Which Way Did It Move? Diagnosing and Overcoming Directional Motion Blindness in Video-LLMs
Pith reviewed 2026-05-22 05:38 UTC · model grok-4.3
The pith
Video large language models fail at signed motion direction because accessible signals are not bound to verbal answers, but a projector-level objective closes the gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
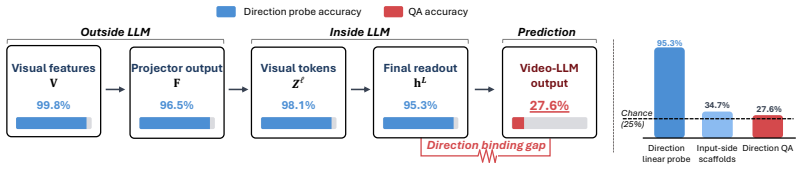
Although motion direction remains linearly accessible from the vision encoder, projector, and LLM hidden states, the readout fails to bind this signal to the correct verbal answer option, revealing a direction binding gap. DeltaDirect addresses this by predicting normalized 2-D motion vectors from adjacent-frame feature deltas at the projector level.
What carries the argument
DeltaDirect, a diagnosis-driven projector-level objective that predicts normalized 2-D motion vectors from adjacent-frame feature deltas to close the direction binding gap.
If this is right
- Instruction tuning with DeltaDirect improves motion direction accuracy from 25.9% to 85.4% on MoDirect-SynBench.
- DeltaDirect improves real-world motion direction accuracy by 21.9 points over the vanilla baseline on MoDirect-RealBench without real-world tuning data.
- The method preserves standard video-understanding performance while addressing the motion direction failure.
- Visual complexity reduces motion signal magnitude and limits out-of-domain generalization, which the objective partially mitigates.
Where Pith is reading between the lines
- Binding gaps between visual features and language outputs may affect other basic perceptual features in multimodal models.
- Projector-level objectives could provide an efficient route to add missing low-level capabilities without retraining the full model.
- Applying the same diagnosis to diagonal, rotational, or 3-D motion would test how far normalized 2-D vector prediction extends.
Load-bearing premise
Linear accessibility of motion direction from hidden states means the main issue is a binding gap fixable at the projector that will generalize beyond synthetic data without trading off other capabilities.
What would settle it
A model trained with DeltaDirect showing no gain or a drop on real-world videos with complex backgrounds would indicate the binding-gap diagnosis is incomplete or the projector fix does not transfer.
Figures


















read the original abstract
Video Large Language Models (Video-LLMs) have made rapid progress on temporal video understanding, yet many fail at a basic perceptual primitive: signed image-plane motion direction. On simple videos of a single object moving left, right, up, or down, most Video-LLMs perform near chance, with above-chance cases largely attributable to prediction biases rather than genuine direction understanding. We call this failure directional motion blindness. We localize the failure by tracing motion direction information through the Video-LLM pipeline. Motion direction remains linearly accessible from the vision encoder, projector, and LLM hidden states, but the readout fails to bind this signal to the correct verbal answer option, revealing a direction binding gap. Although synthetic motion direction instruction tuning reduces this gap on the source domain, motion direction concept vector analysis shows that visual complexity weakens the signal magnitude and limits out-of-domain generalization. We introduce MoDirect, a dataset family for motion direction instruction tuning and evaluation, and DeltaDirect, a diagnosis-driven, projector-level objective that predicts normalized 2-D motion vectors from adjacent-frame feature deltas. On MoDirect-SynBench, instruction tuning with DeltaDirect improves motion direction accuracy from 25.9% to 85.4%. On MoDirect-RealBench, DeltaDirect improves real-world motion direction accuracy by 21.9 points over the vanilla baseline without real-world tuning data, while preserving standard video-understanding performance. Code: https://github.com/KHU-VLL/DeltaDirect
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Video-LLMs exhibit directional motion blindness, performing near chance on signed image-plane motion direction (left/right/up/down) in simple videos, largely due to biases rather than understanding. Linear probing shows motion direction remains accessible in vision encoder, projector, and LLM hidden states, but fails to bind to verbal answers, indicating a direction binding gap. The authors introduce the MoDirect dataset family and DeltaDirect, a projector-level regression objective that predicts normalized 2-D motion vectors from adjacent-frame feature deltas. This yields gains from 25.9% to 85.4% on MoDirect-SynBench and +21.9 points on MoDirect-RealBench (without real-world tuning data), while preserving standard video-understanding performance.
Significance. If the results hold, this work is significant for pinpointing and mitigating a fundamental perceptual limitation in Video-LLMs via a targeted, diagnosis-driven fix at the projector level. Concrete accuracy lifts, the linear-probing diagnosis, and out-of-domain gains from synthetic-only training are strengths. The linked GitHub code supports reproducibility. This approach could guide more reliable temporal and motion capabilities in multimodal models without broad capability trade-offs.
major comments (2)
- [Abstract and results on MoDirect-RealBench] The 21.9-point gain on MoDirect-RealBench without real-world tuning data is load-bearing for the generalization claim that DeltaDirect closes the direction binding gap in general Video-LLMs. The motion direction concept vector analysis acknowledges that visual complexity weakens signal magnitude and limits out-of-domain generalization, yet no ablation or direct measurement compares signal strength or regression performance on real vs. synthetic feature deltas (e.g., due to background, texture, or multi-object motion).
- [Diagnosis section (linear probing experiments)] The diagnosis localizes the failure to a direction binding gap based on linear accessibility of motion direction from encoder, projector, and LLM states. However, this requires stronger evidence that the issue is specifically binding (rather than, e.g., attention dilution or output formatting), including probe details, exact quantification thresholds for accessibility, and controls showing the signal is not utilized despite presence.
minor comments (2)
- [Abstract] The abstract omits specifics on baseline Video-LLM models, number of runs, statistical significance, and data exclusion rules for the accuracy numbers.
- [Method section] Clarify the exact formulation of the DeltaDirect objective (e.g., loss function, normalization details) and how feature deltas are computed across frames to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will revise the manuscript to incorporate additional evidence and details as outlined.
read point-by-point responses
-
Referee: [Abstract and results on MoDirect-RealBench] The 21.9-point gain on MoDirect-RealBench without real-world tuning data is load-bearing for the generalization claim that DeltaDirect closes the direction binding gap in general Video-LLMs. The motion direction concept vector analysis acknowledges that visual complexity weakens signal magnitude and limits out-of-domain generalization, yet no ablation or direct measurement compares signal strength or regression performance on real vs. synthetic feature deltas (e.g., due to background, texture, or multi-object motion).
Authors: We agree that a direct comparison of regression performance on real versus synthetic feature deltas would strengthen the generalization claims. The observed +21.9 point gain on RealBench without real-world tuning data already provides evidence of domain-agnostic improvement, but we will add a new ablation in the revised manuscript reporting MSE and signal magnitude for DeltaDirect regression when applied to real-world feature deltas (extracted from the vision encoder and projector) compared to synthetic ones. This will quantify the effect of visual complexity and better support the out-of-domain results. revision: yes
-
Referee: [Diagnosis section (linear probing experiments)] The diagnosis localizes the failure to a direction binding gap based on linear accessibility of motion direction from encoder, projector, and LLM states. However, this requires stronger evidence that the issue is specifically binding (rather than, e.g., attention dilution or output formatting), including probe details, exact quantification thresholds for accessibility, and controls showing the signal is not utilized despite presence.
Authors: We acknowledge the need for more rigorous supporting evidence. In the revised manuscript we will expand the diagnosis section with: (1) complete specifications of the linear probe models including architecture and training hyperparameters, (2) exact quantification thresholds (e.g., probe accuracy levels and statistical significance criteria) used to deem a signal linearly accessible, and (3) additional control experiments such as attention map analysis and output-format ablations to demonstrate that the accessible motion direction signal is not utilized in generating the verbal answer despite its presence in the hidden states. revision: yes
Circularity Check
No circularity: derivation introduces independent auxiliary objective without reduction to inputs or self-citations
full rationale
The paper traces motion direction signals through the Video-LLM pipeline to identify linear accessibility in encoder/projector/LLM states but a binding gap to answer tokens. It then defines DeltaDirect as an explicit new projector-level regression loss that predicts normalized 2-D motion vectors directly from adjacent-frame feature deltas, trained on the introduced MoDirect synthetic data. This is not a fitted parameter renamed as prediction, nor does any central claim reduce by construction to prior outputs or self-citations. Reported gains (e.g., 25.9% to 85.4% on SynBench, +21.9 points on RealBench) are presented as empirical results of applying this new objective, with no equations or steps that equate the claimed prediction to the training signal itself. The chain is self-contained against external benchmarks and does not rely on load-bearing self-citations or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motion direction information remains linearly decodable from vision encoder, projector, and LLM hidden states
invented entities (2)
-
DeltaDirect
no independent evidence
-
directional motion blindness
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DeltaDirect predicts normalized 2-D motion vectors from adjacent-frame projector-feature deltas... LMVP = 1/(T-1) sum ||m̂_t - m_t||_2^2
-
IndisputableMonolith/Foundation/ArrowOfTime.leanTemporalSequence unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We uniformly sample T=8 frames per video
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InNeurIPS, 2024. 2, 6, 33, 37
work page 2024
-
[2]
Kyungho Bae, Jinhyung Kim, Sihaeng Lee, Soonyoung Lee, Gunhee Lee, and Jinwoo Choi. Mash- vlm: Mitigating action-scene hallucination in video-llms through disentangled spatial-temporal represen- tations. InCVPR, 2025. 1, 3
work page 2025
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
9, 17, 18, 32, 37, 48, 49, 51
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2. 5-vl technical report.a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Structure and function of visual area mt.Annu
Richard T Born and David C Bradley. Structure and function of visual area mt.Annu. Rev. Neurosci., 28 (1):157–189, 2005. 1
work page 2005
-
[7]
Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. InCVPR, 2024. 4
work page 2024
-
[8]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InCVPR, 2024. 9, 17, 18, 26, 32, 49
work page 2024
-
[9]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. InNeurIPS, 2024. 4
work page 2024
-
[10]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Unifying specialized visual encoders for video language models
Jihoon Chung, Tyler Zhu, Max Gonzalez Saez-Diez, Juan Carlos Niebles, Honglu Zhou, and Olga Rus- sakovsky. Unifying specialized visual encoders for video language models. InICML, 2025
work page 2025
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1, 3, 9, 49
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
MARS: Motion-augmented RGB stream for action recognition
Nieves Crasto, Philippe Weinzaepfel, Karteek Alahari, and Cordelia Schmid. MARS: Motion-augmented RGB stream for action recognition. InCVPR, 2019. 3
work page 2019
-
[15]
Motionsight: Boosting fine-grained motion understanding in multimodal LLMs
Yipeng Du, Tiehan Fan, Kepan Nan, Rui Xie, Penghao Zhou, Xiang Li, Jian Yang, Zhenheng Yang, and Ying Tai. Motionsight: Boosting fine-grained motion understanding in multimodal LLMs. InICLR, 2026. 3
work page 2026
-
[16]
Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, and Zhuotao Tian. Flashvid: Efficient video large language models via training-free tree-based spatiotemporal token merging. InICLR, 2026. 9, 17, 49 10
work page 2026
-
[17]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, 2025. 1
work page 2025
-
[18]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. Ocrbench v2: An improved benchmark for evaluating large multimodal models on vis...
work page 2025
-
[19]
James J Gibson.The ecological approach to visual perception: classic edition. Psychology press, 2014. 1
work page 2014
-
[20]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InICCV, 2017. 3, 9, 27, 49
work page 2017
-
[21]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InICLR, 2024. 5, 34, 35, 36
work page 2024
-
[22]
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. Motionbench: Benchmarking and improving fine-grained video motion understand- ing for vision language models. InCVPR, 2025. 1, 3, 9, 17, 22, 49, 50
work page 2025
-
[23]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022. 6
work page 2022
-
[24]
Ziyuan Huang, Shiwei Zhang, Jianwen Jiang, Mingqian Tang, Rong Jin, and Marcelo H. Ang. Self- supervised motion learning from static images. InCVPR, 2021. 3
work page 2021
-
[25]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio- temporal reasoning in visual question answering. InCVPR, 2017. 9, 16, 22, 49, 50
work page 2017
-
[27]
Video-LaVIT: Unified video-language pre-training with decoupled visual-motional tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, and Yadong Mu. Video-LaVIT: Unified video-language pre-training with decoupled visual-motional tokenization. InICML, 2024. 3
work page 2024
-
[28]
Map the flow: Revealing hidden pathways of information in videoLLMs
Minji Kim, Taekyung Kim, and Bohyung Han. Map the flow: Revealing hidden pathways of information in videoLLMs. InICLR, 2026. 3, 4, 6
work page 2026
-
[29]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InNeurIPS, 2022. 4
work page 2022
-
[30]
MotionSqueeze: Neural motion feature learning for video understanding
Heeseung Kwon, Manjin Kim, Suha Kwak, and Minsu Cho. MotionSqueeze: Neural motion feature learning for video understanding. InECCV, 2020. 3
work page 2020
-
[31]
LLaV A-onevision: Easy visual task transfer.TMLR, 2025
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-onevision: Easy visual task transfer.TMLR, 2025. 1, 3, 9, 17, 18, 25, 32, 37, 48, 49, 51
work page 2025
-
[32]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. InNeurIPS, 2023. 2, 5, 6, 33, 37
work page 2023
-
[33]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InCVPR, 2024. 1, 3, 4, 9, 16, 18, 19, 22, 25, 44, 49, 50
work page 2024
-
[34]
Temporal reasoning transfer from text to video
Lei Li, Yuanxin Liu, Linli Yao, Peiyuan Zhang, Chenxin An, Lean Wang, Xu Sun, Lingpeng Kong, and Qi Liu. Temporal reasoning transfer from text to video. InICLR, 2025. 1, 3
work page 2025
-
[35]
Vitatecs: A diagnostic dataset for temporal concept understanding of video-language models
Shicheng Li, Lei Li, Yi Liu, Shuhuai Ren, Yuanxin Liu, Rundong Gao, Xu Sun, and Lu Hou. Vitatecs: A diagnostic dataset for temporal concept understanding of video-language models. InECCV, 2024. 3
work page 2024
-
[36]
TEA: Temporal excitation and aggregation for action recognition
Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, and Limin Wang. TEA: Temporal excitation and aggregation for action recognition. InCVPR, 2020. 3
work page 2020
-
[37]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InECCV, 2024. 1, 3, 9, 49 11
work page 2024
-
[38]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InEMNLP, 2024. 1, 3, 9, 32, 49
work page 2024
-
[39]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InECCV, 2014. 2, 6
work page 2014
-
[40]
St-llm: Large language models are effective temporal learners
Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, and Ge Li. St-llm: Large language models are effective temporal learners. InECCV, 2024. 3
work page 2024
-
[41]
Flow4Agent: Long-form video under- standing via motion prior from optical flow
Ruyang Liu, Shangkun Sun, Haoran Tang, Ge Li, and Wei Gao. Flow4Agent: Long-form video under- standing via motion prior from optical flow. InICCV, 2025. 3
work page 2025
-
[42]
Tempcompass: Do video llms really understand videos? InACL, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InACL, 2024. 1, 3, 9, 16, 22, 49, 50
work page 2024
-
[43]
NVILA: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Haotian Tang, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De- An Huang, An-Chieh Cheng, Jinyi Hu, Sifei Liu, Ranjay Krishna, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, and Yao Lu. NVILA: Efficient frontier visual lang...
work page 2025
-
[44]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InACL, 2024. 3, 25
work page 2024
-
[45]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. InNeurIPS, 2023. 1, 3, 9, 16, 22, 49, 50
work page 2023
-
[46]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InFirst Conference on Language Modeling, 2024. 2, 3, 6, 33, 34, 36
work page 2024
-
[47]
Biological image motion processing: a review.Vision Research, 25(5):625–660, 1985
Ken Nakayama. Biological image motion processing: a review.Vision Research, 25(5):625–660, 1985. doi: 10.1016/0042-6989(85)90171-3. 1
-
[48]
Hong Nguyen, Dung Tran, Hieu Hoang, Phong Nguyen, and Shrikanth Narayanan. MOOSE: Pay atten- tion to temporal dynamics for video understanding via optical flows.arXiv preprint arXiv:2506.01119,
-
[49]
Interpreting GPT: The logit lens
nostalgebraist. Interpreting GPT: The logit lens. LessWrong, August 2020. URLhttps://www. lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens. Accessed: 2026-02-22. 6, 23, 34
work page 2020
-
[50]
Llms know more than they show: On the intrinsic representation of llm hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. Llms know more than they show: On the intrinsic representation of llm hallucinations. InICLR,
-
[51]
Yoonah Park, Haesung Pyun, and Yohan Jo. Bridging the knowledge-prediction gap in llms on multiple- choice questions.arXiv preprint arXiv:2509.23782, 2025. 5, 34
-
[52]
Perception test: A diagnostic benchmark for multimodal video models
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Perception test: A diagnostic benchmark for multimodal video models. InNeurIPS, 2023. 1, 3, 9, 16, 22, 49, 50
work page 2023
-
[53]
Improve temporal reasoning in multimodal large language models via video contrastive decoding
Daiqing Qi, Dongliang Guo, Hanzhang Yuan, Handong Zhao, Mengxuan Hu, Lehan Yang, and Sheng Li. Improve temporal reasoning in multimodal large language models via video contrastive decoding. In NeurIPS, 2025. 1
work page 2025
-
[54]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024. 2, 6, 33, 37
work page 2024
-
[55]
Leveraging large language models for multiple choice question answering
Joshua Robinson, Christopher Michael Rytting, and David Wingate. Leveraging large language models for multiple choice question answering. arxiv (2022). InICLR, 2023. 4
work page 2022
-
[56]
Actionatlas: A videoqa benchmark for domain-specialized action recognition
Mohammadreza Salehi, Jae S Park, Tanush Yadav, Aditya Kusupati, Ranjay Krishna, Yejin Choi, Han- naneh Hajishirzi, and Ali Farhadi. Actionatlas: A videoqa benchmark for domain-specialized action recognition. InNeurIPS, 2024. 1
work page 2024
-
[57]
Recognizing human actions: a local svm approach
Christian Schuldt, Ivan Laptev, and Barbara Caputo. Recognizing human actions: a local svm approach. InICPR, 2004. 3, 9, 49 12
work page 2004
-
[58]
Tomato: Assessing visual temporal reasoning capabilities in multimodal foundation models
Ziyao Shangguan, Chuhan Li, Yuxuan Ding, Yanan Zheng, Yilun Zhao, Tesca Fitzgerald, and Arman Cohan. Tomato: Assessing visual temporal reasoning capabilities in multimodal foundation models. In ICLR, 2025. 1, 3, 9, 21, 49
work page 2025
-
[59]
Jonathan C. Stroud, David A. Ross, Chen Sun, Jia Deng, and Rahul Sukthankar. D3D: Distilled 3D networks for video action recognition. InWACV, 2020. 3
work page 2020
-
[60]
Probing for arithmetic errors in language mod- els
Yucheng Sun, Alessandro Stolfo, and Mrinmaya Sachan. Probing for arithmetic errors in language mod- els. InEMNLP, 2025. 5, 34
work page 2025
-
[61]
Language models linearly rep- resent sentiment
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Language models linearly rep- resent sentiment. InICML, 2024. 2, 6, 33, 37
work page 2024
-
[62]
Favor-bench: A comprehensive benchmark for fine-grained video motion understanding
Chongjun Tu, Lin Zhang, Pengtao Chen, Peng Ye, Xianfang Zeng, Wei Cheng, Gang YU, and Tao Chen. Favor-bench: A comprehensive benchmark for fine-grained video motion understanding. InNeurIPS,
-
[63]
3, 9, 16, 22, 49, 50
-
[64]
TDN: Temporal difference networks for efficient action recognition
Limin Wang, Zhan Tong, Bin Ji, and Gangshan Wu. TDN: Temporal difference networks for efficient action recognition. InCVPR, 2021. 3
work page 2021
-
[65]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InECCV, 2024. 1, 3
work page 2024
-
[66]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022. 4
work page 2022
-
[67]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019. 16
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[68]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InCVPR, 2021. 9, 16, 22, 49, 50
work page 2021
-
[69]
Seeing the arrow of time in large multimodal models
Zihui Xue, Mi Luo, and Kristen Grauman. Seeing the arrow of time in large multimodal models. In NeurIPS, 2025. 3
work page 2025
-
[70]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024. 18, 44
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Haosen Yang, Deng Huang, Bin Wen, Jiannan Wu, Hongxun Yao, Yi Jiang, Xiatian Zhu, and Zehuan Yuan. Self-supervised video representation learning with motion-aware masked autoencoders.arXiv preprint arXiv:2210.04154, 2022. 3
-
[72]
mPLUG-Owl3: Towards long image-sequence understanding in multi-modal large language mod- els
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mPLUG-Owl3: Towards long image-sequence understanding in multi-modal large language mod- els. InICLR, 2025. 17, 32, 48, 49
work page 2025
-
[73]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InICLR, 2026. 4
work page 2026
-
[74]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InCVPR, 2023. 18, 28, 44
work page 2023
-
[75]
Yu-Wei Zhan, Xin Wang, Hong Chen, Tongtong Feng, Wei Feng, Ren Wang, Guangyao Li, Qing Li, and Wenwu Zhu. PhyVLLM: Physics-guided video language model with motion-appearance disentan- glement.arXiv preprint arXiv:2512.04532, 2025. 3
-
[76]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 3, 9, 32, 49
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Jianrui Zhang, Mu Cai, and Yong Jae Lee. Vinoground: Scrutinizing lmms over dense temporal reasoning with short videos.arXiv preprint arXiv:2410.02763, 2024. 3, 9, 16, 22, 49, 50
-
[78]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuan- han Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InNAACL 2025, 2025. 16 13
work page 2025
-
[79]
Llava-next: A strong zero-shot video understanding model, 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, 2024. URLhttps:// llava-vl.github.io/blog/2024-04-30-llava-next-video/. 1, 32
work page 2024
-
[80]
LLaV A-video: Video instruction tuning with synthetic data.TMLR, 2025
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun MA, Ziwei Liu, and Chunyuan Li. LLaV A-video: Video instruction tuning with synthetic data.TMLR, 2025. 3, 4, 6, 9, 17, 25, 28, 31, 32, 33, 48, 49, 50, 51
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.