PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
Pith reviewed 2026-05-25 04:16 UTC · model grok-4.3
The pith
PiD reformulates latent decoding as conditional pixel diffusion to synthesize high-resolution images directly from compact latents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PiD is a pixel diffusion decoder that unifies latent decoding and upsampling by denoising directly in high-resolution pixel space; a sigma-aware adapter injects noise-corrupted latents into the diffusion backbone so that partially denoised latents can be decoded and the latent diffusion process terminated early, with further distillation to four inference steps, yielding 2048x2048 outputs from 512x512 latents in under one second on an RTX 5090 while supporting both VAE and semantic latents.
What carries the argument
The sigma-aware adapter that injects noise-corrupted latents into the pixel diffusion backbone to enable conditional generation and early termination of latent diffusion.
If this is right
- Decoding and upsampling become a single generative module instead of sequential reconstruction and super-resolution stages.
- Latent diffusion pipelines can stop at intermediate denoising steps without major quality degradation.
- The distilled four-step model runs at 210 ms on a GB200 GPU while using 13 GB peak memory on an RTX 5090.
- The same architecture works for both conventional VAE latents and semantic latents such as SigLIP or DINOv2.
- Inference is approximately six times faster than cascaded diffusion-based super-resolution pipelines at equal or higher visual fidelity.
Where Pith is reading between the lines
- The approach could support interactive high-resolution editing tools where latency must stay below one second.
- Similar conditioning adapters might accelerate other latent-based generative tasks such as video or 3D synthesis.
- Further reduction in step count or memory footprint could make megapixel generation feasible on edge devices.
- The unification of decoding and upsampling raises the question of whether end-to-end training from text to pixels can bypass separate latent stages altogether.
Load-bearing premise
The lightweight sigma-aware adapter can successfully inject noise-corrupted latents into the pixel diffusion backbone so that the model can decode partially denoised latents and terminate the latent diffusion process early without major quality loss.
What would settle it
A controlled comparison in which early termination of latent diffusion with the adapter produces visibly lower fidelity or more artifacts than full latent diffusion plus a standard decoder would falsify the efficiency-without-quality-loss claim.
Figures










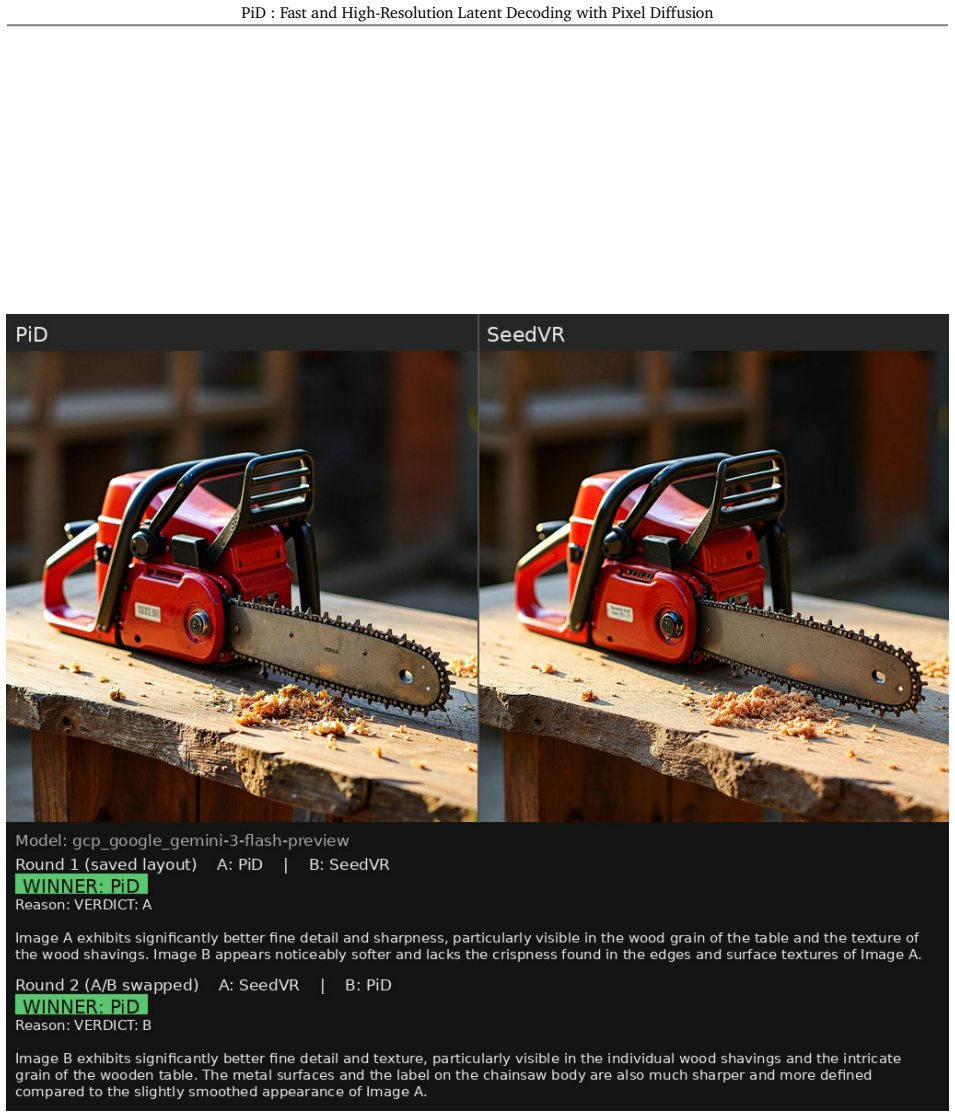
read the original abstract
Most practical high-resolution text-to-image systems, including latent diffusion and autoregressive models, perform generation in a compact latent space, and a decoder maps the generated latents back to pixels. Yet the latent-to-pixel decoder is reconstruction-oriented, optimized to invert the encoder rather than synthesize more details, and becomes increasingly costly at megapixel scale. This drawback calls for a more expressive and efficient decoding paradigm. Motivated by recent progress in scalable pixel-space diffusion, we introduce PiD, a Pixel diffusion Decoder that reformulates latent decoding as conditional pixel diffusion, unifying decoding and upsampling into one generative module. By denoising directly in high-resolution pixel space, PiD synthesizes $4\times$ and even $8\times$ upscaled images with low latency. For latent conditioning, a lightweight sigma-aware adapter injects noise-corrupted latents into the pixel diffusion backbone, enabling PiD to decode partially denoised latents and terminate the latent diffusion process early. To further improve efficiency, we distill the model using DMD2, reducing inference to just 4 steps. PiD applies to both conventional VAE latents and semantic latents (e.g., SigLIP, DINOv2) used in recent RAE-based models. PiD decodes latents of $512 \times 512$ images into $2048 \times 2048$ pixels in under 1 second with 13 GB peak memory on a consumer RTX 5090, and as fast as 210 ms on a GB200 GPU, about $6\times$ faster than cascaded diffusion-based super-resolution pipelines with better visual fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PiD, a Pixel diffusion Decoder that reformulates latent decoding as conditional pixel diffusion to unify decoding and upsampling. It uses a lightweight sigma-aware adapter to inject noise-corrupted latents into a pixel diffusion backbone, enabling early termination of latent diffusion, and applies DMD2 distillation to reduce inference to 4 steps. The method is claimed to apply to both VAE and semantic latents, delivering 2048x2048 outputs from 512x512 latents in under 1s (13GB on RTX 5090) or 210ms on GB200, with 6x speedup and better fidelity versus cascaded diffusion super-resolution.
Significance. If the reported speed, memory, and quality advantages hold under rigorous evaluation, PiD could meaningfully simplify high-resolution latent generative pipelines by replacing separate reconstruction decoders and cascaded upsamplers with a single generative module. The unification of decoding with pixel-space diffusion and support for semantic latents are potentially impactful for both conventional LDMs and recent RAE-style models.
major comments (2)
- [Abstract] Abstract: performance claims (under-1s decoding, 6x speedup, better visual fidelity) are stated without any reference to experimental protocol, datasets, baselines, ablations, or quantitative metrics (e.g., FID, LPIPS, user studies). This absence prevents verification of the central efficiency and quality assertions.
- [Abstract] Abstract: the effectiveness of the sigma-aware adapter for injecting partially denoised latents and safely terminating latent diffusion early is presented as a core enabling mechanism, yet no supporting derivation, training objective, or ablation is referenced, leaving the weakest assumption unexamined.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments on the abstract below. The full manuscript contains the requested experimental details, but we agree the abstract can be strengthened for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance claims (under-1s decoding, 6x speedup, better visual fidelity) are stated without any reference to experimental protocol, datasets, baselines, ablations, or quantitative metrics (e.g., FID, LPIPS, user studies). This absence prevents verification of the central efficiency and quality assertions.
Authors: The abstract is a concise summary and therefore omits explicit citations to the evaluation protocol. The manuscript reports these details in the Experiments section, including datasets (ImageNet, COCO, LAION subsets), baselines (cascaded diffusion SR pipelines), quantitative metrics (FID, LPIPS), user studies, and ablations. We will revise the abstract to add a short clause referencing the evaluation protocol and key metrics used to support the claims. revision: partial
-
Referee: [Abstract] Abstract: the effectiveness of the sigma-aware adapter for injecting partially denoised latents and safely terminating latent diffusion early is presented as a core enabling mechanism, yet no supporting derivation, training objective, or ablation is referenced, leaving the weakest assumption unexamined.
Authors: The abstract highlights the adapter's role at a high level. The manuscript provides the adapter architecture, sigma-aware conditioning derivation, training objective, and dedicated ablations in Sections 3 and 4. We will revise the abstract to include a brief reference to these supporting analyses in the body of the paper. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and description present PiD as a new construction that reformulates latent decoding as conditional pixel diffusion, motivated by external pixel-space diffusion progress. No equations, fitted parameters, or predictions are shown that reduce to the authors' own prior results by definition. The sigma-aware adapter, DMD2 distillation, and early termination are described as engineering choices without self-definitional or self-citation load-bearing reductions. The reader's assessment of score 1.0 is consistent with an independent construction; absent any quoted derivation chain that collapses to inputs, the default non-circular finding applies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arora, Z
A. Arora, Z. Tu, Y. Wang, R. Bai, J. Wang, and S. Ma. Guidesr: Rethinking guidance for one-step high-fidelity diffusion-based super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3914–3922, 2025. 5
2025
-
[2]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang, Q....
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Betker, G
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo, et al. Improving image generation with better captions.Computer Science, 2(3):8, 2023. 4
2023
-
[4]
T. Bi, X. Zhang, Y. Lu, and N. Zheng. Vision foundation models can be good tokenizers for latent diffusion models. arXiv preprint arXiv:2510.18457, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Ntk-aware scaled rope.https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_ rope_allows_llama_models_to_have/
bloc97. Ntk-aware scaled rope.https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_ rope_allows_llama_models_to_have/. 6
-
[6]
H. Cai, S. Cao, R. Du, P. Gao, S. Hoi, Z. Hou, S. Huang, D. Jiang, X. Jin, L. Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
- [8]
-
[9]
J. Chen, C. Ge, E. Xie, Y. Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li. PixArt-Σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. InEuropean Conference on Computer Vision (ECCV), 2024. 5
2024
-
[10]
L. Dong, Q. Fan, Y. Guo, Z. Wang, Q. Zhang, J. Chen, Y. Luo, and C. Zou. Tsd-sr: One-step diffusion with target score distillation for real-world image super-resolution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23174–23184, 2025. 5, 9, 10
2025
-
[11]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024. 5, 9
2024
- [12]
-
[13]
J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33, 2022. 5
2022
-
[14]
X. Hu, R. Wang, Y. Fang, B. Fu, P. Cheng, and G. Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Jeong, S
J. Jeong, S. Han, J. Kim, and S. J. Kim. Latent space super-resolution for higher-resolution image generation with diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2355–2365, 2025. 5
2025
-
[16]
Kawai, T
K. Kawai, T. Oba, K. Tokoro, K. Akita, and N. Ukita. Efficient burst super-resolution with one-step diffusion. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 864–873, 2025. 5
2025
-
[17]
J. Ke, Q. Wang, Y. Wang, P. Milanfar, and F. Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021. 9 19 PiD : Fast and High-Resolution Latent Decoding with Pixel Diffusion
2021
-
[18]
D. P. Kingma and M. Welling. Auto-encoding variational Bayes. InInternational Conference on Learning Representations (ICLR), 2014. 3, 4
2014
-
[19]
B. F. Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 9
2024
-
[20]
B. F. Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025. 9
2025
-
[21]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
T. Li, Y. Tian, H. Li, M. Deng, and K. He. Autoregressive image generation without vector quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3, 4
2024
-
[23]
X. Lin, J. He, Z. Chen, Z. Lyu, B. Dai, F. Yu, Y. Qiao, W. Ouyang, and C. Dong. DiffBIR: Toward blind image restoration with generative diffusion prior. InEuropean Conference on Computer Vision, pages 430–448. Springer, 2024. 5
2024
-
[24]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
completely blind
A. Mittal, R. Soundararajan, and A. C. Bovik. Making a “completely blind” image quality analyzer.IEEE Signal processing letters, 20(3):209–212, 2012. 9
2012
-
[27]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El- Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y. Huang, S.-W. Li, I. Misra, M. Rabbat, V. Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without super...
2024
- [28]
-
[29]
Stochasticbackpropagationandapproximateinferenceindeepgenerative models
D.J.Rezende, S.Mohamed, andD.Wierstra. Stochasticbackpropagationandapproximateinferenceindeepgenerative models. InInternational Conference on Machine Learning (ICML), 2014. 3, 4
2014
-
[30]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695,
-
[31]
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi. Image super-resolution via iterative refinement. arXiv preprint arXiv:2104.07636, 2021. 5
-
[32]
J. Shi, C. Wu, J. Liang, X. Liu, and N. Duan. DiVAE: Photorealistic images synthesis with denoising diffusion decoder,
-
[33]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024. 6
2024
-
[34]
P. Sun, Y. Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Y. Sun, L. Sun, S. Liu, R. Wu, Z. Zhang, and L. Zhang. One-step diffusion for detail-rich and temporally consistent video super-resolution. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 5
2025
-
[36]
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
K. Tian, Y. Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3, 4 20 PiD : Fast and High-Resolution Latent Decoding with Pixel Diffusion
2024
-
[38]
S. Tong, B. Zheng, Z. Wang, B. Tang, N. Ma, E. Brown, J. Yang, R. Fergus, Y. LeCun, and S. Xie. Scaling text-to-image diffusion transformers with representation autoencoders, 2026. 4, 9
2026
-
[39]
T. Vallaeys, J. Verbeek, and M. Cord. SSDD: Single-step diffusion decoder for efficient image tokenization.arXiv preprint arXiv:2510.04961, 2025. 3, 4, 9
-
[40]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017. 4
2017
- [41]
-
[42]
J. Wang, Z. Yue, S. Zhou, K. C. K. Chan, and C. C. Loy. Exploiting diffusion prior for real-world image super-resolution,
-
[43]
X. Wang, L. Xie, C. Dong, and Y. Shan. Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data. InIEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021. 5, 9, 10
2021
-
[44]
X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, C. C. Loy, X. Tang, and Y. Qiao. ESRGAN: Enhanced super-resolution generative adversarial networks. InEuropean Conference on Computer Vision Workshops (ECCVW), 2018. 5
2018
-
[45]
H. Wu, Z. Zhang, W. Zhang, C. Chen, C. Li, L. Liao, A. Wang, E. Zhang, W. Sun, Q. Yan, X. Min, G. Zhai, and W. Lin. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. Equal Contribution by Wu, Haoning and Zhang, Zicheng. Project Lead by Wu, Haoning. Corresponding Authors: Zhai, Guangtai and Li...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
R. Wu, T. Yang, L. Sun, Z. Zhang, S. Li, and L. Zhang. SeeSR: Towards semantics-aware real-world image super- resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25456–25467, 2024. 5
2024
- [47]
-
[48]
X. Wu, J. Xin, J. Hao, H. Gao, J. Li, N. Wang, and X. Gao. One-step diffusion-based real-world image super-resolution with visual perception distillation.Neurocomputing, page 133066, 2026. 5
2026
-
[49]
E. Xie, J. Chen, J. Chen, H. Cai, H. Tang, Y. Lin, Z. Zhang, M. Li, L. Zhu, Y. Lu, and S. Han. SANA: Efficient high-resolution image synthesis with linear diffusion transformer, 2024. 5
2024
-
[50]
S. Yang, T. Wu, S. Shi, S. Lao, Y. Gong, M. Cao, J. Wang, and Y. Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 9
2022
- [51]
-
[52]
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and W. T. Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024. 4, 7, 8
2024
-
[53]
W. You, M. Zhang, L. Zhang, X. Zhou, K. Shi, and S. Gu. Consistency trajectory matching for one-step generative super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12747–12756,
-
[54]
Z. You, X. Cai, J. Gu, T. Xue, and C. Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14483–14494,
-
[55]
F. Yu, J. Gu, Z. Li, J. Hu, X. Kong, X. Wang, J. He, Y. Qiao, and C. Dong. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25669–25680, 2024. 5 21 PiD : Fast and High-Resolution Latent Decoding with Pixel ...
2024
-
[56]
J. Yu, Y. Xu, J. Y. Koh, T. Luong, G. Baid, Z. Wang, V. Vasudevan, A. Ku, Y. Yang, B. K. Ayan, B. Hutchinson, W. Han, Z. Parekh, X. Li, H. Zhang, J. Baldridge, and Y. Wu. Scaling autoregressive models for content-rich text-to-image generation.Transactions on Machine Learning Research, 2022. 3, 4
2022
-
[57]
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y. Cheng, V. Birodkar, A. Gupta, X. Gu, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Q. Yu, M. Weber, X. Deng, X. Shen, D. Cremers, and L.-C. Chen. An image is worth 32 tokens for reconstruction and generation.Advances in Neural Information Processing Systems, 37:128940–128966, 2024. 4
2024
-
[59]
Y. Yu, W. Xiong, W. Nie, Y. Sheng, S. Liu, and J. Luo. Pixeldit: Pixel diffusion transformers for image generation.arXiv preprint arXiv:2511.20645, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Z. Yue, K. Liao, and C. C. Loy. Arbitrary-steps image super-resolution via diffusion inversion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23153–23163, 2025. 5, 9, 10
2025
- [61]
-
[62]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, 2023. 4, 9
2023
-
[63]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 6
2023
-
[64]
L. Zhao, S. Woo, Z. Wan, Y. Li, H. Zhang, B. Gong, H. Adam, X. Jia, and T. Liu. Epsilon-VAE: Denoising as visual decoding. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025. 3, 4
2025
-
[65]
Diffusion Transformers with Representation Autoencoders
B. Zheng, N. Ma, S. Tong, and S. Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025. 3, 4, 9 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.