From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
Pith reviewed 2026-05-25 04:22 UTC · model grok-4.3
The pith
Causal validation with counterfactual stimuli is required to identify true visual representations in the brain, since activation alone yields many false positives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
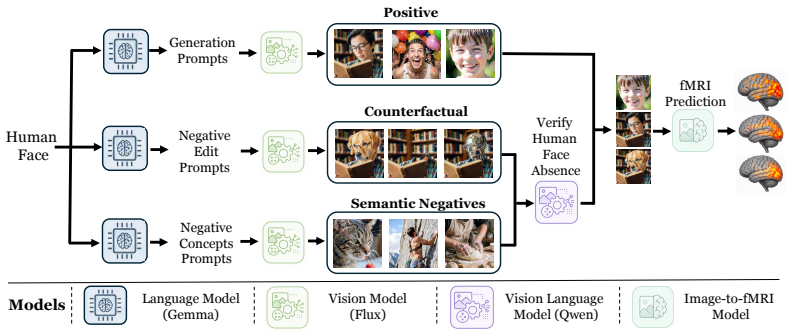
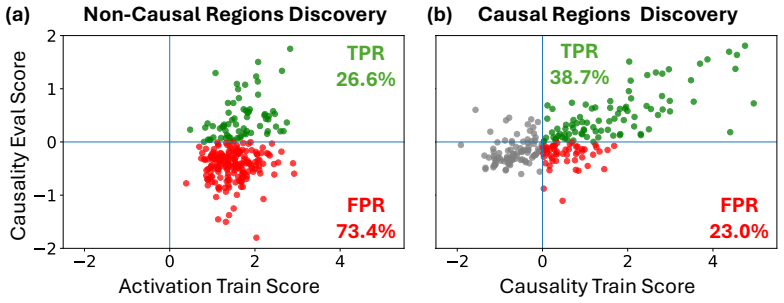
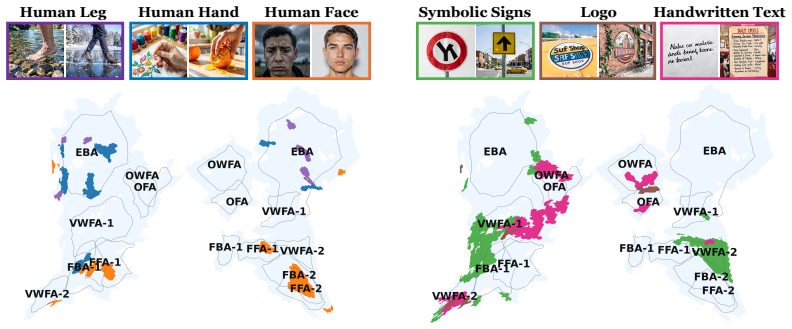
BrainCause automates construction of targeted stimulus sets comprising concept images, counterfactual edits that remove the target concept while preserving other image content, and images with candidate correlated distractors; it then uses an image-to-fMRI encoding model to predict brain responses and identify representations that respond specifically to the target concept over correlated alternatives, recovering known localizations while showing that without this causal step a large fraction of activation-based findings would be false positives.
What carries the argument
BrainCause framework that synthesizes controlled stimuli with counterfactual edits and applies an image-to-fMRI encoding model to perform causal testing of neural representations.
If this is right
- Known functional localizations such as face and place areas are recovered and confirmed through the causal procedure.
- New candidate representations are proposed for dozens of visual concepts.
- A large fraction of localizations identified by activation maximization alone are shown to be false positives.
- The framework generates specific follow-up fMRI experiments to further test or extend the validated candidates.
Where Pith is reading between the lines
- If the encoding model holds for the counterfactual stimuli, the method could be used to screen many candidate concepts before committing scanner time to new experiments.
- Applying similar counterfactual editing to existing large fMRI datasets might allow re-analysis of prior activation maps for causal validity.
- The same stimulus-construction logic could be extended to test representations of more abstract or relational visual properties beyond object categories.
Load-bearing premise
The image-to-fMRI encoding model accurately predicts brain responses to counterfactual stimuli that differ from the training distribution in targeted ways.
What would settle it
Recording actual fMRI responses to the generated counterfactual stimuli and finding that they fail to match the encoding model's predictions for the candidate regions would falsify the claim that those regions represent the target concept.
Figures



read the original abstract
Identifying which brain regions represent a visual concept in the human brain is a central challenge in neuroscience. Existing approaches have localized coarse functional regions (e.g., faces, places) through activation maximization, identifying regions that activate strongly for a target concept relative to other concepts. Yet strong activation alone does not establish that a region represents the concept itself, as responses may instead be driven by correlated visual or semantic cues. We introduce BrainCause, an automated framework that combines generative and brain models to synthesize controlled stimuli and validate neural representations through targeted causal testing. Given a query specifying a concept of interest, our framework constructs targeted stimulus sets comprising concept images, counterfactual edits that remove the target concept while preserving other image content, and images with candidate correlated distractors. It then uses an image-to-fMRI encoding model to predict brain responses and searches for representations that respond specifically to the target concept over correlated alternatives. BrainCause returns validated candidate representations and proposes follow-up fMRI experiments to further test or extend its discoveries. Our approach successfully recovers known functional localizations and identifies new candidate representations across dozens of concepts, validated on both predicted and measured fMRI data. Critically, we show that without causal validation, a large fraction of localizations would be false positives, confirming that activation alone is insufficient evidence of representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BrainCause, a framework combining generative models to synthesize concept images, counterfactual edits that remove a target visual concept while preserving other content, and distractor images, with an image-to-fMRI encoding model to test for causal specificity of brain responses. It claims to recover known functional localizations, identify new candidate representations across dozens of concepts on both predicted and measured fMRI data, and demonstrate that activation-based localization produces a large fraction of false positives, confirming activation alone is insufficient for establishing representation.
Significance. If the encoding model's predictions remain accurate on the generative counterfactual edits, the work could provide a scalable, automated method for causal discovery of visual representations in neuroscience, moving the field beyond correlational activation maps toward more rigorous validation and targeted follow-up experiments.
major comments (2)
- [Abstract] Abstract: the claim that 'without causal validation, a large fraction of localizations would be false positives' is load-bearing for the central thesis but supplies no quantitative fraction, exact validation metrics, or criteria for classifying a localization as a false positive (e.g., differential response thresholds between concept and edit conditions).
- [Abstract] Abstract (validation step and stimulus construction paragraph): the image-to-fMRI encoding model's accuracy on out-of-distribution generative counterfactual edits is not quantified (no held-out correlation, error metrics, or OOD generalization results reported), yet this generalization is required for the causal specificity tests to be reliable; systematic misprediction on edited stimuli would collapse the activation-versus-causality distinction.
minor comments (1)
- [Abstract] Abstract: the description of how the framework 'searches for representations that respond specifically to the target concept over correlated alternatives' would benefit from explicit mention of the statistical test or similarity metric employed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional quantitative details will strengthen the presentation and will revise the abstract accordingly. Responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'without causal validation, a large fraction of localizations would be false positives' is load-bearing for the central thesis but supplies no quantitative fraction, exact validation metrics, or criteria for classifying a localization as a false positive (e.g., differential response thresholds between concept and edit conditions).
Authors: The results section of the manuscript reports the quantitative fraction of activation-based localizations that fail causal validation, along with the exact metrics and the statistical criterion used to classify false positives (regions showing no significant differential response between concept and counterfactual-edit conditions). We will revise the abstract to include these specific values and a concise statement of the classification criterion. revision: yes
-
Referee: [Abstract] Abstract (validation step and stimulus construction paragraph): the image-to-fMRI encoding model's accuracy on out-of-distribution generative counterfactual edits is not quantified (no held-out correlation, error metrics, or OOD generalization results reported), yet this generalization is required for the causal specificity tests to be reliable; systematic misprediction on edited stimuli would collapse the activation-versus-causality distinction.
Authors: The manuscript validates the encoding model on held-out data that includes the generative counterfactual edits and reports the relevant correlation and error metrics in the methods and results sections. We will revise the abstract to explicitly state these OOD generalization numbers so that the reliability of the causal tests is clear from the abstract alone. revision: yes
Circularity Check
No circularity; causal claims rest on measured fMRI validation, not model fit alone
full rationale
The derivation fits an image-to-fMRI encoding model on (presumably natural-image) data and uses its predictions to screen for concept-specific responses versus counterfactual edits and distractors. However, the paper states that candidate representations are 'validated on both predicted and measured fMRI data,' supplying an external benchmark that is independent of the fitted parameters. No equations, self-citations, or self-definitional steps are shown that would make the causal-versus-activation distinction reduce to the training fit by construction. The central claim therefore remains self-contained against the measured data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martin I. Sereno, Anders M. Dale, John B. Reppas, Kai K. Kwong, John W. Belliveau, Thomas J. Brady, Bruce R. Rosen, and Roger B. H. Tootell. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging.Science, 268(5212):889–893, 1995. doi: 10.1126/science.7754376
-
[2]
Stephen A. Engel, Gary H. Glover, and Brian A. Wandell. Retinotopic organization in human visual cortex and the spatial precision of functional mri.Cerebral Cortex, 7(2):181–192, 1997. doi: 10.1093/cercor/7.2.181
-
[3]
Nancy Kanwisher, Josh McDermott, and Marvin M Chun. The fusiform face area: A module in human extrastriate cortex specialized for face perception.Journal of Neuroscience, 1997
work page 1997
-
[4]
A cortical representation of the local visual environment
Russell Epstein and Nancy Kanwisher. A cortical representation of the local visual environment. Nature, 1998
work page 1998
-
[5]
A cortical area selective for visual processing of the human body.Science, 293(5539):2470–2473, 2001
Paul E Downing, Yuhong Jiang, Miles Shuman, and Nancy Kanwisher. A cortical area selective for visual processing of the human body.Science, 293(5539):2470–2473, 2001
work page 2001
-
[6]
Laurent Cohen, Stanislas Dehaene, Lionel Naccache, Stéphane Lehéricy, Ghislaine Dehaene- Lambertz, Marie-Anne Hénaff, and François Michel. The visual word form area: spatial and temporal characterization of an initial stage of reading in normal subjects and posterior split-brain patients.Brain, 123(2):291–307, 2000
work page 2000
-
[7]
Guangyin Bao, Qi Zhang, Zixuan Gong, Zhuojia Wu, and Duoqian Miao. Mindsimulator: Exploring brain concept localization via synthetic fmri.arXiv preprint arXiv:2503.02351, 2025
-
[8]
Ethan Hwang, Hossein Adeli, Wenxuan Guo, Andrew Luo, and Nikolaus Kriegeskorte. In silico mapping of visual categorical selectivity across the whole brain.arXiv preprint arXiv:2510.21142, 2025
-
[9]
Andrew F Luo, Jacob Yeung, Rushikesh Zawar, Shaurya Dewan, Margaret M Henderson, Leila Wehbe, and Michael J Tarr. Brain mapping with dense features: Grounding cortical semantic selectivity in natural images with vision transformers.arXiv preprint arXiv:2410.05266, 2024
-
[10]
Allen, Yihan Wu, Ghislain St-Yves, Thomas Naselaris, Kendrick Kay, Mert R
Zijin Gu, Keith Wakefield Jamison, Meenakshi Khosla, Emily J. Allen, Yihan Wu, Ghislain St-Yves, Thomas Naselaris, Kendrick Kay, Mert R. Sabuncu, and Amy Kuceyeski. Neurogen: Activation optimized image synthesis for discovery neuroscience.NeuroImage, 247:118812,
-
[11]
doi: https://doi.org/10.1016/j.neuroimage.2021.118812
ISSN 1053-8119. doi: https://doi.org/10.1016/j.neuroimage.2021.118812. URL https: //www.sciencedirect.com/science/article/pii/S1053811921010831
-
[12]
Leonard E van Dyck, Martin N Hebart, and Katharina Dobs. Multidimensional feature tuning in category-selective areas of human visual cortex.bioRxiv, pages 2025–06, 2025
work page 2025
-
[13]
Navve Wasserman, Matias Cosarinsky, Yuval Golbari, Aude Oliva, Antonio Torralba, Tamar Rott Shaham, and Michal Irani. Brainexplore: Large-scale discovery of interpretable visual represen- tations in the human brain.arXiv preprint arXiv:2512.08560, 2025
-
[14]
E. A. DeYoe, G. J. Carman, P. Bandettini, S. Glickman, J. Wieser, R. Cox, D. Miller, and J. Neitz. Mapping striate and extrastriate visual areas in human cerebral cortex.Proceedings of the National Academy of Sciences, 93(6):2382–2386, 1996. doi: 10.1073/pnas.93.6.2382
-
[15]
Yukiyasu Kamitani and Frank Tong. Decoding the visual and subjective contents of the human brain.Nature Neuroscience, 8(5):679–685, 2005. doi: 10.1038/nn1444. 10
-
[16]
Spatial frequency tuning in human retinotopic visual areas.Journal of Vision, 8(10):5:1–13, 2008
Linda Henriksson, Lauri Nurminen, Aapo Hyvärinen, and Simo Vanni. Spatial frequency tuning in human retinotopic visual areas.Journal of Vision, 8(10):5:1–13, 2008. doi: 10.1167/8.10.5
-
[17]
Conway, Sebastian Moeller, and Doris Y
Bevil R. Conway, Sebastian Moeller, and Doris Y . Tsao. Specialized color modules in macaque extrastriate cortex.Neuron, 56(3):560–573, 2007. doi: 10.1016/j.neuron.2007.10.008
-
[18]
Roger B. H. Tootell, John B. Reppas, Anders M. Dale, Rodney B. Look, Martin I. Sereno, Rafael Malach, Thomas J. Brady, and Bruce R. Rosen. Visual motion aftereffect in human cortical area mt revealed by functional magnetic resonance imaging.Nature, 375(6527):139–141, 1995. doi: 10.1038/375139a0
-
[19]
Nancy Kanwisher and Galit Yovel. The fusiform face area: a cortical region specialized for the perception of faces.Philosophical Transactions of the Royal Society B: Biological Sciences, 361(1476):2109–2128, 2006
work page 2006
-
[20]
Scene perception in the human brain.Annual review of vision science, 5(1):373–397, 2019
Russell A Epstein and Chris I Baker. Scene perception in the human brain.Annual review of vision science, 5(1):373–397, 2019
work page 2019
-
[21]
Functional brain-to-brain transformation without shared stimuli.NeuroImage, 327:121741, 2026
Navve Wasserman, Roman Beliy, Roy Urbach, and Michal Irani. Functional brain-to-brain transformation without shared stimuli.NeuroImage, 327:121741, 2026
work page 2026
-
[22]
Inter-subject neural code converter for visual image representation.NeuroImage, 113:289–297, 2015
Kentaro Yamada, Yoichi Miyawaki, and Yukiyasu Kamitani. Inter-subject neural code converter for visual image representation.NeuroImage, 113:289–297, 2015
work page 2015
-
[23]
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, and Tanishq Mathew Abraham. Mindeye2: Shared-subject models enable fmri-to-image with 1 hour of data.arXiv preprint arXiv:2403.11207, 2024
-
[24]
Roman Beliy, Amit Zalcher, Jonathan Kogman, Navve Wasserman, and Michal Irani. Brain-it: Image reconstruction from fmri via brain-interaction transformer.arXiv preprint arXiv:2510.25976, 2025
-
[25]
N Apurva Ratan Murty, Pouya Bashivan, Alex Abate, James J DiCarlo, and Nancy Kanwisher. Computational models of category-selective brain regions enable high-throughput tests of selectivity.Nature communications, 12(1):5540, 2021
work page 2021
-
[26]
Kendrick N. Kay, Thomas Naselaris, Ryan J. Prenger, and Jack L. Gallant. Identifying natural im- ages from human brain activity.Nature, 452(7185):352–355, 2008. doi: 10.1038/nature06713
-
[27]
Kay, Shinji Nishimoto, and Jack L
Thomas Naselaris, Kendrick N. Kay, Shinji Nishimoto, and Jack L. Gallant. Encoding and decoding in fmri.NeuroImage, 56(2):400–410, 2011. ISSN 1053-8119. doi: https://doi.org/ 10.1016/j.neuroimage.2010.07.073. URL https://www.sciencedirect.com/science/ article/pii/S1053811910010657. Multivariate Decoding and Brain Reading
-
[28]
The wisdom of a crowd of brains: A universal brain encoder.arXiv preprint arXiv:2406.12179, 2024
Roman Beliy, Navve Wasserman, Amit Zalcher, and Michal Irani. The wisdom of a crowd of brains: A universal brain encoder.arXiv preprint arXiv:2406.12179, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Hossein Adeli, Sun Minni, and Nikolaus Kriegeskorte. Transformer brain encoders explain human high-level visual responses.arXiv preprint arXiv:2505.17329, 2025
-
[30]
Brain diffusion for vi- sual exploration: Cortical discovery using large scale generative models
Andrew Luo, Maggie Henderson, Leila Wehbe, and Michael Tarr. Brain diffusion for vi- sual exploration: Cortical discovery using large scale generative models. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 75740–75781. Curran Associates, Inc., 2023. UR...
work page 2023
-
[31]
Natalia Z Bielczyk, Sebo Uithol, Tim van Mourik, Paul Anderson, Jeffrey C Glennon, and Jan K Buitelaar. Disentangling causal webs in the brain using functional magnetic resonance imaging: A review of current approaches.Network Neuroscience, 3(2):237–273, 2019
work page 2019
-
[32]
Causal mapping of human brain function.Nature reviews neuroscience, 23(6):361–375, 2022
Shan H Siddiqi, Konrad P Kording, Josef Parvizi, and Michael D Fox. Causal mapping of human brain function.Nature reviews neuroscience, 23(6):361–375, 2022. 11
work page 2022
-
[33]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[34]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
work page 2023
-
[35]
Paint by inpaint: Learning to add image objects by removing them first
Navve Wasserman, Noam Rotstein, Roy Ganz, and Ron Kimmel. Paint by inpaint: Learning to add image objects by removing them first. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18313–18324, 2025
work page 2025
-
[36]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Emre Kiciman, Robert Ness, Amit Sharma, and Chenhao Tan. Causal reasoning and large language models: Opening a new frontier for causality.Transactions on Machine Learning Research, 2023
work page 2023
-
[38]
A survey on hypothesis generation for scientific discovery in the era of large language models
Atilla Kaan Alkan, Shashwat Sourav, Maja Jablonska, Simone Astarita, Rishabh Chakrabarty, Nikhil Garuda, Pranav Khetarpal, Maciej Pióro, Dimitrios Tanoglidis, Kartheik G Iyer, et al. A survey on hypothesis generation for scientific discovery in the era of large language models. arXiv preprint arXiv:2504.05496, 2025
-
[39]
Hypothesis generation with large language models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, and Chenhao Tan. Hypothesis generation with large language models. InProceedings of the 1st Workshop on NLP for Science (NLP4Science), pages 117–139, 2024
work page 2024
-
[40]
GPT-5 System Card.https://cdn.openai.com/gpt-5-system-card.pdf , 2025
OpenAI. GPT-5 System Card.https://cdn.openai.com/gpt-5-system-card.pdf , 2025. Accessed: 2026-05-06
work page 2025
-
[41]
Gemma Team and Google DeepMind. Gemma 3.arXiv preprint arXiv:2503.19786, 2025. URL https://arxiv.org
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
work page 2025
-
[43]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[45]
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022. 12 Appendix A Ablation & Analysis A.1 Consistency Across Subjects While...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.