Causality as the Statistical Conscience of Artificial Intelligence: From Pearl's Ladder to Trustworthy Machines
Pith reviewed 2026-06-30 15:04 UTC · model grok-4.3
The pith
Any algorithm achieving out-of-distribution generalization must encode causal structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes the Statistical Necessity Theorem for Causal Generalization: any algorithm achieving out-of-distribution generalization must encode causal structure. This formalizes the distinction between prediction P(Y|X) and intelligence P(Y|do(X)). It also supplies a unified framework that treats Pearl's do-calculus, the Potential Outcomes framework, Double Machine Learning, and Invariant Risk Minimization as members of a family of Causal Statistical Estimators. Three prominent AI failure modes—hallucination in large language models, reward hacking in reinforcement learning from human feedback, and performance degradation under distribution shift—are presented as direct consequence
What carries the argument
The Statistical Necessity Theorem for Causal Generalization, which shows that out-of-distribution generalization requires explicit encoding of causal structure to recover interventional distributions.
If this is right
- AI systems lacking causal structure will remain brittle when distributions shift.
- Trustworthy AI requires systematic use of causal estimators such as do-calculus and invariant risk minimization.
- Hallucinations in language models stem from non-causal pattern matching and can be addressed by causal remedies.
- Reward hacking in RLHF arises from optimizing non-interventional objectives.
- The statistical community holds the foundational tools required for rigorous causal grounding of AI.
Where Pith is reading between the lines
- Models trained solely on correlations may systematically fail in settings where actions or interventions matter.
- Training objectives could be redesigned to enforce causal invariance rather than pure predictive accuracy.
- Robust optimization problems in machine learning could gain from explicit causal encoding mechanisms.
- A direct test would measure whether algorithms that recover causal graphs show measurable gains on distribution-shifted benchmarks.
Load-bearing premise
The listed AI failure modes are each manifestations of causal blindness that admit a principled statistical remedy via causal inference methods.
What would settle it
An algorithm that achieves reliable out-of-distribution generalization on shifted data without encoding any causal structure or interventional quantities.
Figures

read the original abstract
Modern Artificial Intelligence achieves remarkable predictive power by optimizing statistical risk functionals over vast corpora. Yet a gap separates this from genuine intelligence: the inability to distinguish correlation from causation. This paper argues that causal inference (identifying mechanisms invariant under intervention) is AI's indispensable statistical conscience. Without causal grounding, AI systems are correlation machines: powerful in familiar domains, brittle under distribution shift, and biased in high-stakes settings. Three contributions develop this argument. First, a Statistical Necessity Theorem for Causal Generalization: any algorithm achieving out-of-distribution generalization must encode causal structure, formalizing the distinction between prediction P(Y|X) and intelligence P(Y|do(X)). Second, a unified framework connects Pearl's do-calculus, the Potential Outcomes framework, Double Machine Learning, and Invariant Risk Minimization as a family of Causal Statistical Estimators, each identifying interventional distributions under different assumptions. Third, three AI failure modes (hallucination in large language models, reward hacking in reinforcement learning from human feedback, and degradation under distribution shift) are manifestations of causal blindness, each admitting a principled statistical remedy. Trustworthy AI is, at its core, a problem of causal statistics. The statistical community is not merely equipped to solve it -- it is the only community with the foundational tools to do so rigorously.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that causal inference serves as the indispensable statistical foundation for trustworthy AI, claiming that without it systems remain mere correlation machines prone to brittleness. It presents three contributions: (1) a Statistical Necessity Theorem asserting that any algorithm achieving out-of-distribution generalization must encode causal structure, distinguishing P(Y|X) from P(Y|do(X)); (2) a unified framework treating Pearl's do-calculus, potential outcomes, double machine learning, and invariant risk minimization as a family of Causal Statistical Estimators; and (3) the positioning of LLM hallucination, RLHF reward hacking, and distribution-shift degradation as manifestations of causal blindness, each with causal remedies. The conclusion is that trustworthy AI is fundamentally a causal statistics problem.
Significance. If the necessity theorem were rigorously derived and the failure-mode remedies shown to be effective, the work would strengthen the case for embedding causal methods in AI pipelines and could influence how the statistical community engages with AI robustness questions. The unification framing, if substantiated, might aid cross-method comparisons, though the manuscript provides no new derivations or empirical validations to support these points.
major comments (3)
- [Abstract] Abstract: The Statistical Necessity Theorem is asserted without derivation, stated assumptions, or supporting argument, despite being load-bearing for the central claim that OOD generalization requires causal structure. No proof sketch, invariance conditions, or counter-example analysis appears.
- [Abstract] Abstract / OOD generalization discussion: The theorem claims necessity for arbitrary out-of-distribution generalization, yet many common OOD regimes (covariate shift or selection bias addressable by reweighting or domain adaptation) do not alter structural equations and are handled without do-calculus or interventions; the manuscript must delimit the class of shifts to which the necessity claim applies.
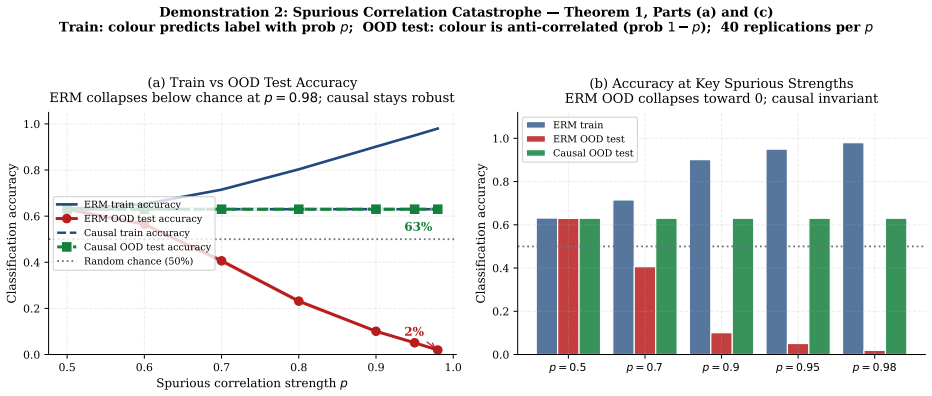
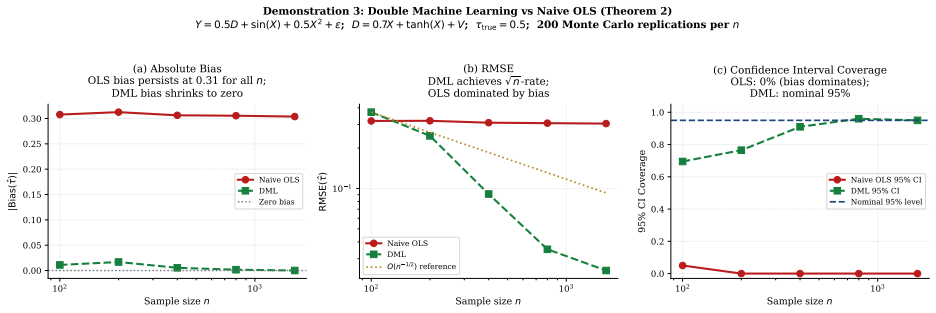
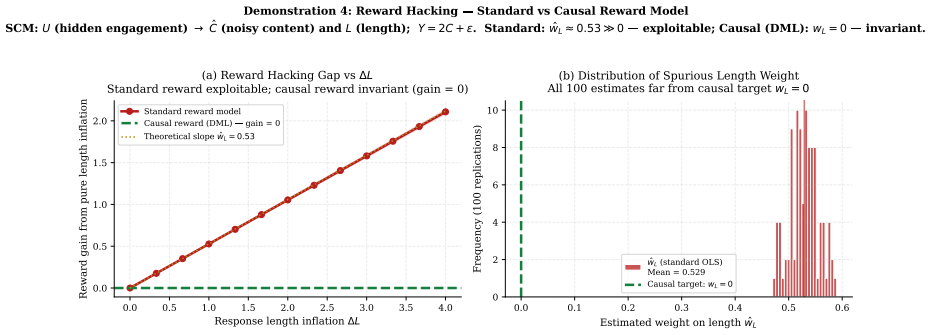
- [Failure modes] Failure modes section: The claim that hallucination, reward hacking, and distribution-shift degradation are direct manifestations of causal blindness is presented as statements rather than through explicit mechanistic mappings or controlled demonstrations linking each failure to the absence of interventional identification.
minor comments (1)
- [Abstract] Notation for interventional vs. observational distributions is introduced in the abstract but not consistently carried through the unification framework; explicit notation table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments, which identify key areas where the presentation of the Statistical Necessity Theorem and the failure-mode analysis can be strengthened. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The Statistical Necessity Theorem is asserted without derivation, stated assumptions, or supporting argument, despite being load-bearing for the central claim that OOD generalization requires causal structure. No proof sketch, invariance conditions, or counter-example analysis appears.
Authors: We agree that the current manuscript presents the theorem at a high conceptual level without a formal derivation. In revision we will add an explicit statement of the theorem together with its assumptions (existence of a structural causal model, invariance of mechanisms under intervention, and the presence of spurious correlations that break under do-interventions). A short proof sketch will be included showing that any predictor relying solely on P(Y|X) can be made arbitrarily inaccurate by an intervention that alters the conditional distribution while preserving the marginals. We will also note simple counter-examples where reweighting suffices and contrast them with interventional shifts. revision: yes
-
Referee: [Abstract] Abstract / OOD generalization discussion: The theorem claims necessity for arbitrary out-of-distribution generalization, yet many common OOD regimes (covariate shift or selection bias addressable by reweighting or domain adaptation) do not alter structural equations and are handled without do-calculus or interventions; the manuscript must delimit the class of shifts to which the necessity claim applies.
Authors: The referee is correct that the necessity claim does not hold for every conceivable distribution shift. We will revise the abstract and the theorem statement to restrict the claim to interventional distribution shifts—i.e., those that change the structural equations or the intervention distribution P(Y|do(X))—while explicitly noting that pure covariate shifts or selection bias that leave the conditional mechanisms unchanged can be addressed by reweighting or domain-adaptation techniques without invoking do-calculus. revision: yes
-
Referee: [Failure modes] Failure modes section: The claim that hallucination, reward hacking, and distribution-shift degradation are direct manifestations of causal blindness is presented as statements rather than through explicit mechanistic mappings or controlled demonstrations linking each failure to the absence of interventional identification.
Authors: The section is intended as a unifying conceptual argument rather than a set of new empirical studies. Nevertheless, we accept that more explicit mechanistic links would improve clarity. In revision we will add short mechanistic paragraphs for each failure mode, referencing existing literature (e.g., how RLHF optimizes an observational reward model rather than an interventional one, and how LLM next-token prediction lacks do-calculus-style consistency checks). We will not add new controlled experiments, as the paper is positioned as a statistical perspective rather than an empirical methods contribution. revision: partial
Circularity Check
No circularity: theorem stated as conceptual distinction without self-referential reduction
full rationale
The paper states a Statistical Necessity Theorem linking OOD generalization to causal structure (P(Y|do(X)) vs P(Y|X)) and unifies existing tools (do-calculus, IRM, DML) as Causal Statistical Estimators. No equations, proofs, or self-citations are exhibited in the provided text that reduce the theorem to a tautology, fitted parameter, or load-bearing self-reference. The argument invokes established frameworks without deriving them from the paper's own inputs, and the failure-mode remedies are presented as applications rather than constructed predictions. This is a standard non-circular positioning of prior causal methods.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Causal structure is required for out-of-distribution generalization in any algorithm
- domain assumption Pearl's do-calculus, potential outcomes, double ML, and IRM form a unified family of causal estimators under different assumptions
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man´ e. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Anonymous. When bias pretends to be truth: How spurious correlations undermine halluci- nation detection in LLMs.arXiv preprint arXiv:2511.07318,
-
[3]
Martin Arjovsky, L´ eon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[4]
Causality Is Key to Understand and Balance Multiple Goals in Trustworthy ML and Foundation Models
17 Daniel Kang et al. Causality is key to understand and balance multiple goals in trustworthy ML and foundation models.arXiv preprint arXiv:2502.21123,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method. arXiv preprint physics/0004057,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2501.09620 , year=
Chaoqi Wang, Zhuokai Zhao, Yibo Bai, and Zhaorun Chen. Beyond reward hacking: Causal rewards for large language model alignment.arXiv preprint arXiv:2501.09620,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.