A generative pre-trained transformer with Kerr-soliton attention
Pith reviewed 2026-06-30 14:54 UTC · model grok-4.3
The pith
Kerr-soliton dynamics in a resonator execute the attention step of a generative transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
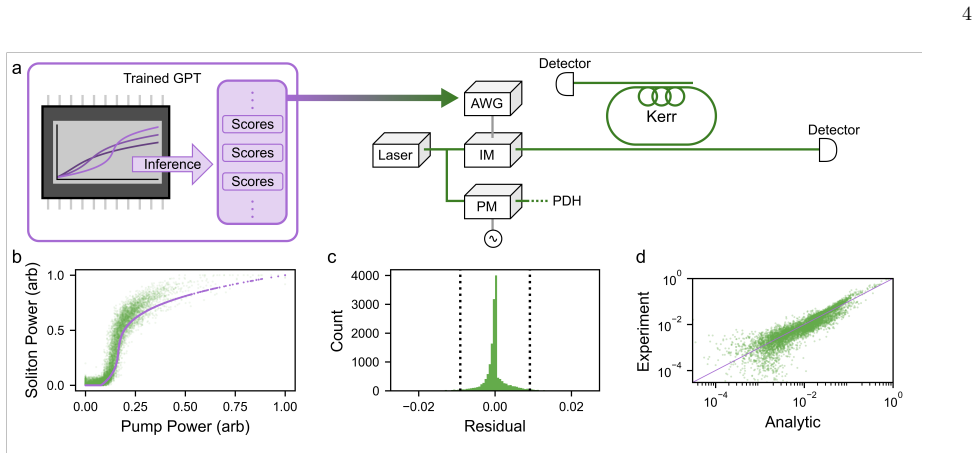
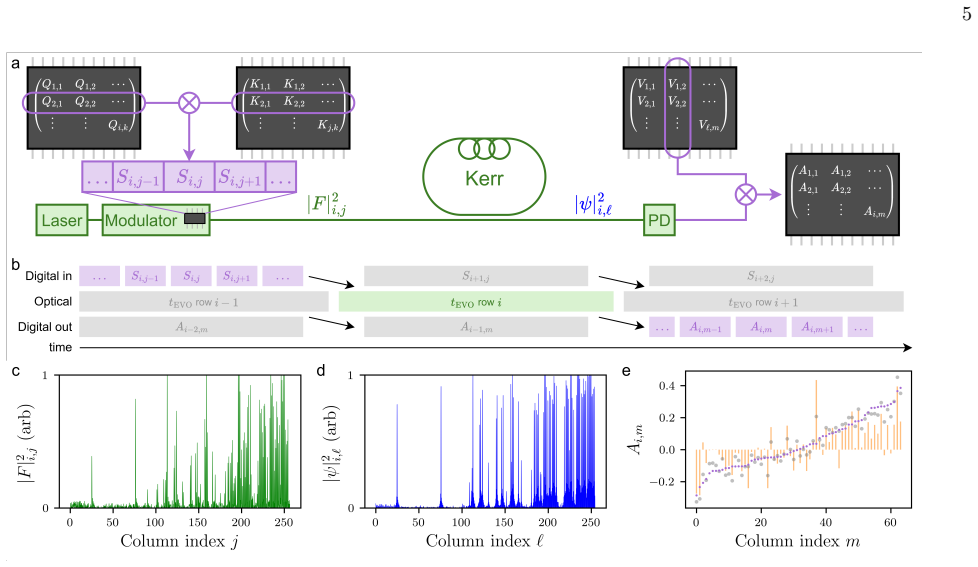
Kerr-soliton attention harnesses driven-dissipative nonlinear dynamics in a resonator to realize, execute, and validate a deep-learning attention operation in physical hardware. Computation proceeds through streaming-in-time excitation of an ensemble of Kerr solitons, with inputs encoded as temporal signals that evolve under nonlinear dynamics. The authors train a transformer language model using an analytic Kerr-soliton attention response and explore generative inference by streaming model-produced inputs through the experimental system, observing high-fidelity agreement between the experimentally produced nonlinear weights and those predicted by the analytic model.
What carries the argument
Kerr-soliton attention: the nonlinear response produced by an ensemble of Kerr solitons in a driven-dissipative resonator when excited by streaming temporal input signals.
If this is right
- Memory and compute are mapped onto the same physical dynamics, relaxing the need for intermediate digital storage.
- Computation proceeds through streaming-in-time excitation without separate data movement steps.
- The approach enables hybrid digital-physical learning systems in which Kerr solitons provide physical memory and high-bandwidth nonlinear processing.
- High-fidelity agreement between experimental and analytic weights validates the physical realization for transformer attention.
Where Pith is reading between the lines
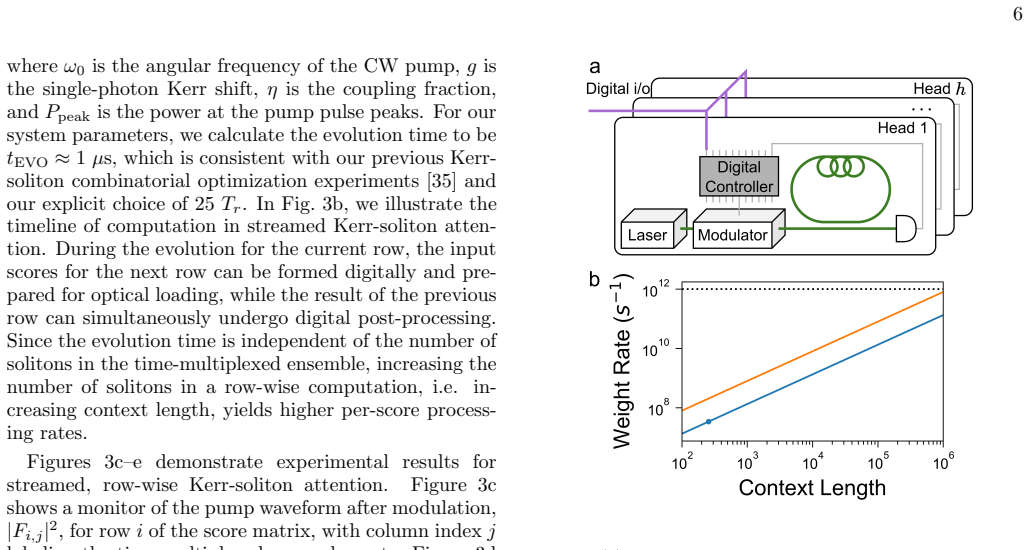
- The method could reduce energy cost per token if the resonator bandwidth and stability scale to the rates required by large models.
- Other nonlinear transformations inside neural networks might be candidates for similar resonator-based implementations.
- Real-time optical processing at the resonator's native bandwidth could become feasible once the digital-to-analog and analog-to-digital interfaces are optimized.
Load-bearing premise
The experimental resonator dynamics faithfully reproduce the analytic Kerr-soliton attention response under streaming inference conditions without unmodeled noise, drift, or bandwidth limitations that would degrade model performance.
What would settle it
A measured deviation between the experimentally generated attention weights and the analytic Kerr-soliton model during streaming inference, exceeding the reported high-fidelity agreement, would falsify the central claim.
Figures

read the original abstract
Artificial intelligence systems, particularly through generative pre-trained transformers (GPTs), have enabled capability-rich language models, but their operation incurs substantial costs in digital computation, memory, and data movement. Attention is a core operation in GPTs that computes context-dependent weights for input tokens. Since deep-learning models are defined by compositions of nonlinear transformations, identifying physical systems that can realize them offers a pathway to higher efficiency. Here, we introduce Kerr-soliton attention, harnessing driven-dissipative nonlinear dynamics in a resonator to realize, execute, and validate a deep-learning attention operation in physical hardware. We train a transformer language model using an analytic Kerr-soliton attention response and explore generative inference by streaming model-produced inputs through the experimental system. We observe high-fidelity agreement between the experimentally produced nonlinear weights and those predicted by the analytic Kerr-soliton model. Computation proceeds through streaming-in-time excitation of an ensemble of Kerr solitons, with inputs encoded as temporal signals that evolve under nonlinear dynamics. Our approach maps memory and compute onto the same physical dynamics, relaxing the need for intermediate digital storage and reducing data movement. This work points toward hybrid digital-physical learning systems in which Kerr solitons provide physical memory and high-bandwidth streaming nonlinear processing within deep-learning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Kerr-soliton attention, a physical implementation of the attention mechanism in generative pre-trained transformers realized via driven-dissipative nonlinear dynamics of Kerr solitons in a resonator. A transformer language model is trained exclusively with an analytic Kerr-soliton response; generative inference is then performed by streaming model-produced token embeddings through an experimental resonator, with the authors reporting high-fidelity agreement between the experimentally generated nonlinear weights and the analytic predictions. The approach maps both memory and nonlinear computation onto the same physical dynamics to reduce digital storage and data movement.
Significance. If the experimental resonator dynamics faithfully reproduce the analytic attention map for inference-length sequences without cumulative degradation, the result would constitute a notable demonstration of hybrid digital-physical deep learning hardware, directly addressing energy and data-movement costs in attention-based models. The work provides a concrete example of embedding a core transformer operation in driven-dissipative nonlinear optics.
major comments (2)
- [Experimental validation (streaming inference)] The central claim that the experimental system executes the attention operation identically to the analytic model under streaming inference conditions is load-bearing, yet the manuscript provides no quantified bounds on cumulative effects such as resonator drift, thermal noise, pump-power fluctuations, or finite response bandwidth that would cause divergence over hundreds-to-thousands of tokens.
- [Abstract and results] Training and loss are computed exclusively with the analytic Kerr-soliton response; any unmodeled deviation in the physical output therefore directly falsifies the hardware-execution claim, but no error metrics, sequence-length dependence, or noise characterization are reported to support the high-fidelity agreement statement.
minor comments (1)
- [Methods] Notation for the mapping of token embeddings to temporal signals and the precise definition of the Kerr-soliton attention response function should be clarified with explicit equations.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on experimental validation and quantitative support for the hardware-execution claim. We address each point below, clarifying the scope of our reported results while acknowledging where additional discussion or metrics can be incorporated.
read point-by-point responses
-
Referee: [Experimental validation (streaming inference)] The central claim that the experimental system executes the attention operation identically to the analytic model under streaming inference conditions is load-bearing, yet the manuscript provides no quantified bounds on cumulative effects such as resonator drift, thermal noise, pump-power fluctuations, or finite response bandwidth that would cause divergence over hundreds-to-thousands of tokens.
Authors: The reported experiments demonstrate high-fidelity agreement between experimental and analytic nonlinear weights for the specific token sequences and inference lengths tested in the generative phase. The setup maintained stability over the duration of those runs, with no observable cumulative divergence within the demonstrated regime. We agree that explicit bounds on drift, noise, and bandwidth effects for sequences of hundreds to thousands of tokens are not provided and constitute a limitation for extrapolating to arbitrary lengths. We will add a dedicated limitations paragraph discussing these factors and the conditions under which the physical dynamics remain faithful to the analytic model. revision: partial
-
Referee: [Abstract and results] Training and loss are computed exclusively with the analytic Kerr-soliton response; any unmodeled deviation in the physical output therefore directly falsifies the hardware-execution claim, but no error metrics, sequence-length dependence, or noise characterization are reported to support the high-fidelity agreement statement.
Authors: The high-fidelity agreement is substantiated by direct visual and qualitative overlap between the experimentally generated weights and the analytic predictions in the results figures. We acknowledge that the manuscript does not include explicit quantitative error metrics (e.g., MSE or sequence-length dependence) or noise characterization. This omission weakens the support for the claim as stated. We will revise the abstract and results section to include quantitative error metrics computed from the existing experimental data for the tested sequences, along with a brief characterization of observed noise levels. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains a transformer using an analytic Kerr-soliton attention response derived from resonator dynamics, then performs inference by streaming model-generated inputs through experimental hardware and reports agreement with the analytic prediction. No equations, definitions, or self-citations are presented that reduce any claimed prediction or uniqueness result to a fitted input or prior author work by construction. The experimental validation functions as an independent empirical check rather than a tautology, leaving the central mapping of nonlinear dynamics to attention self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
using backpropagation to compute gradients and AdamW for optimization; see Methods. In deep-learning systems, the cross-entropy loss (CEL) quantifies the neg- ative log-likelihood of the correct next-character predic- tion under the model distribution, with lower values indi- cating improved predictive accuracy. We estimate CEL by averaging over 200 batch...
-
[2]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, Attention is All you Need, inAdvances in Neural Infor- mation Processing Systems, Vol. 30 (Curran Associates, Inc., 2017)
2017
-
[3]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Ka- plan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sas- try, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCan- dlish, A. Radford, I. Sutskever, and D. A...
2020
-
[4]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy, The Pile: An 800GB Dataset of Diverse Text for Language Modeling (2020), arXiv:2101.00027, arXiv:2101.00027 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, Scaling Laws for Neural Language Models (2020), arXiv:2001.08361, arXiv:2001.08361 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Chowdhery, S
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sut- ton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev,...
2023
-
[7]
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R´ e, FlashAt- tention: Fast and Memory-Efficient Exact Attention with IO-Awareness, inAdvances in Neural Information Pro- cessing Systems, Vol. 35, edited by S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Curran Associates, Inc., 2022) pp. 16344–16359
2022
-
[8]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, Efficient Mem- ory Management for Large Language Model Serving with PagedAttention, inProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23 (Association for Computing Machinery, New York, NY, USA, 2023) pp. 611–626
2023
-
[9]
Strubell, A
E. Strubell, A. Ganesh, and A. McCallum, Energy and Policy Considerations for Deep Learning in NLP, inPro- ceedings of the 57th Annual Meeting of the Association for Computational Linguistics, edited by A. Korhonen, D. Traum, and L. M` arquez (Association for Computa- tional Linguistics, Florence, Italy, 2019) pp. 3645–3650
2019
-
[10]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, Carbon Emissions and Large Neural Network Training (2021), arXiv:2104.10350, arXiv:2104.10350 [cs.CY]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Gholami, S
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, A Survey of Quantization Methods for Efficient Neural Network Inference, inLow-Power Com- puter Vision, edited by G. K. Thiruvathukal, Y.-H. Lu, J. Kim, Y. Chen, and B. Chen (Chapman and Hall/CRC,
-
[12]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
T. Dao, FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (2023), arXiv:2307.08691, arXiv:2307.08691 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V. Ghaemmaghami, R. Gottipati, W. Gulland, R. Hag- mann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan,...
-
[14]
Y.-H. Chen, T. Krishna, J. S. Emer, and V. Sze, Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks, IEEE Journal of Solid- State Circuits52, 127 (2017)
2017
-
[15]
Momeni, B
A. Momeni, B. Rahmani, B. Scellier, L. G. Wright, P. L. McMahon, C. C. Wanjura, Y. Li, A. Skalli, N. G. Berloff, T. Onodera, I. Oguz, F. Morichetti, P. del Hougne, M. Le Gallo, A. Sebastian, A. Mirhoseini, C. Zhang, D. Markovi´ c, D. Brunner, C. Moser, S. Gigan, F. Mar- quardt, A. Ozcan, J. Grollier, A. J. Liu, D. Psaltis, A. Al` u, and R. Fleury, Trainin...
2025
-
[16]
Mohseni, P
N. Mohseni, P. L. McMahon, and T. Byrnes, Ising ma- chines as hardware solvers of combinatorial optimization problems, Nature Reviews Physics4, 363 (2022)
2022
-
[17]
Inagaki, Y
T. Inagaki, Y. Haribara, K. Igarashi, T. Sonobe, S. Ta- mate, T. Honjo, A. Marandi, P. L. McMahon, T. Umeki, K. Enbutsu, O. Tadanaga, H. Takenouchi, K. Aihara, K.- i. Kawarabayashi, K. Inoue, S. Utsunomiya, and H. Take- sue, A coherent ising machine for 2000-node optimization problems, Science354, 603 (2016)
2000
-
[18]
Rizzo, A
A. Rizzo, A. Novick, V. Gopal, B. Y. Kim, X. Ji, S. Daudlin, Y. Okawachi, Q. Cheng, M. Lipson, A. L. Gaeta, and K. Bergman, Massively scalable Kerr comb- driven silicon photonic link, Nature Photonics17, 781 (2023). 10
2023
-
[19]
Pirmoradi, J
A. Pirmoradi, J. Zang, K. Omirzakhov, Z. Yu, Y. Jin, S. B. Papp, and F. Aflatouni, Integrated multi-port multi-wavelength coherent optical source for beyond Tb/s optical links, Nature Communications16, 6387 (2025)
2025
-
[20]
Hamerly, L
R. Hamerly, L. Bernstein, A. Sludds, M. Soljaˇ ci´ c, and D. Englund, Large-Scale Optical Neural Networks Based on Photoelectric Multiplication, Physical Review X9, 021032 (2019)
2019
-
[21]
H. Zhou, J. Dong, J. Cheng, W. Dong, C. Huang, Y. Shen, Q. Zhang, M. Gu, C. Qian, H. Chen, Z. Ruan, and X. Zhang, Photonic matrix multiplication lights up photonic accelerator and beyond, Light: Science & Ap- plications11, 30 (2022)
2022
-
[22]
D. A. B. Miller, Device Requirements for Optical Inter- connects to Silicon Chips, Proceedings of the IEEE97, 1166 (2009)
2009
-
[23]
Y. Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. Baehr- Jones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englund, and M. Soljaˇ ci´ c, Deep learning with coherent nanophotonic circuits, Nature Photonics11, 441 (2017)
2017
-
[24]
F. Leo, S. Coen, P. Kockaert, S.-P. Gorza, P. Emplit, and M. Haelterman, Temporal cavity solitons in one- dimensional Kerr media as bits in an all-optical buffer, Nature Photonics4, 471 (2010)
2010
-
[25]
T. J. Kippenberg, A. L. Gaeta, M. Lipson, and M. L. Gorodetsky, Dissipative kerr solitons in optical microres- onators, Science361, eaan8083 (2018)
2018
-
[26]
D. T. Spencer, T. Drake, T. C. Briles, J. Stone, L. C. Sin- clair, C. Fredrick, Q. Li, D. Westly, B. R. Ilic, A. Blue- stone, N. Volet, T. Komljenovic, L. Chang, S. H. Lee, D. Y. Oh, M. G. Suh, K. Y. Yang, M. H. P. Pfeiffer, T. J. Kippenberg, E. Norberg, L. Theogarajan, K. Va- hala, N. R. Newbury, K. Srinivasan, J. E. Bowers, S. A. Diddams, and S. B. Papp...
2018
-
[27]
T. E. Drake, T. C. Briles, J. R. Stone, D. T. Spencer, D. R. Carlson, D. D. Hickstein, Q. Li, D. Westly, K. Srini- vasan, S. A. Diddams, and S. B. Papp, Terahertz-Rate Kerr-Microresonator Optical Clockwork, Physical Re- view X9, 031023 (2019)
2019
-
[28]
T. E. Drake, J. R. Stone, T. C. Briles, and S. B. Papp, Thermal decoherence and laser cooling of Kerr microres- onator solitons, Nature Photonics14, 480 (2020), num- ber: 8
2020
-
[29]
X. Xu, M. Tan, B. Corcoran, J. Wu, A. Boes, T. G. Nguyen, S. T. Chu, B. E. Little, D. G. Hicks, R. Moran- dotti, A. Mitchell, and D. J. Moss, 11 TOPS photonic convolutional accelerator for optical neural networks, Na- ture589, 44 (2021)
2021
-
[30]
Feldmann, N
J. Feldmann, N. Youngblood, M. Karpov, H. Gehring, X. Li, M. Stappers, M. Le Gallo, X. Fu, A. Lukashchuk, A. S. Raja, J. Liu, C. D. Wright, A. Sebastian, T. J. Kippenberg, W. H. P. Pernice, and H. Bhaskaran, Paral- lel convolutional processing using an integrated photonic tensor core, Nature589, 52 (2021)
2021
- [31]
-
[32]
Suh and K
M.-G. Suh and K. J. Vahala, Soliton microcomb range measurement, Science359, 884 (2018)
2018
-
[33]
Riemensberger, A
J. Riemensberger, A. Lukashchuk, M. Karpov, W. Weng, E. Lucas, J. Liu, and T. J. Kippenberg, Massively parallel coherent laser ranging using a soliton microcomb, Nature 581, 164 (2020)
2020
-
[34]
D. C. Cole, E. S. Lamb, P. Del’Haye, S. A. Diddams, and S. B. Papp, Soliton crystals in Kerr resonators, Nature Photonics11, 671 (2017)
2017
-
[35]
D. C. Cole and S. B. Papp, Subharmonic entrainment of kerr breather solitons, Phys. Rev. Lett.123, 173904 (2019)
2019
- [36]
- [37]
-
[38]
Godey, I
C. Godey, I. V. Balakireva, A. Coillet, and Y. K. Chembo, Stability analysis of the spatiotemporal lugiato- lefever model for kerr optical frequency combs in the anomalous and normal dispersion regimes, Physical Re- view A89, 063814 (2014)
2014
-
[39]
Y. Jin, J. Zang, S. Yeola, A. R. Carollo, N. Chauhan, and S. B. Papp, Nanophotonic control of collective many- body states in kerr solitons (2026), arXiv:2604.22039, arXiv:2604.22039 [physics.optics]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Karpathy, char-rnn, GitHub repository (2015)
A. Karpathy, char-rnn, GitHub repository (2015)
2015
-
[41]
K. Beha, D. C. Cole, P. Del’Haye, A. Coillet, S. A. Did- dams, and S. B. Papp, Electronic synthesis of light, Op- tica4, 406 (2017). [41]NVIDIA A100 Tensor Core GPU Datasheet, NVIDIA Corporation (2021). [42]Corning SMF-28 Ultra Optical Fiber: Product Informa- tion, Corning Incorporated (2025)
2017
-
[42]
Karpathy, nanoGPT: The simplest, fastest reposi- tory for training/finetuning medium-sized gpts, GitHub repository (2022)
A. Karpathy, nanoGPT: The simplest, fastest reposi- tory for training/finetuning medium-sized gpts, GitHub repository (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.