Conceptualizing Embeddings: Sparse Disentanglement for Vision-Language Models
Pith reviewed 2026-05-22 05:46 UTC · model grok-4.3
The pith
Vision-language embeddings disentangle into interpretable features via a learned invertible rotation and top-k sparsity without expanding dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
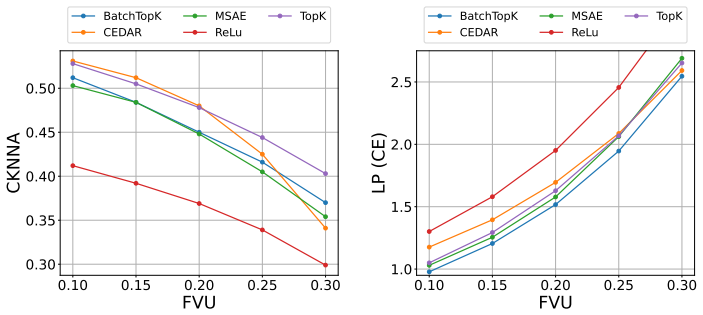
CEDAR learns an invertible transformation of pretrained vision-language embeddings together with a top-k sparsity bottleneck. The resulting axis-aligned coordinates concentrate semantic information so that, in CLIP-like models, each coordinate corresponds to a textual concept and, in generative models such as BLIP, can be decoded into natural language. The approach matches the reconstruction-sparsity performance of overcomplete sparse autoencoders while yielding explanations that are more interpretable and better aligned with human judgments, supporting the view that entanglement can be removed by a change of basis.
What carries the argument
CEDAR: an invertible linear transformation learned post-hoc and paired with a top-k sparsity penalty that aligns semantic content to individual embedding axes.
If this is right
- Individual coordinates become directly mappable to textual concepts in CLIP-style models.
- Coordinates in generative vision-language models can be decoded into readable natural-language descriptions.
- Interpretability improves without sacrificing reconstruction fidelity or increasing embedding size.
- The need for overcomplete feature expansions is removed if a suitable basis change suffices.
Where Pith is reading between the lines
- The same rotation-plus-sparsity idea may transfer to other multimodal embedding spaces where overcomplete expansions are currently used.
- If the axis alignment proves stable across training runs, it could simplify downstream editing or safety interventions on the model.
- Testing whether the learned basis remains consistent when the underlying vision-language model is fine-tuned would clarify the method's robustness.
Load-bearing premise
A learned invertible transformation plus top-k sparsity can concentrate semantic information into axis-aligned coordinates that are meaningfully interpretable with textual concepts or decodable descriptions.
What would settle it
A controlled test in which the transformed coordinates show no better human alignment or concept recovery than the original entangled embeddings at matched sparsity levels.
Figures














read the original abstract
Vision-language models learn powerful multimodal embeddings, yet their internal semantics remain opaque. While sparse autoencoders (SAEs) can extract interpretable features, they rely on expanding the representation dimension, which compromises the original geometry and introduces redundancy. We introduce CEDAR (Conceptual Embedding Disentanglement via Adaptive Rotation), a post-hoc method that reveals the compositional structure of pretrained embeddings without increasing dimensionality. By learning an invertible transformation with a top-$k$ sparsity bottleneck, CEDAR concentrates semantic information into axis-aligned disentangled coordinates. In CLIP-like architecture, individual coordinates can be interpreted with textual concepts, while for generative models such as BLIP, they can be decoded into natural language descriptions. Experiments demonstrate that CEDAR achieves a competitive reconstruction-sparsity trade-off while producing explanations that are more interpretable and better aligned with human perception. Our results suggest that the apparent entanglement in vision-language representations can be resolved through a suitable change of basis, eliminating the need for overcomplete expansions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CEDAR (Conceptual Embedding Disentanglement via Adaptive Rotation), a post-hoc method that learns an invertible linear transformation on pretrained vision-language embeddings (e.g., from CLIP and BLIP) followed by a top-k sparsity bottleneck. The goal is to rotate the embedding space so that semantic information concentrates into axis-aligned coordinates that can be interpreted via textual concepts or decoded into natural language descriptions, without expanding dimensionality as in sparse autoencoders. The authors claim this yields a competitive reconstruction-sparsity trade-off and explanations better aligned with human perception, suggesting that apparent entanglement in VLM representations can be resolved by a suitable change of basis.
Significance. If the central empirical claims are substantiated, CEDAR would provide a dimension-preserving alternative to overcomplete sparse autoencoders for interpreting multimodal embeddings. This could simplify analysis of compositional semantics in vision-language models and reduce redundancy in feature extraction pipelines.
major comments (2)
- [Abstract] Abstract: the claim of a 'competitive reconstruction-sparsity trade-off' and 'more interpretable and better aligned with human perception' is asserted without any reported metrics (e.g., reconstruction MSE, sparsity ratio, human alignment scores), datasets, or baselines, preventing assessment of whether the data supports the superiority statements.
- [Method] Method section (description of the adaptive rotation and optimization): because the transformation is linear and invertible while top-k is applied after the change of basis, any gain in interpretability could arise from selecting high-variance directions rather than from semantic factors becoming independent and axis-aligned; no ablation against a fixed non-learned basis (such as PCA + top-k) is described to isolate the contribution of the learned rotation.
minor comments (1)
- [Abstract] Abstract: the final sentence states that entanglement 'can be resolved through a suitable change of basis'; this phrasing should be qualified to reflect that the result is empirical rather than a general proof.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where we agree that revisions are warranted and outlining the changes we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'competitive reconstruction-sparsity trade-off' and 'more interpretable and better aligned with human perception' is asserted without any reported metrics (e.g., reconstruction MSE, sparsity ratio, human alignment scores), datasets, or baselines, preventing assessment of whether the data supports the superiority statements.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the claims. The Experiments section reports reconstruction MSE, sparsity ratios, human alignment scores, and comparisons against baselines on datasets including MS-COCO and Flickr30k. We will revise the abstract to briefly reference these key results and datasets so that the summary claims are directly tied to the reported evidence. revision: yes
-
Referee: [Method] Method section (description of the adaptive rotation and optimization): because the transformation is linear and invertible while top-k is applied after the change of basis, any gain in interpretability could arise from selecting high-variance directions rather than from semantic factors becoming independent and axis-aligned; no ablation against a fixed non-learned basis (such as PCA + top-k) is described to isolate the contribution of the learned rotation.
Authors: This is a fair point. Although the rotation is optimized end-to-end with the top-k bottleneck to concentrate semantics, it remains possible that a variance-driven basis could produce similar effects. To isolate the benefit of the learned adaptive rotation, we will add an ablation comparing CEDAR against PCA followed by top-k selection in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents CEDAR as a post-hoc learned invertible linear transformation plus top-k sparsity applied to pretrained vision-language embeddings. No equation or step reduces a claimed prediction or disentanglement result to a fitted quantity defined in terms of itself, nor does any load-bearing premise rest on a self-citation chain, imported uniqueness theorem, or ansatz smuggled from prior work. The central claim that a suitable change of basis resolves apparent entanglement is supported by reported reconstruction-sparsity trade-offs and interpretability experiments that remain independent of the target outputs by construction. This is the normal case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-k sparsity level
axioms (1)
- domain assumption Pretrained vision-language embeddings contain compositional semantic information that can be isolated via an invertible linear transformation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We parameterize U as an orthogonal linear operator: U=exp(A−A⊤), which guarantees invertibility U⊤U=I and preserves the geometry of the embedding space ∥Uz∥2=∥z∥2.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CEDAR concentrates semantic information into axis-aligned disentangled coordinates... apparent entanglement... resolved through a suitable change of basis, eliminating the need for overcomplete expansions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. Learning transferable visual models from natural language supervision.arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
work page 2022
-
[3]
Coca: Contrastive captioners are image-text foundation models, 2022
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models, 2022
work page 2022
-
[4]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning (ICML), 2017
work page 2017
-
[5]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PLOS ONE, 10(7):e0130140, 2015
work page 2015
-
[6]
Quantifying attention flow in transformers
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
work page 2020
-
[7]
Transformer interpretability beyond attention visualization
Hila Chefer, Shir Gur, and Lior Wolf. Transformer interpretability beyond attention visualization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[8]
Adam Wróbel, Siddhartha Gairola, Jacek Tabor, Bernt Schiele, Bartosz Zieli´nski, and Dawid Rymarczyk. Dave: Distribution-aware attribution via vit gradient decomposition.arXiv preprint arXiv:2602.06613, 2026
-
[9]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, et al. Concept bottleneck models. InInterna- tional Conference on Machine Learning (ICML), 2020
work page 2020
-
[10]
Towards automatic concept-based explanations
Amirata Ghorbani, James Wexler, James Zou, and Been Kim. Towards automatic concept-based explanations. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[11]
Been Kim, Martin Wattenberg, Justin Gilmer, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[12]
Progress measures for grokking via mechanistic interpretability
Trenton Bricken, Adly Templeton, et al. Towards monosemanticity: Decomposing language models with dictionary learning.arXiv preprint arXiv:2301.05217, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Top-k sparse autoencoders.arXiv preprint arXiv:2501.XXXXX, 2025
Leo Gao et al. Top-k sparse autoencoders.arXiv preprint arXiv:2501.XXXXX, 2025
work page 2025
-
[15]
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan et al. Gated sparse autoencoders.arXiv preprint arXiv:2404.16014, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Interpreting clip with hierarchi- cal sparse autoencoders.arXiv preprint arXiv:2502.20578, 2025
Vladimir Zaigrajew, Hubert Baniecki, and Przemyslaw Biecek. Interpreting clip with hierarchi- cal sparse autoencoders.arXiv preprint arXiv:2502.20578, 2025
-
[17]
Epic: Explanation of pretrained image classification networks via prototypes
Piotr Borycki, Magdalena Tr˛ edowicz, Szymon Janusz, Jacek Tabor, Przemysław Spurek, Arka- diusz Lewicki, and Łukasz Struski. Epic: Explanation of pretrained image classification networks via prototypes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17366–17373, 2026
work page 2026
-
[18]
Łukasz Struski, Dawid Rymarczyk, and Jacek Tabor. Infodisent: Explainability of image classification models by information disentanglement.arXiv preprint arXiv:2409.10329, 2024
-
[19]
Plugen: Multi-label conditional generation from pre-trained models
Maciej Wołczyk, Magdalena Proszewska, Łukasz Maziarka, Maciej Zieba, Patryk Wielopolski, Rafał Kurczab, and Marek Smieja. Plugen: Multi-label conditional generation from pre-trained models. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8647–8656, 2022
work page 2022
-
[20]
Magdalena Proszewska, Maciej Wołczyk, Maciej Zieba, Patryk Wielopolski, Łukasz Maziarka, and Marek ´Smieja. Multi-label conditional generation from pre-trained models.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 46(9):6185–6198, 2024
work page 2024
-
[21]
Face identity-aware disentanglement in stylegan
Adrian Suwała, Bartosz Wójcik, Magdalena Proszewska, Jacek Tabor, Przemysław Spurek, and Marek ´Smieja. Face identity-aware disentanglement in stylegan. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5222–5231, 2024
work page 2024
-
[22]
Divyansh Srivastava, Ge Yan, and Tsui-Wei Weng. Vlg-cbm: Training concept bottleneck models with vision-language guidance.Advances in Neural Information Processing Systems, 37:79057–79094, 2024
work page 2024
-
[23]
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19187–19197, 2023
work page 2023
-
[24]
Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery
Sukrut Rao, Sweta Mahajan, Moritz Böhle, and Bernt Schiele. Discover-then-name: Task- agnostic concept bottlenecks via automated concept discovery. InEuropean Conference on Computer Vision, pages 444–461. Springer, 2024
work page 2024
-
[25]
Swin transformer: Hierarchical vision transformer using shifted windows, 2021
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows, 2021
work page 2021
-
[26]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
work page 2019
-
[27]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[28]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009
work page 2009
-
[29]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 20617–20642, 2024. 11
work page 2024
-
[31]
Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
-
[32]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2(5):6, 2023. 12 A Formulation of the Training Curriculum We consider a homotopy-style curriculum: k(t)...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.