Building a privacy-preserving Federated Recommender system for mobile devices
Pith reviewed 2026-05-25 06:14 UTC · model grok-4.3
The pith
A two-stage pipeline generates shortlists in the cloud from non-sensitive data then re-ranks them on-device with private context signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
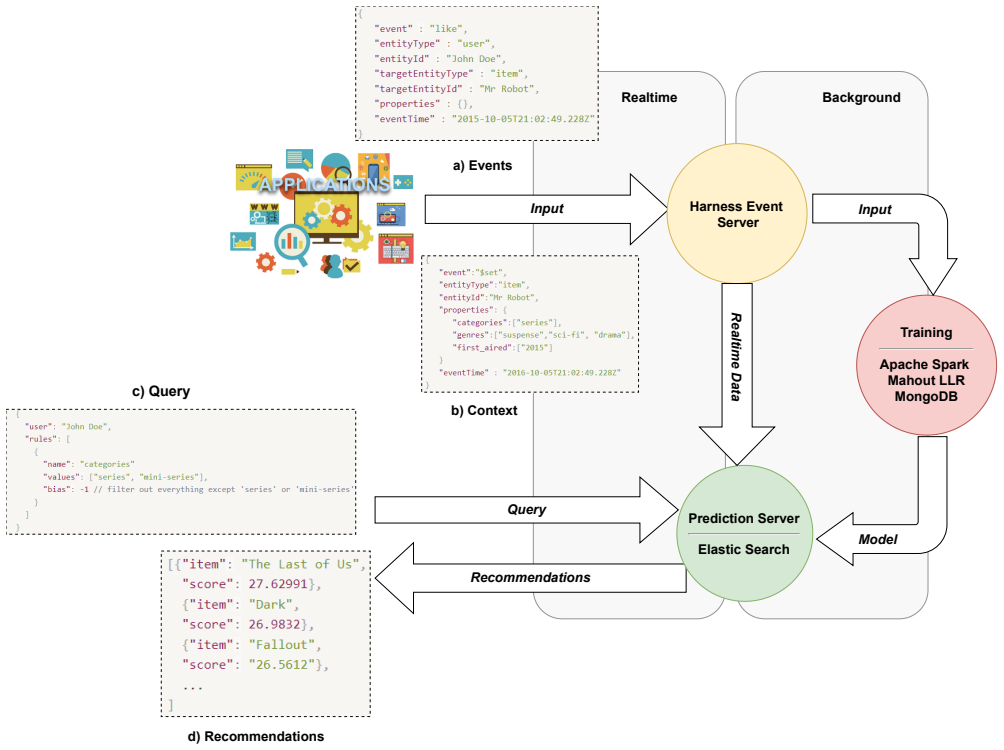
The central claim is that a two-stage federated recommendation pipeline—cloud-based collaborative filtering on non-sensitive app-context data to produce a shortlist, followed by on-device re-ranking that uses sensitive mobile signals—delivers effective personalization while ensuring the sensitive data never leaves the device and only model updates are transmitted.
What carries the argument
The two-stage federated pipeline that isolates non-sensitive preference data for cloud shortlisting from sensitive context data used only for on-device re-ranking.
If this is right
- Personalized mobile content can be served without pooling sensitive context data on servers.
- Training continues via model updates alone, satisfying data-minimization requirements.
- The same separation pattern can be applied to other on-device personalization tasks.
- A single Kotlin Multiplatform library makes the pipeline available on both Android and iOS.
Where Pith is reading between the lines
- The design lowers the regulatory surface area for any app that must handle location or sensor streams.
- On-device re-ranking may also reduce round-trip latency once the shortlist arrives.
- If the shortlist quality is high enough, the on-device stage could be made extremely lightweight.
Load-bearing premise
Re-ranking a cloud-generated shortlist on the device with local sensitive signals yields recommendation quality comparable to a model that has direct access to the full centralized dataset.
What would settle it
A controlled experiment that measures precision or recall on held-out user interactions and shows that the on-device re-ranking stage produces materially lower accuracy than a centralized model trained on the same sensitive signals would falsify the claim of effective personalization.
Figures











read the original abstract
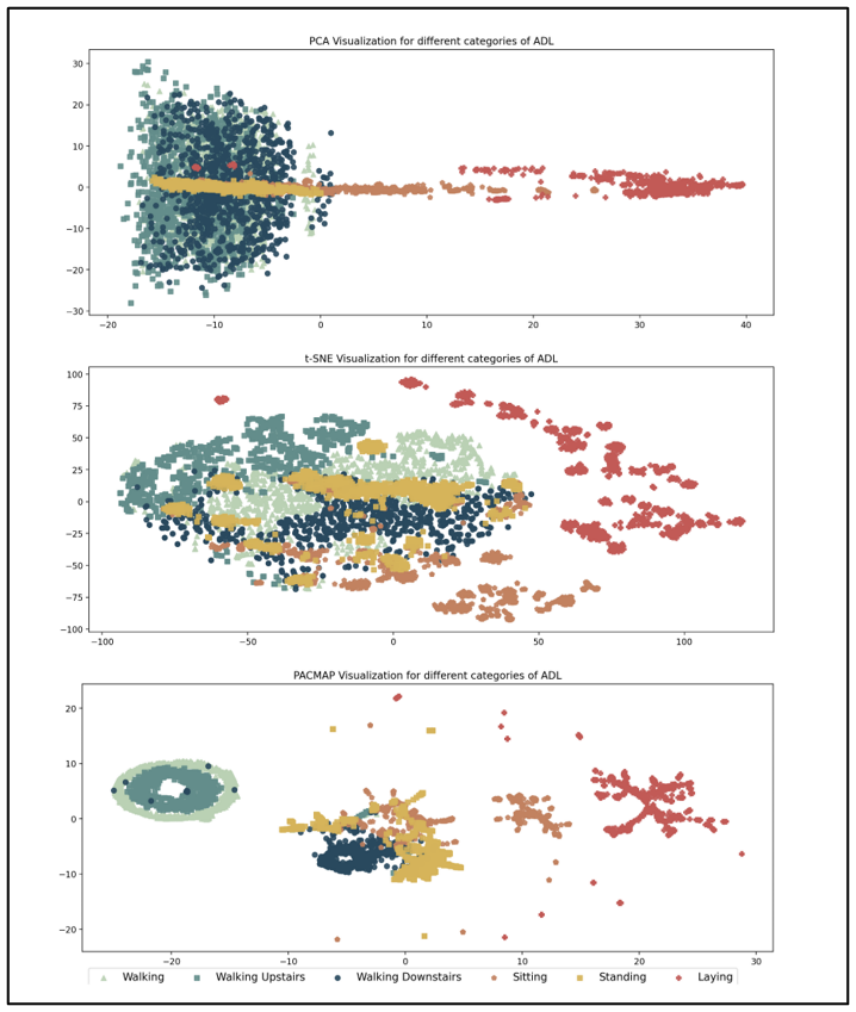
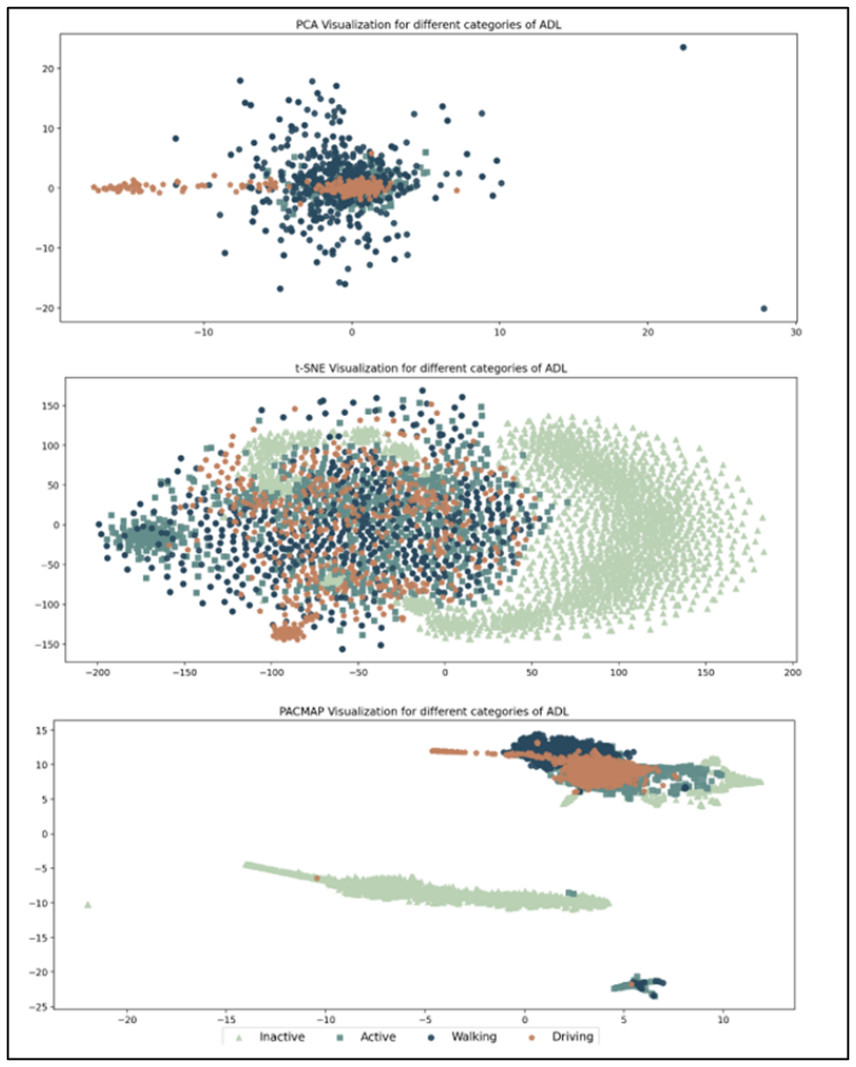
Serving personalized content on mobile devices has traditionally required pooling sensitive user data on centralized servers, a practice increasingly at odds with modern privacy expectations and geographical regulations. We present a two-stage federated recommendation system pipeline for mobile devices, built around a principled separation between non-sensitive user preference data and sensitive mobile context data that never leaves the device. The first stage runs a collaborative filtering model on non-sensitive app-context data in the cloud to generate a shortlist of relevant items. The second stage re-ranks these candidates on-device using sensitive mobile signals, with only model updates/gradients ever leaving the device. We validate the approach on MovieLens, UCI Human Activity Recognition, and a proprietary pilot dataset, and deliver a production-ready implementation as a Kotlin Multiplatform library deployable on Android and iOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-stage federated recommender system pipeline for mobile devices. A cloud-based collaborative filtering stage generates a shortlist from non-sensitive user preference data; an on-device stage then re-ranks candidates using sensitive mobile context signals, with only model updates or gradients ever leaving the device. The approach is claimed to have been validated on MovieLens, UCI Human Activity Recognition, and a proprietary pilot dataset, and a production-ready Kotlin Multiplatform library is provided.
Significance. If the on-device re-ranking stage can be shown to deliver non-trivial personalization gains while keeping sensitive data local, the pipeline would address a practical tension between personalization and privacy regulations in mobile recommender systems. The release of a deployable cross-platform library would be a concrete engineering contribution.
major comments (1)
- [Abstract] Abstract: the manuscript states that validation occurred on MovieLens, UCI HAR, and a proprietary dataset, yet supplies no metrics (e.g., NDCG@K, precision@K), baselines, ablation results comparing the two-stage pipeline against the cloud stage alone, or error analysis. Without these data the central claim that the on-device re-ranking produces effective privacy-preserving personalization remains unsupported.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that validation occurred on MovieLens, UCI HAR, and a proprietary dataset, yet supplies no metrics (e.g., NDCG@K, precision@K), baselines, ablation results comparing the two-stage pipeline against the cloud stage alone, or error analysis. Without these data the central claim that the on-device re-ranking produces effective privacy-preserving personalization remains unsupported.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The manuscript body reports evaluation results across the three datasets, including NDCG@K and precision@K metrics, direct comparisons against the cloud-only baseline, ablation studies isolating the on-device re-ranking contribution, and supporting analysis. To make these data immediately visible and address the concern, we will revise the abstract to summarize the main empirical findings (e.g., relative gains from the on-device stage) while retaining the high-level description. We will also verify that an explicit error analysis subsection appears in the results section. This targeted revision directly supports the central claim without altering the technical contribution. revision: yes
Circularity Check
No derivation chain present; architectural description only
full rationale
The manuscript describes a two-stage federated pipeline separating non-sensitive and sensitive data, with cloud CF generating a shortlist and on-device re-ranking. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. Validation is asserted on MovieLens, UCI HAR, and a proprietary dataset without any reported metrics or derivations that could reduce to inputs by construction. Self-citations are absent from the abstract and pipeline description. The contribution is therefore self-contained as an engineering architecture with no load-bearing mathematical steps to inspect for circularity.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.