BOHM: Zero-Cost Hierarchical Attribution for Compound AI Systems
Pith reviewed 2026-05-25 05:50 UTC · model grok-4.3
The pith
BOHM derives multi-resolution attributions for compound AI systems directly from the routing weights the orchestrator already maintains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BOHM defines leaf attribution as the product of routing weights along the path from root to leaf and level-k attribution as the probability distribution over depth-k nodes induced by those same path products. The tree is obtained directly from the routing state already kept by the orchestrator, requires no additional system evaluations or component introspection, and yields simultaneous attributions at every level of the hierarchy.
What carries the argument
The hierarchical attribution tree whose leaves are path products of routing weights and whose internal nodes are the summed products reaching each depth-k node.
If this is right
- Attributions become available at every depth of the hierarchy in a single pass without extra coalition evaluations.
- Opaque or third-party components receive attributions because the method never inspects their internals.
- Disagreement between BOHM and SHAP on a given cell indicates that the deployed router is not selecting the empirically strongest tool.
- The method satisfies efficiency, monotonicity, symmetry and weak suppression while remaining computable wherever routing state exists.
- Multi-resolution attribution is obtained wherever a router already maintains path probabilities, regardless of the evaluation budget available for flat methods.
Where Pith is reading between the lines
- BOHM could function as an immediate, zero-cost diagnostic for whether an orchestrator's routing policy is near-optimal on the tasks it actually encounters.
- The same path-product construction might apply to any tree-structured decision process that records routing probabilities, including non-AI planning or decision trees.
- When BOHM and SHAP diverge, the difference itself supplies information about the gap between the router's policy and the true contribution surface.
- Extending the method to routers whose weights change over time would require checking whether the path products remain stable or need re-aggregation.
Load-bearing premise
That the routing weights maintained by the orchestrator can be interpreted as multiplicative factors whose path products yield meaningful per-component attributions.
What would settle it
An experiment that independently measures each component's true marginal contribution on a held-out set of tasks, then checks whether the ordering produced by path-product attributions matches the measured ordering when the router is forced to use a demonstrably suboptimal tool.
Figures







read the original abstract
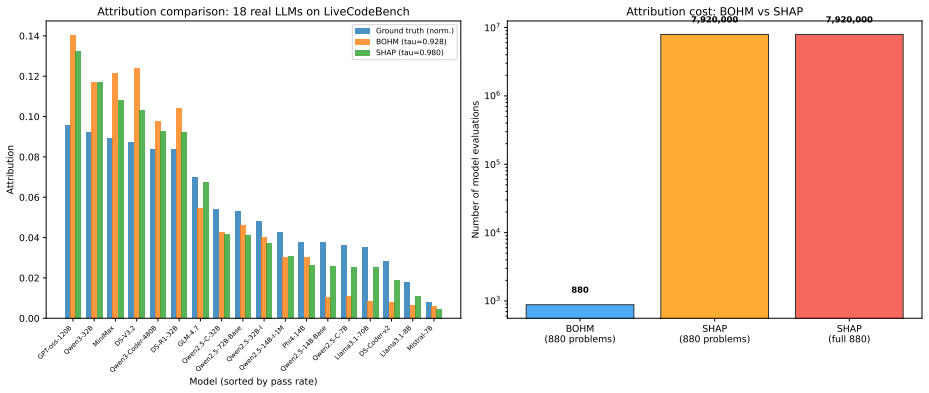
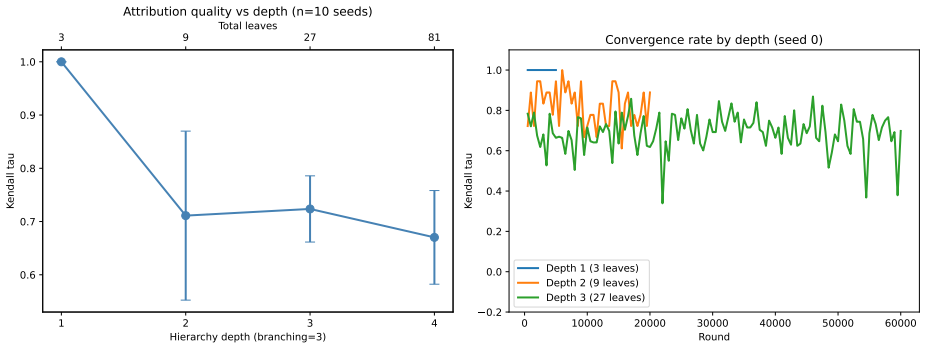
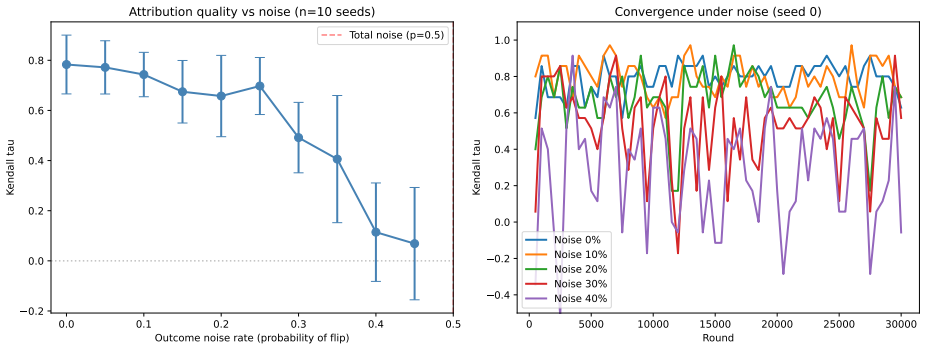
Compound AI systems route tasks through hierarchies of specialised components. Attribution is dominated by Shapley-based methods (SHAP), which decompose a coalition value function into per-component marginal contributions and require evaluation of the system on arbitrary component subsets. That requirement fails for third-party APIs, opaque endpoints, and agentic orchestrators that concentrate routing on a few tools, leaving most coalitions un-evaluable from the deployed orchestrator. We introduce BOHM, which extracts a hierarchical attribution tree directly from the routing weights such systems already maintain: leaf attribution is the path product of root-to-leaf routing weights; level-k attribution is the induced distribution over depth-k nodes. The method has zero marginal cost, requires no access to component internals, and provides multi-resolution attribution at every level simultaneously, which flat methods cannot offer at any evaluation budget. BOHM and SHAP answer different questions and converge when the deployed router routes near-optimally. On 18 LLMs in a 3-level hierarchy over 880 LiveCodeBench problems, BOHM yields Kendall tau=0.928; SHAP reaches tau=0.980 at 9,000x more coalition evaluations per seed. On a 5-driver, 7-benchmark agentic study (35 cells, complete coverage), drivers concentrate routing on a single tool (top-share median 0.65), and cell-level tau(BOHM,SHAP) is predicted by whether the driver's top pick is the empirically best tool (mean +0.22 vs ~+0.01). On a US Census hierarchy (475 leaves, 4 levels), BOHM recovers ground-truth rankings at every level (tau up to 0.722). BOHM satisfies efficiency, monotonicity, symmetry, and weak suppression but not Shapley's additivity. It is best understood as a complementary primitive: a multi-resolution decomposition computable wherever routing state exists, whose disagreement with Shapley is itself diagnostic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BOHM, a zero-cost hierarchical attribution method for compound AI systems. It defines leaf attribution as the product of routing weights along each root-to-leaf path and level-k attribution as the induced marginal distribution over depth-k nodes. The method requires no component internals or additional evaluations, provides multi-resolution output simultaneously, satisfies efficiency/monotonicity/symmetry/weak suppression (but not additivity), and reports Kendall-tau agreement with SHAP of 0.928 on 18 LLMs over LiveCodeBench, up to 0.722 on Census data, and a link between agreement and routing quality in an agentic study.
Significance. If the reported correlations and diagnostic property hold, BOHM supplies a practical complementary primitive for attribution in opaque, third-party, or agentic systems where coalition-based methods like SHAP cannot be applied at scale. The zero marginal cost, hierarchical structure, and explicit axiom verification are clear strengths that flat attribution methods lack at any budget.
major comments (2)
- [Abstract] Abstract: the reported Kendall-tau agreement (0.928 on LLMs, 0.722 on Census) is presented without error bars, number of seeds, or explicit data-exclusion rules; these omissions are load-bearing for the claim that agreement is high and diagnostic of routing quality.
- [Abstract] Method definition (Abstract and results): leaf attribution is defined directly as the path product of routing weights, yet no derivation, approximation guarantee, or error bound is supplied showing why this quantity equals or approximates marginal contribution to system output—the quantity targeted by the SHAP comparisons; support remains conditional on near-optimal routing regimes without a general test or counter-example family.
minor comments (1)
- [Abstract] Abstract: the phrase 'SHAP reaches tau=0.980 at 9,000x more coalition evaluations per seed' would benefit from a brief parenthetical on how the 9,000x factor was computed (e.g., exact coalition count per instance).
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported Kendall-tau agreement (0.928 on LLMs, 0.722 on Census) is presented without error bars, number of seeds, or explicit data-exclusion rules; these omissions are load-bearing for the claim that agreement is high and diagnostic of routing quality.
Authors: We agree that the abstract would benefit from additional statistical context. The full experimental section details the 880 LiveCodeBench problems across 18 LLMs and the 475-leaf Census hierarchy, along with the agentic study's 35 cells. We will revise the abstract to reference the number of seeds (where multiple runs were performed) and add a parenthetical note on variability or direct the reader to the experimental details. Data-exclusion rules (e.g., complete coverage in the agentic study) will be stated explicitly in a revised abstract or methods footnote. revision: yes
-
Referee: [Abstract] Method definition (Abstract and results): leaf attribution is defined directly as the path product of routing weights, yet no derivation, approximation guarantee, or error bound is supplied showing why this quantity equals or approximates marginal contribution to system output—the quantity targeted by the SHAP comparisons; support remains conditional on near-optimal routing regimes without a general test or counter-example family.
Authors: The manuscript positions BOHM as extracting attributions directly from existing routing weights rather than approximating marginal contributions in general; it explicitly states that the two methods answer different questions and converge when routing is near-optimal. The agentic study (35 cells) provides an empirical test linking agreement to routing quality (mean +0.22 when top pick matches best tool). We will add a short methods paragraph deriving the path-product definition from the routing probability interpretation and clarifying the conditional nature of agreement, without claiming a general approximation guarantee. A counter-example family is not required because disagreement is presented as a diagnostic feature rather than a flaw. revision: yes
Circularity Check
No significant circularity; BOHM is a direct definition from routing weights with external empirical checks
full rationale
The paper defines leaf attribution explicitly as the path product of routing weights and level-k attribution as the induced marginal distribution; these are introduced as a construction rather than derived from first principles as equivalent to marginal contributions. It states that BOHM and SHAP answer different questions and converge only when the router is near-optimal, with Kendall-tau agreement reported as an external measurement on benchmarks. No self-citations appear in the load-bearing steps, no parameters are fitted to target attributions, and the axiom checks (efficiency, monotonicity, etc.) are performed directly on the defined quantities. The derivation chain is therefore self-contained as a zero-cost extraction method whose relation to Shapley values is measured rather than assumed by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Routing weights maintained by the system can be interpreted as selection factors whose path products yield meaningful attributions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Leaf attribution is the path product of root-to-leaf routing weights; level-k attribution is the induced distribution over depth-k nodes.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BOHM satisfies efficiency, monotonicity, symmetry, and weak suppression but not Shapley's additivity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mohamad Abou Ali, Fadi Dornaika, and Jinan Charafeddine. Agentic AI: a comprehensive survey of architectures, applications, and future directions.Artificial Intelligence Review, 59 (1):11, 2026. doi: 10.1007/s10462-025-11422-4
-
[2]
Implicit Evaluation Under Minimal Information: Price Formation in Hierarchical Component Selection
Joss Armstrong. Implicit evaluation under minimal information: Price formation in hierarchical component selection, 2026. URLhttps://doi.org/10.48550/arXiv.2605.00921. Preprint
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.00921 2026
-
[3]
Sanjeev Arora, Elad Hazan, and Satyen Kale. The multiplicative weights update method: A meta-algorithm and applications.Theory of Computing, 8(1):121–164, 2012
work page 2012
-
[4]
The nonstochastic multiarmed bandit problem.SIAM Journal on Computing, 32(1):48–77, 2002
Peter Auer, Nicolò Cesa-Bianchi, Yoav Freund, and Robert E Schapire. The nonstochastic multiarmed bandit problem.SIAM Journal on Computing, 32(1):48–77, 2002
work page 2002
-
[5]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Algorithms to estimate Shapley value feature attributions.arXiv preprint arXiv:2207.07605, 2022
Hugh Chen, Ian C Covert, Scott M Lundberg, and Su-In Lee. Algorithms to estimate Shapley value feature attributions.arXiv preprint arXiv:2207.07605, 2022. 11
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Feudal reinforcement learning.Advances in Neural Information Processing Systems, 5, 1993
Peter Dayan and Geoffrey E Hinton. Feudal reinforcement learning.Advances in Neural Information Processing Systems, 5, 1993
work page 1993
-
[9]
DeepSeek-V3 technical report, 2024
DeepSeek-AI. DeepSeek-V3 technical report, 2024. 671B-parameter Mixture-of-Experts model with 37B activated parameters per token. Architecture inherited by DeepSeek-V3.2 (685B) used in this work
work page 2024
-
[10]
William Fedus, Barret Zoph, and Noam Shazeer. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
work page 2022
-
[11]
Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of Computer and System Sciences, 55(1):119–139, 1997
work page 1997
-
[12]
Data Shapley: Equitable valuation of data for machine learning
Amirata Ghorbani and James Zou. Data Shapley: Equitable valuation of data for machine learning. InInternational Conference on Machine Learning, 2019
work page 2019
-
[13]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
work page 2021
-
[14]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
work page 2021
-
[15]
Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
work page 1991
-
[16]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Ion Stoica, and Koushik Sen. LiveCodeBench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Sarthak Jain and Byron C Wallace. Attention is not explanation. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, 2019
work page 2019
-
[18]
GShard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021
work page 2021
-
[19]
Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode.Science, 378(6624):1092–1097, 2022
work page 2022
-
[20]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation. In Advances in Neural Information Processing Systems, 2023. 12
work page 2023
-
[21]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[22]
Devstral-Small-2-24B-2512: Agentic software-engineering language model, 2025
Mistral AI and All Hands AI. Devstral-Small-2-24B-2512: Agentic software-engineering language model, 2025. 24B-parameter dense model finetuned from Mistral-Small-3.1-24B. Available at https://huggingface.co/mistralai/Devstral-Small-2-24B-2512
work page 2025
-
[23]
OECD. PISA 2022 database, 2022. Programme for International Student Assessment. Available athttps://www.oecd.org/pisa/data/2022database/
work page 2022
-
[24]
GPT-OSS-120B: Open-weight reasoning model, 2025
OpenAI. GPT-OSS-120B: Open-weight reasoning model, 2025. Available at https:// huggingface.co/openai/gpt-oss-120b
work page 2025
-
[25]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?”: Explaining the predictions of any classifier. InProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016
work page 2016
-
[26]
Kazuyuki Samejima, Kenji Doya, and Mitsuo Kawato. Inter-module credit assignment in modular reinforcement learning.Neural Networks, 16(7):985–994, 2003
work page 2003
-
[27]
Lloyd S Shapley. A value forn-person games. InContributions to the Theory of Games, volume 2, pages 307–317. Princeton University Press, 1953
work page 1953
-
[28]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
work page 2017
-
[29]
S&P 500 index constituents and GICS classification, 2024
S&P Dow Jones Indices. S&P 500 index constituents and GICS classification, 2024. Global Industry Classification Standard. Market data from Yahoo Finance
work page 2024
-
[30]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InInternational Conference on Machine Learning, pages 3319–3328, 2017
work page 2017
-
[31]
Richard S Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2): 181–211, 1999
work page 1999
-
[32]
American community survey 2022 public use microdata sample (PUMS),
US Census Bureau. American community survey 2022 public use microdata sample (PUMS),
work page 2022
-
[33]
Available athttps://www.census.gov/programs-surveys/acs/microdata.html
-
[34]
Forest inventory and analysis national program: FIA database, 2024
USDA Forest Service. Forest inventory and analysis national program: FIA database, 2024. Available athttps://www.fia.fs.usda.gov/tools-data/
work page 2024
-
[35]
FeUdal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. FeUdal networks for hierarchical reinforcement learning. InInternational Conference on Machine Learning, 2017
work page 2017
-
[36]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InProceedings of the Conference on Empirical Methods in Natural Language Processing, 2019
work page 2019
-
[37]
The shift from models to compound AI systems.Berkeley AI Research Blog, 2024
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. The shift from models to compound AI systems.Berkeley AI Research Blog, 2024. Title: The Shift from Models to Compound AI Systems. 13
work page 2024
-
[38]
GLM-5.1-FP8: A capable open-weight large language model, 2025
Z.ai (Zhipu AI). GLM-5.1-FP8: A capable open-weight large language model, 2025. Available at https://huggingface.co/zai-org/GLM-5.1-FP8. Used as orchestrator for agentic routing experiments
work page 2025
-
[39]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. BigCodeBench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877, 2024. A Additional experiments A.1 S&P 500 institutional hierarchy As a seco...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
the routing substrate (Algorithm 1) has converged to the single-selector equilibrium of Lemma 1 at every router on the root-to-leaf paths
-
[41]
the SHAP coalition value functionv(S)is non-decreasing in component qualities, in the sense that the marginal contributionϕi =E S[v(S∪{i})−v(S)]is monotone inpi; and
-
[42]
the comparison is restricted to a sibling set (leaves sharing a common parent router), or, equivalently, the hierarchy is flat (a single router over allNcomponents). Then BOHM leaf attribution and SHAP marginal contributions induce the same total order over the components in that sibling set. Under condition (1), Lemma 1 givesw∗ v,i monotone inpi at each ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.