Clipping Bottleneck: Stabilizing RLVR via Stochastic Recovery of Near-Boundary Signals
Pith reviewed 2026-05-22 07:47 UTC · model grok-4.3
The pith
Stochastic rescue of near-boundary signals fixes the clipping bottleneck in RLVR and improves training stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
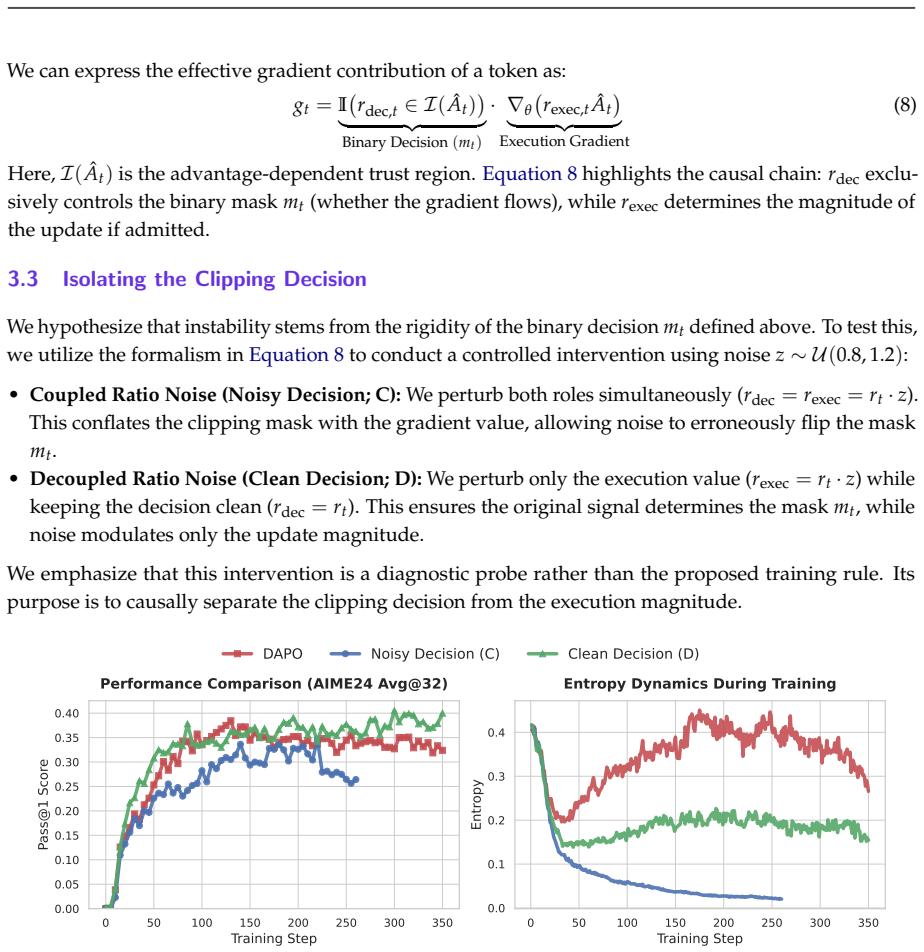
In RLVR training the standard hard-clipping rule in GRPO-style objectives creates a bottleneck by discarding tokens whose advantage lies just outside the clip threshold. NSR stochastically retains a fraction of these near-boundary tokens, which in expectation produces a mild gradient decay yet proves more effective than any deterministic decay schedule. Across scales from 7B to 30B and both dense and MoE models, the change yields measurable gains in stability and final performance over strong baselines including DAPO and GSPO.
What carries the argument
Near-boundary Stochastic Rescue (NSR): a boundary-local stochastic sampling step inserted into the clipping operation that randomly keeps a subset of slightly out-of-bound tokens to recover otherwise lost signals.
If this is right
- Training stability improves substantially once the stochastic rescue is active.
- Performance gains appear consistently over DAPO and GSPO baselines.
- The benefit holds from 7B through 30B parameters for both dense and MoE models.
- Stochastic boundary rescue outperforms deterministic gradient-decay alternatives in direct ablations.
- The modification remains a minimal, drop-in change to existing clipping-based RLVR objectives.
Where Pith is reading between the lines
- The same boundary-rescue idea may generalize to other policy-gradient methods that rely on hard clipping.
- Adaptive retention probability conditioned on token advantage magnitude could be a natural next refinement.
- Reduced sensitivity to exact clip threshold values may simplify hyperparameter search in RLVR pipelines.
Load-bearing premise
The near-boundary region beyond the clipping threshold contains recoverable informative signals whose stochastic retention produces net gains without introducing new instability or bias.
What would settle it
A controlled comparison in which NSR runs exhibit equal or higher variance in reward curves or lower final scores than the hard-clipping baseline across multiple random seeds would falsify the claim of consistent stability and performance gains.
Figures









read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a central paradigm for scaling LLM reasoning, yet its optimization often suffers from training instability and suboptimal convergence. Through a systematic dissection of clipping-based GRPO-style objectives, we identify the rigid clipping decision induced by hard clipping as a key practical bottleneck in the studied RLVR setups. Specifically, our analysis suggests that informative signals can lie in the near-boundary region just beyond the clipping threshold, and are therefore discarded by the standard hard-clipping rule. Notably, once this bottleneck is precisely identified, even simple stochastic perturbations at the boundary can recover meaningful performance gains. Building on this finding, we propose Near-boundary Stochastic Rescue (NSR), a minimal, plug-and-play modification that stochastically retains these slightly out-of-bound tokens to recover lost signals. While NSR, via stochastic sampling, can be interpreted as inducing an implicit gradient decay in expectation, our ablations reveal that its stochastic, boundary-local rescue mechanism is consistently more effective than deterministic gradient decay. Validated by extensive experiments across model sizes from 7B to 30B and both dense and MoE architectures, as a plug-and-play solution, NSR substantially improves training stability and delivers consistent gains over strong baselines such as DAPO and GSPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies rigid hard clipping in GRPO-style objectives as a bottleneck in RLVR that discards informative signals in the near-boundary region just beyond the clipping threshold. It proposes Near-boundary Stochastic Rescue (NSR), a minimal stochastic perturbation that retains these out-of-bound tokens, claiming this recovers lost signals, improves training stability, and yields consistent gains over baselines such as DAPO and GSPO across 7B–30B dense and MoE models.
Significance. If the empirical results hold, NSR provides a parameter-free, plug-and-play stabilization technique for RLVR that is shown to outperform deterministic gradient decay in ablations. This could have practical impact on scaling verifiable-reward training for LLM reasoning, especially given the reported consistency across model scales and architectures.
major comments (2)
- [Analysis of GRPO-style objectives (as described in the abstract and experimental motivation)] The central claim that near-boundary tokens contain recoverable informative signals (rather than high-variance outliers) is load-bearing yet supported only at a high level. No quantitative breakdown—such as histograms of clipped ratios versus advantage magnitude, or correlation with verifiable reward—is referenced to demonstrate that these tokens are systematically more useful than those already inside the clip.
- [Ablations and comparison to deterministic decay] The superiority of NSR over deterministic gradient decay is asserted via ablations, but the manuscript does not isolate whether the benefit arises from signal recovery or from the added stochasticity itself. This leaves open the possibility that stochastic rescue reintroduces the instability that clipping was meant to suppress.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the clipping threshold value (e.g., the exact bound used in the GRPO objective) to allow readers to reproduce the near-boundary definition.
- [Experimental results] Figure or table captions for the stability and performance plots should include the number of random seeds and the precise definition of 'stability' (e.g., variance of reward or gradient norm).
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have carefully considered each point and provide detailed responses below. Where appropriate, we will revise the manuscript to incorporate additional analyses and clarifications.
read point-by-point responses
-
Referee: [Analysis of GRPO-style objectives (as described in the abstract and experimental motivation)] The central claim that near-boundary tokens contain recoverable informative signals (rather than high-variance outliers) is load-bearing yet supported only at a high level. No quantitative breakdown—such as histograms of clipped ratios versus advantage magnitude, or correlation with verifiable reward—is referenced to demonstrate that these tokens are systematically more useful than those already inside the clip.
Authors: We agree that a more quantitative characterization would strengthen the motivation. In the original manuscript, our analysis of the clipping bottleneck is presented at a conceptual level to identify the issue, with empirical validation coming from the performance gains of NSR. To directly address this, we will add in the revised version histograms showing the distribution of clipped tokens by advantage magnitude and their correlation with verifiable rewards, demonstrating that near-boundary tokens often carry meaningful signals. revision: yes
-
Referee: [Ablations and comparison to deterministic decay] The superiority of NSR over deterministic gradient decay is asserted via ablations, but the manuscript does not isolate whether the benefit arises from signal recovery or from the added stochasticity itself. This leaves open the possibility that stochastic rescue reintroduces the instability that clipping was meant to suppress.
Authors: Our ablations compare NSR to deterministic gradient decay and show that NSR provides better stability and performance, suggesting the boundary-specific stochastic rescue is beneficial. However, we acknowledge the need for clearer isolation. In the revision, we will include an additional ablation applying stochasticity uniformly or away from the boundary to confirm that the gains stem from targeted signal recovery rather than general stochasticity. Existing results indicate no reintroduction of instability, as training curves remain stable. revision: yes
Circularity Check
No significant circularity; empirical algorithmic proposal is self-contained
full rationale
The paper presents an empirical analysis of clipping in GRPO-style objectives followed by a practical plug-and-play modification (NSR). No derivation chain, first-principles prediction, or fitted parameter is claimed that reduces to its own inputs by construction. The identification of near-boundary signals and the stochastic rescue mechanism are motivated by dissection of existing objectives and validated through ablations and experiments; the comparison to deterministic gradient decay is external to the proposal itself. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided text. This is a standard empirical contribution without tautological reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NSR ... induces an implicit soft-clipping mechanism, imposing an approximate 1/r² gradient decay on out-of-bound tokens (Corollary 6.2)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hard-clipping operation creates a rigid gradient cutoff: any token falling outside the trust region is detached
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Madeleine Dwyer, Adam Sobey, and Adriane Chapman. It’s not you, it’s clipping: A soft trust-region via probability smoothing for llm rl.arXiv preprint arXiv:2509.21282,
-
[5]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen. Rethinking entropy interventions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, and Matthias Bethge. A sober look at progress in language model reasoning: Pitfalls and paths to repro- ducibility.arXiv preprint arXiv:2504.07086,
-
[9]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open- reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Guanhua Huang, Tingqiang Xu, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, and Bo Zhou. Low-probability tokens sustain exploration in reinforcement learning with verifiable reward.arXiv preprint arXiv:2510.03222,
-
[11]
On the direction of rlvr updates for llm reasoning: Identification and exploitation, 2026
Kexin Huang, Haoming Meng, Junkang Wu, Jinda Lu, Chiyu Ma, Ziqian Chen, Xue Wang, Bolin Ding, Jiancan Wu, Xiang Wang, et al. On the direction of rlvr updates for llm reasoning: Identification and exploitation.arXiv preprint arXiv:2603.22117,
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Hel- yar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yunjie Ji, Sitong Zhao, Xiaoyu Tian, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, and Xiangang Li. How difficulty-aware staged reinforcement learning enhances llms’ reasoning capabilities: A preliminary experimental study.arXiv preprint arXiv:2504.00829,
-
[14]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025a. 13 Zihe Liu, Jiashun Liu, Yancheng He, Weixun Wang, Jiaheng Liu, Ling Pan, Xinyu Hu, Shaopan Xiong, Ju Huang, Jian Hu, et al. Part i: Tricks or traps? a deep di...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Hanyi Mao, Quanjia Xiao, Lei Pang, and Haixiao Liu. Clip your sequences fairly: Enforcing length fairness for sequence-level rl.arXiv preprint arXiv:2509.09177,
-
[16]
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.arXiv preprint arXiv:2603.22446,
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
When Importance Sampling Misallocates Credit: Asymmetric Ratios for Outcome-Supervised RL
Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, and Kun Gai. Aspo: Asymmetric importance sampling policy optimization.arXiv preprint arXiv:2510.06062, 2025a. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy mi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Quantile advantage estimation for entropy-safe reasoning.arXiv preprint arXiv:2509.22611,
Junkang Wu, Kexin Huang, Jiancan Wu, An Zhang, Xiang Wang, and Xiangnan He. Quantile advantage estimation for entropy-safe reasoning.arXiv preprint arXiv:2509.22611,
-
[22]
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, et al. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adaptive clipping.arXiv preprint arXiv:2510.18927,
-
[23]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
Zhongwen Xu and Zihan Ding. Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. 14 Shuo Yang, Yuwei Niu, Yuyang Liu, Yang Ye, Bin Lin, and Li Yuan. Look-back: Implicit visual re- focusing in mllm reasoning. InProceedings of the AAAI Conference on A...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2505.12929 , year=
Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, and Yunjian Xu. Do not let low-probability tokens over-dominate in rl for llms.arXiv preprint arXiv:2505.12929, 2025b. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforc...
-
[26]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning.arXiv preprint arXiv:2506.01347,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.