Tokenization with Split Trees
Pith reviewed 2026-05-22 05:43 UTC · model grok-4.3
The pith
ToaST reduces English token counts by more than 11% versus BPE at vocabularies of 40960 and larger while raising 1.5B model CORE scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
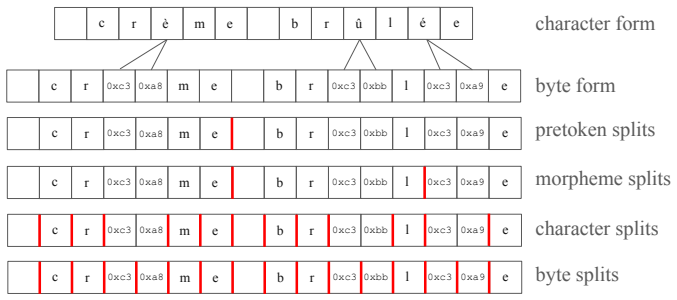
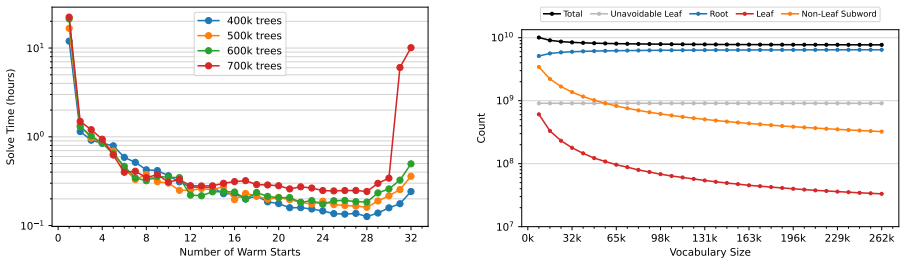
ToaST greedily splits each pretoken into a full binary tree using precomputed byte n-gram counts independent of any vocabulary. Given a vocabulary, inference recursively descends each split tree and emits the first in-vocabulary node reached on each path. Vocabulary selection is formulated as an integer program that minimizes the total token count over all split trees under this inference procedure, and the LP relaxation is near-integral in practice, yielding provably near-optimal vocabularies.
What carries the argument
The split tree, a full binary tree built greedily on byte n-grams for each pretoken, which supports recursive first-in-vocabulary emission and serves as the objective for the integer program that selects the vocabulary.
If this is right
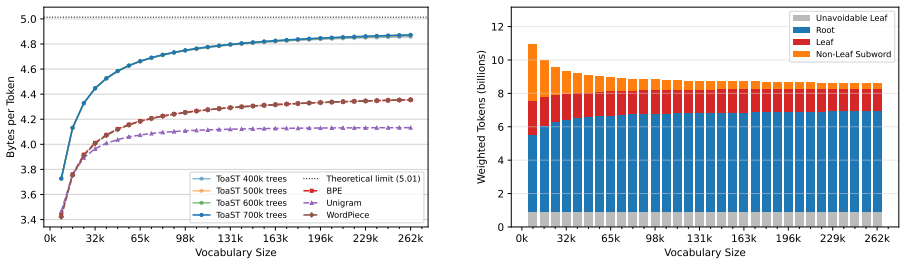
- Token counts drop by more than 11% on English text at vocabulary sizes of 40,960 and above, extending effective context length.
- 1.5B-parameter language models reach the highest CORE score and outperform baselines by 2.6% to 7.6% with significance in two of three comparisons.
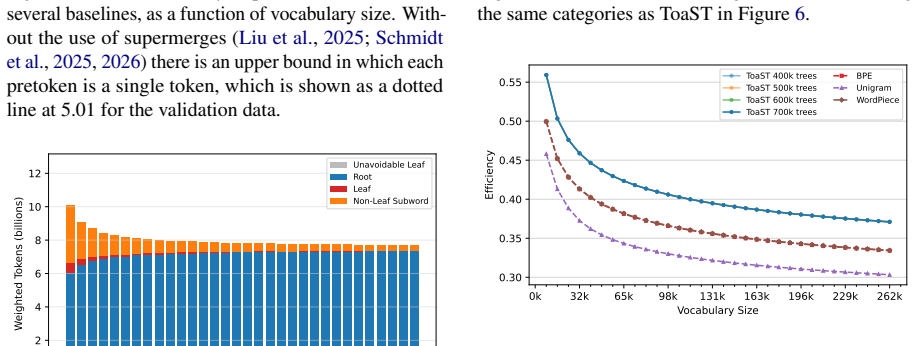
- Common single-byte tokens appear less often, producing a substantial gain in Renyi efficiency.
- The LP relaxation remains near-integral, so the same optimization procedure scales to practical vocabulary sizes with quadratic training time in the number of split trees.
Where Pith is reading between the lines
- The same split-tree construction could be tried on non-English text by replacing the byte n-gram statistics with those of the target language.
- Because training time grows quadratically with the number of pretokens, sampling a representative subset of the corpus may be needed before applying ToaST to very large datasets.
- The reduction in token count may also improve performance on sequence-to-sequence tasks such as machine translation that are sensitive to sequence length.
Load-bearing premise
That the greedy binary splitting of pretokens using precomputed byte n-gram counts, followed by recursive descent to the first in-vocabulary node, produces a compression objective whose integer-program solution yields vocabularies that are near-optimal in actual downstream use.
What would settle it
Measuring token counts and downstream CORE scores for a 1.5B model trained with a ToaST vocabulary chosen at size 40960 on a fresh English corpus and checking whether the reported gains versus BPE still appear.
Figures





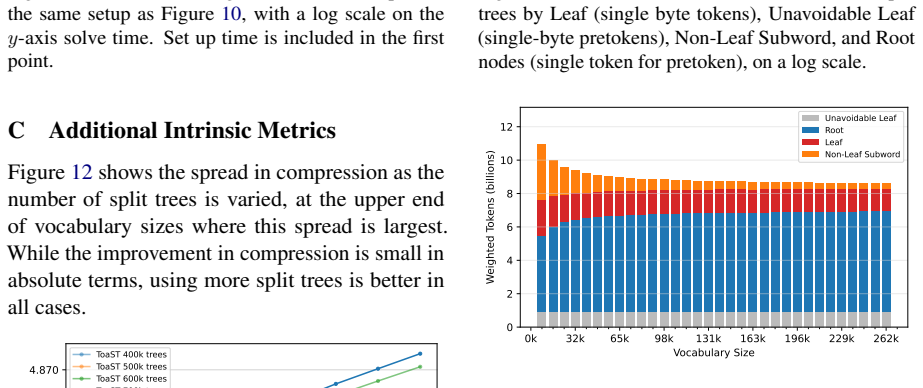



read the original abstract
We introduce Tokenization with Split Trees (ToaST), a subword tokenization method that directly optimizes compression under a new recursive inference procedure. ToaST greedily splits each pretoken into a full binary tree using precomputed byte n-gram counts, independent of any vocabulary. Given a vocabulary, inference recursively descends each split tree and emits the first in-vocabulary node reached on each path. Vocabulary selection is formulated as an Integer Program (IP) that minimizes the total token count over all split trees under this inference procedure. The Linear Programming (LP) relaxation is near-integral in practice, yielding provably near-optimal vocabularies, with training time empirically scaling quadratically in the number of split trees. On English text, ToaST reduces token counts by more than 11% compared to BPE, WordPiece, and UnigramLM at vocabulary sizes of 40,960 and above, reducing the number of inference tokens for models using this tokenizer, thus extending the effective context length. ToaST also uses common single-byte tokens less frequently than these baselines, leading to a substantial improvement in Renyi efficiency. In experiments training 1.5B parameter language models, ToaST achieves the highest CORE score, outperforming baselines by 2.6%--7.6%, with significance for two of three, and scoring best on 13 of 22 individual tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tokenization with Split Trees (ToaST), a subword tokenization method that greedily builds full binary split trees for pretokens from precomputed byte n-gram counts, then selects a vocabulary by solving an integer program minimizing total token count under recursive descent inference to the first in-vocabulary node. It claims the LP relaxation is near-integral and yields provably near-optimal vocabularies, reports >11% token reduction versus BPE/WordPiece/UnigramLM on English text at vocab sizes >=40960, reduced single-byte token usage, and superior CORE scores (outperforming baselines by 2.6%-7.6%) when training 1.5B-parameter LMs.
Significance. If the near-integrality of the LP solution and the downstream gains hold, the explicit IP formulation of the compression objective under the new inference rule would be a clear strength, offering a more direct optimization path than heuristic methods like BPE. The reported quadratic scaling of training time and the falsifiable token-reduction predictions are also positive features. However, the significance is tempered by the absence of supporting analysis for the LP claim and potential confounds in the LM experiments.
major comments (2)
- [Abstract] Abstract: The statement that the LP relaxation is near-integral and yields provably near-optimal vocabularies is presented without derivation, error analysis, or verification that the reported 11% token reduction is robust to changes in pretokenization or domain.
- [LM training experiments] LM training experiments: The description of the 1.5B-parameter LM training does not specify whether a fixed token budget or fixed optimizer steps was used; given ToaST's >11% token reduction, this leaves open whether the 2.6%-7.6% CORE gains are attributable to the tokenizer or to processing more raw text.
minor comments (1)
- [Introduction] The interaction between the greedy binary splitting procedure and the IP objective could be clarified with a small illustrative example early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that the LP relaxation is near-integral and yields provably near-optimal vocabularies is presented without derivation, error analysis, or verification that the reported 11% token reduction is robust to changes in pretokenization or domain.
Authors: The manuscript formulates vocabulary selection as an integer program minimizing total token count under the recursive inference rule and reports that the LP relaxation is near-integral based on empirical solutions across vocabulary sizes. We agree the abstract states the near-optimality claim without a self-contained derivation or error analysis. We will revise the abstract to qualify the claim as empirically supported and expand the methods or appendix section with additional details on the observed integrality gaps. For robustness, our primary results use standard English pretokenization; we will add a brief discussion of sensitivity to alternative pretokenizers and note that the approach is domain-agnostic, with plans for broader verification. revision: yes
-
Referee: [LM training experiments] LM training experiments: The description of the 1.5B-parameter LM training does not specify whether a fixed token budget or fixed optimizer steps was used; given ToaST's >11% token reduction, this leaves open whether the 2.6%-7.6% CORE gains are attributable to the tokenizer or to processing more raw text.
Authors: We thank the referee for identifying this ambiguity. The 1.5B-parameter models were trained for a fixed number of optimizer steps across all tokenizers. This choice means ToaST's lower token count per sequence allows more raw text to be processed within the same step budget. We will revise the experimental description to state this explicitly and discuss the contribution of increased data exposure to the reported CORE improvements. revision: yes
Circularity Check
No circularity in derivation: IP optimizes explicit objective with external baseline comparisons
full rationale
The paper defines split trees independently via byte n-gram counts, then formulates vocabulary selection as an IP minimizing total token count under the recursive descent inference rule. Reported token-count reductions (>11% vs BPE/WordPiece/UnigramLM) are direct empirical measurements against those external methods' own vocabularies and inference procedures, not a re-reporting of the IP objective on the same data. Downstream 1.5B LM CORE scores are presented as experimental results without any reduction to a fitted parameter or self-citation chain. No uniqueness theorems, ansatzes, or renamings from prior author work are invoked as load-bearing steps. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Byte n-gram counts computed independently of any vocabulary can be used to construct greedy full binary split trees that support the subsequent recursive inference procedure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Vocabulary selection is formulated as an Integer Program (IP) that minimizes the total token count over all split trees under this inference procedure.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanbare_distinguishability_of_absolute_floor unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ToaST greedily splits each pretoken into a full binary tree using precomputed byte n-gram counts, independent of any vocabulary.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.