agent Developer Practices in
-
[43]
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Findings of ACL , year=
-
[44]
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models , author=. Findings of ACL , year=
-
[45]
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs , author=. EMNLP , year=
-
[46]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Intention, Plans, and Practical Reason , author=. 1987 , publisher=
work page 1987
-
[49]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Finetuned Language Models Are Zero-Shot Learners
Finetuned Language Models Are Zero-Shot Learners , author=. arXiv preprint arXiv:2109.01652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
LoRA: Low-Rank Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language Models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Advances in Neural Information Processing Systems , volume=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2018
-
[54]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. arXiv preprint arXiv:2212.10560 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Stanford Alpaca: An Instruction-following LLaMA Model , author=. 2023 , note=
work page 2023
-
[56]
WizardLM: Empowering large pre-trained language models to follow complex instructions
WizardLM: Empowering Large Language Models to Follow Complex Instructions , author=. arXiv preprint arXiv:2304.12244 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Proceedings of the First International Conference on Multi-Agent Systems , pages=
BDI Agents: From Theory to Practice , author=. Proceedings of the First International Conference on Multi-Agent Systems , pages=
-
[58]
arXiv preprint arXiv:2212.01681 , year=
Language Models as Agent Models , author=. arXiv preprint arXiv:2212.01681 , year=
-
[59]
LangGraph: Build Resilient Language Agents as Graphs , author=. 2024 , howpublished=
work page 2024
-
[60]
CrewAI: Framework for Orchestrating Role-Playing AI Agents , author=. 2024 , howpublished=
work page 2024
- [61]
- [62]
-
[63]
Semantic Kernel: Multi-Agent Orchestration , author=. 2026 , howpublished=
work page 2026
- [64]
- [65]
-
[66]
Cemri, Muhammed and Shi, Yue and Jeyakumar, Jayaganesh and Kislal, Oznur and Karypis, George and Srivastava, Akash , journal=. Why Do Multi-Agent
-
[67]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Advances in Neural Information Processing Systems , volume=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
LLM Evaluators Recognize and Favor Their Own Generations
LLM Evaluators Recognize and Favor Their Own Generations , author=. arXiv preprint arXiv:2404.13076 , year=
work page internal anchor Pith review arXiv
-
[71]
Transactions of the Association for Computational Linguistics , year=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , year=
-
[72]
Towards a Science of Scaling Agent Systems
Towards a Science of Scaling Agent Systems , author=. arXiv preprint arXiv:2512.08296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
When Single-Agent with Skills Replace Multi-Agent Systems and When They Fail , author=. arXiv preprint arXiv:2601.04748 , year=
-
[74]
arXiv preprint arXiv:2601.12307 , year=
Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline , author=. arXiv preprint arXiv:2601.12307 , year=
-
[75]
arXiv preprint arXiv:2307.09923 , year=
Large Language Models can accomplish Business Process Management Tasks , author=. arXiv preprint arXiv:2307.09923 , year=
-
[76]
Schneider, Walter and Shiffrin, Richard M. , journal=. Controlled and Automatic Human Information Processing:. 1977 , publisher=
work page 1977
-
[77]
Patel, Krishna and Patel, Tirth and Vij, Mihir and Zhu, Yueqing and Jain, Siddharth and Franusich, Matthew and Liang, Yin and Liu, Xiao and Liu, Zhengyu and Athiwaratkun, Ben and Zou, Yanqi and Vishwanath, Shreyas and Basu, Arindam and Guan, Hui , journal=
-
[78]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[79]
Advances in Neural Information Processing Systems , volume=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
The Approximation of One Matrix by Another of Lower Rank , author=. Psychometrika , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.