RoboSurg-VQA: A Multimodal Benchmark for Surgical Segmentation-Aware Visual Question Answering
Pith reviewed 2026-05-25 05:21 UTC · model grok-4.3
The pith
RoboSurg-VQA is a new segmentation-aware VQA benchmark created by repurposing public surgical datasets with fixed clinically motivated questions and closed answer sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
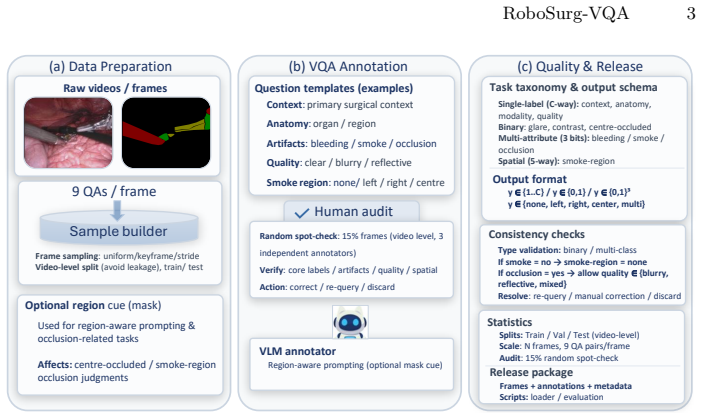
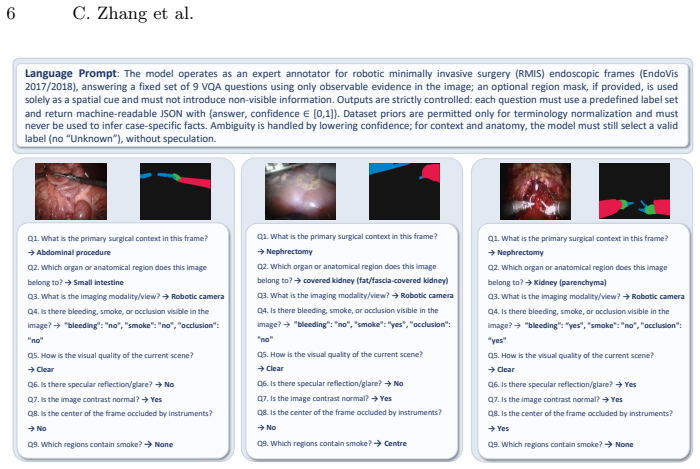
We present RoboSurg-VQA, a segmentation-aware visual question answering (VQA) benchmark built by repurposing public surgical segmentation datasets under a shared schema. Each frame is paired with a fixed set of clinically motivated questions spanning procedure context, anatomy, imaging modality/view, surgical artefacts, image quality, and basic visibility and spatial attributes, with closed answer sets.
Load-bearing premise
That constrained prompting plus automatic validity checks followed by human auditing produces labels that are sufficiently accurate, consistent, and clinically representative without introducing systematic biases from the generation process.
Figures


read the original abstract
Reliable visual understanding in robot-assisted and minimally invasive surgery (RMIS/MIS) demands more than accurate masks: in clinical practice, clinicians pose language-like questions about procedural context, visibility, artefacts, and the presence of anatomical structures and surgical instruments, often under degraded views caused by occlusion, smoke, bleeding, and specular highlights. We present \textbf{RoboSurg-VQA}, a segmentation-aware visual question answering (VQA) benchmark built by repurposing public surgical segmentation datasets under a shared schema. Each frame is paired with a fixed set of clinically motivated questions spanning procedure context, anatomy (including region), imaging modality/view, surgical artefacts, image quality, and basic visibility and spatial attributes, with closed answer sets to enable consistent evaluation. To scale annotation, we generate candidate answers via constrained prompting with automatic validity and consistency checks, followed by human auditing to improve plausibility and label consistency. We report benchmark statistics, sanity baselines, and common evaluation challenges under challenging surgical conditions. The code will be available on https://github.com/ziyangwang007/Robosurg-VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RoboSurg-VQA, a segmentation-aware VQA benchmark constructed by repurposing existing public surgical segmentation datasets under a shared schema. Each frame receives a fixed set of clinically motivated questions on procedure context, anatomy/region, imaging modality/view, surgical artefacts, image quality, visibility, and spatial attributes, all with closed answer sets. Candidate labels are produced via constrained LLM prompting plus automatic validity/consistency checks, followed by human auditing. The paper reports benchmark statistics, sanity baselines, and common evaluation challenges under degraded surgical conditions.
Significance. If the labels prove reliable, the benchmark would usefully extend surgical scene understanding beyond masks to clinically relevant language queries and could support joint segmentation-VQA models. The shared schema across datasets and emphasis on artefacts/occlusion/smoke are practical strengths. The construction pipeline is a reasonable attempt at scalable annotation, but the lack of any quantitative validation of label quality makes the usability claim provisional rather than demonstrated.
major comments (1)
- [Abstract and Methods] Abstract / Methods (annotation pipeline description): The central claim that RoboSurg-VQA constitutes a usable, reliable benchmark rests on the assertion that constrained prompting, automatic checks, and human auditing yield accurate, consistent, and clinically representative closed-answer labels. No quantitative evidence is supplied—error rates, inter-rater agreement, bias from the LLM step, or agreement between audited vs. fully manual labels are absent. This is load-bearing for the benchmark's claimed value.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential utility of the shared schema and artefact-focused questions. We agree that quantitative validation of label quality is necessary to move the usability claim from provisional to demonstrated and will strengthen this aspect in revision.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract / Methods (annotation pipeline description): The central claim that RoboSurg-VQA constitutes a usable, reliable benchmark rests on the assertion that constrained prompting, automatic checks, and human auditing yield accurate, consistent, and clinically representative closed-answer labels. No quantitative evidence is supplied—error rates, inter-rater agreement, bias from the LLM step, or agreement between audited vs. fully manual labels are absent. This is load-bearing for the benchmark's claimed value.
Authors: We acknowledge the absence of quantitative label-quality metrics in the current manuscript. The pipeline description emphasizes constrained prompting plus automatic checks followed by human auditing to improve plausibility and consistency, but no error rates, inter-rater statistics, or LLM-vs-audited comparisons are reported. In the revised manuscript we will add a dedicated validation subsection that includes: (i) inter-rater agreement (Cohen’s kappa) computed on a randomly sampled subset of frames re-annotated by two additional clinical experts; (ii) agreement between the initial LLM candidate labels and the final audited labels; and (iii) a small-scale comparison of audited versus fully manual labels on a held-out set. These additions will supply the requested empirical evidence while preserving the scalable construction approach. revision: yes
Circularity Check
No circularity: dataset construction with no derivations or self-referential claims
full rationale
The paper presents a benchmark dataset created by repurposing public surgical segmentation datasets, generating labels via constrained LLM prompting plus automatic checks and human auditing. No equations, fitted parameters, predictions, or mathematical derivations are present. No self-citations are invoked as load-bearing for any uniqueness theorem or ansatz. The central claim (a usable VQA benchmark under a shared schema) does not reduce to its inputs by construction; it is a self-contained data curation effort. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Public surgical segmentation datasets can be directly repurposed under a shared schema without loss of clinical validity.
- domain assumption Constrained prompting with automatic checks plus human auditing yields sufficiently consistent and plausible labels.
Reference graph
Works this paper leans on
-
[1]
Scientific Data12(1), 825 (2025)
Alabi, O., et al.: CholecInstanceSeg: a tool instance segmentation dataset for la- paroscopic surgery. Scientific Data12(1), 825 (2025)
2025
-
[2]
Medical Image Analysis p
Alabi, O., et al.: Multitask learning in minimally invasive surgical vision: a review. Medical Image Analysis p. 103480 (2025)
2025
-
[3]
arXiv preprint arXiv:2001.11190 (2020)
Allan, M., Kondo, S., Bodenstedt, S., Leger, S., Kadkhodamohammadi, R., Luengo, I., Fuentes, F., Flouty, E., Mohammed, A., Pedersen, M., et al.: 2018 robotic scene segmentation challenge. arXiv preprint arXiv:2001.11190 (2020)
-
[4]
2017 Robotic Instrument Segmentation Challenge
Allan, M., et al.: 2017 robotic instrument segmentation challenge. arXiv preprint arXiv:1902.06426 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
In: Proceedings of the IEEE International Con- ference on Computer Vision (ICCV)
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: VQA: Visual question answering. In: Proceedings of the IEEE International Con- ference on Computer Vision (ICCV). pp. 2425–2433 (2015)
2015
-
[6]
arXiv preprint arXiv:2305.11692 (2023)
Bai, L., Islam, M., Seenivasan, L., Ren, H.: Surgical-VQLA: transformer with gated vision-language embedding for visual question localized-answering in robotic surgery. arXiv preprint arXiv:2305.11692 (2023)
-
[7]
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
Bodenstedt, S., et al.: Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery. arXiv preprint arXiv:1805.02475 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Scientific Data10(1), 1–8 (2023)
Carstens, M., et al.: The Dresden Surgical Anatomy Dataset for abdominal organ segmentation in surgical data science. Scientific Data10(1), 1–8 (2023)
2023
-
[9]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the V in VQA Matter: elevating the role of image understanding in visual question answer- ing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6904–6913 (2017)
2017
-
[10]
In: International Conference on Multimedia Modeling
Jha, D., et al.: Kvasir-Instrument: diagnostic and therapeutic tool segmentation dataset in gastrointestinal endoscopy. In: International Conference on Multimedia Modeling. pp. 218–229. Springer (2021)
2021
-
[11]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Kirillov, A., et al.: Segment Anything. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 4015–4026 (2023)
2023
-
[12]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI
Koleilat, T., Asgariandehkordi, H., Rivaz, H., Xiao, Y.: MedCLIP-SAM: bridging text and image towards universal medical image segmentation. In: Medical Image Computing and Computer Assisted Intervention – MICCAI. pp. 643–653. Springer (2024)
2024
-
[13]
Scientific Data 5(1), 180251 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data 5(1), 180251 (2018)
2018
-
[14]
In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI)
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: SLAKE: a semantically- labeled knowledge-enhanced dataset for medical visual question answering. In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). pp. 1650–1654. IEEE (2021)
2021
-
[15]
Nature Communications15(1), 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment Anything in Medical Images. Nature Communications15(1), 654 (2024)
2024
-
[16]
arXiv preprint arXiv:2312.12429 (2023)
Murali, A., et al.: The Endoscapes dataset for surgical scene segmentation, object detection, and critical view of safety assessment: official splits and benchmark. arXiv preprint arXiv:2312.12429 (2023)
-
[17]
arXiv preprint arXiv:2401.00496 (2023) 10 C
Psychogyios, D., et al.: SAR-RARP50: segmentation of surgical instrumentation and action recognition on robot-assisted radical prostatectomy challenge. arXiv preprint arXiv:2401.00496 (2023) 10 C. Zhang et al
-
[18]
arXiv preprint arXiv:2407.19305 (2024)
Schmidgall, S., Cho, J., Zakka, C., Hiesinger, W.: GP-VLS: a general-purpose vision language model for surgery. arXiv preprint arXiv:2407.19305 (2024)
-
[19]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI
Seenivasan, L., Islam, M., Kannan, G., Ren, H.: SurgicalGPT: end-to-end language- vision GPT for visual question answering in surgery. In: Medical Image Computing and Computer Assisted Intervention – MICCAI. pp. 281–290. Springer (2023)
2023
-
[20]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI
Seenivasan, L., Islam, M., Krishna, A.K., Ren, H.: Surgical-VQA: visual question answering in surgical scenes using transformer. In: Medical Image Computing and Computer Assisted Intervention – MICCAI. pp. 33–43. Springer (2022)
2022
-
[21]
IEEE Transactions on Medical Imaging36(1), 86–97 (2017)
Twinanda, A.P., et al.: EndoNet: a deep architecture for recognition tasks on la- paroscopic videos. IEEE Transactions on Medical Imaging36(1), 86–97 (2017). https://doi.org/10.1109/TMI.2016.2593957
-
[22]
arXiv preprint arXiv:2501.11347 (2025)
Wang, G., et al.: EndoChat: grounded multimodal large language model for endo- scopic surgery. arXiv preprint arXiv:2501.11347 (2025)
-
[23]
IEEE Transactions on Medical Robotics and Bionics (2025)
Wang, Z., et al.: S4RoboFormer: scribble-supervised surgical robotic segmentation transformer via augmented consistency training. IEEE Transactions on Medical Robotics and Bionics (2025)
2025
-
[24]
npj Digital Medicine8(1), 566 (2025)
Zhao, Z., et al.: Large-vocabulary segmentation for medical images with text prompts. npj Digital Medicine8(1), 566 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.