AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
Pith reviewed 2026-05-25 04:44 UTC · model grok-4.3
The pith
AutoResearch autonomy is credible only in structured, executable, and rapidly verifiable domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
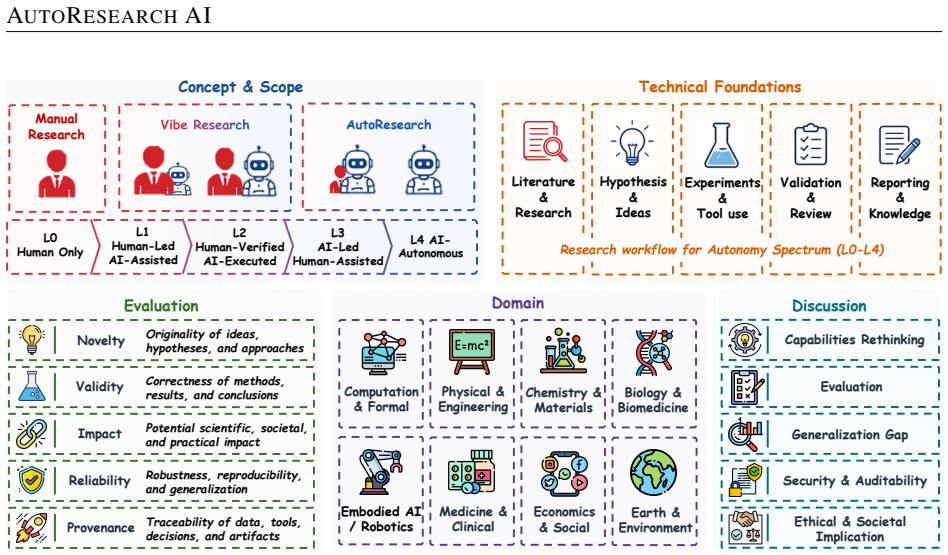
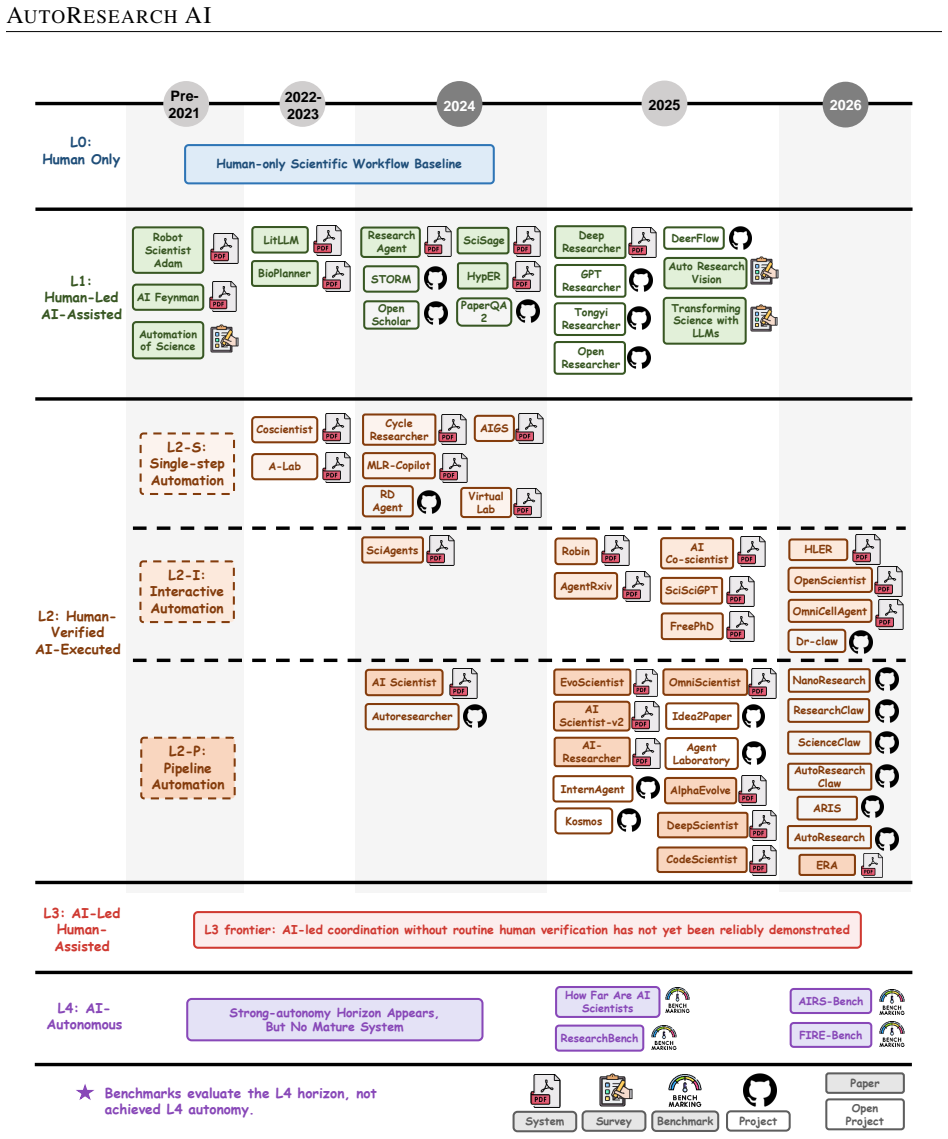
AutoResearch is defined as the developmental spectrum of AI-powered scientific workflow automation. Within it, Vibe Research covers human-steered prompt-based assistance while AI-led systems coordinate larger portions of the discovery loop. Analysis of how these systems redistribute control, evidence, execution, validation, and accountability shows that autonomy is domain-conditioned: more credible in structured, executable, and rapidly verifiable settings but limited in embodied, delayed, heterogeneous, ethical, or institutionally accountable contexts.
What carries the argument
AutoResearch, the developmental spectrum of AI-powered scientific workflow automation that partitions control across five workflow conditions: literature and research grounding; hypothesis formation and planning; experimentation and tool use; feedback, validation, and review; and reporting and knowledge communication.
If this is right
- Systems should be assessed using the five proposed dimensions of novelty, validity, impact, reliability, and provenance rather than isolated task metrics.
- Development of AI scientist systems will be more credible when restricted to structured domains with rapid verification mechanisms.
- Mixed-initiative frameworks remain necessary in domains involving ethics, embodiment, or institutional accountability.
- Challenges in evidence preservation, reproducibility, and provenance tracking persist across all surveyed systems regardless of autonomy level.
Where Pith is reading between the lines
- The same domain-conditioning pattern may appear in AI automation of non-scientific workflows such as legal analysis or engineering design.
- Cross-domain benchmarks that deliberately vary structure, verification speed, and ethical stakes could quantify the boundaries of current autonomy.
- Institutional review boards could serve as an external validation layer to extend AutoResearch into currently limited ethical and accountable contexts.
Load-bearing premise
The surveyed systems and literature can be meaningfully partitioned into the proposed spectrum of autonomy levels and five workflow conditions without significant overlap or omission that would alter the domain-conditioned conclusion.
What would settle it
A documented AI system achieving robust autonomy, with minimal human oversight, in an embodied domain such as physical robotics experimentation or in an ethical context such as human-subjects clinical research would falsify the domain-conditioned claim.
Figures










read the original abstract
Scientific research is being reshaped by AI systems that move beyond isolated assistance toward longer-horizon workflows spanning literature grounding, hypothesis generation, experimentation, validation, reporting, and revision. This shift marks a transition from task-level AI for science to workflow-level research automation. Yet current systems remain fragmented, differing in autonomy, domain scope, execution environment, validation mechanism, and human oversight, while still struggling with evidence preservation, reproducibility, weak-direction rejection, provenance tracking, cross-domain robustness, and accountable scientific closure. This survey examines these developments through AutoResearch, defined as the developmental spectrum of AI-powered scientific workflow automation. Within it, Vibe Research denotes the human-steered region of prompt-based assistance and human-verified execution, whereas emerging AI-led systems coordinate larger portions of the discovery loop without achieving robust autonomy. We analyze how research systems redistribute control, evidence, execution, validation, and accountability across workflows and organize the field around five workflow conditions: literature and research grounding; hypothesis formation and planning; experimentation and tool use; feedback, validation, and review; and reporting and knowledge communication. We further synthesize AI scientist systems, mixed-initiative co-research frameworks, benchmarks, domain deployments, and open-source infrastructures. Finally, we propose five evaluation dimensions--novelty, validity, impact, reliability, and provenance--and show that AutoResearch autonomy is domain-conditioned, being more credible in structured, executable, and rapidly verifiable settings but limited in embodied, delayed, heterogeneous, ethical, or institutionally accountable contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys AI systems for automating scientific research workflows, framing the field as 'AutoResearch'—a developmental spectrum from 'Vibe Research' (human-steered, prompt-based assistance with human-verified execution) to emerging AI-led systems that coordinate larger portions of the discovery loop. It organizes the literature around five workflow conditions (literature/research grounding; hypothesis formation/planning; experimentation/tool use; feedback/validation/review; reporting/knowledge communication), synthesizes AI scientist systems, mixed-initiative frameworks, benchmarks, domain deployments, and open-source infrastructures, proposes five evaluation dimensions (novelty, validity, impact, reliability, provenance), and concludes that AutoResearch autonomy is domain-conditioned: more credible in structured, executable, rapidly verifiable settings but limited in embodied, delayed, heterogeneous, ethical, or institutionally accountable contexts.
Significance. If the framework and partitioning hold, this survey offers a coherent synthesis of an emerging area, redistributing control/evidence/validation across workflows and delineating feasible versus limited domains for automation. The proposed evaluation dimensions provide a starting point for assessing such systems, and the domain-conditioned conclusion, if rigorously supported, would help prioritize research directions in structured versus complex settings.
major comments (1)
- [Section on workflow conditions and autonomy spectrum] The section organizing the field around the five workflow conditions and the autonomy spectrum (Vibe Research vs. AI-led): these are defined qualitatively without operational decision rules, boundary conditions, or assignment criteria (e.g., thresholds for autonomous steps, handling of iterative loops between experimentation and validation, or percentage-based classification). This partitioning is load-bearing for the central claim that autonomy is domain-conditioned, as non-trivial overlap or omission in system assignments could alter which domains appear limited.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our survey. We address the major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Section on workflow conditions and autonomy spectrum] The section organizing the field around the five workflow conditions and the autonomy spectrum (Vibe Research vs. AI-led): these are defined qualitatively without operational decision rules, boundary conditions, or assignment criteria (e.g., thresholds for autonomous steps, handling of iterative loops between experimentation and validation, or percentage-based classification). This partitioning is load-bearing for the central claim that autonomy is domain-conditioned, as non-trivial overlap or omission in system assignments could alter which domains appear limited.
Authors: We agree that the workflow conditions and autonomy spectrum (Vibe Research to AI-led) are defined qualitatively in the current manuscript. This choice reflects the emerging nature of the field, where systems are described in the literature using narrative capabilities rather than standardized metrics, making uniform quantitative thresholds (e.g., step percentages or loop-handling rules) premature and potentially arbitrary. The five conditions follow conventional research workflow stages, and system assignments draw from explicit descriptions in cited works. However, the referee's point is valid: clearer criteria would strengthen the domain-conditioned claim. In revision we will add explicit qualitative boundary conditions (e.g., based on degree of closed-loop execution without human intervention, presence of automated validation, and handling of iterative feedback), include a table mapping representative systems to the spectrum with justifications, and discuss iterative loops explicitly. These additions will be conceptual rather than numeric to avoid over-prescription. revision: yes
Circularity Check
No circularity: literature survey without derivations or self-referential reductions
full rationale
The paper is a qualitative survey that defines AutoResearch, Vibe Research, AI-led systems, and five workflow conditions (literature grounding; hypothesis/planning; experimentation/tool use; feedback/validation/review; reporting/communication) as organizing categories. It synthesizes existing systems and proposes evaluation dimensions but contains no equations, fitted parameters, predictions, or derivations. No step reduces a claimed result to its own inputs by construction, and no self-citation chain is load-bearing for a mathematical claim. The domain-conditioned autonomy conclusion follows from the surveyed literature rather than from any internal tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. Llm4sr: A survey on large language models for scientific research.arXiv preprint arXiv:2501.04306, 2025
-
[2]
Highly accurate protein structure pre- diction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure pre- diction with alphafold.nature, 596(7873):583–589, 2021
2021
-
[3]
Mourad Gridach, Jay Nanavati, Khaldoun Zine El Abidine, Lenon Mendes, and Christina Mack. Agentic ai for scientific discovery: A survey of progress, challenges, and future directions.arXiv preprint arXiv:2503.08979, 2025
-
[4]
Jiaqi Wei, Yuejin Yang, Xiang Zhang, Yuhan Chen, Xiang Zhuang, Zhangyang Gao, Dongzhan Zhou, Guang- shuai Wang, Zhiqiang Gao, Juntai Cao, et al. From ai for science to agentic science: A survey on autonomous scientific discovery.arXiv preprint arXiv:2508.14111, 2025
-
[5]
Evolving Roles of LLMs in Scientific Innovation: Assistant, Collaborator, Scientist, and Evaluator
Haoxuan Zhang, Ruochi Li, Yang Zhang, Ting Xiao, Jiangping Chen, Junhua Ding, and Haihua Chen. The evolving role of large language models in scientific innovation: Evaluator, collaborator, and scientist.arXiv preprint arXiv:2507.11810, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
From automation to autonomy: A survey on large language models in scientific discovery
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. From automation to autonomy: A survey on large language models in scientific discovery. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17744–17761, 2025
2025
-
[7]
Ai for science: Opportunities, challenges, and future directions.Authorea Preprints, 2025
Valerie Fu. Ai for science: Opportunities, challenges, and future directions.Authorea Preprints, 2025
2025
-
[8]
A process-centric survey of ai for scientific discovery through the exhyte framework
Md Musaddaqul Hasib, Sumin Jo, Harsh Sinha, Jifeng Song, Arun Das, Zhentao Liu, Hugh Galloway, Huey Huang, Kexun Zhang, Shou-Jiang Gao, et al. A process-centric survey of ai for scientific discovery through the exhyte framework. 2025
2025
-
[9]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Patrick Tser Jern Kon, Jiachen Liu, Qiuyi Ding, Yiming Qiu, Zhenning Yang, Yibo Huang, Jayanth Srini- vasa, Myungjin Lee, Mosharaf Chowdhury, and Ang Chen. Curie: Toward rigorous and automated scientific experimentation with ai agents.arXiv preprint arXiv:2502.16069, 2025
-
[12]
Yingming Pu, Tao Lin, and Hongyu Chen. Piflow: Principle-aware scientific discovery with multi-agent col- laboration.arXiv preprint arXiv:2505.15047, 2025
-
[13]
Large language models for automated scholarly paper review: A survey.Information Fusion, 124:103332, 2025
Zhenzhen Zhuang, Jiandong Chen, Hongfeng Xu, Yuwen Jiang, and Jialiang Lin. Large language models for automated scholarly paper review: A survey.Information Fusion, 124:103332, 2025
2025
-
[14]
A vision for auto research with llm agents.arXiv preprint arXiv:2504.18765, 2025
Chengwei Liu, Chong Wang, Jiayue Cao, Jingquan Ge, Kun Wang, Lyuye Zhang, Ming-Ming Cheng, Peng- hai Zhao, Tianlin Li, Xiaojun Jia, et al. A vision for auto research with llm agents.arXiv preprint arXiv:2504.18765, 2025
-
[15]
Litllm: A toolkit for scientific literature review.arXiv preprint arXiv:2402.01788, 2024
Shubham Agarwal, Gaurav Sahu, Abhay Puri, Issam H Laradji, Krishnamurthy DJ Dvijotham, Jason Stan- ley, Laurent Charlin, and Christopher Pal. Litllm: A toolkit for scientific literature review.arXiv preprint arXiv:2402.01788, 2024
-
[16]
Openscholar.https://github.com/AkariAsai/OpenScholar, 2026
GitHub repository. Openscholar.https://github.com/AkariAsai/OpenScholar, 2026
2026
-
[17]
Michael D Skarlinski, Sam Cox, Jon M Laurent, James D Braza, Michaela Hinks, Michael J Hammerling, Man- vitha Ponnapati, Samuel G Rodriques, and Andrew D White. Language agents achieve superhuman synthesis of scientific knowledge.arXiv preprint arXiv:2409.13740, 2024
-
[18]
Paperqa2.https://github.com/Future-House/paper-qa, 2026
GitHub repository. Paperqa2.https://github.com/Future-House/paper-qa, 2026
2026
-
[19]
Openhands: An open platform for ai software developers as generalist agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. InInternational Conference on Learning Representations, volume 2025, pages 65882–65919, 2025. 41 AUTORESEARCHAI
2025
-
[20]
Aider.https://github.com/Aider-AI/aider, 2026
GitHub repository. Aider.https://github.com/Aider-AI/aider, 2026
2026
-
[21]
Swe-agent.https://github.com/SWE-agent/SWE-agent, 2026
GitHub repository. Swe-agent.https://github.com/SWE-agent/SWE-agent, 2026
2026
-
[22]
Agent laboratory.https://github.com/SamuelSchmidgall/ AgentLaboratory, 2026
GitHub repository. Agent laboratory.https://github.com/SamuelSchmidgall/ AgentLaboratory, 2026
2026
-
[23]
Ai-researcher.https://github.com/HKUDS/AI-Researcher, 2026
GitHub repository. Ai-researcher.https://github.com/HKUDS/AI-Researcher, 2026
2026
-
[24]
Auto-claude-code-research-in-sleep (aris).https://github.com/wanshuiyin/ Auto-claude-code-research-in-sleep, 2026
GitHub repository. Auto-claude-code-research-in-sleep (aris).https://github.com/wanshuiyin/ Auto-claude-code-research-in-sleep, 2026
2026
-
[25]
Nanoresearch, 2026
OpenRaiser. Nanoresearch, 2026
2026
-
[26]
Alisia Lupidi, Bhavul Gauri, Thomas Simon Foster, Bassel Al Omari, Despoina Magka, Alberto Pepe, Alexis Audran-Reiss, Muna Aghamelu, Nicolas Baldwin, Lucia Cipolina-Kun, et al. Airs-bench: a suite of tasks for frontier ai research science agents.arXiv preprint arXiv:2602.06855, 2026
-
[27]
Guijin Son, Jiwoo Hong, Honglu Fan, Heejeong Nam, Hyunwoo Ko, Seungwon Lim, Jinyeop Song, Jinha Choi, Gonçalo Paulo, Youngjae Yu, et al. When ai co-scientists fail: Spot-a benchmark for automated verification of scientific research.arXiv preprint arXiv:2505.11855, 2025
-
[28]
Controla: Agentic workflow control mechanisms for reliable science
Amal Gueroudji, Tanwi Mallick, Renan Souza, Rafael Ferreira Da Silva, Robert Ross, Matthieu Dorier, Philip Carns, Kyle Chard, and Ian Foster. Controla: Agentic workflow control mechanisms for reliable science. In 2025 IEEE International Conference on eScience (eScience), pages 415–426. IEEE, 2025
2025
-
[29]
Qiujie Xie, Yixuan Weng, Minjun Zhu, Fuchen Shen, Shulin Huang, Zhen Lin, Jiahui Zhou, Zilan Mao, Zijie Yang, Linyi Yang, et al. How far are ai scientists from changing the world?arXiv preprint arXiv:2507.23276, 2025
-
[30]
A survey of ai scientists.arXiv preprint arXiv:2510.23045, 2025
Guiyao Tie, Pan Zhou, and Lichao Sun. A survey of ai scientists.arXiv preprint arXiv:2510.23045, 2025
-
[31]
Qiguang Chen, Mingda Yang, Libo Qin, Jinhao Liu, Zheng Yan, Jiannan Guan, Dengyun Peng, Yiyan Ji, Hanjing Li, Mengkang Hu, et al. Ai4research: A survey of artificial intelligence for scientific research.arXiv preprint arXiv:2507.01903, 2025
-
[32]
Routledge, 2005
Karl Popper.The logic of scientific discovery. Routledge, 2005
2005
-
[33]
University of Chicago press Chicago, 1970
Thomas S Kuhn and Ian Hacking.The structure of scientific revolutions, volume 2. University of Chicago press Chicago, 1970
1970
-
[34]
University of Chicago press, 1973
Robert K Merton.The sociology of science: Theoretical and empirical investigations. University of Chicago press, 1973
1973
-
[35]
Peer review of gpt-4 technical report and systems card.PLOS digital health, 3(1):e0000417, 2024
Jack Gallifant, Amelia Fiske, Yulia A Levites Strekalova, Juan S Osorio-Valencia, Rachael Parke, Rogers Mwavu, Nicole Martinez, Judy Wawira Gichoya, Marzyeh Ghassemi, Dina Demner-Fushman, et al. Peer review of gpt-4 technical report and systems card.PLOS digital health, 3(1):e0000417, 2024
2024
-
[36]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
2025
-
[37]
Openhands.https://github.com/All-Hands-AI/OpenHands, 2026
GitHub repository. Openhands.https://github.com/All-Hands-AI/OpenHands, 2026
2026
-
[38]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist.arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Ed Li, Junyu Ren, Xintian Pan, Cat Yan, Chuanhao Li, Dirk Bergemann, and Zhuoran Yang. Build your personalized research group: A multiagent framework for continual and interactive science automation.arXiv preprint arXiv:2510.15624, 2025
-
[40]
Evaluating sakana’s ai scientist: Bold claims, mixed results, and a promising future? InACM SIGIR Forum, volume 59, pages 1–20
Joeran Beel, Min-Yen Kan, and Moritz Baumgart. Evaluating sakana’s ai scientist: Bold claims, mixed results, and a promising future? InACM SIGIR Forum, volume 59, pages 1–20. ACM New York, NY , USA, 2025
2025
-
[41]
Can ai conduct autonomous scientific research? case studies on two real-world tasks.bioRxiv, pages 2026–01, 2026
Shreyansh Agrawal, Harsh B Anadkat, Kiran K Athimoolam, Harsh Bhardwaj, Trishul Chowdhury, Shengtao Gao, Purva K Kamat, Vishwadeepsinh Makwana, Mohammed H Shariff, Amitesh Badkul, et al. Can ai conduct autonomous scientific research? case studies on two real-world tasks.bioRxiv, pages 2026–01, 2026
2026
-
[42]
Ziming Luo, Atoosa Kasirzadeh, and Nihar B Shah. The more you automate, the less you see: Hidden pitfalls of ai scientist systems.arXiv preprint arXiv:2509.08713, 2025
-
[43]
Autonomous ‘self-driving’laboratories: a review of technology and policy implications.Royal Society Open Science, 12(7):250646, 2025
Alexander V Tobias and Adam Wahab. Autonomous ‘self-driving’laboratories: a review of technology and policy implications.Royal Society Open Science, 12(7):250646, 2025. 42 AUTORESEARCHAI
2025
-
[44]
Empowering biomedical discovery with ai agents.Cell, 187(22):6125–6151, 2024
Shanghua Gao, Ada Fang, Yepeng Huang, Valentina Giunchiglia, Ayush Noori, Jonathan Richard Schwarz, Yasha Ektefaie, Jovana Kondic, and Marinka Zitnik. Empowering biomedical discovery with ai agents.Cell, 187(22):6125–6151, 2024
2024
-
[45]
Ai-researcher: Autonomous scientific innovation
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. Ai-researcher: Autonomous scientific innovation. Advances in Neural Information Processing Systems, 38:9481–9520, 2026
2026
-
[46]
Perspective on utilizing foundation models for laboratory automation in materials research.Science and Technology of Advanced Materials: Methods, 5(1):2582379, 2025
Kan Hatakeyama-Sato, Toshihiko Nishida, Kenta Kitamura, Yoshitaka Ushiku, Koichi Takahashi, Yuta Nabae, and Teruaki Hayakawa. Perspective on utilizing foundation models for laboratory automation in materials research.Science and Technology of Advanced Materials: Methods, 5(1):2582379, 2025
2025
-
[47]
Shuxiang Cao, Zijian Zhang, Mohammed Alghadeer, Simone D Fasciati, Michele Piscitelli, Mustafa Bakr, Peter Leek, and Alán Aspuru-Guzik. Agents for self-driving laboratories applied to quantum computing.arXiv preprint arXiv:2412.07978, 2024
-
[48]
Hy- per: Literature-grounded hypothesis generation and distillation with provenance
Rosni Vasu, Chandrayee Basu, Bhavana Dalvi, Cristina Sarasua, Peter Clark, and Abraham Bernstein. Hy- per: Literature-grounded hypothesis generation and distillation with provenance. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25424–25449, 2025
2025
-
[49]
Bioplanner: automatic evaluation of llms on protocol planning in biology
Odhran O’Donoghue, Aleksandar Shtedritski, John Ginger, Ralph Abboud, Ali Ghareeb, and Samuel Ro- driques. Bioplanner: automatic evaluation of llms on protocol planning in biology. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2676–2694, 2023
2023
-
[50]
Researchagent: Iterative research idea generation over scientific literature with large language models
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pag...
2025
-
[51]
Omniscientist: Toward a co-evolving ecosystem of human and ai scientists
Chenyang Shao, Dehao Huang, Yu Li, Keyu Zhao, Weiquan Lin, Yining Zhang, Qingbin Zeng, Zhiyu Chen, Tianxing Li, Yifei Huang, et al. Omniscientist: Toward a co-evolving ecosystem of human and ai scientists. arXiv preprint arXiv:2511.16931, 2025
-
[52]
Codescientist: End-to-end semi-automated scien- tific discovery with code-based experimentation
Peter Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi, Bod- hisattwa Prasad Majumder, Daniel S Weld, and Peter Clark. Codescientist: End-to-end semi-automated scien- tific discovery with code-based experimentation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 13370–13467, 2025
2025
-
[53]
Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
Lianhao Zhou, Hongyi Ling, Cong Fu, Yepeng Huang, Michael Sun, Wendi Yu, Xiaoxuan Wang, Xiner Li, Xingyu Su, Junkai Zhang, et al. Autonomous agents for scientific discovery: Orchestrating scientists, language, code, and physics.arXiv preprint arXiv:2510.09901, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Tingting Chen, Srinivas Anumasa, Beibei Lin, Vedant Shah, Anirudh Goyal, and Dianbo Liu. Auto-bench: An automated benchmark for scientific discovery in llms.arXiv preprint arXiv:2502.15224, 2025
-
[55]
Zifeng Wang, Benjamin Danek, and Jimeng Sun. Biodsa-1k: Benchmarking data science agents for biomedical research.arXiv preprint arXiv:2505.16100, 2025
-
[56]
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Yujie Liu, Zonglin Yang, Tong Xie, Jinjie Ni, Ben Gao, Yuqiang Li, Shixiang Tang, Wanli Ouyang, Erik Cambria, and Dongzhan Zhou. Researchbench: Benchmarking llms in scientific discovery via inspiration- based task decomposition.arXiv preprint arXiv:2503.21248, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Tianze Xu, Pengrui Lu, Lyumanshan Ye, Xiangkun Hu, and Pengfei Liu. Researcherbench: Evaluating deep ai research systems on the frontiers of scientific inquiry.arXiv preprint arXiv:2507.16280, 2025
-
[58]
autoresearch.https://github.com/karpathy/autoresearch, 2026
GitHub repository. autoresearch.https://github.com/karpathy/autoresearch, 2026
2026
-
[59]
Deerflow.https://github.com/bytedance/deer-flow, 2026
GitHub repository. Deerflow.https://github.com/bytedance/deer-flow, 2026
2026
-
[60]
Open deep research.https://github.com/langchain-ai/open_deep_ research, 2026
GitHub repository. Open deep research.https://github.com/langchain-ai/open_deep_ research, 2026
2026
-
[61]
Automated scientific discov- ery: from equation discovery to autonomous discovery systems.Machine Learning, 115(5):109, 2026
Stefan Kramer, Mattia Cerrato, Jannis Brugger, Sašo Džeroski, and Ross D King. Automated scientific discov- ery: from equation discovery to autonomous discovery systems.Machine Learning, 115(5):109, 2026
2026
-
[62]
Boyuan Zheng, Zerui Fang, Zhe Xu, Rui Wang, Yiwen Chen, Cunshi Wang, Mengwei Qu, Lei Lei, Zhen Feng, Yan Liu, et al. Agent4s: The transformation of research paradigms from the perspective of large language models.arXiv preprint arXiv:2506.23692, 2025
-
[63]
Columbia university press, 1963
Derek J De Solla Price.Little science, big science. Columbia university press, 1963
1963
-
[64]
Functional genomic hypothesis generation and experimentation by a robot scientist.Nature, 427(6971):247–252, 2004
Ross D King, Kenneth E Whelan, Ffion M Jones, Philip GK Reiser, Christopher H Bryant, Stephen H Muggle- ton, Douglas B Kell, and Stephen G Oliver. Functional genomic hypothesis generation and experimentation by a robot scientist.Nature, 427(6971):247–252, 2004. 43 AUTORESEARCHAI
2004
-
[65]
Ai feynman: A physics-inspired method for symbolic regression
Silviu-Marian Udrescu and Max Tegmark. Ai feynman: A physics-inspired method for symbolic regression. Science advances, 6(16):eaay2631, 2020
2020
-
[66]
Storm.https://github.com/stanford-oval/storm, 2026
GitHub repository. Storm.https://github.com/stanford-oval/storm, 2026
2026
-
[67]
Xiaofeng Shi, Qian Kou, Yuduo Li, Ning Tang, Jinxin Xie, Longbin Yu, Songjing Wang, and Hua Zhou. Scis- age: A multi-agent framework for high-quality scientific survey generation.arXiv preprint arXiv:2506.12689, 2025
-
[68]
Deep research arena: The first exam of llms’ research abilities via seminar-grounded tasks
Haiyuan Wan, Chen Yang, Junchi Yu, Meiqi Tu, Jiaxuan Lu, Di Yu, Jianbao Cao, Ben Gao, Jiaqing Xie, Aoran Wang, et al. Deep research arena: The first exam of llms’ research abilities via seminar-grounded tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33341–33349, 2026
2026
-
[69]
Gpt researcher.https://github.com/assafelovic/gpt-researcher, 2026
GitHub repository. Gpt researcher.https://github.com/assafelovic/gpt-researcher, 2026
2026
-
[70]
Tongyi deepresearch.https://github.com/Alibaba-NLP/DeepResearch, 2026
GitHub repository. Tongyi deepresearch.https://github.com/Alibaba-NLP/DeepResearch, 2026
2026
-
[71]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
2023
-
[72]
An autonomous laboratory for the accelerated synthesis of inorganic materials.Nature, 624(7990):86, 2023
Nathan J Szymanski, Bernardus Rendy, Yuxing Fei, Rishi E Kumar, Tanjin He, David Milsted, Matthew J Mc- Dermott, Max Gallant, Ekin Dogus Cubuk, Amil Merchant, et al. An autonomous laboratory for the accelerated synthesis of inorganic materials.Nature, 624(7990):86, 2023
2023
-
[73]
Cy- cleresearcher: Improving automated research via automated review
Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. Cy- cleresearcher: Improving automated research via automated review. InInternational Conference on Learning Representations, volume 2025, pages 3669–3709, 2025
2025
-
[74]
Ruochen Li, Teerth Patel, Qingyun Wang, and Xinya Du. Mlr-copilot: Autonomous machine learning research based on large language models agents.arXiv preprint arXiv:2408.14033, 2024
-
[75]
R&d-agent: An llm-agent framework towards autonomous data science, 2025
Xu Yang, Xiao Yang, Shikai Fang, Yifei Zhang, Jian Wang, Bowen Xian, Qizheng Li, Jingyuan Li, Minrui Xu, Yuante Li, et al. R&d-agent: An llm-agent framework towards autonomous data science, 2025
2025
-
[76]
Zijun Liu, Kaiming Liu, Yiqi Zhu, Xuanyu Lei, Zonghan Yang, Zhenhe Zhang, Peng Li, and Yang Liu. Aigs: Generating science from ai-powered automated falsification.arXiv preprint arXiv:2411.11910, 2024
-
[77]
The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
Kyle Swanson, Wesley Wu, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
2025
-
[78]
Sciagents: automating scientific discovery through bioinspired multi-agent intelligent graph reasoning.Advanced Materials, 37(22):2413523, 2025
Alireza Ghafarollahi and Markus J Buehler. Sciagents: automating scientific discovery through bioinspired multi-agent intelligent graph reasoning.Advanced Materials, 37(22):2413523, 2025
2025
-
[79]
Sciscigpt: advancing human–ai collaboration in the science of science.Nature Computational Science, 6(3):301–315, 2026
Erzhuo Shao, Yifang Wang, Yifan Qian, Zhenyu Pan, Han Liu, and Dashun Wang. Sciscigpt: advancing human–ai collaboration in the science of science.Nature Computational Science, 6(3):301–315, 2026
2026
-
[80]
Szostkiewicz, Dmytro Shved, Gavin J
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J. Szostkiewicz, Dmytro Shved, Gavin J. Gyimesi, Jon M. Laurent, Samantha M. Wright, Muhammed T. Razzak, Andrew D. White, Silvia C. Finnemann, Michaela M. Hinks, and Samuel G. Rodriques. A multi-agent system for automating scientific discovery.Nature, May 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.