Beyond Neural Activity Prediction: Probing Latent Representations in Mouse V1 Digital Twins
Pith reviewed 2026-06-30 15:11 UTC · model grok-4.3
The pith
Digital twins of mouse V1 with similar neural prediction accuracy can still differ substantially in probe performance and latent-unit tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
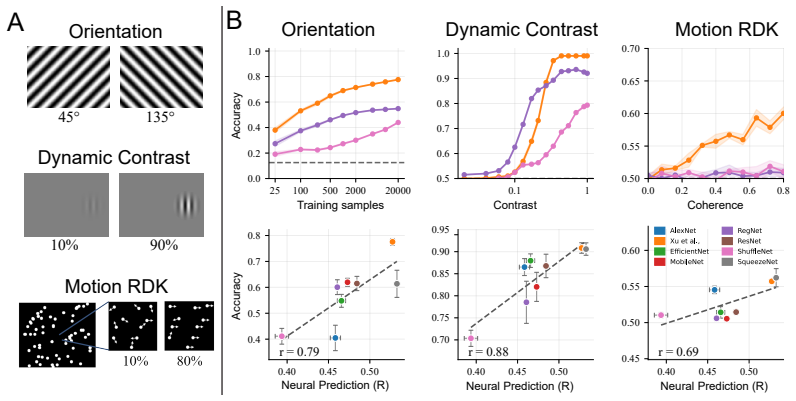
Across architectures, neural-response prediction accuracy correlates with stronger linear decodability of visual features and with flatter hidden-layer eigenspectra that approach the dimensionality signatures seen in real mouse V1; nevertheless, models that achieve comparable prediction scores continue to differ markedly in both probe accuracy and the detailed tuning of their latent units.
What carries the argument
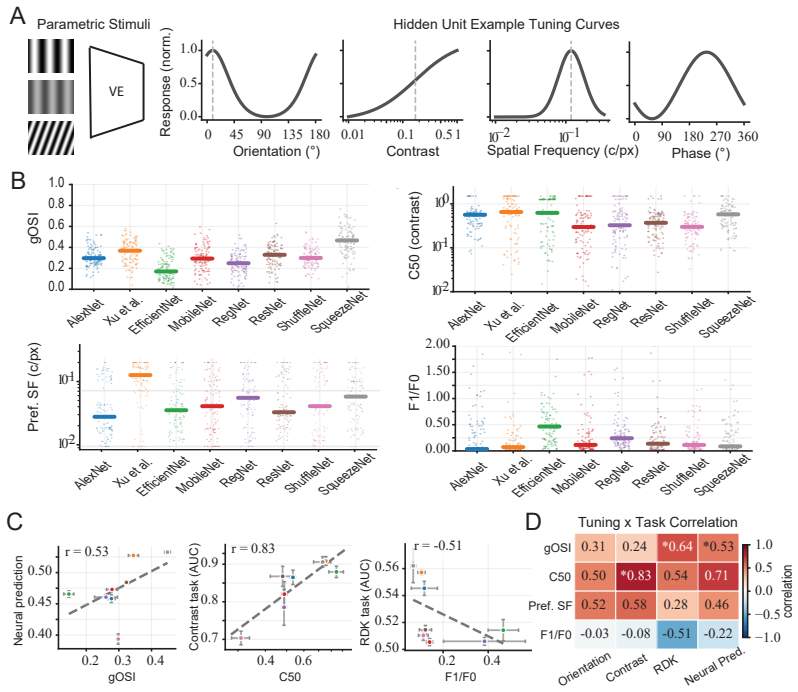
Multi-level representational probing that combines linear decodability from controlled visual stimuli, single-unit tuning curves for orientation and contrast, and analysis of hidden-population eigenspectra.
If this is right
- Higher prediction accuracy on naturalistic video is accompanied by improved linear readout of orientation, contrast, and motion from the same frozen layers.
- Models with stronger prediction performance exhibit flatter eigenspectra, indicating higher-dimensional population representations closer to those measured in biological V1.
- Prediction accuracy and representational properties covary across architectures but do not determine each other one-to-one.
- Digital twins that match on prediction error can still support different linear readouts and different single-unit tuning, so they are not interchangeable as in-silico experimental platforms.
Where Pith is reading between the lines
- Selecting a digital twin for stimulus-design experiments may require checking probe performance in addition to prediction accuracy to ensure the chosen model encodes the intended visual features.
- The observed spread in latent representations among equally predictive models suggests that architecture choice could systematically bias the outcomes of downstream in-silico tests even when training data and loss are held fixed.
- Extending the same probing protocol to models trained on different data regimes or loss functions would test whether the dissociation between prediction accuracy and internal geometry is architecture-specific or more general.
Load-bearing premise
Observed differences in decodability, tuning, and spectra reflect genuine distinctions in the computations the models perform rather than artifacts introduced by the specific probes or architectures chosen.
What would settle it
A result in which every pair of architectures that reach the same prediction accuracy also produce statistically indistinguishable probe accuracies, unit tuning curves, and eigenspectra would falsify the claim that comparable prediction scores can mask substantial representational differences.
Figures


read the original abstract
Digital twins of sensory cortex serve as powerful response oracles. Although prediction accuracy is the central metric by which these models are evaluated, it provides limited insight into the latent representations that support those predictions. This becomes increasingly important as digital twins are used as in silico experimental systems for stimulus design and hypothesis generation: models with similar prediction accuracy may rely on different latent representations. We address this gap by systematically probing a family of digital twins of mouse V1 trained to predict neural activity from naturalistic videos recorded in freely moving mice. The models share the same training data and neural-prediction objective, but differ in visual-encoder architecture. For each frozen model, we characterize latent representations along three levels: (i) linear decodability from controlled visual probes of orientation, contrast, and motion; (ii) latent-unit tuning to canonical visual features including orientation selectivity, contrast response, spatial-frequency tuning; and (iii) population geometry of hidden-layer activity. Across architectures, better neural-response prediction correlates with stronger probe accuracy. Additionally, highly predictive models exhibit flatter hidden-population eigenspectra, indicating higher-dimensional representations closer to population-geometry signatures reported in mouse V1. Although these representational properties covary with prediction accuracy across architectures, digital twins with comparable prediction scores can still differ substantially in probe performance and latent-unit tuning. These results establish multi-level representational probing as a complement to standard neural-prediction evaluation, providing a framework for understanding digital twins not only as predictors, but also as substrates for studying visual computations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper trains a family of digital twins of mouse V1 to predict neural responses to naturalistic videos, holding training data and objective fixed while varying only the visual-encoder architecture. It reports that neural-prediction accuracy correlates with linear probe accuracy on orientation/contrast/motion and with flatter hidden-layer eigenspectra, yet models achieving comparable prediction scores can still differ substantially in probe performance and latent-unit tuning properties.
Significance. If the empirical observations hold under the full methods and controls, the work supplies a concrete demonstration that prediction accuracy alone does not determine the internal representational geometry of these models. The multi-level probing protocol (linear decodability, single-unit tuning curves, population eigenspectra) therefore offers a practical complement to standard evaluation when digital twins are used for stimulus design or hypothesis generation.
minor comments (3)
- The abstract refers to 'flatter hidden-population eigenspectra' without stating the precise definition (e.g., participation ratio, power-law exponent, or normalized eigenvalue decay) or the layer at which it is computed; this should be clarified in the methods or results section.
- The claim that 'digital twins with comparable prediction scores can still differ substantially' would be strengthened by an explicit statement of the accuracy-matching criterion (e.g., within 1% or 2% of top performance) and the number of architecture pairs that satisfy it.
- Notation for the three probing levels (i)–(iii) is introduced in the abstract but not carried forward with consistent labels in the main text; a short table or subsection header mapping each probe to its quantitative metric would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments appear in the report.
Circularity Check
No significant circularity detected
full rationale
The manuscript reports empirical comparisons of neural-prediction accuracy versus linear decodability, unit tuning, and population eigenspectra across encoder architectures. No equations, derivations, or fitted-parameter predictions are presented; all reported quantities are direct measurements on held-out probes and hidden-layer activations. No self-citations are invoked as load-bearing premises, and the central claim (that matched prediction scores can coexist with divergent representational probes) follows from the experimental design of holding training data and objective fixed while varying architecture. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://journals.plos.org/ ploscompbiol/article?id=10.1371/journal.pcbi.1012056
doi: 10.1371/journal.pcbi.1012056. URL https://journals.plos.org/ ploscompbiol/article?id=10.1371/journal.pcbi.1012056. Colin Conwell, Jacob S. Prince, Kendrick N. Kay, George A. Alvarez, and Talia Konkle. A large- scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature Communications, 15:9383,
-
[2]
URL https://www.nature.com/articles/s41467-024-53147-y
doi: 10.1038/s41467-024-53147-y. URL https://www.nature.com/articles/s41467-024-53147-y. Zhiwei Ding, Dat Tran, Kayla Ponder, et al. Functional bipartite invariance in mouse primary visual cortex receptive fields.Nature Neuroscience,
-
[3]
URL https://www.nature.com/articles/s41593-026-02213-3
doi: 10.1038/s41593-026-02213-3. URL https://www.nature.com/articles/s41593-026-02213-3. Lindsey L. Glickfeld, Mark H. Histed, and John H. R. Maunsell. Mouse primary visual cortex is used to detect both orientation and contrast changes.Journal of Neuroscience, 33(50):19416– 19422,
-
[4]
URL https://www.jneurosci.org/ content/33/50/19416
doi: 10.1523/JNEUROSCI.3560-13.2013. URL https://www.jneurosci.org/ content/33/50/19416. Hojin Jang and Frank Tong. Improved modeling of human vision by incorporating robustness to blur in convolutional neural networks.Nature Communications, 15:1989,
-
[5]
Dario Liscai, Emanuele Luconi, Alessandro Marin Vargas, and Alessandro Sanzeni
URL https://proceedings.neurips.cc/ paper_files/paper/2017/file/8c249675aea6c3cbd91661bbae767ff1-Paper.pdf. Dario Liscai, Emanuele Luconi, Alessandro Marin Vargas, and Alessandro Sanzeni. Beyond single neurons: population response geometry in digital twins of mouse visual cortex. InInternational Conference on Learning Representations,
2017
-
[6]
doi: 10.1523/JNEUROSCI.0623-08.2008
ISSN 0270-6474, 1529-2401. doi: 10.1523/JNEUROSCI.0623-08.2008. URL https://www.jneurosci.org/lookup/doi/ 10.1523/JNEUROSCI.0623-08.2008. Philip R. L. Parker, Elliott T. T. Abe, Emmalyn S. P. Leonard, Dylan M. Martins, and Cristopher M. Niell. Joint coding of visual input and eye/head position in V1 of freely moving mice.Neuron, 110(23):3897–3906.e5, December
-
[7]
doi: 10.1016/j.neuron.2022.08.029
ISSN 0896-6273. doi: 10.1016/j.neuron.2022.08.029. URLhttps://www.sciencedirect.com/science/article/pii/S0896627322008042. Dario L. Ringach, Patrick J. Mineault, Elaine Tring, Nicholas D. Olivas, Pablo Garcia-Junco- Clemente, and Joshua T. Trachtenberg. Spatial clustering of tuning in mouse primary visual cortex.Nature Communications, 7:12270,
-
[8]
URL https: //www.nature.com/articles/ncomms12270
doi: 10.1038/ncomms12270. URL https: //www.nature.com/articles/ncomms12270. Marius Schneider, Joe Canzano, Jing Peng, Yuchen Hou, Spencer LaVere Smith, and Michael Beyeler. Mouse vs. AI: A Neuroethological Benchmark for Visual Robustness and Neural Alignment, September
-
[9]
URLhttp://arxiv.org/abs/2509.14446. arXiv:2509.14446 [q-bio]. Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. Brain-score: Which artificial neural network for object recognition is most brain-like? bioRxiv,
-
[10]
URL https://www.biorxiv.org/content/10.1101/ 407007v1
doi: 10.1101/407007. URL https://www.biorxiv.org/content/10.1101/ 407007v1. Jianghong Shi, Eric Shea-Brown, and Michael A. Buice. Comparison against task-driven artificial neural networks reveals functional organization of mouse visual cortex. InAdvances in Neural Information Processing Systems,
-
[11]
doi: 10.48550/arXiv.1911.07986. URL https://arxiv. org/abs/1911.07986. Jeffrey N. Stirman, Leah B. Townsend, and Spencer L. Smith. A touchscreen based global motion perception task for mice.Vision Research, 127:74–83,
-
[12]
URLhttps://pubmed.ncbi.nlm.nih.gov/27497283/
doi: 10.1016/j.visres.2016.07.006. URLhttps://pubmed.ncbi.nlm.nih.gov/27497283/. Carsen Stringer, Marius Pachitariu, Nicholas Steinmetz, Matteo Carandini, and Kenneth D Harris. High-dimensional geometry of population responses in visual cortex.Nature, 571(7765):361–365,
-
[13]
Polina Turishcheva, Max F. Burg, Fabian H. Sinz, and Alexander S. Ecker. Reproducibility of predictive networks for mouse visual cortex. InAdvances in Neural Information Processing Systems 37, 2024a. URLhttps://arxiv.org/abs/2406.12625. Polina Turishcheva, Paul G. Fahey, Laura Hansel, Rachel Froebe, Kayla Ponder, Michaela Vystrcilova, Konstantin F. Willek...
-
[14]
URL https://arxiv.org/abs/2206.08666. Aiwen Xu, Yuchen Hou, Cris M. Niell, and Michael Beyeler. Multimodal deep learning model unveils behavioral dynamics of V1 activity in freely moving mice. InAdvances in Neural Information Processing Systems 36, pages 15341–15357,
-
[15]
12 A Detailed Methods A.1 Neural-prediction training details Mouse sessions.We used publicly available freely moving neural recordings from Parker et al
URL https://openreview.net/forum? id=qv5UZJTNda. 12 A Detailed Methods A.1 Neural-prediction training details Mouse sessions.We used publicly available freely moving neural recordings from Parker et al. [2022], which are accessible through osf.io/msp3a/overview. The neural-prediction mod- els were trained jointly on three mouse V1 sessions: 070921_J553RT,...
2022
-
[16]
The visual encoder and GRU parameters were shared across all mice, whereas the readout matrices Wm and biasesb m were separate for each mouse
The final hidden state ht+4 ∈R 512 was mapped to neural responses by a mouse-specific linear readout Wmht+4 +b m followed by a softplus nonlinearity: by(m) t+5 = softplus(Wmht+4 +b m). The visual encoder and GRU parameters were shared across all mice, whereas the readout matrices Wm and biasesb m were separate for each mouse. Loss.For each minibatch from ...
2023
-
[17]
−1 2 x−µ exc σexc 2# −A inh exp
Each dimension of this vector was treated as a latent feature unit. This final 108-dimensional visual- encoder output has no explicit spatial layout, so units were indexed only by feature dimension. Because these encoder dimensions are signed model features rather than nonnegative firing rates, all tuning summaries in this section (orientation selectivity...
2016
-
[18]
A unit was considered responsive if the maximum peak-to-peak response across its orientation, phase, spatial-frequency, and contrast curves exceeded 10−6
Quality-control flags.Quality-control flags were used to identify units with measurable tuning for summary analyses. A unit was considered responsive if the maximum peak-to-peak response across its orientation, phase, spatial-frequency, and contrast curves exceeded 10−6. Orientation QC required responsiveness, finite gOSI, and an orientation response rang...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.