CoMoGen: COntrollable MOtion Dynamics and Interactions with Mask-Guided Video GENeration
Pith reviewed 2026-05-25 05:43 UTC · model grok-4.3
The pith
CoMoGen generates videos with precise subject motion and interactions from binary mask sequences by adapting motion-specific layers in a diffusion transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
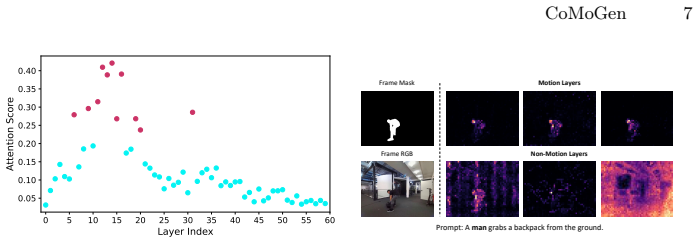
CoMoGen enables precise subject motion and plausible interactions with surrounding humans, objects, and scenes by encoding binary mask sequences into a latent residual signal via a lightweight MaskAdapter, injecting the signal into the MMDiT model through a cosine-weighted schedule, identifying Motion Layers in the attention space of MMDiT, and fine-tuning only those layers with LoRA without any architecture change.
What carries the argument
Motion Layers identified in the attention space of MMDiT, which are adapted via LoRA after mask signals are injected by the MaskAdapter.
If this is right
- Videos can be generated with subject trajectories and interactions dictated directly by binary mask sequences.
- Plausible contacts between the controlled subject and other scene elements occur without explicit 3D modeling.
- Training cost drops because only a small subset of transformer layers receives LoRA updates.
- The same base MMDiT model can be reused for different motion tasks by swapping the adapted Motion Layers.
- Performance exceeds earlier mask-conditioned video methods on standard motion and realism metrics.
Where Pith is reading between the lines
- The layer-identification technique could be tested on other transformer video models to see whether similar motion subspaces exist.
- Mask sequences might be combined with text prompts to add semantic constraints while retaining spatial control.
- The cosine injection schedule could be replaced by learned schedules to check whether further motion accuracy is possible.
- Real-time applications such as interactive video editing become feasible if inference remains close to the base model speed.
Load-bearing premise
The procedure for locating Motion Layers in MMDiT attention space correctly isolates the components responsible for motion so that LoRA on only those layers delivers motion control without unwanted effects on other parts of generation.
What would settle it
An experiment showing that LoRA adaptation on the identified Motion Layers produces no measurable gain in motion fidelity or introduces visible artifacts in appearance, lighting, or non-motion elements compared with adapting random layers.
Figures









read the original abstract
We present CoMoGen, a controllable video generation framework that generates realistic interactive dynamics from a single binary mask sequence conditioned on an input image. CoMoGen introduces a lightweight MaskAdapter that encodes binary mask sequences into a latent residual signal, injected into the Multi Modal Diffusion Transformer (MMDiT) model through a cosine-weighted schedule. Unlike the hierarchical coarse-to-fine design of UNet architectures, MMDiT operates as a sequence of uniform transformer blocks, making it difficult to identify which layers are responsible for the motion generation. Therefore, we propose a novel way to determine "Motion Layers" operating in the attention space of MMDiT. We fine-tune the model by using Low-Rank Adaptation (LoRA) to the Motion Layers, without requiring any architecture change in the MMDiT. This selective adaptation enables our method to focus on motion-critical components, yielding reduced computational cost. Despite its simplicity, CoMoGen enables precise subject motion and plausible interactions with surrounding humans, objects, and scenes. Comprehensive experiments on different datasets show that CoMoGen consistently outperforms prior controllable video generation methods and achieves state-of-the-art performance in motion fidelity and perceptual realism. Project page: mericadil.github.io/CoMoGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoMoGen, a framework for generating controllable videos from an input image and binary mask sequence. It introduces a MaskAdapter that encodes the mask sequence as a latent residual injected into MMDiT via a cosine-weighted schedule, identifies 'Motion Layers' in the MMDiT attention space, applies LoRA only to those layers for fine-tuning, and claims this yields precise subject motion, plausible interactions, and SOTA results on motion fidelity and perceptual realism across datasets without architecture changes.
Significance. If the motion-layer selection mechanism is shown to isolate motion-critical components without side effects, the approach would provide a practical, low-cost adaptation strategy for uniform transformer-based video diffusion models that lack UNet-style hierarchy, potentially improving efficiency and controllability in mask-guided generation.
major comments (2)
- [Abstract / Method] Abstract and method description: the procedure for determining 'Motion Layers' in MMDiT attention space is stated to be novel and necessary because MMDiT lacks UNet hierarchy, yet no criterion, metric (e.g., attention statistics, gradient importance), algorithm, or layer-wise ablation is supplied. This selection is load-bearing for the central claim that selective LoRA produces motion control without affecting appearance or scene consistency.
- [Abstract] Abstract: the claim of 'comprehensive experiments' and 'state-of-the-art performance in motion fidelity and perceptual realism' is unsupported by any quantitative metrics, dataset names/sizes, baseline comparisons, or validation protocol for the motion layers. Without these, the data-to-claim link cannot be evaluated.
minor comments (1)
- [Abstract] The abstract asserts 'precise subject motion and plausible interactions' but provides no definition or measurement protocol for these properties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional detail would strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the procedure for determining 'Motion Layers' in MMDiT attention space is stated to be novel and necessary because MMDiT lacks UNet hierarchy, yet no criterion, metric (e.g., attention statistics, gradient importance), algorithm, or layer-wise ablation is supplied. This selection is load-bearing for the central claim that selective LoRA produces motion control without affecting appearance or scene consistency.
Authors: We agree that the selection procedure for Motion Layers requires explicit documentation. The manuscript currently asserts novelty without supplying the underlying criterion, metrics, or ablations. In the revised version we will insert a dedicated subsection in the Method section that describes the attention-statistic-based selection algorithm, the precise metrics employed, and the layer-wise ablation results demonstrating that these layers control motion while preserving appearance and scene consistency. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'comprehensive experiments' and 'state-of-the-art performance in motion fidelity and perceptual realism' is unsupported by any quantitative metrics, dataset names/sizes, baseline comparisons, or validation protocol for the motion layers. Without these, the data-to-claim link cannot be evaluated.
Authors: The abstract summarizes the experimental outcomes at a high level. To make the SOTA claims directly traceable to data, we will revise the abstract to name the datasets and their sizes, report the principal quantitative metrics (motion fidelity and perceptual realism scores), and reference the baseline comparisons. The full experimental protocol, including the motion-layer validation, already appears in Section 4; the abstract revision will ensure the high-level claims are explicitly supported by those results. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution
full rationale
The paper's central mechanism is the proposal of a novel (but undetailed in the provided text) procedure for identifying Motion Layers in MMDiT attention space followed by selective LoRA fine-tuning. No equations, fitted parameters, or self-citations are shown that reduce the claimed motion control or performance gains to a definition or input by construction. The abstract frames the work as an empirical engineering advance with experimental validation on datasets, and the selection of layers is presented as a methodological choice rather than a self-referential derivation. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a novel way to determine 'Motion Layers' operating in the attention space of MMDiT... S_ℓ = sum M_f ⊗ A / sum A
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoRA on Motion Layers... cosine-weighted latent injection w_s = 1/2 (1 + cos(π t_s))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Akkerman, R., Feng, H., Black, M.J., Tzionas, D., Abrevaya, V.F.: Interdyn: Con- trollable interactive dynamics with video diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12467–12479 (2025)
work page 2025
-
[2]
arXiv preprint arXiv:2503.14492 (2025)
Alhaija, H.A., Alvarez, J., Bala, M., Cai, T., Cao, T., Cha, L., Chen, J., Chen, M., Ferroni, F., Fidler, S., et al.: Cosmos-transfer1: Conditional world generation with adaptive multimodal control. arXiv preprint arXiv:2503.14492 (2025)
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Avrahami, O., Patashnik, O., Fried, O., Nemchinov, E., Aberman, K., Lischinski, D., Cohen-Or, D.: Stable flow: Vital layers for training-free image editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 7877–7888 (June 2025)
work page 2025
-
[4]
Bahmani, S., Skorokhodov, I., Qian, G., Siarohin, A., Menapace, W., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. Proc. CVPR (2025)
work page 2025
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Bhatnagar, B.L., Xie, X., Petrov, I., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: Behave: Dataset and method for tracking human object interactions. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (jun 2022)
work page 2022
-
[7]
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets (2023),https: //arxiv.org/abs/2311.15127
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
work page 2023
-
[9]
In: CVPR (2025), licensed under Modified Apache 2.0 with special crediting requirement
Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., Ryoo, M., Debevec, P., Yu, N.: Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise. In: CVPR (2025), licensed under Modified Apache 2.0 with special crediting requirement
work page 2025
-
[10]
Cai, M., Cun, X., Li, X., Liu, W., Zhang, Z., Zhang, Y., Shan, Y., Yue, X.: Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video generation. arXiv:2412.18597 (2024)
-
[11]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Cao, M., Wang, X., Qi, Z., Shan, Y., Qie, X., Zheng, Y.: Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22560–22570 (October 2023)
work page 2023
-
[12]
arXiv preprint arXiv:2504.03072 (2025) 16 Meric et al
Chang, P., Tang, J., Gross, M., Azevedo, V.C.: How i warped your noise: a temporally-correlated noise prior for diffusion models. arXiv preprint arXiv:2504.03072 (2025) 16 Meric et al
-
[13]
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-basedsemanticguidancefortext-to-imagediffusionmodels.ACMTrans- actions on Graphics (TOG)42, 1 – 10 (2023),https://api.semanticscholar. org/CorpusID:256416326
work page 2023
-
[14]
In: Proceedings of the 41st International Conference on Machine Learning
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., Rom- bach, R.: Scaling rectified flow transformers for high-resolution image synthesis. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
work page 2024
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Aytar, Y., Rubinstein, M., Sun, C., et al.: Motion prompting: Controlling video generation with motion trajectories. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1–12 (2025)
work page 2025
-
[16]
arXiv preprint arXiv:2412.02700 (2024)
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Doersch, C., Aytar, Y., Rubinstein, M., Sun, C., Wang, O., Owens, A., Sun, D.: Motion prompting: Controlling video generation with motion trajectories. arXiv preprint arXiv:2412.02700 (2024)
-
[17]
Goel, S., Pavlakos, G., Rajasegaran, J., Kanazawa, A., Malik, J.: Humans in 4D: Reconstructing and tracking humans with transformers. In: ICCV (2023)
work page 2023
-
[18]
Google: A new era of intelligence with gemini 3.https://blog.google/products- and-platforms/products/gemini/gemini-3/(November 2025), accessed: 2026- 01-21
work page 2025
-
[19]
arXiv preprint arXiv:2501.03847 (2025)
Gu, Z., Yan, R., Lu, J., Li, P., Dou, Z., Si, C., Dong, Z., Liu, Q., Lin, C., Liu, Z., Wang, W., Liu, Y.: Diffusion as shader: 3d-aware video diffusion for versatile video generation control. arXiv preprint arXiv:2501.03847 (2025)
-
[20]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
In: The Eleventh In- ternational Conference on Learning Representations (2023),https://openreview
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross-attention control. In: The Eleventh In- ternational Conference on Learning Representations (2023),https://openreview. net/forum?id=_CDixzkzeyb
work page 2023
-
[22]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
In: Pro- ceedings of the 34th International Conference on Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Pro- ceedings of the 34th International Conference on Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
work page 2020
-
[24]
Advances in neural information processing systems35, 8633– 8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633– 8646 (2022)
work page 2022
-
[25]
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf9
work page 2022
-
[26]
arXiv preprint arXiv:2503.18950 (2025)
Kim, T., Joo, H.: Target-aware video diffusion models. arXiv preprint arXiv:2503.18950 (2025)
-
[27]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) CoMoGen 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Kuang, Z., Cai, S., He, H., Xu, Y., Li, H., Guibas, L., Wetzstein, G.: Collabo- rative video diffusion: Consistent multi-video generation with camera control. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=arHJlYiY2J
work page 2024
-
[29]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., Wu, Z.: Magicmotion: Control- lable video generation with dense-to-sparse trajectory guidance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 12112– 12123 (October 2025)
work page 2025
-
[31]
Evaluating text-to-visual generation with image-to-text models.preprint arXiv:2404.01291, 2024
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291 (2024)
-
[32]
Ling, P., Bu, J., Zhang, P., Dong, X., Zang, Y., Wu, T., Chen, H., Wang, J., Jin, Y.: Motionclone: Training-free motion cloning for controllable video generation. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=aY3L65HgHJ
work page 2025
-
[33]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conferenceon LearningRepresentations(2019),https://openreview.net/forum? id=Bkg6RiCqY7
work page 2019
-
[35]
com / JonathonLuiten / TrackEval(2020)
Luiten, J., Hoffhues, A.: Trackeval.https : / / github . com / JonathonLuiten / TrackEval(2020)
work page 2020
-
[36]
International Journal of Computer Vision pp
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixé, L., Leibe, B.: Hota: A higher order metric for evaluating multi-object tracking. International Journal of Computer Vision pp. 1–31 (2020)
work page 2020
-
[37]
arXiv preprint arXiv:2412.05275 (2024)
Meral, T.H.S., Yesiltepe, H., Dunlop, C., Yanardag, P.: Motionflow: Attention- driven motion transfer in video diffusion models. arXiv preprint arXiv:2412.05275 (2024)
-
[38]
Montanaro, A., Aira, L.S., Aiello, E., Valsesia, D., Magli, E.: Motioncraft: Physics- based zero-shot video generation. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum? id=lvcWA24dxB
work page 2024
-
[39]
Namekata, K., Bahmani, S., Wu, Z., Kant, Y., Gilitschenski, I., Lindell, D.B.: Sg-i2v: Self-guided trajectory control in image-to-video generation. In: The Thir- teenth International Conference on Learning Representations (2025),https:// openreview.net/forum?id=uQjySppU9x
work page 2025
-
[40]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4172–4182 (2023).https://doi.org/10.1109/ICCV51070.2023.00387
-
[41]
In: Computer Vision and Pattern Recognition (2016)
Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: Computer Vision and Pattern Recognition (2016)
work page 2016
-
[42]
arXiv preprint arXiv:2406.16863 (2024) 18 Meric et al
Qiu, H., Chen, Z., Wang, Z., He, Y., Xia, M., Liu, Z.: Freetraj: Tuning-free trajec- tory control in video diffusion models. arXiv preprint arXiv:2406.16863 (2024) 18 Meric et al
-
[43]
Qiu, H., Chen, Z., Wang, Z., He, Y., Xia, M., Liu, Z.: Freetraj: Tuning-free tra- jectory control via noise guided video diffusion (2025),https://openreview.net/ forum?id=CU7QfWJ6nC
work page 2025
-
[44]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024),https://arxiv.org/ abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2021)
work page 2021
-
[46]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S.K.S., Gontijo-Lopes, R., Ayan, B.K., Salimans, T., Ho, J., Fleet, D.J., Norouzi, M.: Photorealistic text-to-image diffusion models with deep language understand- ing. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural In- formation Processing Systems (...
work page 2022
-
[47]
Shi, X., Huang, Z., Wang, F.Y., Bian, W., Li, D., Zhang, Y., Zhang, M., Cheung, K.C., See, S., Qin, H., et al.: Motion-i2v: Consistent and controllable image-to- video generation with explicit motion modeling. SIGGRAPH 2024 (2024)
work page 2024
-
[48]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conferenceon LearningRepresentations(2021),https://openreview.net/forum? id=St1giarCHLP
work page 2021
- [49]
-
[50]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-or, D., Bermano, A.H.: Human motion diffusion model. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
work page 2023
-
[51]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Advances in Neural Information Processing Systems36, 7594–7611 (2023)
Wang, X., Yuan, H., Zhang, S., Chen, D., Wang, J., Zhang, Y., Shen, Y., Zhao, D., Zhou, J.: Videocomposer: Compositional video synthesis with motion control- lability. Advances in Neural Information Processing Systems36, 7594–7611 (2023)
work page 2023
-
[53]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
work page 2024
- [54]
-
[55]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
arXiv preprint arxiv:2311.17009 (2023) CoMoGen 19
Yatim, D., Fridman, R., Bar-Tal, O., Kasten, Y., Dekel, T.: Space-time diffusion features for zero-shot text-driven motion transfer. arXiv preprint arxiv:2311.17009 (2023) CoMoGen 19
-
[57]
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: CLEVRER: collision events for video representation and reasoning. In: ICLR (2020)
work page 2020
-
[58]
Yin, S., Wu, C., Liang, J., Shi, J., Li, H., Ming, G., Duan, N.: Dragnuwa: Fine- grainedcontrolinvideogenerationbyintegratingtext,image,andtrajectory.arXiv preprint arXiv:2308.08089 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models (2023)
work page 2023
-
[60]
Zhang, Y., Butt, A.A., Varol, G., Laptev, I.: Interpose: Learning to generate human-object interactions from large-scale web videos. arXiv (2025)
work page 2025
-
[62]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Z., Liao, J., Li, M., Dai, Z., Qiu, B., Zhu, S., Qin, L., Wang, W.: Tora: Trajectory-oriented diffusion transformer for video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2063–2073 (2025)
work page 2063
-
[63]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024) 20 Meric et al. A Implementation Details We train models on two different datasets: one on CLEVRER [57] and one on BEHAVE [6]. This mirrors the experimental goal of isolati...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.