Multilingual Steering by Design: Multilingual Sparse Autoencoders and Principled Layer Selection
Pith reviewed 2026-05-25 05:33 UTC · model grok-4.3
The pith
Training sparse autoencoders on multilingual data strengthens cross-lingual representations and enables reliable language control by selecting layers via the intersection of alignment and separability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
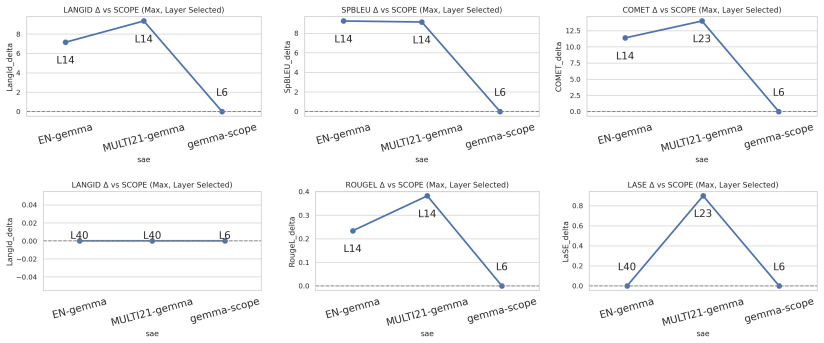
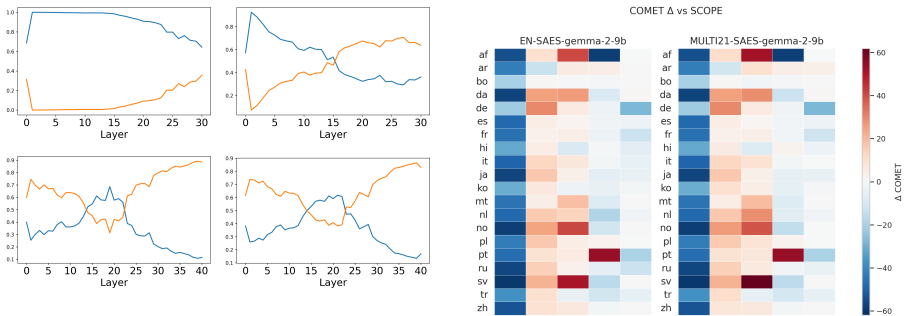
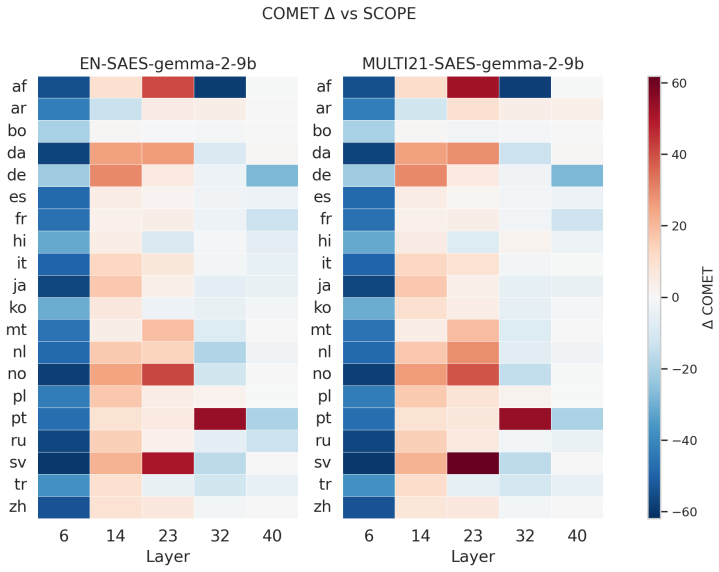
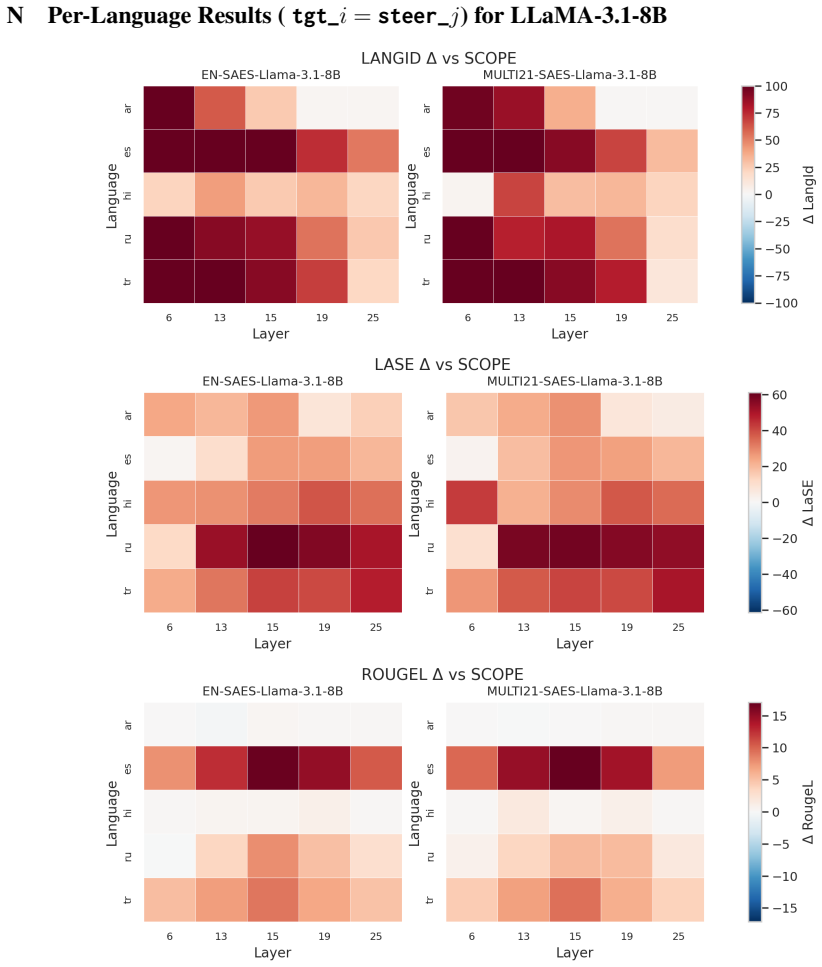
Training SAEs on multilingual data consistently strengthens cross-lingual representations and yields more reliable, quality-preserving language control across layers and model families. An a priori steering layer-selection rule based on the intersection of multilingual alignment and language separability predicts effective intervention depths without exhaustive layerwise search.
What carries the argument
Multilingual sparse autoencoders trained on mixed-language data, together with an intersection metric of multilingual alignment and language separability used to select intervention layers.
Load-bearing premise
The intersection of multilingual alignment and language separability at a given layer reliably predicts which layers will work best for steering without needing post-hoc checks on new models or tasks.
What would settle it
A demonstration that layers chosen by the intersection metric produce no better steering results than randomly chosen or heuristically chosen layers on a new model family or task would falsify the predictive rule.
Figures



























read the original abstract
Sparse autoencoders (SAEs) enable feature-level mechanistic interpretability and activation steering in large language models (LLMs), but SAE-based language control remains unreliable in multilingual settings: most SAEs are trained on English-only data, and steering layers are chosen heuristically. We address these limitations by advancing a principled, mechanistic account of multilingual language steering with SAEs. First, we show that training SAEs on multilingual data consistently strengthens cross-lingual representations and yields more reliable, quality-preserving language control across layers and model families. Second, we introduce an \emph{a priori} steering layer-selection rule based on the intersection of multilingual alignment and language separability, which predicts effective intervention depths without exhaustive layerwise search. We evaluate our approach on LLaMA-3.1-8B and Gemma-2-9B across machine translation and cross-lingual summarization (CrossSumm), using SpBLEU, ROUGE-L, COMET, and LaSE. Our results show that multilingual SAEs combined with intersection-selected layers stabilize the trade-off between language identification accuracy and generation quality, providing a principled, predictive, representation-level account of multilingual SAE steering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training sparse autoencoders (SAEs) on multilingual data strengthens cross-lingual representations and enables more reliable, quality-preserving language control across layers and model families. It introduces an a priori layer-selection rule based on the intersection of multilingual alignment and language separability metrics to predict effective steering depths without exhaustive search. Evaluations on LLaMA-3.1-8B and Gemma-2-9B for machine translation and cross-lingual summarization (CrossSumm) using SpBLEU, ROUGE-L, COMET, and LaSE are said to show that multilingual SAEs with intersection-selected layers stabilize the trade-off between language identification accuracy and generation quality.
Significance. If the empirical claims hold, the work advances mechanistic interpretability by providing a representation-level account of multilingual SAE steering that reduces heuristic choices and English-centric biases. The a priori selection rule, if validated, would be a notable contribution for scalable intervention in multilingual settings.
major comments (1)
- Abstract: the central claim that the intersection metric of multilingual alignment and language separability is a reliable a priori predictor of steering effectiveness is load-bearing, yet the abstract provides no definition, computation details, or cross-validation evidence for this metric, leaving its generalization beyond the two tested models and tasks unaddressed.
minor comments (1)
- Abstract: no quantitative results, effect sizes, or specific metric improvements (e.g., changes in SpBLEU or COMET) are reported despite claims of stabilized trade-offs, which hinders assessment of practical impact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's presentation of our central contribution. We address the concern point by point below.
read point-by-point responses
-
Referee: Abstract: the central claim that the intersection metric of multilingual alignment and language separability is a reliable a priori predictor of steering effectiveness is load-bearing, yet the abstract provides no definition, computation details, or cross-validation evidence for this metric, leaving its generalization beyond the two tested models and tasks unaddressed.
Authors: We agree the abstract would benefit from greater precision on this point. The manuscript body defines multilingual alignment as the cosine similarity between language-specific mean SAE activations and language separability as the accuracy of a linear probe on SAE latents; the intersection rule selects layers where both exceed English-derived thresholds, computed on a held-out multilingual calibration set. Cross-validation evidence appears in the layerwise steering results for MT and CrossSumm on LLaMA-3.1-8B and Gemma-2-9B (Tables 3–5, Figures 4–6). We will revise the abstract to include a concise parenthetical definition of the metrics and a reference to the empirical validation. The paper evaluates the rule on the two models and two tasks reported and does not claim generalization beyond this scope. revision: yes
Circularity Check
No significant circularity; derivation is empirically grounded and self-contained
full rationale
The paper's central claims rest on two empirical demonstrations: (1) multilingual SAE training improves cross-lingual steering reliability, and (2) an independently computed intersection metric of multilingual alignment and language separability at each layer predicts effective steering depths. Neither result is obtained by fitting parameters to the target steering outcomes and then relabeling those fits as predictions; the layer-selection rule is presented as a priori and is validated post-hoc on held-out tasks and models. No self-citation chain, self-definitional equations, or ansatz smuggling is described in the abstract or reader's summary. The derivation chain therefore remains non-circular and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing
The geometry of multilingual language model representations. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing. Association for Computational Linguis- tics. Cheng-Ting Chou, George Liu, Jessica Sun, Cole Blondin, Kevin Zhu, Vasu Sharma, and Sean O’Brien
work page 2022
-
[3]
Causal language control in multilingual trans- formers via sparse feature steering. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics: Student Research Workshop. Association for Computational Linguistics. Alexis Conneau, Shijie Wu, Haoran Li, Luke Zettle- moyer, and Veselin Stoyanov. 2020. Emerging cross- lingual ...
work page 2020
-
[4]
No Language Left Behind: Scaling Human-Centered Machine Translation
Association for Computational Linguistics. Marta R Costa-Jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, and 1 others. 2022. No language left behind: Scaling human-centered machine translation.arXiv preprint arXiv:2207.04672. Hoagy Cunningham, Aidan Ewart, Logan Rig...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Clas-bench: A cross-lingual alignment and steering benchmark.Preprint, arXiv:2601.08331. Daniil Gurgurov, Katharina Trinley, Yusser Al Ghussin, Tanja Baeumel, Josef van Genabith, and Simon Oster- mann. 2025. Language arithmetics: Towards system- atic language neuron identification and manipulation. InProceedings of the 14th International Joint Con- ferenc...
-
[6]
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov
Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders.arXiv preprint arXiv:2410.20526. Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov
-
[7]
Fasttext.zip: Compressing text classification models.arXiv preprint arXiv:1612.03651. Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Isaac Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum Stuart Mcdougall, Kola Ay- onrinde, Demian Till, Matthew Wearden, Arthur Conmy, Samuel Marks, and Neel Nanda. 2025. SAEBench: A comprehensive benchmark...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Interpretable steering of large language mod- els with feature guided activation additions.arXiv preprint arXiv:2501.09929. Shaomu Tan, Di Wu, and Christof Monz. 2024. Neuron specialization: Leveraging intrinsic task modularity for multilingual machine translation. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing,...
-
[9]
Encode the activation into sparse space: zℓ(x) = Encoderℓ(hℓ(x))
-
[10]
Apply the steering vector: z′ ℓ(x) =z ℓ(x) +α w DiffMean(ℓ), where α controls steering strength. We use fixed steering coefficients for all test examples within each model setting, with α= 5.0 for LLaMA and α= 100.0 for Gemma. These values were chosen in preliminary experi- ments as conservative values that improved target-language identification, and wer...
-
[11]
Decode back to dense space: ˆh′ ℓ(x) = Decoderℓ(z′ ℓ(x))
-
[12]
The corrected activation ˜hℓ(x) is then passed to subsequent layers
Correct for reconstruction error by adding the residual: ˜hℓ(x) = ˆh′ ℓ(x)+ hℓ(x)−Decoder ℓ(zℓ(x)) . The corrected activation ˜hℓ(x) is then passed to subsequent layers. This procedure preserves the original activation outside the SAE subspace while applying a targeted intervention along the language direction. D Language Correlation and Intersection-Base...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.