How Human-Like Are Large Language Models? A Register-Aware Linguistic Evaluation Framework
Pith reviewed 2026-05-25 04:18 UTC · model grok-4.3
The pith
Large language models always deviate from human linguistic patterns, but the closest model depends on the register rather than size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
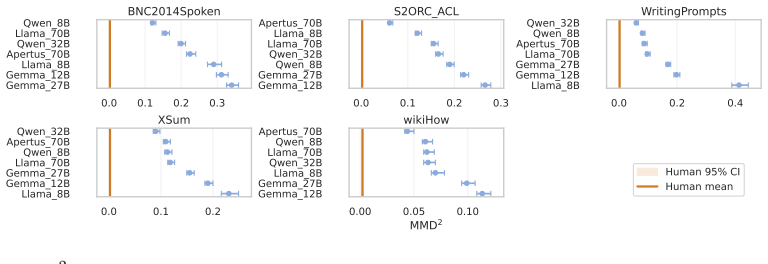
LLMs deviate from the human baseline in every tested setup when their texts are compared on lexico-grammatical feature distributions. The model that produces the distribution closest to human writing changes with the register, and this ordering is not dictated by model size.
What carries the argument
A two-sample Maximum Mean Discrepancy comparison between human and LLM corpora, performed separately for each register using the 67 Biber lexico-grammatical features.
If this is right
- Evaluation of LLM output must be performed register by register rather than with a single aggregate score.
- Larger models are not guaranteed to produce more human-like language distributions than smaller ones.
- Different communicative contexts expose different strengths among current open-source models.
- The framework supplies a quantitative basis for selecting models according to the intended register of use.
Where Pith is reading between the lines
- Fine-tuning on register-specific human data may close the observed gaps more effectively than further scaling.
- The same method could be applied to measure how well models handle register shifts within a single conversation.
- Training data that under-represents certain registers likely contributes to the systematic deviations found here.
Load-bearing premise
The 67 Biber features together with the MMD statistic capture the aspects of language production that determine whether a text feels human-like in a given register.
What would settle it
An experiment that finds one model size ranking first across every register would show that closeness is dictated by size after all.
Figures


























read the original abstract
While factual correctness and task-performance have been in focus of Large Language Model (LLM) research for a long time, the fundamental question of how human-like generated texts are on a linguistic level has been underexplored. From a corpus-linguistic perspective, language production is inherently context-dependent, with distinct communicative contexts giving rise to differences in frequencies and co-occurrence patterns of linguistic features. A text failing to adhere to these patterns can be content-wise correct, but still be unfavorable to human readers. In this work, we propose a context-aware evaluation framework in which human-likeness is assessed using a two-sample problem between the linguistic feature distribution of a human reference corpus for a given register and a corresponding LLM-generated corpus. We implement this framework using the Maximum Mean Discrepancy (MMD) and the 67 lexico-grammatical features introduced by Biber, which are commonly applied in corpus linguistics. In our experiments, we compare seven instruction-tuned, open-source models across five English-language datasets spanning distinct registers against a human baseline. While across all tested setups, LLMs deviate from the human baseline, which models are closest to human language depends on the register and is not dictated by model size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a context-aware evaluation framework for assessing the human-likeness of LLM-generated texts using Maximum Mean Discrepancy (MMD) to compare distributions of 67 Biber lexico-grammatical features between human reference corpora and LLM outputs across five distinct English registers. Experiments with seven instruction-tuned open-source LLMs reveal that all models deviate from human baselines, but the model closest to the human distribution varies depending on the register and is not solely determined by model size.
Significance. If the framework's assumptions hold, this work offers a valuable corpus-linguistic approach to LLM evaluation that accounts for register-specific linguistic patterns, moving beyond task performance metrics. The reliance on established Biber features and MMD contributes to the method's transparency and potential for replication in the field.
major comments (1)
- [Abstract] The central claim that 'which models are closest to human language depends on the register and is not dictated by model size' is load-bearing on the 67 Biber features plus two-sample MMD being a sufficient statistic for human-likeness (Abstract). The manuscript provides no evidence that these distances align with human judgments of naturalness or discourse-level properties in the tested registers, nor any ablation against expanded feature sets; if the ordering differs from such external validation, the register-dependence conclusion does not follow from the reported MMD values.
minor comments (1)
- [Abstract] The abstract states the main finding but does not name the five registers or seven models; adding these would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim that 'which models are closest to human language depends on the register and is not dictated by model size' is load-bearing on the 67 Biber features plus two-sample MMD being a sufficient statistic for human-likeness (Abstract). The manuscript provides no evidence that these distances align with human judgments of naturalness or discourse-level properties in the tested registers, nor any ablation against expanded feature sets; if the ordering differs from such external validation, the register-dependence conclusion does not follow from the reported MMD values.
Authors: We acknowledge the referee's point that the manuscript does not provide direct evidence linking MMD distances on the Biber feature set to human judgments of naturalness. The 67 features are selected because they are a well-established, replicable set in corpus linguistics for modeling register variation (Biber 1988 and subsequent validation studies). MMD serves as a distribution-level comparator rather than a claim of sufficiency for all aspects of human-likeness. The reported finding is therefore scoped to relative distances within this operationalization: across the five registers, the model minimizing MMD changes and is not monotonically related to parameter count. We agree that external validation would strengthen interpretation. In revision we will (1) temper the abstract wording to emphasize that conclusions concern this specific feature set and metric, (2) add citations to existing literature on the predictive validity of Biber features for perceived register appropriateness, and (3) expand the limitations section to note the absence of human judgment correlation or feature-set ablations as directions for future work. No new experiments are added at this stage. revision: partial
Circularity Check
No circularity; direct empirical comparison to external human corpora
full rationale
The paper defines human-likeness via two-sample MMD distances on the fixed, externally established set of 67 Biber lexico-grammatical features between LLM-generated texts and independent human reference corpora for each register. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear; the reported register-dependent ordering of models follows immediately from these distance computations without any reduction of outputs to inputs by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Biber's 67 lexico-grammatical features capture the relevant frequency and co-occurrence patterns that distinguish registers in human language production.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.